文章目录
- Seq2Seq架构
- 构建简单Seq2Seq架构
- 1.构建实验语料库和词汇表
- 2.生成Seq2Seq训练数据
- 3. 定义编码器和解码器类
- 4.定义Seq2Seq架构
- 5. 训练Seq2Seq架构
- 6.测试Seq2Seq架构
- 归纳
- Seq2Seq编码器-解码器架构小结
Seq2Seq架构
起初,人们尝试使用一个独立的RNN来解决这种序列到序列的NLP任务,但发现效果并不理想。这是因为RNN 在同时处理输入和输出序列(既负责编码又负责解码)时,容易出现信息损失。而Seq2Seq架构通过编码器(Encoder)和解码器(Decoder)来分离对输入和输出序列的处理,即在编码器和解码器中,分别嵌入相互独立的 RNN(见下图),这样就有效地解决了编解码过程中的信息损失问题。
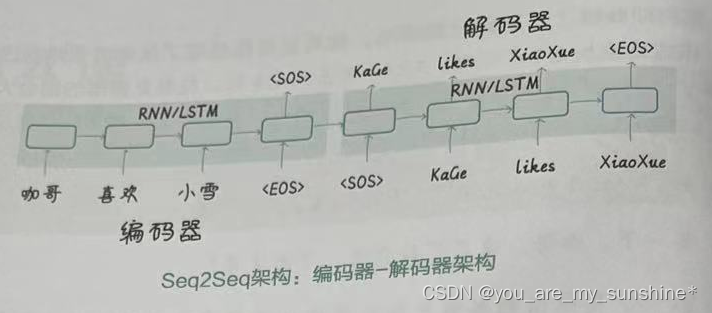
Seq2Seq架构,就是将编码器的输入序列转换成一个固定大小的向量表示,然后将该向量表示转换成解码器的输出序列。
注:编码器的输入序列和解码器的输出序列的长度可以是不同的。
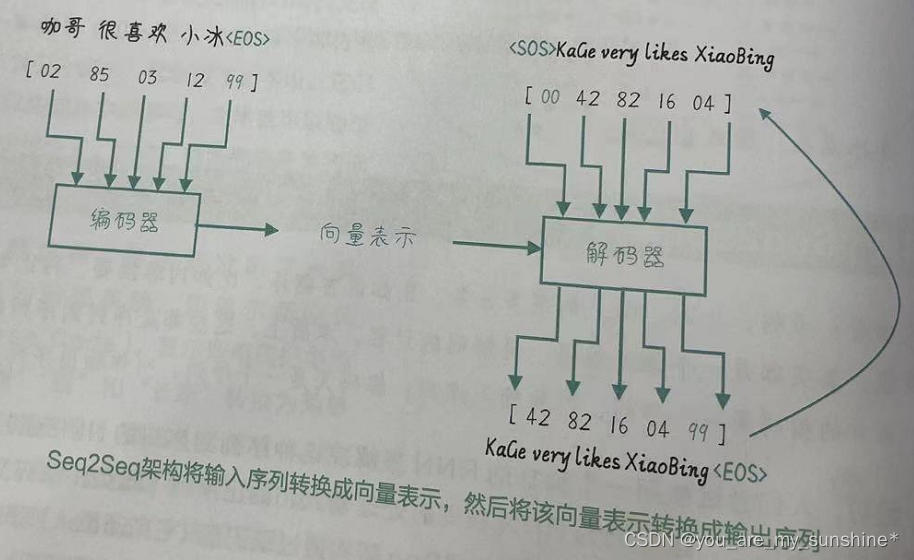
图中,模型读取了一个输入的句子“咖哥很喜欢小冰”,并生成“Kage very likes XiaoBing”作为输出的句子。在输出句子的结束标记后,模型停止输出。编码器将输入序列编码成一个固定大小的向量表示,解码器再将这个向量表示解码成输出序列。在解码阶段,解码器在每个时间步生成一个输出符号,并将其作为下一个时间步的输入。这个过程实际上是自回归的,因为解码器在生成输出序列时依赖于先前生成的符号。
Seq2Seq架构的本质是一种对输入序列的压缩和对输出序列的解压缩过程。而这个压缩和解压缩的过程,可以通过RNN、LSTM或GRU等序列建模方法来实现。编码器使用RNN、LSTM或GRU等来处理输入序列,生成向量表示;解码器也使用RNN、LSTM或GRU等来处理向量表示,生成输出序列。
构建简单Seq2Seq架构
我们会在一个小型语料库上训练Seq2Seq架构,学习如何将一个中文句子翻译成对应的英文句子。
翻译架构的程序结构如下
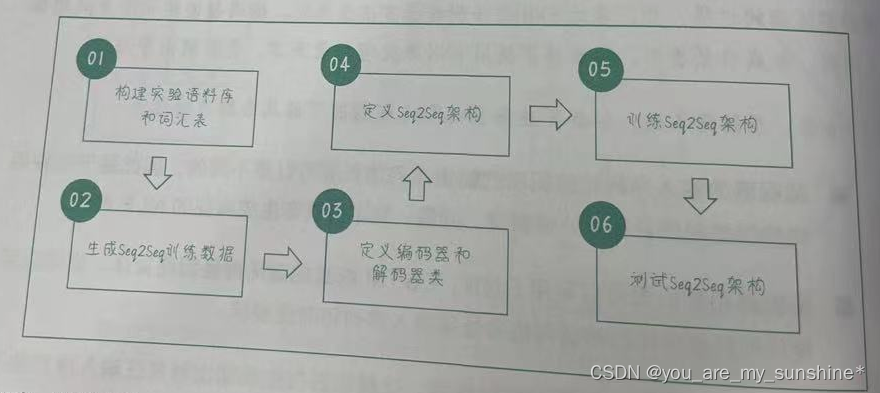
1.构建实验语料库和词汇表
# 构建语料库,每行包含中文、英文(解码器输入)和翻译成英文后的目标输出 3 个句子
sentences = [
['哒哥 喜欢 爬山', '<sos> DaGe likes climb', 'DaGe likes climb <eos>'],
['我 爱 学习 人工智能', '<sos> I love studying AI', 'I love studying AI <eos>'],
['深度学习 改变 世界', '<sos> DL changed the world', 'DL changed the world <eos>'],
['自然 语言 处理 很 强大', '<sos> NLP is so powerful', 'NLP is so powerful <eos>'],
['神经网络 非常 复杂', '<sos> Neural-Nets are complex', 'Neural-Nets are complex <eos>']]
word_list_cn, word_list_en = [], [] # 初始化中英文词汇表
# 遍历每一个句子并将单词添加到词汇表中
for s in sentences:
word_list_cn.extend(s[0].split())
word_list_en.extend(s[1].split())
word_list_en.extend(s[2].split())
# 去重,得到没有重复单词的词汇表
word_list_cn = list(set(word_list_cn))
word_list_en = list(set(word_list_en))
# 构建单词到索引的映射
word2idx_cn = {w: i for i, w in enumerate(word_list_cn)}
word2idx_en = {w: i for i, w in enumerate(word_list_en)}
# 构建索引到单词的映射
idx2word_cn = {i: w for i, w in enumerate(word_list_cn)}
idx2word_en = {i: w for i, w in enumerate(word_list_en)}
# 计算词汇表的大小
voc_size_cn = len(word_list_cn)
voc_size_en = len(word_list_en)
print(" 句子数量:", len(sentences)) # 打印句子数
print(" 中文词汇表大小:", voc_size_cn) # 打印中文词汇表大小
print(" 英文词汇表大小:", voc_size_en) # 打印英文词汇表大小
print(" 中文词汇到索引的字典:", word2idx_cn) # 打印中文词汇到索引的字典
print(" 英文词汇到索引的字典:", word2idx_en) # 打印英文词汇到索引的字典

这个语料库是专门为学习Seq2Seq 模型而创建的,每行包含3个句子。
- 第一句(源语言):中文句子,作为输入序列提供给编码器。
- 第二句(+目标语言):英文句子, 作为解码器的输入序列。句子以特殊的开始符号开头,表示句子的开始。符号有助于解码器学会在何时开始生成目标句子。
- 第三句(目标语言+):也是英文句子,作为解码器的目标输出序列。句子以特殊的结束符号结尾,表示句子的结束。符号有助于解码器学会在何时结束目标句子的生成。
2.生成Seq2Seq训练数据
import numpy as np # 导入 numpy
import torch # 导入 torch
import random # 导入 random 库
# 定义一个函数,随机选择一个句子和词汇表生成输入、输出和目标数据
def make_data(sentences):
# 随机选择一个句子进行训练
random_sentence = random.choice(sentences)
# 将输入句子中的单词转换为对应的索引
encoder_input = np.array([[word2idx_cn[n] for n in random_sentence[0].split()]])
# 将输出句子中的单词转换为对应的索引
decoder_input = np.array([[word2idx_en[n] for n in random_sentence[1].split()]])
# 将目标句子中的单词转换为对应的索引
target = np.array([[word2idx_en[n] for n in random_sentence[2].split()]])
# 将输入、输出和目标批次转换为 LongTensor
encoder_input = torch.LongTensor(encoder_input)
decoder_input = torch.LongTensor(decoder_input)
target = torch.LongTensor(target)
return encoder_input, decoder_input, target
# 使用 make_data 函数生成输入、输出和目标张量
encoder_input, decoder_input, target = make_data(sentences)
for s in sentences: # 获取原始句子
if all([word2idx_cn[w] in encoder_input[0] for w in s[0].split()]):
original_sentence = s
break
print(" 原始句子:", original_sentence) # 打印原始句子
print(" 编码器输入张量的形状:", encoder_input.shape) # 打印输入张量形状
print(" 解码器输入张量的形状:", decoder_input.shape) # 打印输出张量形状
print(" 目标张量的形状:", target.shape) # 打印目标张量形状
print(" 编码器输入张量:", encoder_input) # 打印输入张量
print(" 解码器输入张量:", decoder_input) # 打印输出张量
print(" 目标张量:", target) # 打印目标张量
3. 定义编码器和解码器类
import torch.nn as nn # 导入 torch.nn 库
# 定义编码器类,继承自 nn.Module
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size):
super(Encoder, self).__init__()
self.hidden_size = hidden_size # 设置隐藏层大小
self.embedding = nn.Embedding(input_size, hidden_size) # 创建词嵌入层
self.rnn = nn.RNN(hidden_size, hidden_size, batch_first=True) # 创建 RNN 层
def forward(self, inputs, hidden): # 前向传播函数
embedded = self.embedding(inputs) # 将输入转换为嵌入向量
output, hidden = self.rnn(embedded, hidden) # 将嵌入向量输入 RNN 层并获取输出
return output, hidden
# 定义解码器类,继承自 nn.Module
class Decoder(nn.Module):
def __init__(self, hidden_size, output_size):
super(Decoder, self).__init__()
self.hidden_size = hidden_size # 设置隐藏层大小
self.embedding = nn.Embedding(output_size, hidden_size) # 创建词嵌入层
self.rnn = nn.RNN(hidden_size, hidden_size, batch_first=True) # 创建 RNN 层
self.out = nn.Linear(hidden_size, output_size) # 创建线性输出层
def forward(self, inputs, hidden): # 前向传播函数
embedded = self.embedding(inputs) # 将输入转换为嵌入向量
output, hidden = self.rnn(embedded, hidden) # 将嵌入向量输入 RNN 层并获取输出
output = self.out(output) # 使用线性层生成最终输出
return output, hidden
n_hidden = 128 # 设置隐藏层数量
# 创建编码器和解码器
encoder = Encoder(voc_size_cn, n_hidden)
decoder = Decoder(n_hidden, voc_size_en)
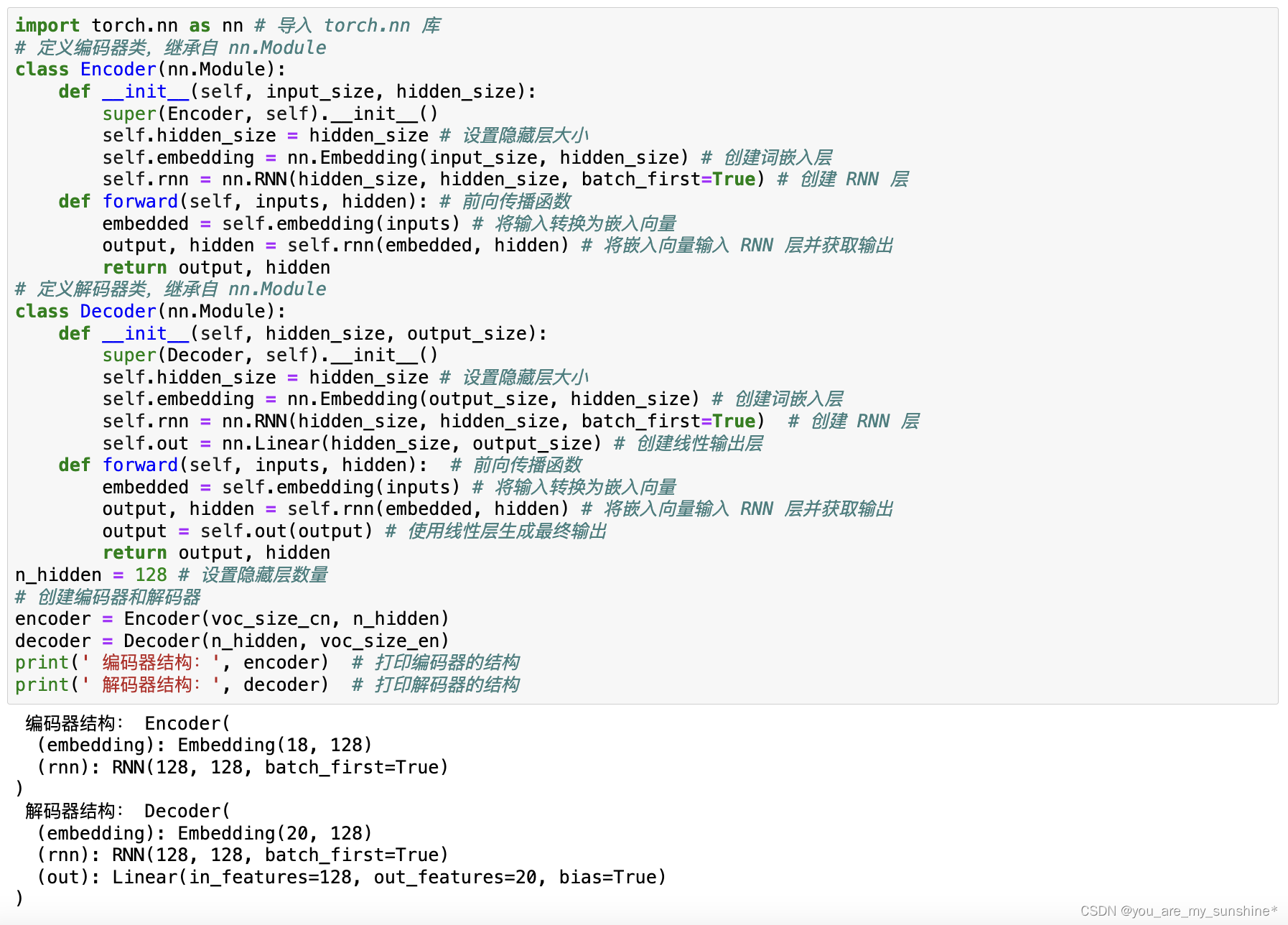
print(' 编码器结构:', encoder) # 打印编码器的结构
print(' 解码器结构:', decoder) # 打印解码器的结构
专注于编码器和解码器各自的功能,同时使代码更具可读性和可维护性。此外,替换不同的编码器和解码器也很方便,从而能够实现更多样化的模型结构。
可以调整的地方很多,比如通过调整input_size和output_size参数(即输入输出维度),可以使它们适应不同的源语言和目标语言的词汇表大小。又如RNN层的个数,当前我们只使用了一个RNN层,但根据需要,可以在RNN的构造函数中设置 num_layers参数,堆叠多个RNN层,增加模型的复杂性和容量。还可以使用其他类型的RNN层,如LSTM 层或GRU层,来替换RNN层,帮助模型更好地捕获长距离依赖关系。此外,也可以在RNN的构造函数中设置bidirectional=True参数,来使用双向 RNN 捕获输入序列中的前后信息。当然,使用双向RNN 时需要调整隐藏状态的形态以适应双向结构。
编码器和解码器有output、hidden两个输出的作用是什么?
- output:每个时间步(每个输入的序列元素)的输出。对于一般的RNN来说,output通常就是hidden;但对于某些更复杂的模型,如LSTM来说, output可能会与 hidden有所不同。在你的代码中,output可以被视为对输入序列中每个元素的编码。
- hidden:RNN的隐藏状态,保存了至当前步骤的所有历史信息。在标准的 RNN中,hidden状态由前一个时间步的hidden状态和当前时间步的输入共同决定。这种机制使得hidden状态能够捕获和记住序列的时间依赖性。
在Seq2Seq架构中,编码器的作用是将源语言句子编码成一个向量,而解码器则以此向量为输入,生成目标语言的句子。在这个过程中,编码器的hidden 状态被用作解码器的初始hidden 状态,作为对整个源语言句子的总结,被解码器用来生成第一个目标语言单词。
编码器的 output通常用于刚才我提到的注意力机制,这是一种在解码器生成每个单词时选择性地查看输入句子的不同部分的技术,可以帮助模型更好地处理长句子和复杂的语言结构。这个简单的Seq2Seq架构并没有真正意义上地使用到编码器的 output。
4.定义Seq2Seq架构
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder):
super(Seq2Seq, self).__init__()
# 初始化编码器和解码器
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_input, hidden, dec_input): # 定义前向传播函数
# 使输入序列通过编码器并获取输出和隐藏状态
encoder_output, encoder_hidden = self.encoder(enc_input, hidden)
# 将编码器的隐藏状态传递给解码器作为初始隐藏状态
decoder_hidden = encoder_hidden
# 使解码器输入(目标序列)通过解码器并获取输出
decoder_output, _ = self.decoder(dec_input, decoder_hidden)
return decoder_output
# 创建 Seq2Seq 架构
model = Seq2Seq(encoder, decoder)
print('S2S 模型结构:', model) # 打印模型的结构

这段代码定义了一个类,用于处理输入序列并生成输出序列。这个类继承自PyTorch的nn.Module,使其成为一个自定义的深度学习模型。在这个类中,主要完成了以下操作。
-
___init__方法:这是类的构造函数,用于初始化Seq2Seq架构。传入已经定义好的编码器和解码器对象。然后将这两个对象分别赋值给类的实例变量self encoder和 self.decoder。这样,我们可以在类的其他方法中使用这两个子模型。
-
forward 方法:forward是类的前向传播函数,它定义了如何将输入序列enc_input传递给编码器和解码器以生成输出序列。这个函数接收3个参数:编码器输入序列 enc_input、初始隐藏状态hidden和解码器输入序列dec_input,具体操作如下。
-
(1)将输入序列传递给编码器,并获得编码器的输出和隐藏状态(encoder output, encoder_hidden )。
-
(2)将编码器的隐藏状态作为解码器的初始隐藏状态(decoder_hidden= encoder_hidden )。
-
(3)将解码器输入序列,也就是目标序列和解码器的初始隐藏状态传递给解码器,以获取解码器的输出(decoder_output,_)。这里的下划线表示我们不关心解码器返回的隐藏状态,因为我们只需要输出序列。
-
(4)返回解码器的输出decoder_output。这个输出可以用来计算损失,优化模型,并生成翻译后的句子。
在定义前向传播函数的代码def forward(self,enc_input, hidden, dec_input)中,参数dec_input接收的实际上是目标序列的信息。可是通常来说,我们是不会在前向传播部分把目标值输入网络的呀。只有在反向传播,计算损失的时候,才需要目标值嘛,这是“教师强制”。
教师强制是训练Seq2Seq架构的一种常用技术。使用该技术,要向解码器提供真实的目标序列中的词作为输入,而不是使用解码器自身生成的词。这样可以帮助模型更快地收敛,并在训练时获得更好的性能。
5. 训练Seq2Seq架构
# 定义训练函数
def train_seq2seq(model, criterion, optimizer, epochs):
for epoch in range(epochs):
encoder_input, decoder_input, target = make_data(sentences) # 训练数据的创建
hidden = torch.zeros(1, encoder_input.size(0), n_hidden) # 初始化隐藏状态
optimizer.zero_grad()# 梯度清零
output = model(encoder_input, hidden, decoder_input) # 获取模型输出
loss = criterion(output.view(-1, voc_size_en), target.view(-1)) # 计算损失
if (epoch + 1) % 1000 == 0: # 打印损失
print(f"Epoch: {epoch + 1:04d} cost = {loss:.6f}")
loss.backward()# 反向传播
optimizer.step()# 更新参数
# 训练模型
epochs = 5000 # 训练轮次
criterion = nn.CrossEntropyLoss() # 损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 优化器
train_seq2seq(model, criterion, optimizer, epochs) # 调用函数训练模型

这是训练模型的标准过程,与你之前看到的大同小异。在train_seq2seq函数中,每个epoch 都会随机选择一个句子进行训练。首先,为这个句子创建输入批次、输出批次和目标批次。然后初始化模型的隐藏状态,并将梯度清零。接着,将输入批次、隐藏状态和输出批次传递给模型,获取模型的输出。计算模型输出和目标批次之间的损失,并在每100个epoch后打印损失值。最后,执行反向传播及参数更新。
代码中的 encoder_input是模型的输入数据,hidden用于初始化 RNN,这两个张量我们已经十分了解。而decoder_input是专属于 Seq2Seq架构的训练数据。刚才我已经说明了,这些数据用于进行教师强制,是在训练时故意暴露给解码器的内容。
6.测试Seq2Seq架构
# 定义测试函数
def test_seq2seq(model, source_sentence):
# 将输入的句子转换为索引
encoder_input = np.array([[word2idx_cn[n] for n in source_sentence.split()]])
# 构建输出的句子的索引,以 '<sos>' 开始,后面跟 '<eos>',长度与输入句子相同
decoder_input = np.array([word2idx_en['<sos>']] + [word2idx_en['<eos>']]*(len(encoder_input[0])-1))
# 转换为 LongTensor 类型
encoder_input = torch.LongTensor(encoder_input)
decoder_input = torch.LongTensor(decoder_input).unsqueeze(0) # 增加一维
hidden = torch.zeros(1, encoder_input.size(0), n_hidden) # 初始化隐藏状态
predict = model(encoder_input, hidden, decoder_input) # 获取模型输出
predict = predict.data.max(2, keepdim=True)[1] # 获取概率最大的索引
# 打印输入的句子和预测的句子
print(source_sentence, '->', [idx2word_en[n.item()] for n in predict.squeeze()])
# 测试模型
test_seq2seq(model, '哒哥 喜欢 爬山')
test_seq2seq(model, '我 爱 学习 人工智能')

在test_seq2seq函数中,首先将输入的句子转换为索引,并构建输出的句子的索引,以开始,后面跟,长度与输入句子相同。
为什么在这里,使用一个和一系列符号来构建 decoder_input呢?
进行教师强制是因为要在训练的时候,使模型更快地跟“老师”学会要翻译的内容。现在已经进入测试阶段,我就是要看看模型能否脱离“老师”自己翻译,当然不能再“喂”它真实的目标输出了,那不就完全体现不出模型的翻译能力了嘛。
通过不断的探索和改进,Seq2Seq架构也在不断地发展和完善,即将出现的编码器-解码器注意力机制,将进一步优化基于Seq2Seq架构的模型的性能。
归纳
从NPLM到Seq2Seq,NLP研究人员不断探索更有效的建模方法来捕捉自然语言的复杂性。
NPLM使用神经网络来学习词嵌入表示,并预测给定上文的下一个词。NPLM用连续向量表示词,捕捉到了单词之间的语义和语法关系。尽管NPLM性能有所提高,但仍然存在一些局限性,例如上下文窗口的大小是固定的。
为了解决上下文窗口大小固定的问题,研究人员开始使用RNN来处理可变长度的序列。RNN 可以在处理序列时保持内部状态,从而捕捉长距离依赖关系。然而,RNN在训练中容易出现梯度消失和梯度爆炸问题。
为了解决梯度消失和梯度爆炸问题,LSTM和 GRU等门控循环单元被提出。它们引入了门控机制,可以学习长距离依赖关系,同时缓解梯度消失和梯度爆炸问题。
在此之后,又出现了Seq2Seq这种序列到序列的编码器-解码器架构,渐渐取代了单一的 RNN。编码器将输入序列编码成一个固定大小的向量,解码器则解码该向量,从而生成输出序列。Seq2Seq架构可以处理不等长的输入和输出序列,因此在机器翻译、文本摘要等任务中表现出色。
基于RNN的Seq2Seq架构存在一些缺点,例如难以处理长序列(长输入序列可能导致信息损失)和复杂的上下文相关性等。具体来讲,在一个长序列中,一些重要的上下文信息可能会被编码成一个固定长度的向量,因此在解码过程中,模型难以正确地关注到所有重要信息。为了提高Seq2Seq架构的性能,研究人员发现向编码器一解码器架构间引入注意力机制,可以帮助Seq2Seq架构更好地处理长序列和上下文相关性。通过给予不同时间步(也就是token)的输入不同的注意力权重,可以让模型更加关注与当前时间步(也就是当前token)相关的信息。
Seq2Seq编码器-解码器架构小结
优势:
编码器将输入序列编码成一个固定大小的向量,解码器则解码该向量,从而生成输出序列。Seq2Seq架构可以处理不等长的输入和输出序列,因此在机器翻译、文本摘要等任务中表现出色。
劣势:
难以处理长序列(长输入序列可能导致信息损失)和复杂的上下文相关性。
学习的参考资料:
(1)书籍
利用Python进行数据分析
西瓜书
百面机器学习
机器学习实战
阿里云天池大赛赛题解析(机器学习篇)
白话机器学习中的数学
零基础学机器学习
图解机器学习算法
动手学深度学习(pytorch)
…
(2)机构
光环大数据
开课吧
极客时间
七月在线
深度之眼
贪心学院
拉勾教育
博学谷
慕课网
海贼宝藏
…
![[机器学习]K-means——聚类算法](https://img-blog.csdnimg.cn/direct/cfe264aecec147118f4418f5794bff14.png)