文章目录
- 基于Kaggle电信用户流失案例数据(可在官网进行下载)
- 数据解读与数据预处理
- 数据质量探索
- 变量相关性探索分析
基于Kaggle电信用户流失案例数据(可在官网进行下载)
数据解读与数据预处理
建议使用jupyter lab进行运行
import numpy as np
import pandas as pd
tcc = pd.read_csv('WA_Fn-UseC_-Telco-Customer-Churn.csv')
pd.set_option('max_colwidth',200)
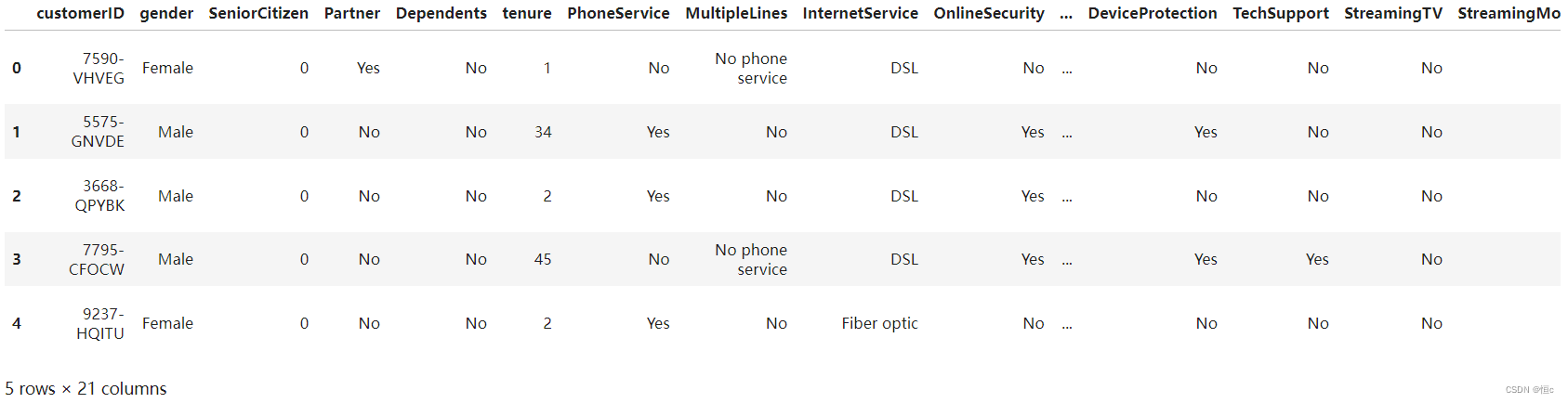
# 查看前五条数据
tcc.head(5)
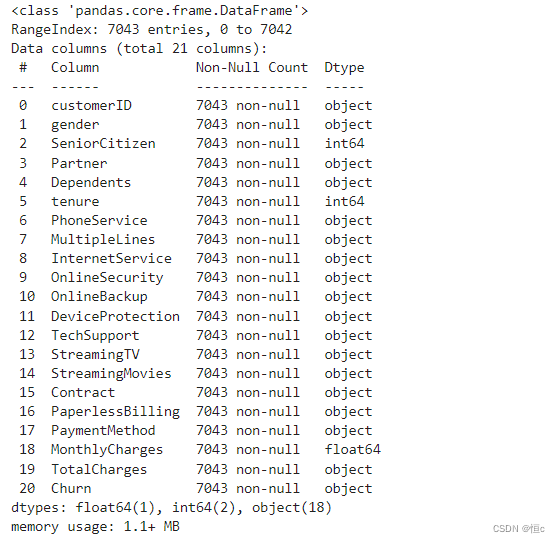
# 查看数据集信息(字段解释)
tcc.info()
| 字段 | 解释 |
|---|---|
| customerID | 用户ID |
| gender | 性别 |
| SeniorCitizen | 是否是老年人(1代表是) |
| Partner | 是否有配偶(Yes or No) |
| Dependents | 是否经济独立(Yes or No) |
| tenure | 用户入网时间 |
| PhoneService | 是否开通电话业务(Yes or No) |
| MultipleLines | 是否开通多条电话业务(Yes 、 No or No phoneservice) |
| InternetService | 是否开通互联网服务(No、DSL数字网络或filber potic光线网络) |
| OnlineSecurity | 是否开通网络安全服务(Yes、No or No internetservice) |
| OnlineBackup | 是否开通在线备份服务(Yes、No or No internetservice) |
| DeviceProtection | 是否开通设备保护服务(Yes、No or No internetservice) |
| TechSupport | 是否开通技术支持业务(Yes、No or No internetservice) |
| StreamingTV | 是否开通网络电视(Yes、No or No internetservice) |
| StreamingMovies | 是否开通网络电影(Yes、No or No internetservice) |
| Contract | 合同签订方式(按月、按年或者两年) |
| PaperlessBilling | 是否开通电子账单(Yes or No) |
| PaymentMethod | 付款方式(bank transfer、credit card、electronic check、mailed check) |
| MonthlyCharges | 月度费用 |
| TotalCharges | 总费用 |
| Churn | 是否流失(Yes or No) |
数据质量探索
- 数据集正确性校验
首先是数据集正确性校验。一般来说数据集正确性校验分为两种,其一是检验数据集字段是否和数据字典中的字段一致,其二则是检验数据集中ID列有无重复。由于该数据集并为提供数据字典,因此此处主要校验数据集ID有无重复:
#查看ID列是否有重复列
tcc['customerID'].nunique() == tcc.shape[0]
#或
tcc.duplicated().sum() # 返回值为0时说明没有重复行
- 数据缺失值检验
# 定义缺失值查看函数
def missing (df):
"""
计算每一列的缺失值及占比
"""
missing_number = df.isnull().sum().sort_values(ascending=False) # 每一列的缺失值求和后降序排序
missing_percent = (df.isnull().sum()/df.isnull().count()).sort_values(ascending=False) # 每一列缺失值占比
missing_values = pd.concat([missing_number, missing_percent], axis=1, keys=['Missing_Number', 'Missing_Percent']) # 合并为一个DataFrame
return missing_values
missing(tcc)
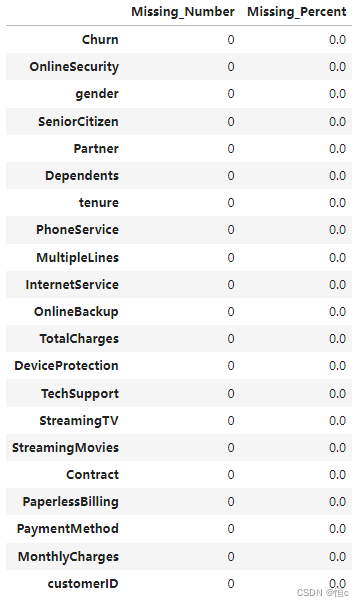
从上述结果看出数据集中不存在缺失值。
- 时序字段处理
tcc['tenure'].nunique( )
# 运行结果为73
该字段总共有73个不同的取值,结合此前所说,数据集是第三季度的用户数据,因此我们推断该字段应该是经过字典排序后的离散型字段。所谓字典排序,其本质是一种离散变量的转化方式,有时我们也可以将时序数据进行字典排序,该过程我们可以通过如下示例进行说明:
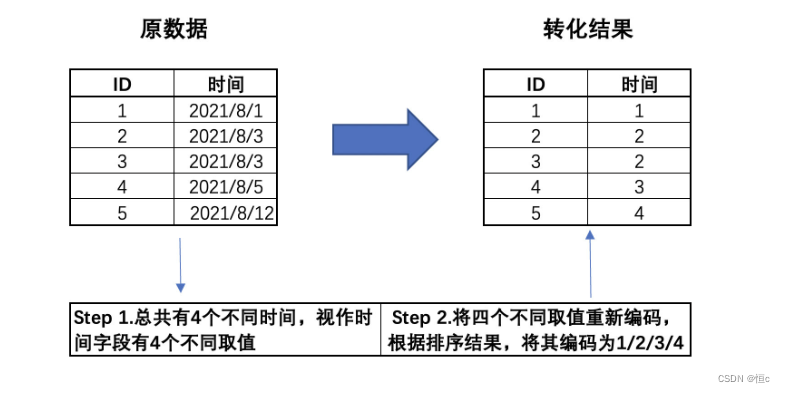
也就是说,在第三季度中,这些用户的行为发生在某73天内,因此入网时间字段有73个取值。不过由于该字段是经过字典排序后的结果,因此已经损失了原始信息,即每位用户实际的入网时间。而在实际的分析过程中,我们可以转化后的入网时间字段看成是离散变量,当然也可以将其视作连续变量来进行分析,具体选择需要依据模型来决定。此处我们先将其视作离散变量,后续根据情况来进行调整。
- 连续/离散型变量标注
接下来,我们来标注每一列的数据类型,我们可以通过不同列表来存储不同类型字段的名称:
# 离散字段
category_cols = ['customerID', 'gender', 'SeniorCitizen', 'Partner', 'Dependents', 'tenure',
'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup',
'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling',
'PaymentMethod']
# 连续字段
numeric_cols = ['MonthlyCharges', 'TotalCharges']
# 标签
target = 'Churn'
# 验证是否划分能完全
assert len(category_cols) + len(numeric_cols) + 1 == tcc.shape[1]
#当然,大多数时候离散型字段都在读取时都是object类型,因此我们也可以通过如下方式直接提取object字段:
tcc.select_dtypes('object').columns

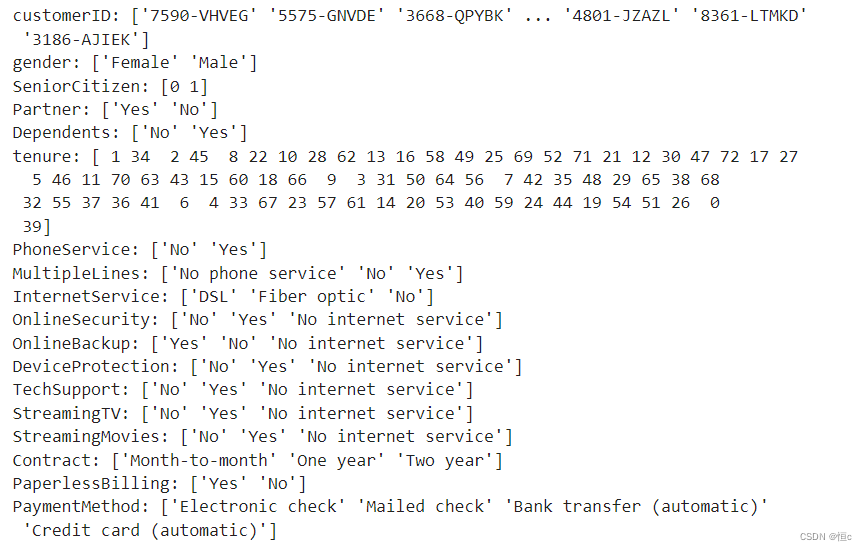
我们也可以通过如下方式查看每个离散变量的不同取值:
for feature in tcc[category_cols]:
print(f'{feature}: {tcc[feature].unique()}')
- 缺失值检验与填补
发现在连续特征中存在空格。则此时我们需要进一步检查空格字符出现在哪一列的哪个位置,我们可以通过如下函数来进行检验:
def find_index(data_col, val):
"""
查询某值在某列中第一次出现位置的索引,没有则返回-1
:param data_col: 查询的列
:param val: 具体取值
"""
val_list = [val]
if data_col.isin(val_list).sum() == 0:
index = -1
else:
index = data_col.isin(val_list).idxmax()
return index
# 查看空格第一次出现在哪一列的哪个位置:
for col in numeric_cols:
print(find_index(tcc[col], ' '))
我们也可以简单观察缺失’TotalCharges’信息的每条数据实际情况
tcc['TotalCharges']= tcc['TotalCharges'].apply(lambda x: x if x!= ' ' else np.nan).astype(float)
tcc['MonthlyCharges'] = tcc['MonthlyCharges'].astype(float)
tcc[tcc['TotalCharges'].isnull()]
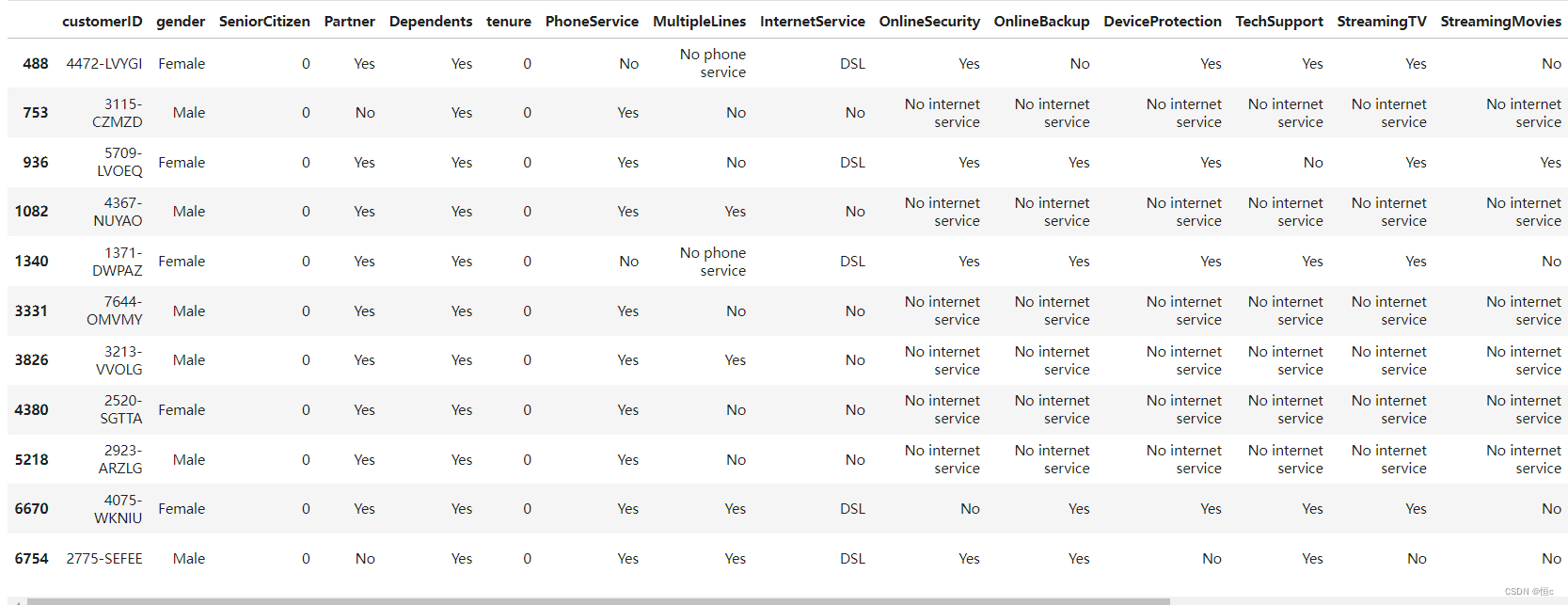
我们发现,这11条数据的入网时间都是0,也就是说,这11位用户极有可能是在统计周期结束前的最后时间入网的用户,因此没有过去的总消费记录,但是却有当月的消费记录。也就是说,该数据集的过去总消费记录不包括当月消费记录,也就是不存在过去总消费记录等于0的记录。既然如此,我们就可以将这11条记录的缺失值记录为0,以表示在最后一个月统计消费金额前,这些用户的过去总消费金额为0:
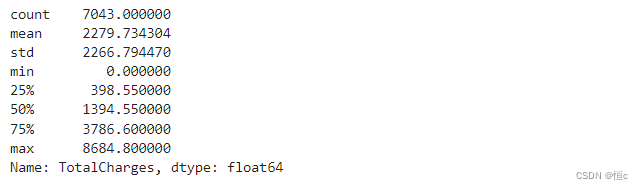
tcc['TotalCharges'] = tcc['TotalCharges'].fillna(0)
tcc['TotalCharges'].describe()
- 异常值检验
tcc[numeric_cols].describe()

异常值检测有很多方法,我们可以通过三倍标准差法来进行检验,即以均值-3倍标注差为下界,均值+3倍标准差为上界,来检测是否有超过边界的点:
tcc['MonthlyCharges'].mean() + 3 * tcc['MonthlyCharges'].std() # 155.03183375363483
tcc['MonthlyCharges'].mean() - 3 * tcc['MonthlyCharges'].std() # -25.5084488324364
tcc['TotalCharges'].mean() + 3 * tcc['TotalCharges'].std() # 9080.117712630885
tcc['TotalCharges'].mean() - 3 * tcc['TotalCharges'].std() # -4520.649105503233
对比上表格能够发现,数据集并不存在异常值点。
- 通过箱线图进行观察
此外,我们还可以通过箱线图来进行异常值点的识别,和3倍标准差法利用均值和方差进行计算不同,箱线图主要借助中位数和四分位数来进行计算,以上四分位数+1.5倍四分位距为上界、下四分位数-1.5倍四分位距为下界,超出界限则认为是异常值。我们可以借助plt.boxplot绘图函数迅速绘制箱线图来观察异常值点情况:
import seaborn as sns
import matplotlib.pyplot as plt
# MonthlyCharges上四分位数
Q3 = tcc[numeric_cols].describe()['MonthlyCharges']['75%'] # 89.95
# MonthlyCharges下四分位数
Q1 = tcc[numeric_cols].describe()['MonthlyCharges']['25%'] # 35.5
# # MonthlyCharges的四分位距
IQR = Q3 - Q1 # 54.349999999999994
# 异常值上界
Q3 + 1.5 * IQR # 171.375
# 异常值下界
Q1 - 1.5 * IQR # -46.02499999999999
tcc['MonthlyCharges'].min(), tcc['MonthlyCharges'].max() # (18.25, 118.75)
同理我们观察TotalCharges的性质
Q3 = tcc[numeric_cols].describe()['TotalCharges']['75%']
Q1 = tcc[numeric_cols].describe()['TotalCharges']['25%']
IQR = Q3 - Q1
(Q1 - 1.5 * IQR, Q3 + 1.5 * IQR) # (-4683.525, 8868.675)
tcc['TotalCharges'].min(), tcc['TotalCharges'].max() # (0.0, 8684.8)
不过需要知道的是,由于数据集中没有超出边界的异常值点,因此在实际绘制箱线图时,箱线图的边界会以数据集的极值为准:
plt.figure(figsize=(16, 6), dpi=200)
plt.subplot(121)
plt.boxplot(tcc['MonthlyCharges'])
plt.xlabel('MonthlyCharges')
plt.subplot(122)
plt.boxplot(tcc['TotalCharges'])
plt.xlabel('TotalCharges')

能够发现,根据箱线图的判别结果,数据并没有异常值出现。当然,此外我们还能通过连续变量的分布情况来观察是否存在异常值:
plt.figure(figsize=(16, 6), dpi=200)
plt.subplot(121)
sns.histplot(tcc['MonthlyCharges'], kde=True)
plt.subplot(122)
sns.histplot(tcc['TotalCharges'], kde=True)
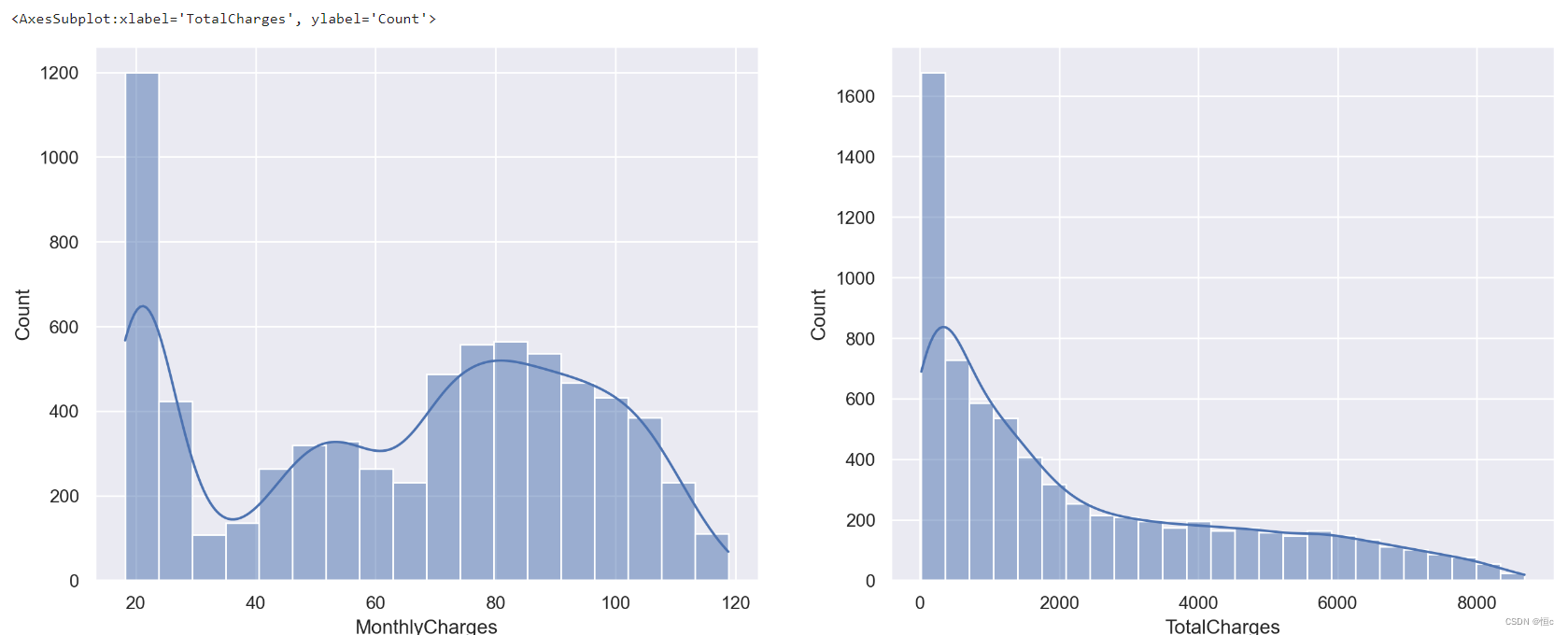
当然,通过上述图像我们也能基本看出月消费金额和总消费金额的基本分布情况,对于大多数用户来说月消费金额和总消费金额都较小,而月消费金额所出现的波动,极有可能是某些套餐的组合定价。
变量相关性探索分析
- 标签取值分布
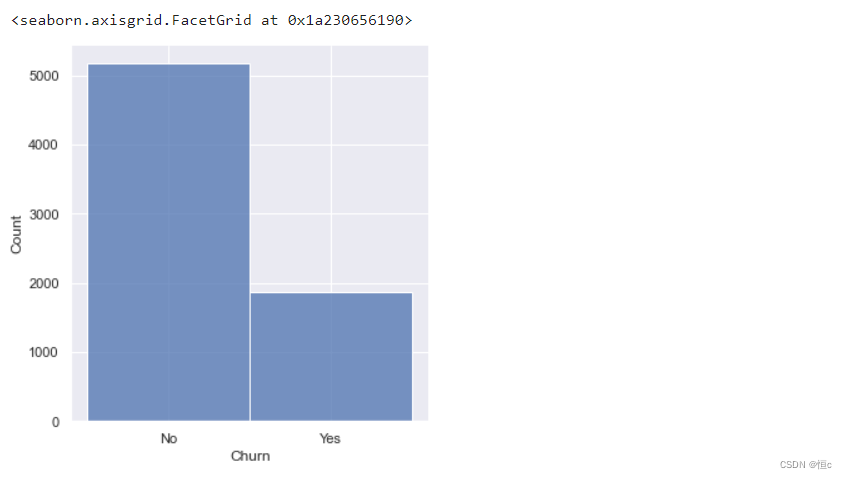
y = tcc['Churn']
print(f'Percentage of Churn: {round(y.value_counts(normalize=True)[1]*100,2)} % --> ({y.value_counts()[1]} customer)\nPercentage of customer did not churn: {round(y.value_counts(normalize=True)[0]*100,2)} % --> ({y.value_counts()[0]} customer)')
Percentage of Churn: 26.54 % --> (1869 customer)
Percentage of customer did not churn: 73.46 % --> (5174 customer)
也就是在总共7000余条数据中,流失用户占比约为26%,整体来看标签取值并不均匀,但如果放到用户流失这一实际业务背景中来探讨,流失用户比例占比26%已经是非常高的情况了。当然我们也可以通过直方图进行直观的观察:
sns.displot(y)
- 计算相关系数矩阵
当然,首先我们可以先计算相关系数矩阵,直接通过具体数值大小来表示相关性强弱。不过需要注意的是,尽管我们可以忽略变量的连续/离散特性,但为了更好的分析分类变量如何影响标签的取值,我们需要将标签转化为整型(也就是视作连续变量),而将所有的分类变量进行哑变量处理:
# 剔除ID列
df3 = tcc.iloc[:,1:].copy()
# 将标签Yes/No转化为1/0
df3['Churn'].replace(to_replace='Yes', value=1, inplace=True)
df3['Churn'].replace(to_replace='No', value=0, inplace=True)
# 将其他所有分类变量转化为哑变量,连续变量保留不变
df_dummies = pd.get_dummies(df3)
df_dummies.head()
 此处需要注意pd.get_dummies会将非数值类型对象类型进行自动哑变量转化,而对数值类型对象,无论是整型还是浮点型,都会保留原始列不变:
此处需要注意pd.get_dummies会将非数值类型对象类型进行自动哑变量转化,而对数值类型对象,无论是整型还是浮点型,都会保留原始列不变:
df_dummies[['Churn', 'tenure', 'MonthlyCharges', 'TotalCharges']]
# 然后即可采用.corr方法计算相关系数矩阵:
df_dummies.corr()
# 当然,在所有的相关性中,我们较为关注特征和标签之间的相关关系,
# 因此可以直接挑选标签列的相关系数计算结果,并进行降序排序:
df_dummies.corr()['Churn'].sort_values(ascending = False)
# 运行结果
# Churn 1.000000
# Contract_Month-to-month 0.405103
# OnlineSecurity_No 0.342637
# TechSupport_No 0.337281
# InternetService_Fiber optic 0.308020
# PaymentMethod_Electronic check 0.301919
# OnlineBackup_No 0.268005
# DeviceProtection_No 0.252481
# MonthlyCharges 0.193356
# PaperlessBilling_Yes 0.191825
# Dependents_No 0.164221
# SeniorCitizen 0.150889
# Partner_No 0.150448
# StreamingMovies_No 0.130845
# StreamingTV_No 0.128916
# StreamingTV_Yes 0.063228
# StreamingMovies_Yes 0.061382
# MultipleLines_Yes 0.040102
# PhoneService_Yes 0.011942
# gender_Female 0.008612
# gender_Male -0.008612
# MultipleLines_No phone service -0.011942
# PhoneService_No -0.011942
# MultipleLines_No -0.032569
# DeviceProtection_Yes -0.066160
# OnlineBackup_Yes -0.082255
# PaymentMethod_Mailed check -0.091683
# PaymentMethod_Bank transfer (automatic) -0.117937
# InternetService_DSL -0.124214
# PaymentMethod_Credit card (automatic) -0.134302
# Partner_Yes -0.150448
# Dependents_Yes -0.164221
# TechSupport_Yes -0.164674
# OnlineSecurity_Yes -0.171226
# Contract_One year -0.177820
# PaperlessBilling_No -0.191825
# TotalCharges -0.199484
# DeviceProtection_No internet service -0.227890
# StreamingMovies_No internet service -0.227890
# InternetService_No -0.227890
# OnlineSecurity_No internet service -0.227890
# StreamingTV_No internet service -0.227890
# TechSupport_No internet service -0.227890
# OnlineBackup_No internet service -0.227890
# Contract_Two year -0.302253
# tenure -0.352229
# Name: Churn, dtype: float64
需要知道的是,根据相关系数计算的基本原理,相关系数为正数,则二者为正相关,数值变化会更倾向于保持同步。例如Churn与Contract_Month-to-month相关系数为0.4,则说明二者存在一定的正相关性,即Contract_Month-to-month取值为1(更大)越有可能使得Churn取值为1。也就是在Contract字段的Month-to-month取值结果和最终流失的结果相关性较大,也就是相比其他条件,Contract取值为Month-to-month的用户流失概率较大,而tenure和Churn负相关,则说明tenure取值越大、用户流失概率越小。其他结果解读依此类推。
- 热力图展示相关性
当然,我们也可以通过一些可视化的方式来展示特征和标签之间的相关性,例如可以考虑使用热力图进行相关性的可视化展示:
plt.figure(figsize=(15,8), dpi=200)
sns.heatmap (df_dummies.corr())
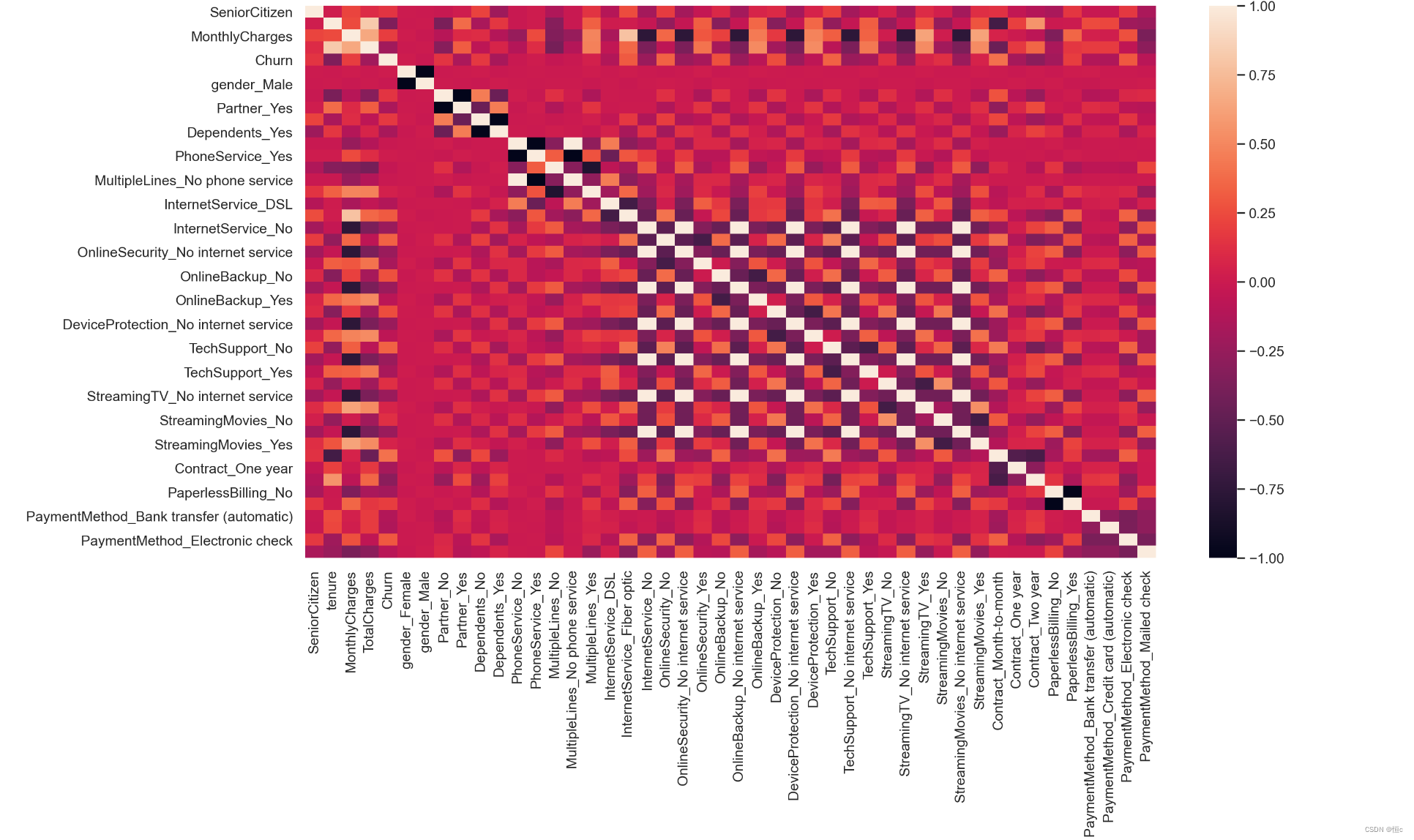
- 柱状图展示相关性
当然,很多时候如果特征较多,热力图的展示结果并不直观,此时我们可以考虑进一步使用柱状图来进行表示:
sns.set()
plt.figure(figsize=(15,8), dpi=200)
df_dummies.corr()['Churn'].sort_values(ascending = False).plot(kind='bar')