文章目录
- Pandas文本数据处理大全:类型判断、空白字符处理、拆分与连接
- 1. 判断文本数据类型
- 2. 去除空白字符
- 3. 文本数据拆分
- 4. 文本数据连接
- 5. 文本数据替换
- 6. 文本数据匹配与提取
- 7. 文本数据的大小写转换
- 8. 文本数据的长度计算
- 9. 文本数据的排序
- 10. 文本数据的分组与聚合
- 11. 文本数据的模糊匹配
- 12. 文本数据的字符串切片
- 13. 文本数据的替换匹配
- 14. 文本数据的字符串匹配与提取
- 15. 文本数据的多条件筛选
- 16. 文本数据的拼接与替换
- 总结
Pandas文本数据处理大全:类型判断、空白字符处理、拆分与连接
Pandas是Python中一种强大的数据分析库,广泛用于数据清洗、处理和分析。在实际的数据处理中,文本数据常常是不可避免的一部分。本篇博客将介绍Pandas中处理文本数据的一些常用技巧,包括类型判断、去除空白字符、拆分和连接。

1. 判断文本数据类型
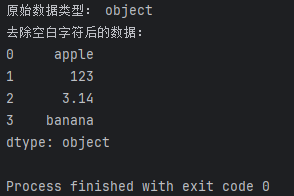
在处理文本数据时,首先要了解数据的类型,以便采取相应的处理方法。使用dtype属性可以获取Pandas Series或DataFrame中文本数据的类型。
import pandas as pd
# 创建一个包含文本数据的Series
data = pd.Series(['apple', '123', '3.14', 'banana'])
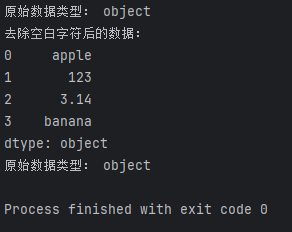
print("原始数据类型:", data.dtype)
在这个例子中,data包含了不同类型的文本数据,输出结果应该是object,表示这是一列包含对象的数据。
2. 去除空白字符
在处理文本数据时,经常需要去除字符串中的空白字符,以便更好地进行分析。使用str.strip()方法可以去除字符串两端的空白字符。
# 去除字符串两端的空白字符
data = data.str.strip()
print("去除空白字符后的数据:")
print(data)
这个例子中,str.strip()将去除字符串两端的空白字符,输出结果将是去除空白字符后的数据。
3. 文本数据拆分
有时候,我们需要将包含多个元素的字符串拆分成单独的部分,以便进一步处理。使用str.split()方法可以实现字符串的拆分。
# 将字符串拆分成单独的部分
data = data.str.split(',')
print("拆分后的数据:")
print(data)
这个例子中,str.split(',')将字符串按逗号分隔成多个部分,输出结果将是拆分后的数据。
4. 文本数据连接
除了拆分,有时候我们需要将多个字符串连接成一个字符串。使用str.cat()方法可以实现字符串的连接。
# 将多个字符串连接成一个字符串
data = data.str.cat(sep='-')
print("连接后的数据:", data)
在这个例子中,str.cat(sep='-')将多个字符串按照连接符“-”连接成一个字符串,输出结果将是连接后的数据。
通过上述介绍,我们了解了Pandas中处理文本数据的一些常用技巧,包括类型判断、去除空白字符、拆分和连接。这些技巧在实际的数据处理中经常会用到,能够帮助我们更灵活地处理各种文本数据。希望这篇博客能对你在使用Pandas进行文本数据处理时有所帮助。# Pandas文本数据处理技巧之类型判断、空白字符处理、拆分与连接
Pandas是Python中一种强大的数据分析库,广泛用于数据清洗、处理和分析。在实际的数据处理中,文本数据常常是不可避免的一部分。本篇博客将介绍Pandas中处理文本数据的一些常用技巧,包括类型判断、去除空白字符、拆分和连接。
5. 文本数据替换
文本数据处理中,替换是一种常见的操作,可以用于清理数据或将特定字符串替换为其他值。使用str.replace()方法可以实现字符串的替换。
# 替换字符串中的特定值
data = data.str.replace('apple', 'orange')
print("替换后的数据:", data)
在这个例子中,str.replace('apple', 'orange')将数据中的’apple’替换为’orange’,输出结果将是替换后的数据。
6. 文本数据匹配与提取
通过正则表达式,可以进行文本数据的匹配和提取。使用str.extract()方法可以根据正则表达式提取符合条件的部分。
# 使用正则表达式提取数字部分
data = data.str.extract('(\d+)')
print("提取数字后的数据:", data)
在这个例子中,str.extract('(\d+)')使用正则表达式提取数据中的数字部分,输出结果将是提取后的数据。
7. 文本数据的大小写转换
有时候需要将文本数据转换为大写或小写,以便进行统一处理。使用str.upper()和str.lower()方法可以分别实现大写和小写的转换。
# 将数据转换为大写
data_upper = data.str.upper()
print("转换为大写后的数据:", data_upper)
# 将数据转换为小写
data_lower = data.str.lower()
print("转换为小写后的数据:", data_lower)
这个例子中,str.upper()将数据转换为大写,str.lower()将数据转换为小写,输出结果分别是转换后的数据。
通过这些文本数据处理的技巧,我们能够更灵活地进行数据清洗和分析,使得数据处理过程更加高效和精确。希望这些示例能够帮助你更好地利用Pandas处理文本数据。
8. 文本数据的长度计算
有时候需要计算文本数据的长度,以便进一步分析。使用str.len()方法可以获取字符串的长度。
# 计算字符串的长度
data_length = data.str.len()
print("字符串长度:", data_length)
在这个例子中,str.len()将返回每个字符串的长度,输出结果将是字符串长度的Series。
9. 文本数据的排序
对文本数据进行排序是常见的需求之一,可以使用str.sort_values()方法实现。
# 对字符串进行排序
data_sorted = data.sort_values()
print("排序后的数据:", data_sorted)
这个例子中,str.sort_values()将对文本数据进行排序,输出结果将是排序后的数据。
10. 文本数据的分组与聚合
在处理文本数据时,有时候需要对数据进行分组,并对每个组进行聚合操作。可以使用groupby和聚合函数来实现。
# 根据首字母进行分组,并计算每组的平均长度
grouped_data = data.groupby(data.str[0]).mean()
print("分组后的平均长度:", grouped_data)
在这个例子中,首先使用data.str[0]获取每个字符串的首字母,然后使用groupby按照首字母进行分组,最后计算每组的平均长度。
通过这些进阶的文本数据处理技巧,我们可以更全面地应对各种实际场景中的需求。Pandas提供了丰富的文本处理功能,灵活运用这些方法能够提高数据处理的效率和准确性。希望本文提供的代码实例和解析能够帮助你更好地利用Pandas处理文本数据。
11. 文本数据的模糊匹配
在处理文本数据时,有时候需要进行模糊匹配,找到与指定模式相似的字符串。Pandas提供了str.contains()方法来实现模糊匹配。
# 模糊匹配包含特定字符的字符串
contains_result = data[data.str.contains('an')]
print("包含特定字符的字符串:", contains_result)
在这个例子中,str.contains('an')将返回包含字符’“an”的所有字符串,输出结果将是符合条件的字符串。
12. 文本数据的字符串切片
有时候需要对文本数据进行切片操作,获取指定位置范围的子字符串。使用str.slice()方法可以实现字符串的切片。
# 对字符串进行切片操作
sliced_data = data.str.slice(1, 3)
print("切片后的数据:", sliced_data)
在这个例子中,str.slice(1, 3)将对每个字符串进行切片操作,获取位置1到位置3之间的子字符串,输出结果将是切片后的数据。
13. 文本数据的替换匹配
除了简单的替换,有时候需要根据模式进行替换,可以使用str.replace()结合正则表达式实现。
# 使用正则表达式替换匹配的字符串
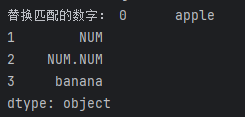
data = data.str.replace(r'\d+', 'NUM')
print("替换匹配的数字:", data)
在这个例子中,str.replace(r'\d+', 'NUM')将匹配所有的数字并替换为’NUM’,输出结果将是替换后的数据。
通过这些高级的文本数据处理技巧,我们可以更灵活地处理各种文本数据的复杂情况。这些方法能够满足不同场景下的需求,使得文本数据处理更加强大和高效。希望这些示例代码和解析对你在Pandas文本数据处理中有所帮助。
14. 文本数据的字符串匹配与提取
在文本数据中,有时候需要根据一定的模式进行字符串匹配和提取。使用str.match()方法可以实现字符串匹配,而str.extract()方法可以提取符合模式的部分。
# 字符串匹配与提取
matched_data = data[data.str.match('b\w+')]
extracted_data = data.str.extract('(\d+\.\d+)')
print("匹配的字符串:", matched_data)
print("提取的数字部分:", extracted_data)
在这个例子中,str.match('b\w+')将返回所有以字母’b’开头的字符串,而str.extract('(\d+\.\d+)')将提取数据中的浮点数部分,输出结果将是匹配的字符串和提取的数字部分。
15. 文本数据的多条件筛选
有时候我们需要根据多个条件对文本数据进行筛选,可以使用逻辑运算符结合多个条件实现。
# 多条件筛选
filtered_data = data[(data.str.len() > 5) & data.str.contains('e')]
print("满足条件的字符串:", filtered_data)
在这个例子中,data.str.len() > 5表示字符串长度大于5,data.str.contains('e')表示字符串包含字符’e’,通过逻辑运算符&结合这两个条件,输出结果将是满足条件的字符串。
16. 文本数据的拼接与替换
使用str.cat()方法可以实现文本数据的拼接,而str.replace()方法可以实现文本数据的替换。
# 文本数据的拼接与替换
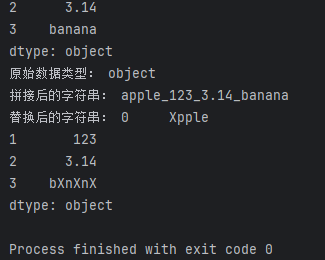
concatenated_data = data.str.cat(sep='_')
replaced_data = data.str.replace('a', 'X')
print("拼接后的字符串:", concatenated_data)
print("替换后的字符串:", replaced_data)
在这个例子中,str.cat(sep='_')将用下划线拼接所有字符串,str.replace('a', 'X')将替换所有的字符’a’为’X’,输出结果将是拼接后的字符串和替换后的字符串。
通过这些进阶的文本数据处理技巧,我们能够更灵活地应对各种实际场景中的需求。Pandas提供了丰富的文本处理功能,灵活运用这些方法能够提高数据处理的效率和准确性。希望本文提供的代码实例和解析能够帮助你更好地利用Pandas处理文本数据。
总结
本文介绍了Pandas中处理文本数据的一系列技巧,涵盖了从基础的类型判断、空白字符处理到高级的模糊匹配、多条件筛选等多个方面。通过这些技巧,我们能够更灵活地进行文本数据的清洗、处理和分析,提高数据处理的效率和准确性。
在基础部分,我们学习了如何判断文本数据的类型,去除空白字符,进行拆分和连接。这些操作对于初步了解和处理文本数据非常重要。
随后,我们深入探讨了一些高级的文本处理技巧,包括替换匹配、字符串切片、模糊匹配、字符串匹配与提取、多条件筛选、拼接与替换等。这些技巧能够满足不同场景下的需求,使得文本数据处理更加强大和灵活。
最后,我们强调了Pandas提供的丰富功能,如字符串长度计算、排序、分组与聚合等,这些功能能够帮助我们更全面地应对各种实际情况。
通过阅读本文,你应该对如何使用Pandas处理文本数据有了更深入的了解。文中提供的代码实例和解析可以作为参考,帮助你在实际项目中更高效地处理文本数据。希望这些技巧对你的数据分析和清洗工作有所帮助。



![最大子数组和[中等]](https://img-blog.csdnimg.cn/direct/054d660177f04abab28f0fc0af6ae8bc.png)