文章目录
- 前言
- 例子
- 结果
- 源码
前言
今天讨论一个问题,如果全部方法都加上事务,会不会有问题?
前两天看到一个老项目,xml方式的配置,拦截了所有的方法,增加了事务,不能说它的做法有问题,也不能说不对。
例子
下面hikari配置了一个连接池:
最大个数20个,获取链接等待5秒
spring:
application:
name: data-import
datasource:
url: jdbc:mysql://localhost:3306/data-import?useSSl=true&zeroDateTimeBehavior=convertToNull&characterEncoding=utf-8&serverTimezone=GMT%2B8
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
hikari:
minimum-idle: 5
idle-timeout: 1000
maximum-pool-size: 20
auto-commit: true
pool-name: datimportpool
max-lifetime: 1800000
connection-timeout: 5000
connection-test-query: SELECT 1
再增加一个接口
注意:这里我增加了线程睡眠时间,模拟业务处理慢的情况
@RestController
@RequestMapping("/test")
public class TestController {
@Transactional
@GetMapping("/get")
public Object get() throws InterruptedException {
TimeUnit.SECONDS.sleep(2);
return "xx";
}
}
结果
我们用jmeter压测看看
100的并发量,吞吐量只有14,并且还有异常的



异常就是获取connection超时:

我们查看下mysql它默认的链接数
# 查看mysql的最大链接数
show variables like '%max_connections%';
# 查看每个用户的最大链接数
show variables like 'max_user_connections';
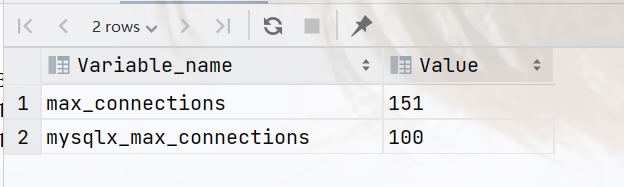
实际情况需要根据环境来进行配置,这里作为测试,修改应用的最大链接数到50



结论:
- 业务处理慢的接口,会占用连接池资源,导致后续接口的等待,严重的导致超时异常;
- 加入了事务的方法,不论是否使用了
jdbc,都会受限于数据库连接池的限制,也就是会产生性能瓶颈,虽然说连接池是为了提高系统性能,避免资源浪费,但是在业务处理慢的时候是相反的;
源码
上面我们是通过表象去看待问题,下面我们通过源码去看它的过程。
关于事务详细的源码分析看:spring源码篇(八)事务的原理-CSDN博客
spring事务有动态代理实现,实现逻辑在TransactionAspectSupport
org.springframework.transaction.interceptor.TransactionAspectSupport
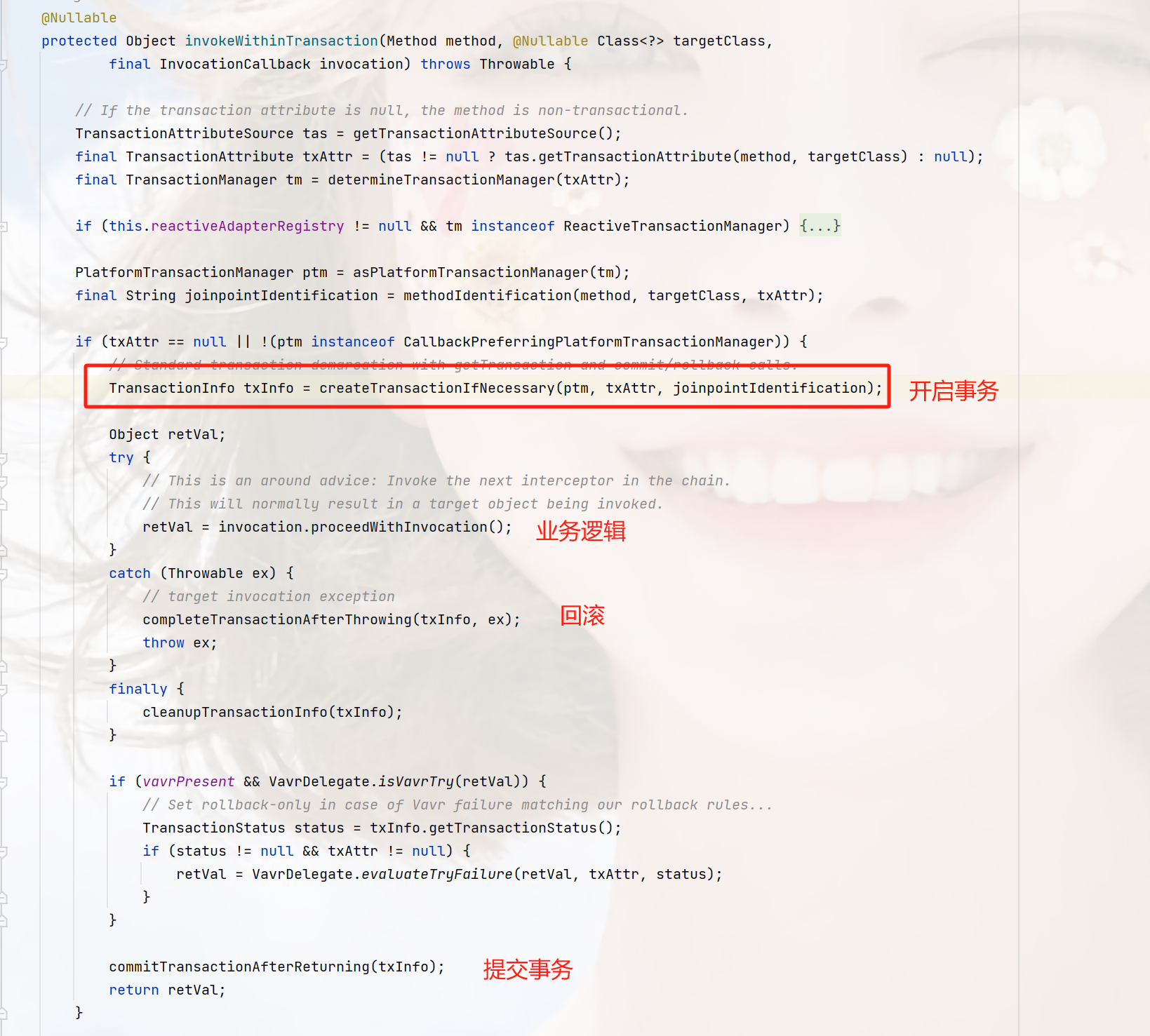
最后他会走到这个位置:
org.springframework.jdbc.datasource.DataSourceTransactionManager#doBegin
在这里他会通过dataSource获取一个connection
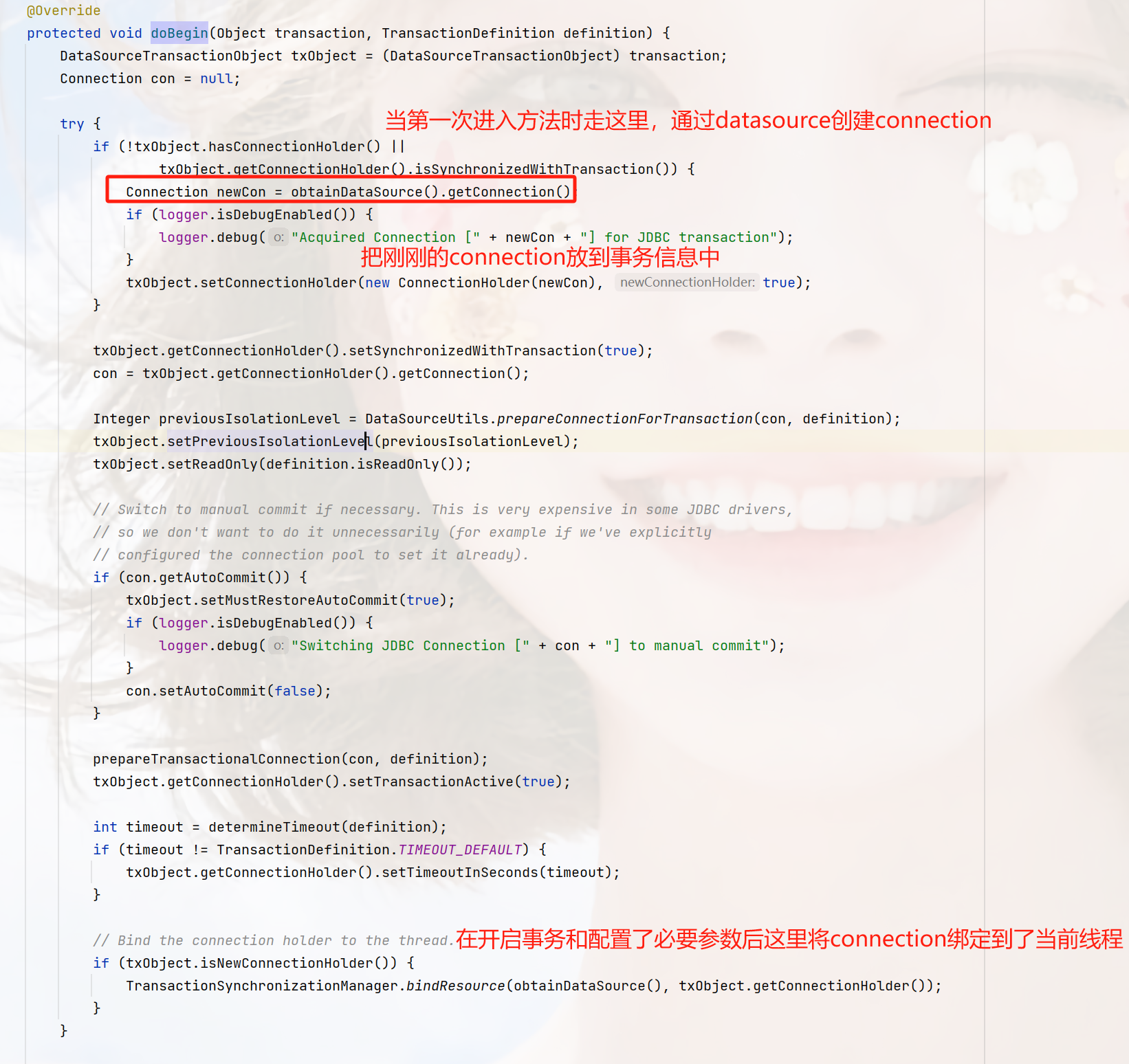
看一下这个绑定的方法
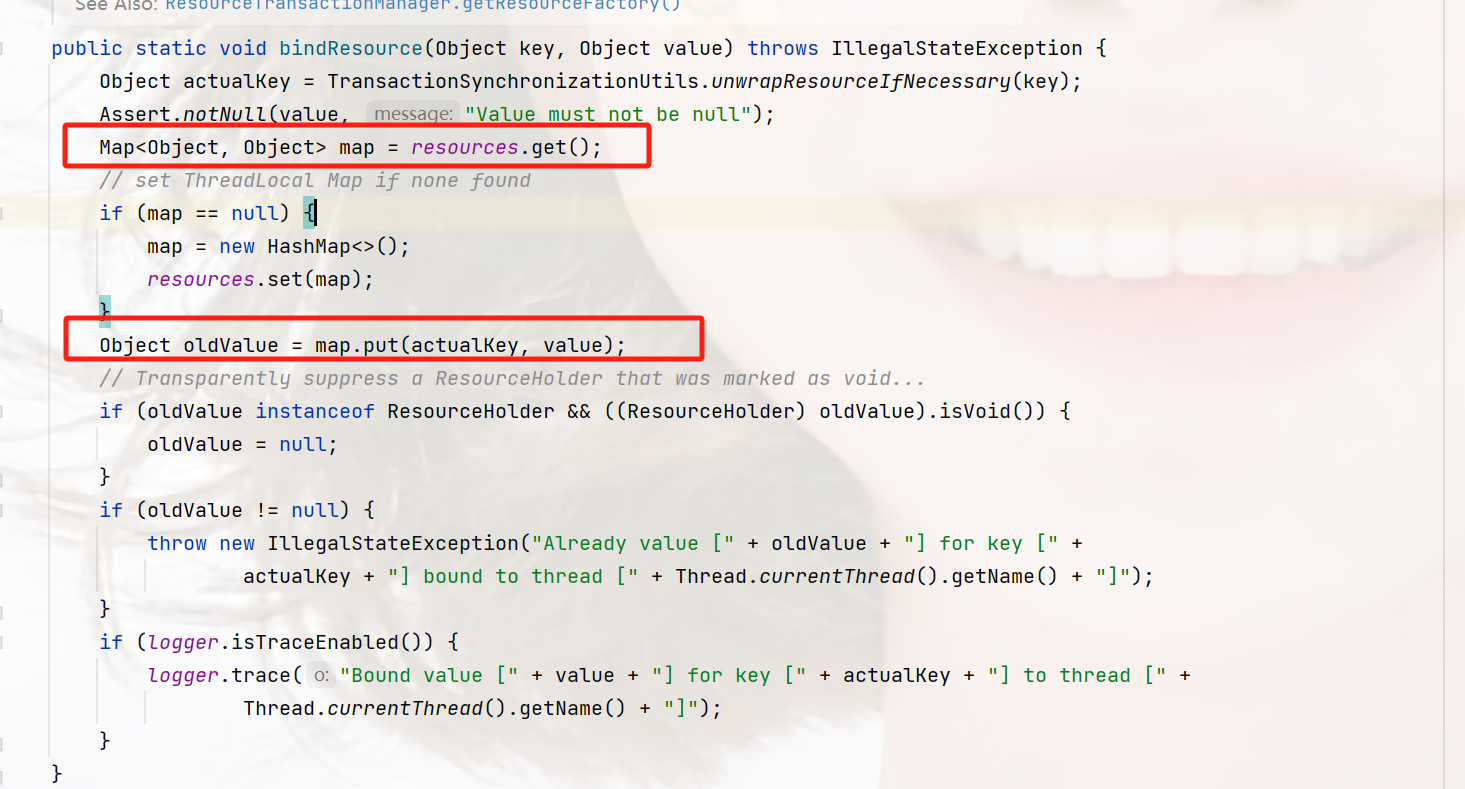

这里以datasource为键,connectionHandle为value放到了resources中,而resources这个是线程变量ThreadLocal,只对当前线程有效,到这里,大概的一个流程我们梳理一下
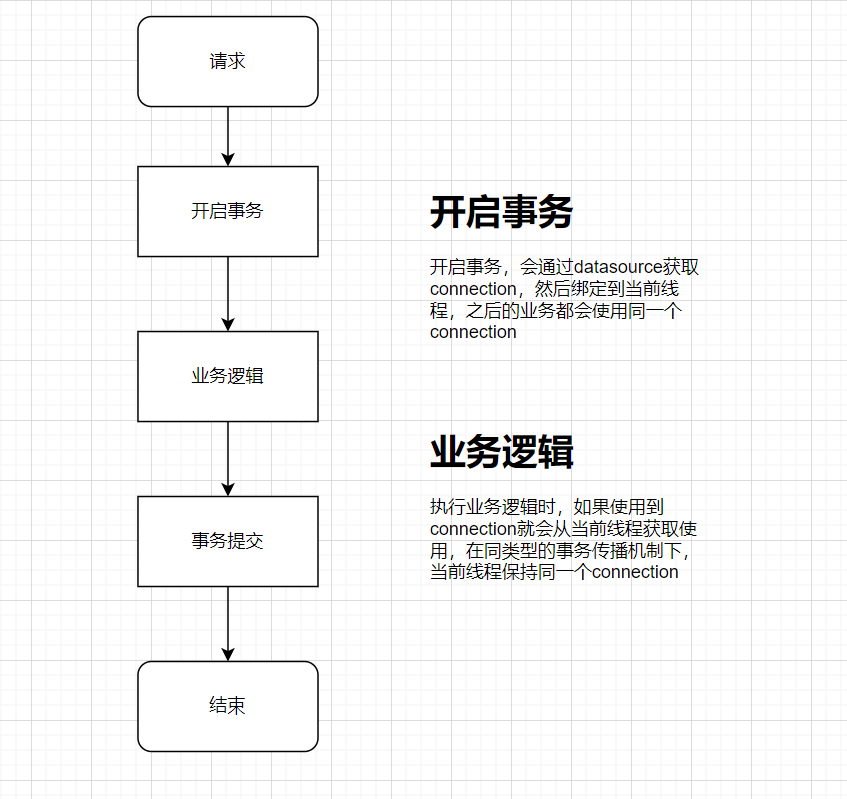
所以说当业务逻辑执行慢的时候,就会占用一个connection资源不释放,当连接池的Connection达到上限时就会使得后面的请求等待,当等待时间达到设置的超时时间就会抛出timeout的异常。