🚩🚩🚩Transformer实战-系列教程总目录
有任何问题欢迎在下面留言
本篇文章的代码运行界面均在Pycharm中进行
本篇文章配套的代码资源已经上传
Vision Transformer 源码解读1
Vision Transformer 源码解读2
Vision Transformer 源码解读3
Vision Transformer 源码解读4
11、Encoder类------前向传播
class Encoder(nn.Module):
def forward(self, hidden_states):
# print(hidden_states.shape)
attn_weights = []
for layer_block in self.layer:
hidden_states, weights = layer_block(hidden_states)
if self.vis:
attn_weights.append(weights)
encoded = self.encoder_norm(hidden_states)
return encoded, attn_weights
hidden_states.shape = torch.Size([16, 197, 768])
encoded.shape = torch.Size([16, 197, 768])
- attn_weights ,用于存储注意力权重
- 循环处理每一个Block层
- 将隐藏状态传递给当前的Block层,获取处理后的隐藏状态和注意力权重
- 将注意力权重添加到attn_weights列表中
- 将最后一层的输出通过LayerNorm层进行归一化处理
- 返回归一化后的输出和(如果有的话)注意力权重列表
这段代码实现了一个编码器,能够处理序列数据并可选择性地输出每层的注意力权重,通过层层叠加的Block和最终的归一化处理,它能够有效地学习输入数据的特征表示
12、Block类------前向传播
class Block(nn.Module):
def forward(self, x):
h = x
x = self.attention_norm(x)
x, weights = self.attn(x)
x = x + h
h = x
x = self.ffn_norm(x)
x = self.ffn(x)
x = x + h
return x, weights
- x.shape = torch.Size([16, 197, 768]),输入数据
- h=x
- self.attention_norm(x).shape = torch.Size([16, 197, 768]),x经过一个层归一化,层归一化直接在torch中的nn中调用
- (h+self.attn(x)).shape = torch.Size([16, 197, 768])经过一个self-Attention,再加上前面的x,加上x是一个残差连接
- self.ffn_norm(x).shape = torch.Size([16, 197, 768]),再经过一个层归一化
- self.ffn(x).shape = torch.Size([16, 197, 768]),经过一个MLP类
- (x + h).shape = torch.Size([16, 197, 768]),再来一个残差连接
13、MLP类------前向传播
class Mlp(nn.Module):
def forward(self, x):
x = self.fc1(x)
x = self.act_fn(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.dropout(x)
return x
- x.shape = torch.Size([16, 197, 768]),原始输入
- x.shape = torch.Size([16, 197, 3072]),经过第1层全连接
- x.shape = torch.Size([16, 197, 3072]),经过gelu经过函数
- x.shape = torch.Size([16, 197, 3072]),经过第1次dropout
- x.shape = torch.Size([16, 197, 768]),经过第2层全连接
- x.shape = torch.Size([16, 197, 768]),经过第2次dropout
14、Attention类------前向传播
最重要的Attention类
class Attention(nn.Module):
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(self, hidden_states):
mixed_query_layer = self.query(hidden_states)#Linear(in_features=768, out_features=768, bias=True)
mixed_key_layer = self.key(hidden_states)
mixed_value_layer = self.value(hidden_states)
query_layer = self.transpose_for_scores(mixed_query_layer)
key_layer = self.transpose_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer)
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
attention_probs = self.softmax(attention_scores)
weights = attention_probs if self.vis else None
attention_probs = self.attn_dropout(attention_probs)
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
attention_output = self.out(context_layer)
attention_output = self.proj_dropout(attention_output)
return attention_output, weights
14.1 transpose_for_scores函数
x------torch.Size([16, 197, 12, 64])
new_x_shape------torch.Size([16, 197, 12, 64])
x.permute(0, 2, 1, 3)------torch.Size([16, 12, 197, 64])
transpose_for_scores函数将输入张量的最后一个维度拆分为num_attention_heads(注意力头数)和attention_head_size(每个头的大小),然后将维度重新排列以满足矩阵乘法的需求
14.2 前向传播
- hidden_states,torch.Size([16, 197, 768]),原始输入
- mixed_query_layer,torch.Size([16, 197, 768]),经过一层全连接生成Q向量,维度不变
- mixed_key_layer,torch.Size([16, 197, 768]),经过一层全连接生成K向量,维度不变
- mixed_value_layer,torch.Size([16, 197, 768]),经过一层全连接生成V向量,维度不变
- query_layer ,torch.Size([16, 12, 197, 64]),多头注意力的拆分,拆分12头,每头64维向量
- key_layer,torch.Size([16, 12, 197, 64]),多头注意力的拆分,拆分12头,每头64维向量
- value_layer,torch.Size([16, 12, 197, 64]),多头注意力的拆分,拆分12头,每头64维向量
- attention_scores ,torch.Size([16, 12, 197, 197]),q和k的内积结果
- attention_scores ,torch.Size([16, 12, 197, 197]),将注意力得分除以注意力头的大小的平方根进行缩放,防止梯度过小
- attention_probs ,softmax归一化
- weights ,如果开启可视化则保留注意力权重,否则不保留
- attention_probs , 对注意力权重应用dropout
- context_layer ,torch.Size([16, 12, 197, 64]),注意力权重重构v向量
- context_layer ,torch.Size([16, 197, 12, 64]),重新排列维度
- new_context_layer_shape ,计算重塑后的上下文表示形状
- context_layer ,torch.Size([16, 197, 768]),重塑上下文表示的形状,合并所有注意力头的输出,将多头进行还原
- attention_output ,torch.Size([16, 197, 768]),使用另一个线性层处理上下文表示,生成最终的注意力模块输出
- attention_output ,torch.Size([16, 197, 768]),使用另一个线性层处理上下文表示,生成最终的注意力模块输出
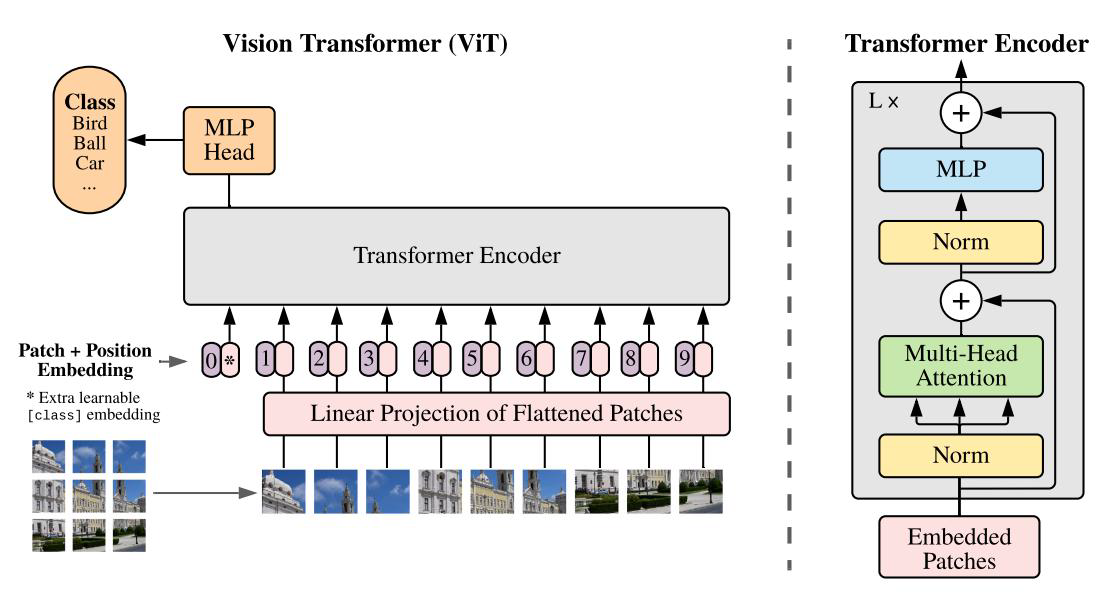
最后回顾一下ViT的网络架构:
Vision Transformer 源码解读1
Vision Transformer 源码解读2
Vision Transformer 源码解读3
Vision Transformer 源码解读4