在上一篇redis源码之:集群创建与节点通信(1)我们可知,在集群中,cluster节点之间,通过meet将对方加入到本方的cluster->nodes列表中,并在后续过程中,不断通过clusterSendPing发送ping请求,使用gossip协议共享集群节点信息并通过clusterReadHandler处理对方发送的ping请求和pong响应。本文,来继续看看,clusterSendPing和clusterReadHandler的处理逻辑。
一、clusterSendPing
1.1、分享集群节点信息节点个数计算
clusterSendPing主要是为了将本方已知的集群节点信息共享到对方,但是redis并不是一次就把所有已知节点信息共享到对方:

1、freshnodes,是本方节点已知的所有集群节点中,除去本方和对方两个节点后的其余节点。
需要向对方发送的节点个数时wanted,通过计算本方已知节点数(包含本方对方节点)/10,这个数不能小于3,也不能大于freshnodes。
2、为什么要floor(dictSize(server.cluster->nodes)/10)总节点数除以10?
首先在clusterCron中,当检测到最近一次的ping的pong响应时间超过cluster_node_timeout/2会马上重发一次ping。
同时,在clearNodeFailureIfNeeded中会有两个timeout的fail状态修复时间:#define CLUSTER_FAIL_UNDO_TIME_MULT 2
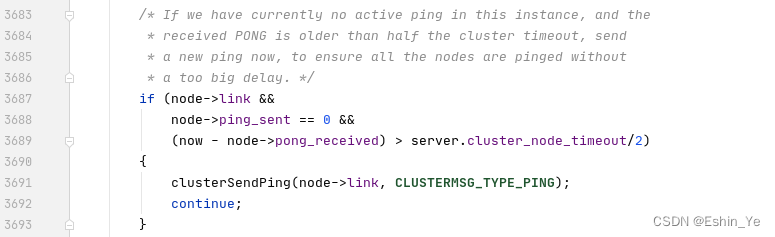

因此在cluster_node_timeout时间里,最差本方也会发送到对方两次ping到对方,因此会收到两次pong。同时对方在这段时间内也会发至少两次ping。因此本方在cluster_node_timeout内会最差收到四次对方发的包,在redis中cluster_node_timeout*2的故障检测时间内,本方能接收某个对方节点8个包,设置为每次发送1/10,就能保证在两个timeout时间内,至少能发送80%的几点信息共享。当然,这也是redis官方的一个取舍。
3、标注疑似下线的节点个数,本方发现的疑似掉线的其他主节点,全部在本次就告知对方。
1.2、生成分享信息头


1.3、gossip协议节点数据封装

1.4、疑似下线节点处理
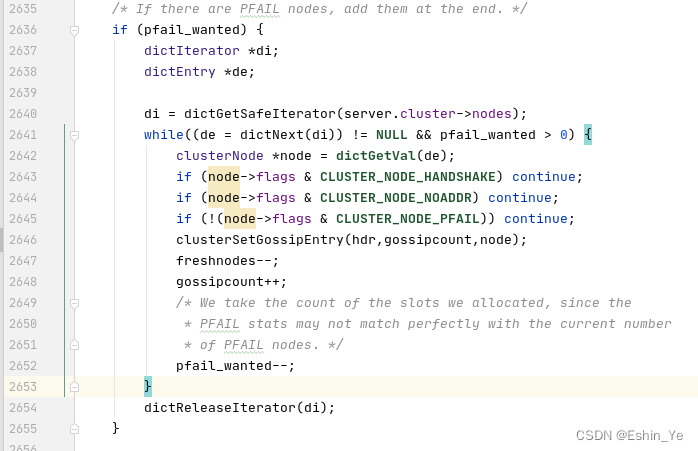
将疑似下线的节点信息一个个添加到gossip数组中
1.5、发送hdr到对方节点

二、clusterReadHandler处理ping请求与pong响应
clusterReadHandler涉及两种信息处理:
一种是本方主动连接对方,向对方发送ping后,对方响应的pong信息;
一种是对方连接本方,向本方发送的ping消息;
clusterReadHandler很长一段是读取消息的代码,读完数据后,进入clusterProcessPacket处理:
接收到的消息类型可能有,ping/pong /meet/fail/等信息,不同的信息对应的结构体不一样,根据对应的结构体获取数据。
我们先主要看ping/pong /meet三种信息的处理:

上面调用clusterProcessGossipSection()主要处理未知节点发送的gossip内容




此时调用clusterProcessGossipSection()是处理已知节点的gossip内容,
接下来看看clusterProcessGossipSection的处理逻辑:
三、clusterProcessGossipSection

因此gossip消息的处理,一定是要正常握手之后,确认发送方式集群确定的节点后才能在本地的cluster->nodes中添加节点实例。