1、hash算法使用场景
一般情况下hash算法主要用于:负载均衡(nginx 请求转发,scg路由等),分布式缓存分区,数据库分库分表(mycat,shardingSphere)等。
2、hash算法大致实现
变量%固定值
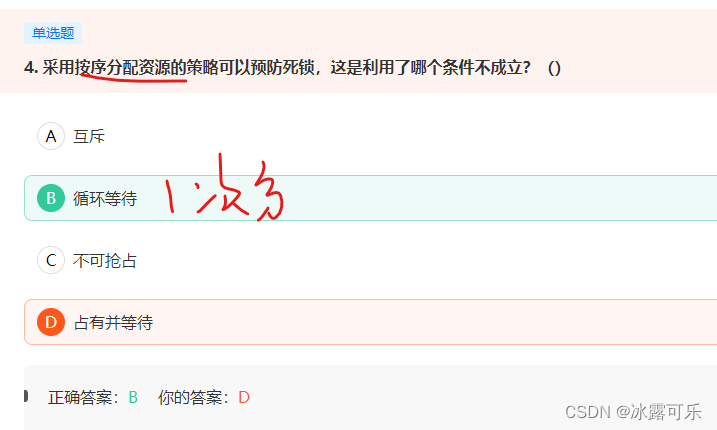
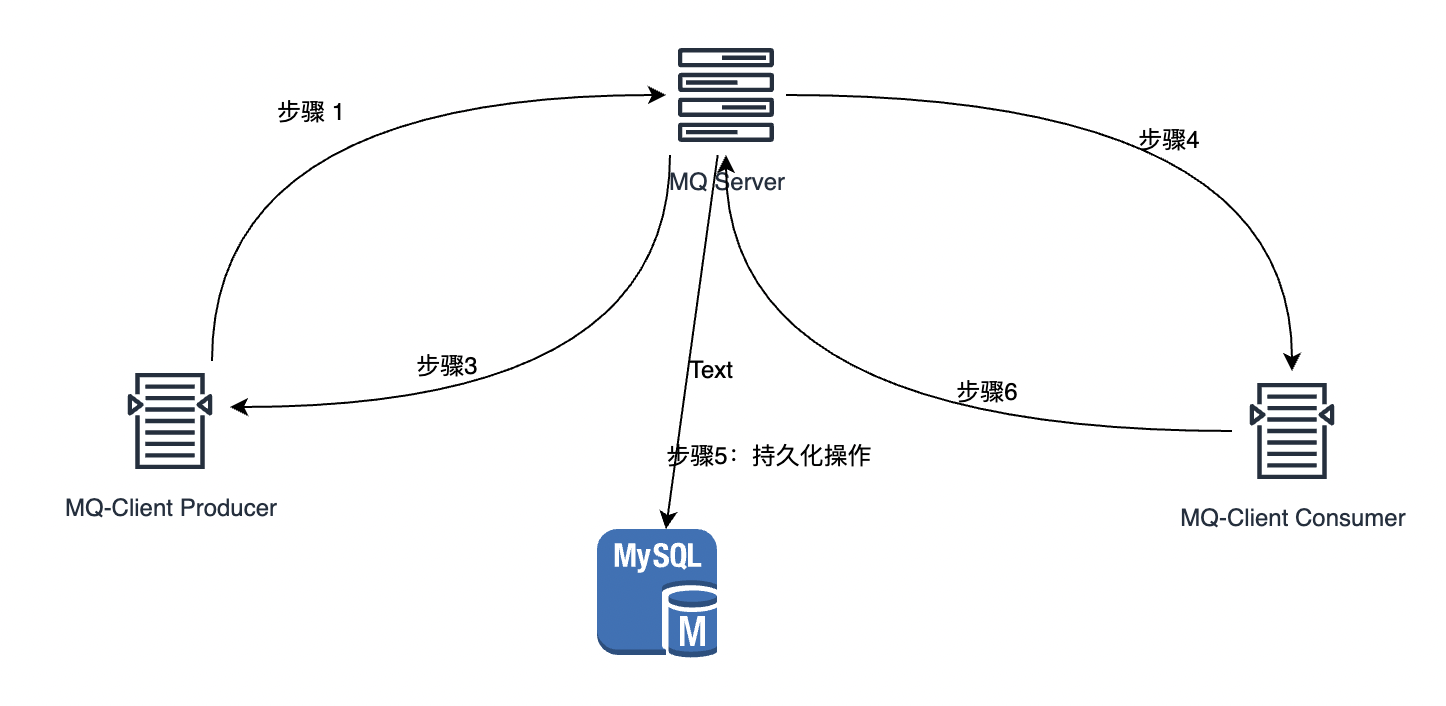
目的是将目标值锁定在固定值内
3、普通hash算法遇到的问题
普通hash算法计算会依赖于这个固定值
1、固定请求映射到固定服务器处理,可能导致某一时间段这个服务器很忙,其他服务器很闲,整体利用率低
2、如果固定值改变,之前的hash映射都将重新计算调整,这将会导致 动态扩缩容请求大量迁移,原本请求需要的数据无法使用(例如本地缓存,session)
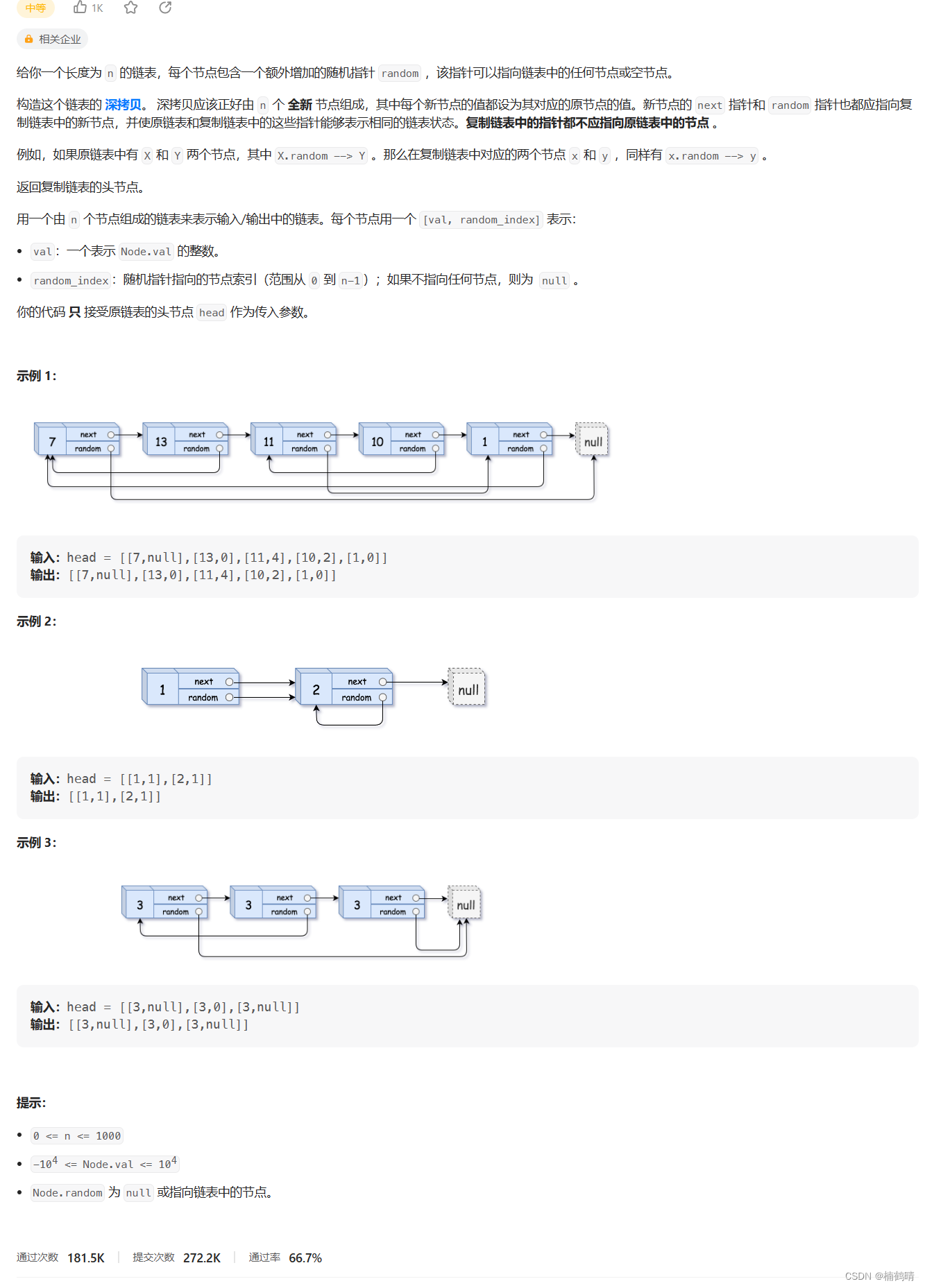
4、一致性hash算法原理
一致性哈希算法就很好地解决了分布式系统在扩容或者缩容时,发生过多的数据迁移的问题。
一致哈希算法也用了取模运算,但与哈希算法不同的是,哈希算法是对节点的数量进行取模运算,而一致哈希算法是对 2^32 进行取模运算,是一个固定的值。
原理如下:
1、假如存在3个节点,通过hash算法,将值定在hash环内
2、当请求过来,通过计算目的请求的hash值,将值定在hash环内
3、将请求 顺时针转发到目标节点
4、当某个节点失效时,会将请求自动转发到下一目标节点,请求迁移量小,节点影响小,增加节点同理
5、一致性hash算法存在的问题
1、缓存命中率降低及单一热点问题
一致性哈希解决的是某节点宕机后缓存失效的问题,只会导致相邻节点负载增加。但是因为宕机后需要重新从数据库读取,会导致此时缓存命中率下降及db压力增加。
也无法避免单一热点问题。某一数据被海量请求,不论怎么哈希,哈希环多大,数据只存在一个节点,早晚有被打垮的时候。
此时的解决策略是每个节点主备或主主集群。
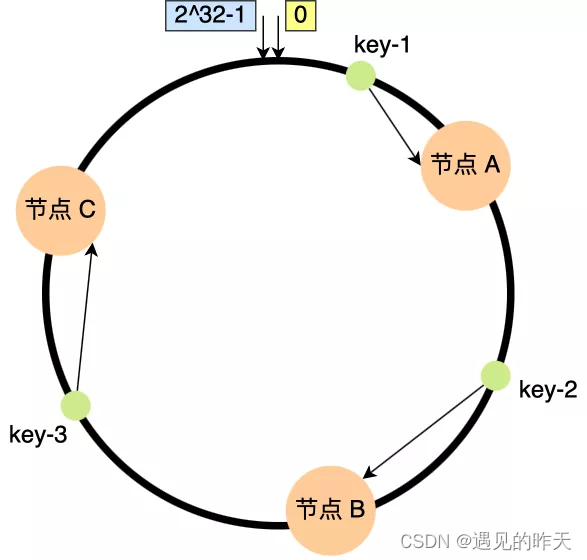
2、请求数据倾斜
一致性Hash算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,例如系统中只有两台服务器,其环分布如下:
此时必然造成大量数据集中到Node A上,而只有极少量会定位到Node B上。
解决方案
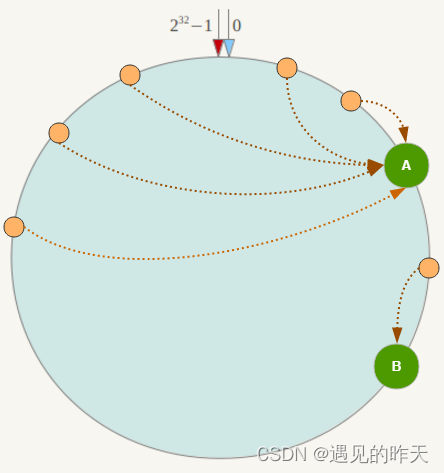
为了解决这种数据倾斜问题,一致性Hash算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点
例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,于是形成六个虚拟节点:
这样请求就会被负载均衡掉!
6、总结
一致性hash主要解决的还是 动态阔缩容下,请求大量迁移,数据读取或存储对目标节点影响降到最低。