文章目录
- HTTP
- 抓包工具FIddler
- **HTTP请求**
- **HTTP响应**
- 认识URL
- URL encode
- 认识"方法"(method)
- 1.GET方法
- 使用Fiddler观察GET请求
- 2.POST方法
- 使⽤Fiddler观察POST⽅法
- 经典面试题:GET和POST有啥区别
- 请求报头(header)
- Host
- Content-Length
- Content-Type
- User-Agent(简称UA)
- Referer
- Cookie
HTTP
HTTP(全称为"超⽂本传输协议")是⼀种应⽤⾮常⼴泛的应⽤层协议.
HTTP协议最主要的应用场景就是网站,浏览器和服务器之间传输数据
客户端(手机,PC)和服务器也有可能是HTTP
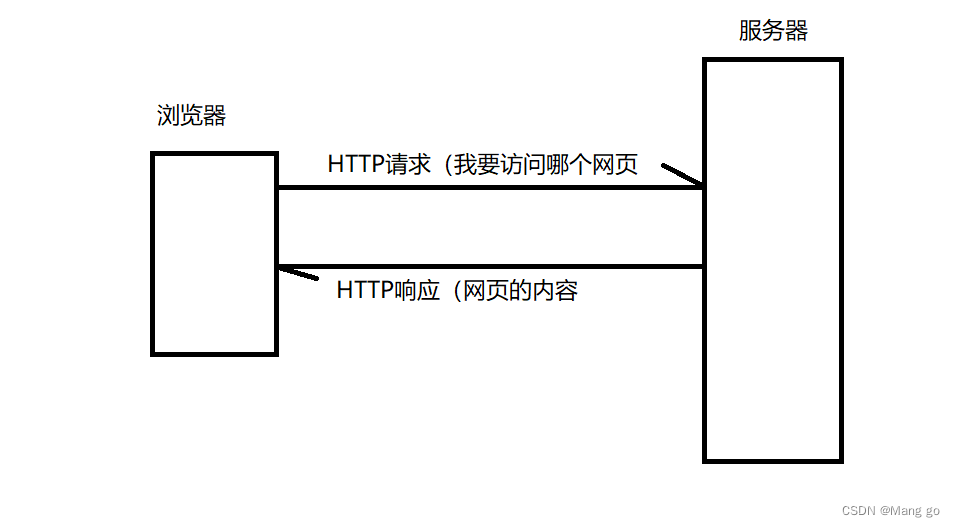
HTTP协议的交互是典型的一问一答
HTTP是⼀个⽂本格式的协议.可以通过Chrome开发者⼯具或者Fiddler抓包,分析HTTP请求/响应的细节.
抓包工具FIddler
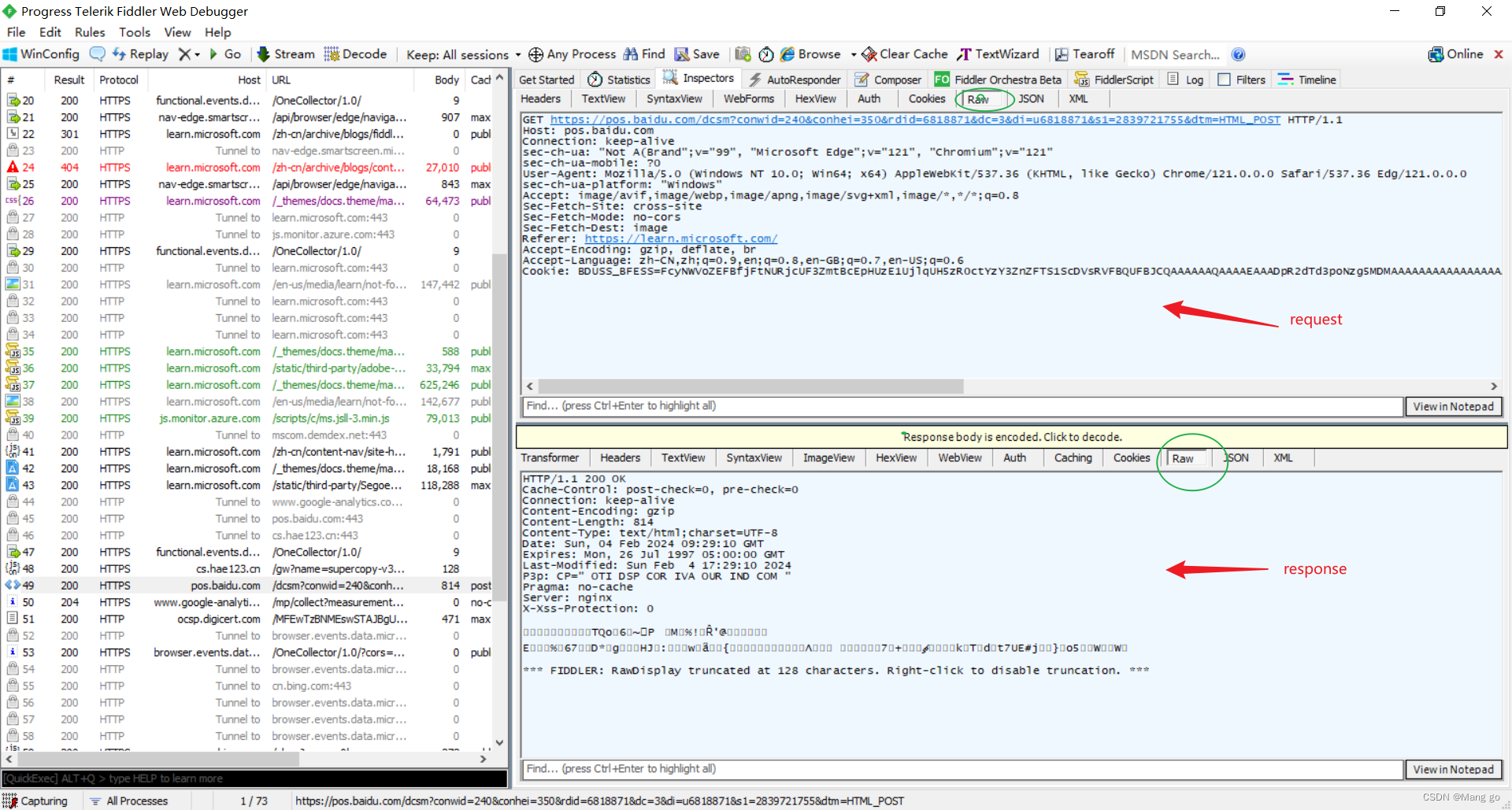
• 左侧窗⼝显⽰了所有的HTTP请求/响应,可以选中某个请求查看详情.
• 右侧上⽅显⽰了HTTP请求的报⽂内容.(切换到Raw标签⻚可以看到详细的数据格式)
• 右侧下⽅显⽰了HTTP响应的报⽂内容.(切换到Raw标签⻚可以看到详细的数据格式)
• 请求和响应的详细数据,可以通过右下⻆的 View in Notepad 通过记事本打开.
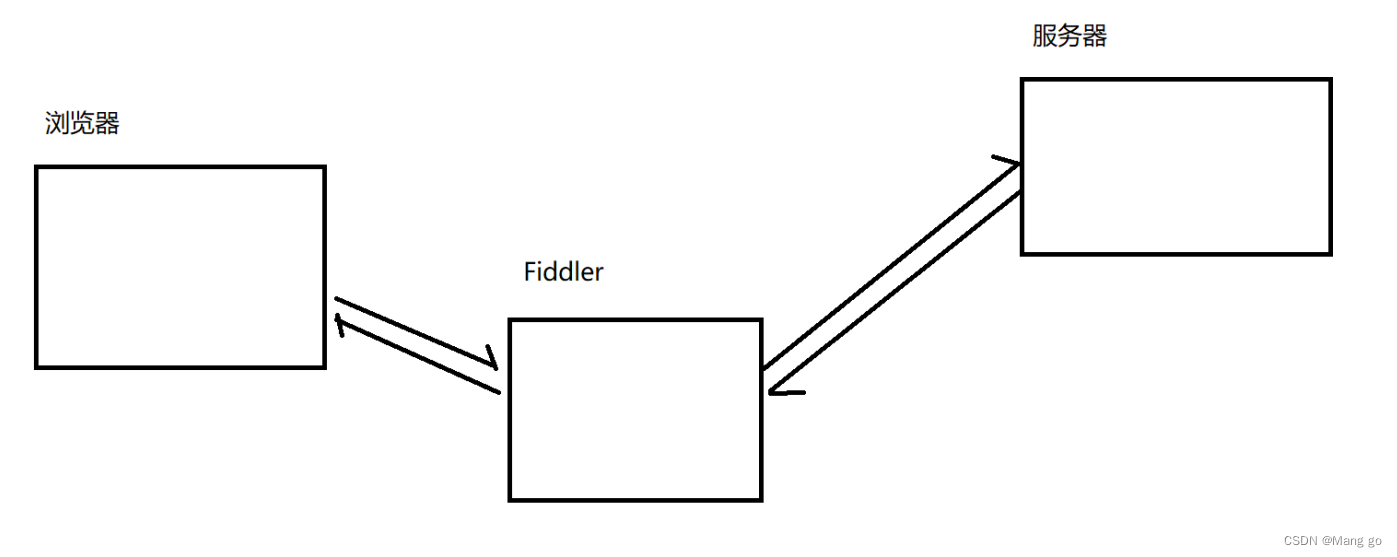
Fiddler相当于⼀个"代理".
浏览器访问sogou.com时,就会把HTTP请求先发给Fiddler,Fiddler再把请求转发给sogou的服务器.当sogou服务器返回数据时,Fiddler拿到返回数据,再把数据交给浏览器.
因此Fiddler对于浏览器和sogou服务器之间交互的数据细节,都是⾮常清楚的.
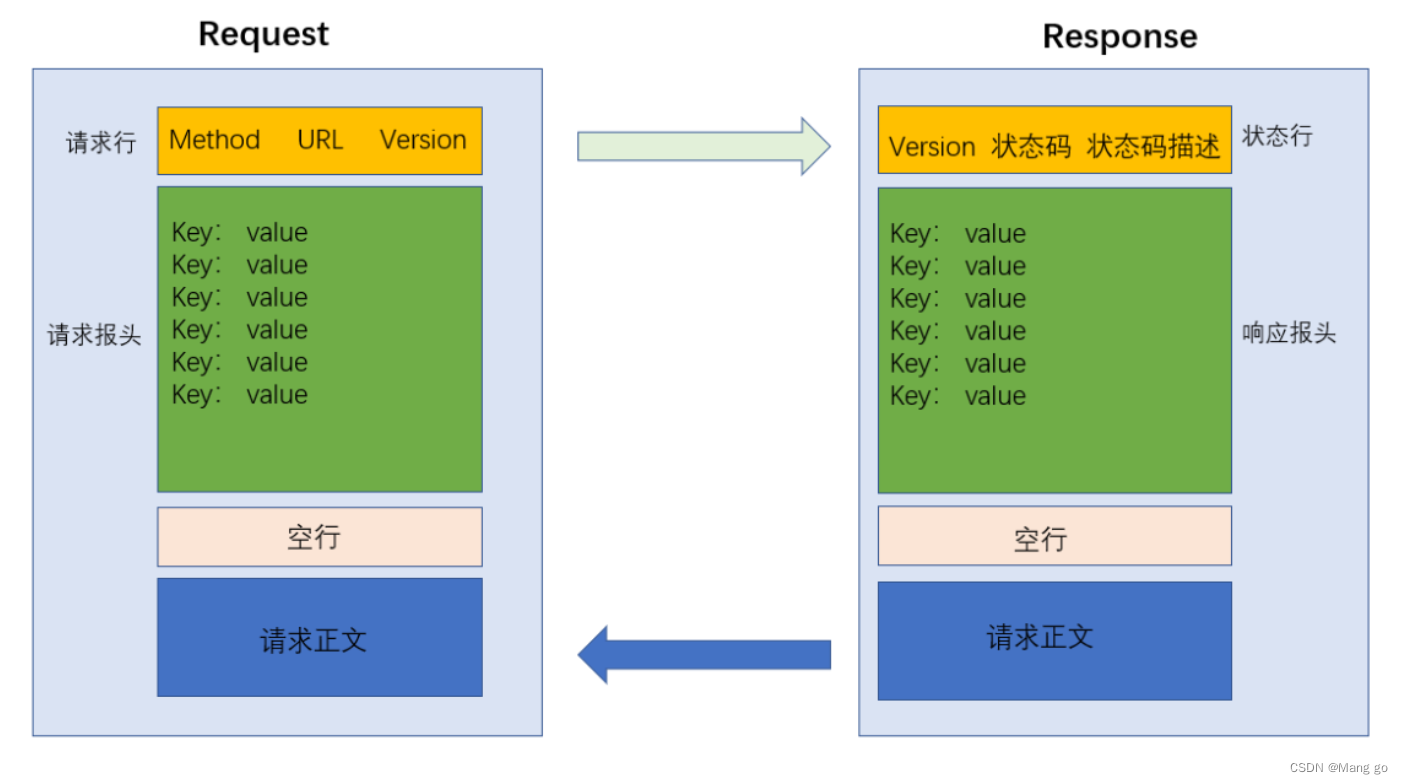
HTTP请求
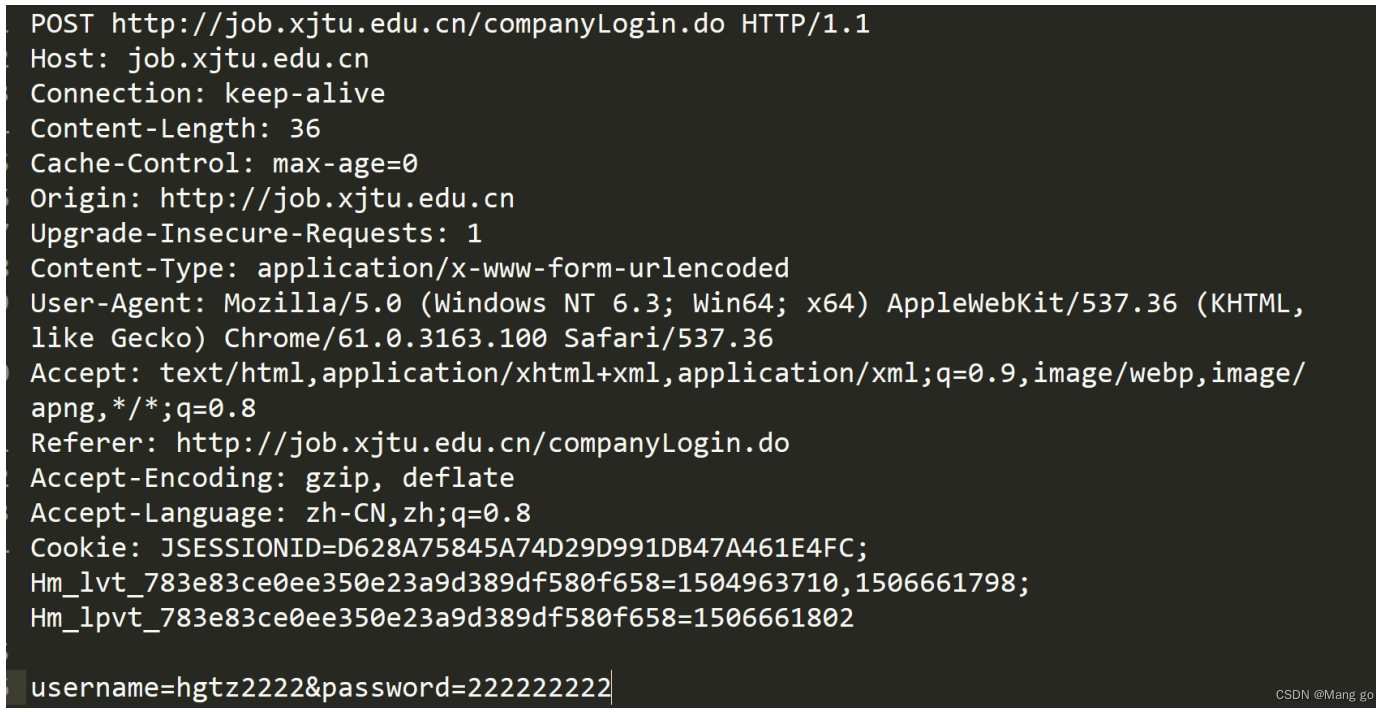
- 首行:[⽅法]+[url]+[版本]
- Header:请求的属性,冒号分割的键值对;每组属性之间使⽤\n分隔;遇到空行表示Header部分结束
- 空行:请求头最下面会有一个空行,这一行就可以表示结束标记
- 正文(Body):空⾏后⾯的内容都是Body.Body允许为空字符串.如果Body存在,则在Header中会有⼀个Content-Length属性来标识Body的⻓度;
HTTP响应
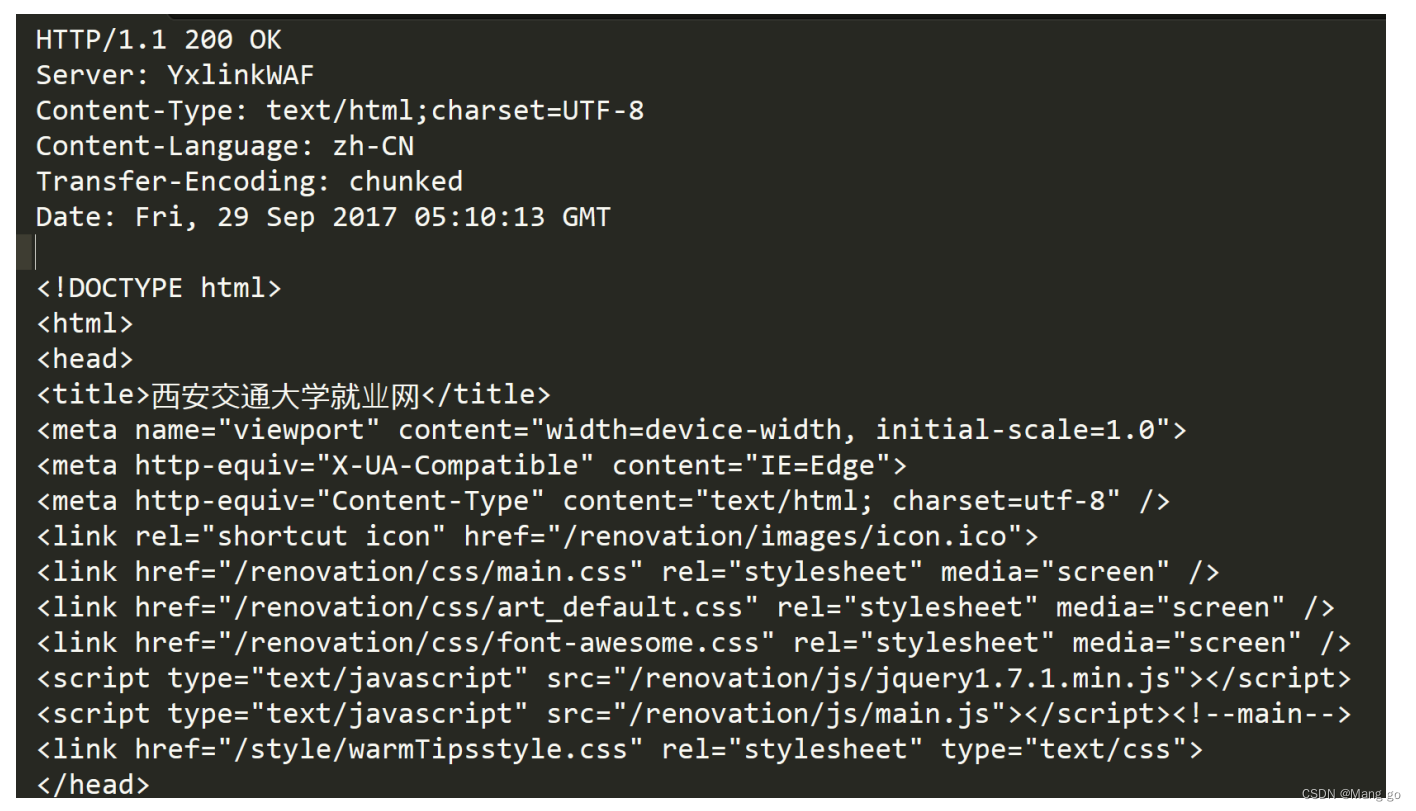
- ⾸⾏:[版本号]+[状态码]+[状态码解释]
- Header:请求的属性,冒号分割的键值对;每组属性之间使⽤\n分隔;遇到空⾏表⽰Header部分结束
- 空行:请求头最下面会有一个空行,这一行就可以表示结束标记
- Body:空⾏后⾯的内容都是Body.Body允许为空字符串.如果Body存在,则在Header中会有⼀个Content-Length属性来标识Body的⻓度;如果服务器返回了⼀个html⻚⾯,那么html⻚⾯内容就是在body中.
认识URL
URL是描述一个网络上的资源位置,唯一资源定位符
互联⽹上的每个⽂件都有⼀个唯⼀的URL,它包含的信息指出⽂件的位置以及浏览器应该怎么处理它.

- 登录信息:写在这里不太安全,现在都是通过“单独的登陆页面”来完成身份验证的
- 服务器地址,服务器端口号:如果url中不带端口号,浏览器就会自动给一个默认的端口
- 带层次的文件路径:这里可能会对应一个真实的硬盘文件,也可能会对应一个虚拟的文件
- 查询字符串:针对请求的内容做的补充说明
- 片段标识符:用来标识当前页面的某个部分,通过不同的片段标识可以完成页面内的跳转
网络上的资源位置:
a)通过IP地址知道服务器在哪
b)通过端口号知道程序是哪个
c)通过路径知道是访问哪个资源
URL encode
像/ ?:等这样的字符,已经被url当做特殊意义理解了.因此这些字符不能随意出现.
⽐如,某个参数中需要带有这些特殊字符,就必须先对特殊字符进⾏转义.
⼀个中⽂字符由UTF-8或者GBK这样的编码⽅式构成,虽然在URL中没有特殊含义,但是仍然需要进⾏转义.否则浏览器可能把UTF-8/GBK编码中的某个字节当做URL中的特殊符号.
认识"方法"(method)
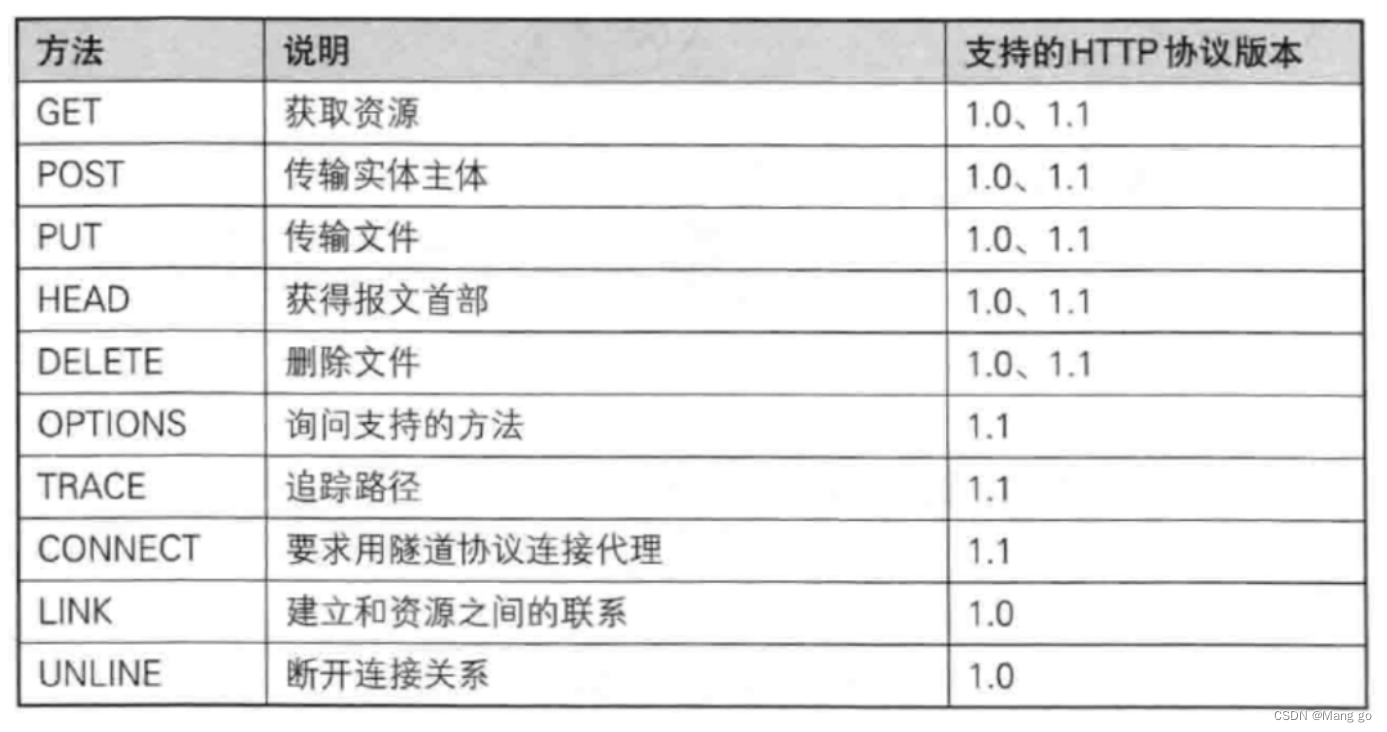
1.GET方法
GET是最常⽤的HTTP⽅法.常⽤于获取服务器上的某个资源.
在浏览器中直接输⼊URL,此时浏览器就会发送出⼀个GET请求.
另外,HTML中的link,img,script等标签,也会触发GET请求.
使用Fiddler观察GET请求
打开Fiddler,访问搜狗主⻚,观察抓包结果.
观察请求的详细结果
GET https://www.sogou.com/ HTTP/1.1
Host: www.sogou.com
Connection: keep-alive
Cache-Control: max-age=0
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
sec-ch-ua-mobile: ?0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/w
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: SUID=19AA8B7B6E1CA00A000000005F9A2F76; SUV=1603940214073598; pgv_pvi=266
GET请求的特点
• ⾸⾏的第⼀部分为GET
• URL的query string可以为空,也可以不为空.
• header部分有若⼲个键值对结构.
• body部分为空.
2.POST方法
POST⽅法也是⼀种常⻅的⽅法.多⽤于提交⽤⼾输⼊的数据给服务器(例如登陆页面).
通过HTML中的form标签可以构造POST请求,或者使⽤JavaScript的ajax也可以构造POST请求
使⽤Fiddler观察POST⽅法
在⽐特教务系统的登陆⻚⾯,输⼊⽤⼾名,密码,验证码之后,点击登陆,就可以看到POST请求.
点击这个请求,查看请求详情
POST https://v.bitedu.vip/tms/login HTTP/1.1
Host: v.bitedu.vip
Connection: keep-alive
Content-Length: 105
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
sec-ch-ua-mobile: ?0
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
Access-Control-Allow-Methods: PUT,POST,GET,DELETE,OPTIONS
Content-Type: application/json;charset=UTF-8
Access-Control-Allow-Origin: *
Accept: application/json, text/plain, */*
Access-Control-Allow-Headers: Content-Type, Content-Length, Authorization, Accep
Origin: https://v.bitedu.vip
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: https://v.bitedu.vip/login
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: username=123456789; rememberMe=true
{"username":"123456789","password":"xxxx","code":"jw7l","uuid":"d110a05ccde64b16
POST请求的特点
• ⾸⾏的第⼀部分为POST
• URL的query string⼀般为空(也可以不为空)
• header部分有若⼲个键值对结构
• body部分⼀般不为空.body内的数据格式通过header中的 Content-Type 指定.body的⻓度由header中的 Content-Length 指定.
经典面试题:GET和POST有啥区别
GET和POST本质上没有区别,使用GET的场景,也可以替换成POST
使用POST的场景,也可以替换成GET
但是在使用习惯上还是有区别的
- GET习惯于把数据放到url的query string中,POST习惯于把数据放到body中,GET也是可以放到body,POST也是可以放到query string
- 关于幂等性,标准文档中,建议GET请求实现成幂等的(每次输出的内容一定,输出的结果也一定),POST则无要求
- 语义上的区别,标准文档中,GET的语义是用来获取数据,POST的语义是给服务器传输数据
- GET请求是可以被浏览器收藏夹收藏的,POST请求不可以
网上有些相关的资料,说法不太准确
-
POST比GET更安全
论据:登录的时候,如果使用GET,用户名密码就会显示在url,此时就会被别人直接看到,所以不安全
解释:
即使是POST数据没有显示在url,也是可以被黑客通过抓包获取的,真正保证安全性的关键在于加密,如果数据加密了,就算放到url也是安全的 -
GET传输的数据量小(存在上限),POST传输的数据量更大
解释:
这说的是以前,实际上HTTP标准文档上明确说了,对于GET,URL的长度不做限制,目前比较长的URL也是很常见 -
GET只能携带文本数据,POST则可以携带二进制数据
解释:
这个说法不能说是完全错误,确实有一定的局限性的,URL通过query string 来携带数据,query string是只能包含文本的,但是可以对二进制数据进行urlencode,自然就成了文本了,到了服务器自然进行urlencode,就能把数据还原成二进制
PSOT请求body中也经常不是直接携带二进制,也有很多时候是对二进制数据进行urlencode/base64等方式进行转码
请求报头(header)
Host
表示服务器主机的地址和端口
Content-Length
表示body中的数据长度
通过这个长度来处理粘包问题,HTTP底层也是基于TCP,连续传输多个HTTP数据报,此时接收方这边的接收缓冲区里就会积累多个包的数据,应用程序在读取这些数据的时候就需要明确包之间的边界
Content-Type
表示请求的body中的数据格式
body可以传输很多种格式,包括程序员也可以自己约定任意的格式
User-Agent(简称UA)
表⽰浏览器/操作系统的属性.
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
其中Windows NT 10.0; Win64; x64 表⽰操作系统信息
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77
Safari/537.36 表⽰浏览器信息.
Referer
表示这个页面是从哪个页面跳转过来的.形如
https://v.bitedu.vip/login
如果直接在浏览器中输⼊URL,或者直接通过收藏夹访问页面时是没有Referer的.
Cookie
Cookie本质上是一个浏览器这边本地持久化存储数据的机制
- Cookie从哪里来?
服务器返回给浏览器的,通常都是首次访问/登陆成功之后 - Cookie到哪里去?
Cookie会存储在浏览器本地主机硬盘上,后续每次访问服务器都会带上Cookie,不同的客户端,保存的Cookie是不同的,即使是同意主机,使用不同的浏览器,Cookie大概率也是不同的 - Cookie中存什么?
键值对格式的数据,这里的内容都是程序员自定义的,和query string一样外人无从理解 - Cookie在浏览器这边如何组织?
在硬盘本地保存,是按照不同的域名为维度分别存储 - Cookie的用途是什么?
用来在客户端保存数据,其中最主要的是保存用户的身份标识,服务器就可以通过标识来区别用户