更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
背景
随着 LLM 技术应用及落地,数据库需要提高向量分析以及 AI 支持能力,向量数据库及向量检索等能力“异军突起”,迎来业界持续不断关注。简单来说,向量检索技术以及向量数据库能为 LLM 提供外置的记忆单元,通过提供与问题及历史答案相关联的内容,协助 LLM 返回更准确的答案。
不仅仅是 LLM,向量检索也早已在 OLAP 引擎中应用,用来提升非结构化数据的分析和检索能力。ByteHouse 是火山引擎推出的云原生数据仓库,近期推出高性能向量检索能力,本篇将结合 ByteHouse 团队对向量数据库行业和技术的前沿观察,详细解读 OLAP 引擎如何建设高性能的向量检索能力。
负载特征
向量检索的目标是查找与给定向量最相似的 k 个结果,广泛用于以图搜图、推荐系统等场景。近两年,随着大模型的普及,而基于向量检索构建的大模型检索增强功能,能够显著改善大模型的结果准确率低的问题,得到了广泛的关注。因此,向量检索相关技术,以及基于向量检索的向量数据库的概念逐渐流行起来,成为数据库领域一个热门话题。
实际使用场景中,向量检索针对的数据集大小通常会在 million 甚至 billion 级别,而查询延迟通常会要求在数毫秒到百毫秒内返回,因此,通常不会使用 brute force 的方式进行计算,而是会使用具有特殊结构的向量检索索引的方式来计算,比较流行的向量索引算法有 HNSW、Faiss IVF 等。

这类基于向量索引的向量检索负载大概具有以下几个特点:
-
构建时间长,资源消耗大:索引的构建时间通常比较长,远大于数据插入的时间,以常用的 gist1M 数据集为例不同类型的索引构建时间大概需要几十秒甚至上百秒。此外,构建索引通常需要消耗较多的 CPU 及内存资源。因此,在实现向量检索功能时,需要考虑如何高效管理索引构建任务需要的资源,保证构建速度的同时,也不会影响其他任务的进行。
-
内存计算:HNSW、Faiss IVF 类索引都需要将索引结构全部读取到内存中,而索引结构通常会包含有所有向量数据的原始数据以及一些额外的结构相关数据,因此其大小通常会大于向量数据的总量,由于结构较大每次加载索引时间会比较长,对于查询低延迟和高 QPS 的需求场景通常需要索引常驻内存。因此,向量检索功能需要考虑如何支持内存计算,并考虑内存资源的高效管理。
-
融合查询:用户通常需要查询相近向量的很多其他属性信息,通常也需要结合一些标量过滤条件进行更符合预期的结果筛选。因此,向量检索功能需要考虑如何降低从向量检索到其他属性读取的额外开销,同时考虑如何与过滤语句结合。
设计思路
现有架构局限性分析
ByteHouse 当前已经有一整套 skip index 的实现。向量索引可以作为一种新型的 skip index 来引入使用。然而,原本的 skip index 体系并不能高效支持向量检索相关计算,主要体现在以下几点:
1 当前没有针对 skip index 的 cache 机制,因此无法保证向量索引常驻内存
2 当前 skip index 只用于查询计划执行前做 mark level 的过滤,过滤的结果需要通过额外的距离计算才能获取到 topK 的结果,而不是直接使用 skip index 计算的结果来获取,计算上存在冗余。
3 skip index 只能按照 mark 粒度(mark * granule)来进行构建,对于数据量较大的 data part 而言,会存在多个 skip index,带来更多的 IO 与计算的开销。
考虑到以上几点,我们认为现有的 skip index 架构不能支持高性能的向量检索计算,因此,我们重新针对向量检索场景设计了一套全新的架构方案。
整体架构
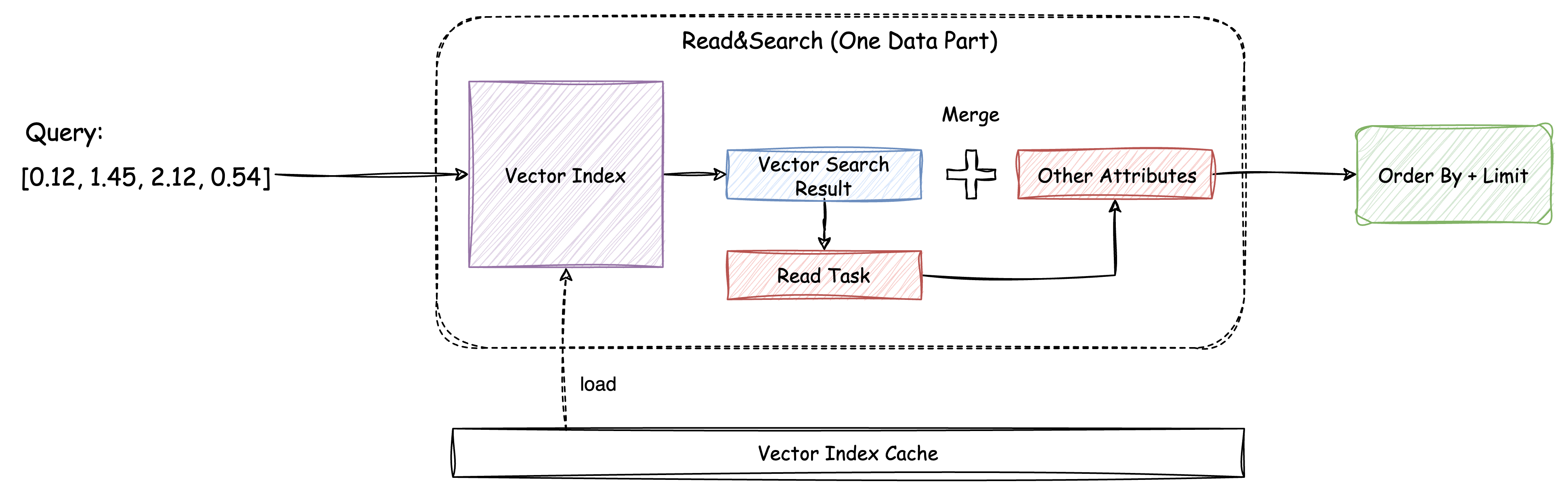
ByteHouse 的向量检索功能整体的架构如下图所示:

向量索引方面,我们接入了 hnswlib、faiss 两个比较流行的检索算法库,支持 HNSW、IVF_PQ、IVF_PQ_FS 等多种常用索引。另外,考虑到向量检索需要在内存中执行,还加入了向量索引缓存机制,确保查询涉及的 data part 的索引能够常驻内存,以实现低延迟的向量检索。
另外,我们基于现有 skip index 逻辑,添加了对应索引的构建语句支持,指定每个 data part 只构建一个索引。
考虑到构建资源消耗较高,在索引构建流程上,针对此类索引,添加了构建资源(CPU)控制机制,并且针对内存使用较大场景(IVF 类型索引的 train 方法),提供了 on disk 的构建逻辑。
查询执行方面,我们在查询的各个层次针对向量检索相关的查询进行了 Pattern 识别与 Query 改写,目前主要识别 order by L2Distance/cosineDistance + limit topK 相关查询,并针对向量检索的计算特点,实现了一个全新的 SelectWithSearch 算子来执行实际的向量检索与其他属性读取操作。
新旧执行链路比较如下:
Skip Index Based Pipeline

New Pipeline
构建语句例子如下:
CREATE TABLE test_ann(`id` UInt64,`label` String,`vector` Array(Float32),INDEX v1 vector TYPE HNSW('DIM=960, METRIC=COSINE'))ENGINE = MergeTreeORDER BY id
复制代码
查询语句例子如下:
selectid,label,distfrom test_annprewhere label = '...'order by cosineDistance(vector, [query_vector]) as distlimit 100
复制代码
优化
1 向量列读取操作消除:
-
识别向量列是否只在向量检索操作中需要,如果是,则在最终的读盘操作中,去掉向量列,减少不必要的读取操作
2 向量检索计算前置:
-
默认执行流程中,我们会为每个 data part 创建一个 SelectWithSearch 算子,计算时会针对单个 part 执行向量检索与其他属性的读取,由于读取任务最小的读取单元是一个 mark,这样的执行计划总的读取行数最大可为 (part_num * mark_size * topK) 行。造成的结果是性能会随 part 数量增多而不断下降。为了优化多 part 场景的查询性能,我们提出了一种向量检索前置的优化思路,即在执行计划实际执行之前,将所有 part 的向量检索全部先进行计算,得到全局的 topk 个结果,再进行各个 part 的其他属性读取,这样改造后,每次查询要读取的行数最高为 (mark_size * topK) ,实际场景测试中,latency 会有 2x 以上的提升。

3 Cache Preload
当前支持的向量索引需要加载到内存中以后才能进行高性能的向量检索计算。在查询执行到向量检索相关操作时,如果发现待计算的 data part 对应向量索引未存在与 vector index cache 中,则需要首先调用 load 操作将 index load 到内存中,查询则需要等待 load 结束后才能继续执行。vector index load 操作会显著增加查询的执行实现,尤其是对于新写入的 data part 或者 server 重新启动的场景。针对这个问题,我们添加了 cache preload 的机制,在 data part 生成后,以及 server 启动过程中,将 index load 自动到内存中,并且添加特定的 setting,支持 table level 以及 global 的 cache preload 配置。该机制为当前支持的 HaMergeTree、HaUniqueMergeTree 引擎都添加了支持。
性能评测
我们使用 VectorDBBench 对 ByteHouse 以及专用向量数据库 Milvus 进行了评测。ByteHouse 同等 recall 情况下,QPS 好于 Milvus,同时在数据插入时间上,也是优于 Milvus。

未来规划
当前已经实现了高性能向量数据库的基本框架,但是,在资源消耗、性能以及易用性上,仍有很多需要探索和改善的方面。后续 ByteHouse 将继续针对低资源消耗向量索引、查询性能优化、易用性、大模型生态等方面进行探索。
点击跳转ByteHouse了解更多