AIGC实战——归一化流模型
- 0. 前言
- 1. 归一化流模型
- 1.1 归一化流模型基本原理
- 1.2 变量变换
- 1.3 雅可比行列式
- 1.4 变量变换方程
- 2. RealNVP
- 2.1 Two Moons 数据集
- 2.2 耦合层
- 2.3 通过耦合层传递数据
- 2.4 堆叠耦合层
- 2.5 训练 RealNVP 模型
- 3. RealNVP 模型分析
- 4. 其他归一化流模型
- 4.1 GLOW
- 4.3 FFJORD
- 小结
- 系列链接
0. 前言
我们已经学习了三类生成模型:变分自动编码器 (Variational Autoencoder, VAE)、生成对抗网络 (Generative Adversarial Network, GAN) 和自回归模型 (Autoregressive Model)。每种模型都使用不同的方式对分布
p
(
x
)
p(x)
p(x) 进行建模,其中 VAE 和 GAN 引入了易于使用的潜变量,自回归模型则将分布建模为先前元素值的函数。在本节中,我们将介绍一类新的生成模型,归一化流模型 (Normalizing Flow Model)。
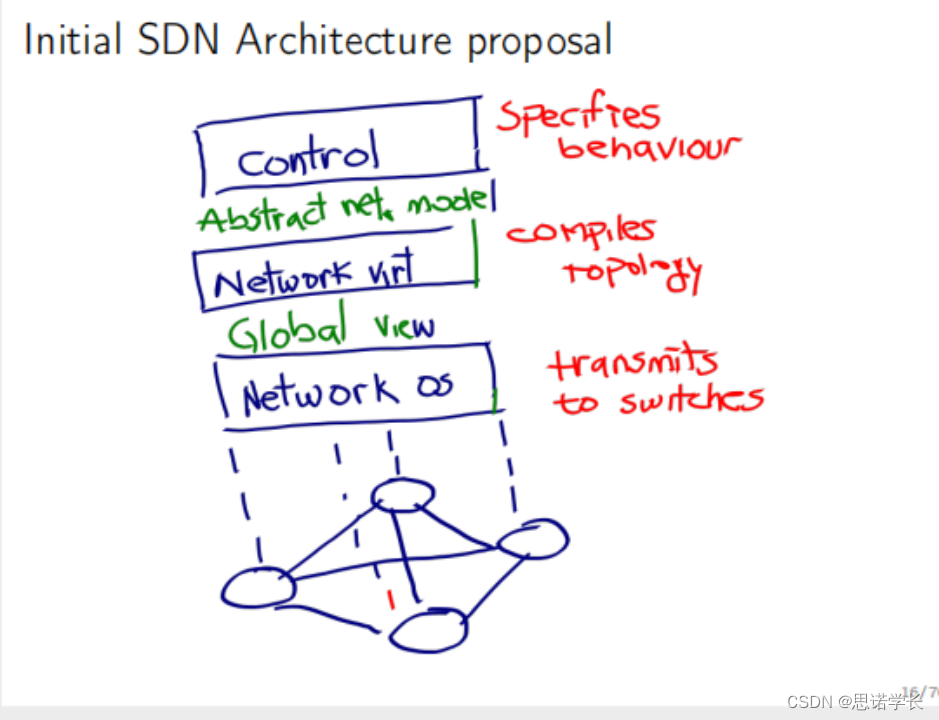
1. 归一化流模型
1.1 归一化流模型基本原理
归一化流模型的目标与变分自编码器类似,变分自编码器学习一个编码器映射函数,用于将复杂分布映射到可以从中采样的简单分布,并学习了一个从简单分布到复杂分布的解码器映射函数,以便通过从简单分布中采样一个点z并应用学到的转换来生成新的数据点。从概率角度来看,解码器用于建模
p
(
x
∣
z
)
p(x|z)
p(x∣z),但编码器只是真实分布
p
(
z
∣
x
)
p(z|x)
p(z∣x) 的近似,编码器和解码器是两个完全不同的神经网络。
在归一化流模型中,解码函数被设计为编码函数的精确反函数,且计算速度快,使得归一化流具有可计算性。而神经网络默认情况下并不是可逆函数,因此需要利用深度学习的灵活性创建一个可逆过程,将一个复杂分布转化为一个简单分布。
为此,我们首先需要了解变量转换 (change of variables) 的技术。在本节中,我们使用一个只有两个维度的简单例子,以便了解归一化流的工作原理,将其进行扩展即可适应复杂问题。
1.2 变量变换
假设有一个在二维空间 x = ( x 1 , x 2 ) x=(x_1,x_2) x=(x1,x2) 中定义的矩形 X X X 上的概率分布 p X ( x ) p_X(x) pX(x),如下图所示。

此函数在分布的定义域(即
x
1
x_1
x1 在 [1, 4] 范围内,
x
2
x_2
x2 在 [0, 2] 范围内)上积分为 1,因此它表示一个明确定义的概率分布,可以写成如下形式:
∫
0
2
∫
1
4
p
X
(
x
)
d
x
1
d
x
2
=
1
∫_0^2 ∫_1^4 p_X(x) dx_1 dx_2 = 1
∫02∫14pX(x)dx1dx2=1
假设我们想要将这个分布平移和缩放,使其在一个单位正方形
Z
Z
Z 上定义。我们可以通过定义一个新变量
z
=
(
z
1
,
z
2
)
z = (z_1, z_2)
z=(z1,z2) 和一个函数
f
f
f,将
X
X
X 中的每个点映射到
Z
Z
Z 中的点,如下所示:
z
=
f
(
x
)
z
1
=
x
1
−
1
3
z
2
=
x
2
2
z = f(x) \\ z_1 = \frac {x_1 - 1}3 \\ z_2 =\frac {x_2} 2
z=f(x)z1=3x1−1z2=2x2
此函数是可逆的,也就是说,存在一个函数
g
g
g,能够将每个
z
z
z 映射回其对应的点
x
x
x,即若一函数有反函数,此函数便称为可逆的 (invertible)。这对于变量变换来说是至关重要的,否则我们无法在两个空间之间进行一致的反向和正向映射,我们可以通过重新排列定义f的方程来找到
g
g
g,如下图所示。

接下来,我们继续了解从
X
X
X 到
Z
Z
Z 的变量变换如何影响概率分布
p
X
(
x
)
p_X(x)
pX(x)。我们可以通过将定义
g
g
g 的方程代入
p
X
(
x
)
p_X(x)
pX(x) 来进行转换,得到一个以
z
z
z 为自变量的函数
p
Z
(
z
)
p_Z(z)
pZ(z):
p
Z
(
z
)
=
(
(
3
z
1
+
1
)
−
1
)
(
2
z
2
)
9
=
2
z
1
z
2
3
p_Z(z) = \frac{((3z_1 + 1) - 1)(2z_2)}9 =\frac{ 2z_1z_2}3
pZ(z)=9((3z1+1)−1)(2z2)=32z1z2
然而,如果在单位正方形上对
p
Z
(
z
)
p_Z(z)
pZ(z)进行积分,会出现以下问题:
∫
0
1
∫
0
1
2
z
1
z
2
3
d
z
1
d
z
2
=
1
6
∫_0^1 ∫_0^1\frac {2z_1z_2} 3 dz_1 dz_2 = \frac 1 6
∫01∫0132z1z2dz1dz2=61
即转换后的函数
p
Z
(
z
)
p_Z(z)
pZ(z) 不再是一个有效的概率分布,因为它的积分等于
1
6
\frac 1 6
61。如果我们想要将复杂的数据概率分布转换为一个简单的分布以便进行采样,就必须确保其积分为
1
1
1。
缺失的因子
6
6
6 源于转换后的概率分布的定义域比原始定义域小六倍——原始矩形
X
X
X 的面积为 6,变换后被压缩为面积为 1 的单位正方形
Z
Z
Z。因此,我们需要将新的概率分布乘以一个归一化因子,该因子等于面积(或在更高维度中的体积)的相对变化,可以使用变换的雅可比行列式 (Jacobian determinant) 的绝对值计算给定变换的体积变化。
1.3 雅可比行列式
函数
z
=
f
(
x
)
z=f(x)
z=f(x) 的雅可比矩阵是其一阶偏导数的矩阵,如下所示:
J
=
∂
z
∂
x
=
[
∂
z
1
∂
x
1
⋯
∂
z
1
∂
x
n
⋮
⋱
⋮
∂
z
m
∂
x
1
⋯
∂
z
m
∂
x
n
]
J=\frac{∂z}{∂x}=\begin{bmatrix} \frac{∂z_1}{∂x_1} & \cdots & \frac{∂z_1}{∂x_n} \\ \vdots & \ddots & \vdots \\ \frac{∂z_m}{∂x_1} & \cdots\ & \frac{∂z_m}{∂x_n} \\ \end{bmatrix}
J=∂x∂z=
∂x1∂z1⋮∂x1∂zm⋯⋱⋯ ∂xn∂z1⋮∂xn∂zm
在以上示例中,如果计算
z
1
z_1
z1 关于
x
1
x_1
x1 的偏导,结果为
1
3
\frac 1 3
31,如果计算
z
1
z_1
z1 关于
x
2
x_2
x2 的偏导,结果为 0;同样地,如果计算
z
2
z_2
z2 关于
x
1
x_1
x1 的偏导,结果为 0;最后,如果计算
z
2
z_2
z2 关于
x
2
x_2
x2 的偏导,结果为
1
2
\frac 1 2
21。因此,函数
f
(
x
)
f(x)
f(x) 的雅可比矩阵如下:
J
=
(
1
3
0
0
1
2
)
J = \left (\begin{array}{rrrr} \frac13 & 0 \\ 0 & \frac 1 2 \\ \end{array}\right)
J=(310021)
行列式 (determinant) 仅对方阵有定义,并且它等于通过将矩阵表示的变换应用到单位(超)立方体上所创建的平行六面体的有向体积 (signed volume)。在二维情况下,这等于将矩阵表示的变换应用到单位正方形上所创建的平行四边形的有向面积 (signed area)。
用于计算
n
n
n 维矩阵的行列式的时间复杂度为
O
(
n
3
)
O(n^3)
O(n3)。对于以上示例,只需要两维形式的公式,即:
d
e
t
(
a
b
c
d
)
=
a
d
−
b
c
det \left (\begin{array}{rrrr} a & b \\c & d \end{array}\right)= ad - bc
det(acbd)=ad−bc
因此,对于以上示例,雅可比矩阵的行列式为:
1
3
×
1
2
−
0
×
0
=
1
6
\frac 1 3 × \frac 1 2 - 0 × 0 = \frac 1 6
31×21−0×0=61
此缩放因子 (
1
6
\frac1 6
61) 用于确保变换后的概率分布积分仍然为 1。根据定义,行列式带有符号,也就是说它可以是负数。因此,我们需要取雅可比矩阵行列式的绝对值才能得到体积的相对变化。
1.4 变量变换方程
我们可以使用变量变换方程描述
X
X
X 和
Z
Z
Z 之间的变量变换过程:
p
X
(
x
)
=
p
Z
(
z
)
∣
d
e
t
(
∂
z
∂
x
)
∣
p_X(x)=p_Z(z)|det(\frac {∂z} {∂x})|
pX(x)=pZ(z)∣det(∂x∂z)∣
基于以上理论构建生成模型,关键在于理解,如果
p
Z
(
z
)
p_Z(z)
pZ(z) 是一个简单的分布,我们可以很容易地从中进行采样(例如高斯分布),那么理论上,我们只需要找到一个适当的可逆函数
f
(
x
)
f(x)
f(x),可以将数据
X
X
X 映射到
Z
Z
Z,以及相应的反函数
g
(
z
)
g(z)
g(z) 用于将采样的
z
z
z 映射回原始域中的点
x
x
x。我们可以利用上述包含雅可比行列式的方程来找到数据分布
p
(
x
)
p(x)
p(x) 的精确的、可计算的公式。
然而,在实际应用中存在两个主要问题。首先,计算高维矩阵的行列式的计算代价较高,其时间复杂度为
O
(
n
3
)
O(n^3)
O(n3)。在实践中,这并不可行,因为即使是小尺寸的 32x32 像素灰度图像也有 1,024 个维度。其次,通常并无显式计算可逆函数
f
(
x
)
f(x)
f(x) 的方法,我们可以使用神经网络来找到某个函数
f
(
x
)
f(x)
f(x),但我们不能保证能够逆转此网络,因为神经网络只能单向工作。
为了解决这两个问题,我们需要使用一种特殊的神经网络架构,确保变量变换函数
f
f
f 具有易于计算的行列式,并且是可逆的。接下来,我们将介绍如何使用实值非体积保持 (Real-valued Non-volume Preserving, RealNVP) 变换的技术解决上述问题。
2. RealNVP
实值非体积保持 (Real-valued Non-volume Preserving, RealNVP) 由 Dinh 等人于 2017 年首提出,RealNVP 可以将复杂的数据分布转换为简单的高斯分布,同时还具有可逆性和易于计算的雅可比行列式。
2.1 Two Moons 数据集
在本节中,我们使用由 sklearn 的 make_moons 函数创建的数据集,make_moons 函数能够创建包含噪声的二维点数据集,类似于两个新月形状。
# 生成一个包含噪声、未标准化的包含 3,000 个点的 Two Moons 数据集
data = datasets.make_moons(30000, noise=0.05)[0].astype("float32")
norm = layers.Normalization()
norm.adapt(data)
# 将数据集标准化,使其均值为 0,标准差为 1
normalized_data = norm(data)

接下来,我们将构建一个 RealNVP 模型,可以生成与两个新月形数据集类似分布的二维点。使用此简单示例能够帮助我们详细了解归一化化流模型在实践中的工作原理。首先,我们介绍一种称为耦合层的新层。
2.2 耦合层
耦合层 (coupling layer) 为其输入的每个元素输出一个缩放因子和一个平移因子。换句话说,它会输出两个与输入大小完全相同的张量,一个用于缩放因子 s,一个用于平移因子 t。

为了构建自定义耦合层处理 Two Moons 数据集,我们可以通过堆叠一组 Dense 层来创建缩放输出,并使用另一组 Dense 层来创建平移输出;而对于图像,耦合层可以使用 Conv2D 层替代 Dense 层。
def Coupling(input_dim, coupling_dim, reg):
# 为了处理 Two Moons 数据集,耦合层的输入具有两个维度
input_layer = layers.Input(shape=input_dim)
# 缩放流是一组具有 256 个单元的 Dense 层
s_layer_1 = layers.Dense(
coupling_dim, activation="relu", kernel_regularizer=regularizers.l2(reg)
)(input_layer)
s_layer_2 = layers.Dense(
coupling_dim, activation="relu", kernel_regularizer=regularizers.l2(reg)
)(s_layer_1)
s_layer_3 = layers.Dense(
coupling_dim, activation="relu", kernel_regularizer=regularizers.l2(reg)
)(s_layer_2)
s_layer_4 = layers.Dense(
coupling_dim, activation="relu", kernel_regularizer=regularizers.l2(reg)
)(s_layer_3)
# 最后一个缩放层具有 2 个单元,并且使用 tanh 激活函数
s_layer_5 = layers.Dense(
input_dim, activation="tanh", kernel_regularizer=regularizers.l2(reg)
)(s_layer_4)
# 平移流是一组具有 256 个单元的 Dense 层
t_layer_1 = layers.Dense(
coupling_dim, activation="relu", kernel_regularizer=regularizers.l2(reg)
)(input_layer)
t_layer_2 = layers.Dense(
coupling_dim, activation="relu", kernel_regularizer=regularizers.l2(reg)
)(t_layer_1)
t_layer_3 = layers.Dense(
coupling_dim, activation="relu", kernel_regularizer=regularizers.l2(reg)
)(t_layer_2)
t_layer_4 = layers.Dense(
coupling_dim, activation="relu", kernel_regularizer=regularizers.l2(reg)
)(t_layer_3)
# 最后一个平移层具有 2 个单元,并且使用线性激活函数
t_layer_5 = layers.Dense(
input_dim, activation="linear", kernel_regularizer=regularizers.l2(reg)
)(t_layer_4)
# 构建耦合层,其包含两个输出,包括缩放因子和平移因子
return models.Model(inputs=input_layer, outputs=[s_layer_5, t_layer_5])
在将输出维度还原回与输入维度相同之前,通过增加维度学习数据更复杂的特征。还可以对每一层使用正则化器以惩罚较大的权重。
2.3 通过耦合层传递数据
耦合层的架构并不复杂,它的独特之处在于输入数据在被送入耦合层时如何进行掩码和变换。

只有数据的前
d
d
d 个维度被输入到第一个耦合层中,剩下的 D-d 个维度被掩码(即被设为零)。在本节构建的模型中,我们假设
D
=
2
D=2
D=2 且
d
=
1
d=1
d=1,这意味着耦合层不会看到全部值
(
x
1
,
x
2
)
(x_1,x_2)
(x1,x2),而只能看到
(
x
1
,
0
)
(x_1,0)
(x1,0)。
耦合层的输出是缩放因子和平移因子,输出也会被掩码,但使用的是之前的相反掩码,以便只有后半部分被传递出去,在以上模型中,输出结果为
(
0
,
s
2
)
(0,s_2)
(0,s2) 和
(
0
,
t
2
)
(0,t_2)
(0,t2)。然后,这些输出被逐元素地应用于输入的后半部分
x
2
x_2
x2,而输入的前半部分
x
1
x_1
x1 则直接传递,没有进行任何更新。综上,对于一个维度为
D
D
D 且
d
<
D
d<D
d<D 的向量,更新方程如下:
z
1
:
d
=
x
1
:
d
z
d
+
1
:
D
=
x
d
+
1
:
D
⊙
e
x
p
(
s
(
x
1
:
d
)
)
+
t
(
x
1
:
d
)
z_{1:d} = x_{1:d}\\ z_{d+1:D} = x_{d+1:D} ⊙ exp(s(x_{1:d})) + t(x_{1:d})
z1:d=x1:dzd+1:D=xd+1:D⊙exp(s(x1:d))+t(x1:d)
想要知道为什么需要构建一个掩码了这么多信息的层,我们首先观察此函数的雅可比矩阵的结构:
∂
z
∂
x
=
[
I
0
∂
z
d
+
1
:
D
∂
x
1
:
d
d
i
a
g
(
e
x
p
[
s
(
x
1
:
d
)
]
)
]
\frac {∂z}{∂x} =\begin{bmatrix} \bold {I} &0 \\ \frac {∂z_d+1:D}{∂x1:d} & diag(exp[s(x_{1:d})]) \\ \end{bmatrix}
∂x∂z=[I∂x1:d∂zd+1:D0diag(exp[s(x1:d)])]
左上角的
d
×
d
d×d
d×d 子矩阵是单位矩阵
I
\bold {I}
I,因为
z
1
:
d
=
x
1
:
d
z_{1:d} = x_{1:d}
z1:d=x1:d,这些元素直接传递而不进行更新。因此,左上角的子矩阵是 0,因为
z
d
+
1
:
D
z_{d+1:D}
zd+1:D 不依赖于
x
d
+
1
:
D
x_{d+1:D}
xd+1:D。
右下角的子矩阵只是一个对角矩阵,使用元素
e
x
p
(
s
(
x
1
:
d
)
)
exp(s(x1:d))
exp(s(x1:d)) 进行填充,因为
z
d
+
1
:
D
z_{d+1:D}
zd+1:D 线性依赖于
x
d
+
1
:
D
x_{d+1:D}
xd+1:D,梯度仅依赖于缩放因子(不依赖于平移因子)。下图展示了该矩阵形式,只有非零元素被填充上颜色。

需要注意的是,对角线上方没有非零元素,因此这种矩阵称为下三角矩阵。这种结构化矩阵(下三角矩阵)的行列式等于对角线元素的乘积。换句话说,行列式不依赖于左下角的复杂导数。因此,可以将这个矩阵的行列式写为:
d
e
t
(
J
)
=
e
x
p
(
∑
j
s
(
x
1
:
d
)
j
)
det(J) = exp(∑_js(x_{1:d})_j)
det(J)=exp(j∑s(x1:d)j)
上式十分易于计算的,解决了雅可比行列式的计算问题后,我们继续考虑另一问题,即目标是函数必须易于求其反函数。我们可以通过重新排列正向方程得到可逆函数,如下所示:
x
1
:
d
=
z
1
:
d
x
d
+
1
:
D
=
(
z
d
+
1
:
D
−
t
(
x
1
:
d
)
)
⊙
e
x
p
(
−
s
(
x
1
:
d
)
)
x_{1:d} = z_{1:d} x_{d+1:D} = (z_{d+1:D} - t(x_{1:d})) ⊙ exp(-s(x_{1:d}))
x1:d=z1:dxd+1:D=(zd+1:D−t(x1:d))⊙exp(−s(x1:d))
如下图所示。

解决了 RealNVP 模型的构建问题后,我们继续考虑如何更新输入的前
d
d
d 个元素。
2.4 堆叠耦合层
为了更新输入的前
d
d
d 个元素,我们可以将耦合层堆叠在一起,但交替使用掩码模式,在某一个层保持不变的元素将在下一层中进行更新。这种架构能够学习数据更复杂的表示,因为它是一个更深层的神经网络。
耦合层组合的雅可比矩阵仍然很容易计算,根据线性代数的原理,矩阵乘积的行列式是行列式的乘积。同样地,两个函数组合的反函数就是各自反函数的组合,如下方程所示:
d
e
t
(
A
⋅
B
)
=
d
e
t
(
A
)
d
e
t
(
B
)
(
f
b
∘
f
a
)
−
1
=
f
a
−
1
∘
f
b
−
1
det(A·B) = det(A) det(B)\\ (f_b ∘ f_a)^{-1} = f_a^{-1} ∘ f_b^{-1}
det(A⋅B)=det(A)det(B)(fb∘fa)−1=fa−1∘fb−1
因此,如果我们堆叠耦合层,并且每次改变掩码模式,就可以构建一个能够转换整个输入张量的神经网络,同时保持具有简单雅可比矩阵行列式和可逆性的关键特性。总体结构如下图所示。

2.5 训练 RealNVP 模型
构建了 RealNVP 模型后,便可以对其进行训练,以学习 Two Moons 数据集的复杂分布。我们希望模型最小化数据的负对数似然
−
l
o
g
p
X
(
x
)
-logp_X(x)
−logpX(x):
−
l
o
g
p
X
(
x
)
=
−
l
o
g
p
Z
(
z
)
−
l
o
g
∣
d
e
t
(
∂
z
∂
x
)
∣
-logp_X(x)=-logp_Z(z)-log|det(\frac {∂z}{∂x})|
−logpX(x)=−logpZ(z)−log∣det(∂x∂z)∣
选择正向过程f的目标输出分布
p
Z
(
z
)
p_Z(z)
pZ(z) 为标准高斯分布,因为我们可以很容易地从该分布中进行采样。然后,通过应用逆过程
g
g
g,我们可以将从高斯分布中采样得到的点转换回原始图像域,如下图所示。

接下来,使用 Keras 构建 RealNVP 网络。
class RealNVP(models.Model):
def __init__(
self, input_dim, coupling_layers, coupling_dim, regularization
):
super(RealNVP, self).__init__()
self.coupling_layers = coupling_layers
# 目标分布是一个标准的二维高斯分布
self.distribution = tfp.distributions.MultivariateNormalDiag(
loc=[0.0, 0.0], scale_diag=[1.0, 1.0]
)
# 创建交替掩码模式
self.masks = np.array([[0, 1], [1, 0]] * (coupling_layers // 2), dtype="float32")
self.loss_tracker = metrics.Mean(name="loss")
# 定义由 Coupling 层组成的列表,用于定义 RealNVP 网络
self.layers_list = [
Coupling(input_dim, coupling_dim, regularization)
for i in range(coupling_layers)
]
@property
def metrics(self):
return [self.loss_tracker]
def call(self, x, training=True):
log_det_inv = 0
direction = 1
if training:
direction = -1
# 在网络的 call 函数中,循环遍历 Coupling 层。如果 training=True,则正向通过耦合层(即从数据到潜空间);如果 training=False,则反向通过耦合层(即从潜空间到数据)
for i in range(self.coupling_layers)[::direction]:
x_masked = x * self.masks[i]
reversed_mask = 1 - self.masks[i]
s, t = self.layers_list[i](x_masked)
s *= reversed_mask
t *= reversed_mask
gate = (direction - 1) / 2
# 正向和反向方程,取决于方向参数 direction 的值
x = (
reversed_mask
* (x * tf.exp(direction * s) + direction * t * tf.exp(gate * s))
+ x_masked
)
# 雅可比行列式的对数行列式,用于计算损失函数,是缩放因子的总和
log_det_inv += gate * tf.reduce_sum(s, axis=1)
return x, log_det_inv
def log_loss(self, x):
y, logdet = self(x)
# 损失函数是转换后的数据在目标高斯分布下的负对数概率和雅可比行列式的对数之和的负值
log_likelihood = self.distribution.log_prob(y) + logdet
return -tf.reduce_mean(log_likelihood)
def train_step(self, data):
with tf.GradientTape() as tape:
loss = self.log_loss(data)
g = tape.gradient(loss, self.trainable_variables)
self.optimizer.apply_gradients(zip(g, self.trainable_variables))
self.loss_tracker.update_state(loss)
return {"loss": self.loss_tracker.result()}
def test_step(self, data):
loss = self.log_loss(data)
self.loss_tracker.update_state(loss)
return {"loss": self.loss_tracker.result()}
model = RealNVP(
input_dim=INPUT_DIM,
coupling_layers=COUPLING_LAYERS,
coupling_dim=COUPLING_DIM,
regularization=REGULARIZATION,
)
# Compile and train the model
model.compile(optimizer=optimizers.Adam(learning_rate=0.0001))
model.fit(
normalized_data,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
)
3. RealNVP 模型分析
模型训练完成后,就可以使用它将训练集转换为潜空间(使用正向方程
f
f
f),或者将从潜在空间中采样的点转换为像是从原始数据分布中采样的点(使用反向方程
g
g
g)。
在模型进行训练之前网络的输出如下所示,无论是正向还是反向都只是将信息直接传递,几乎没有任何变换。

在训练之后,正向过程能够将训练集中的点转换为类似于高斯分布的分布。同样,反向过程可以将从高斯分布中采样的点映射回类似于原始数据的分布。

接下来,我们将继续介绍一些改进的归一化流模型,这些模型扩展了 RealNVP 的思想。
4. 其他归一化流模型
另外两个重要的归一化流模型包括 GLOW 和 FFJORD。
4.1 GLOW
GLOW 于 2018 年提出,是第一个证明了归一化流具有生成高质量样本和获得有意义的潜空间以用于样本操作的能力的模型之一。其关键步骤是使用可逆的 1×1 卷积层替换反向掩码。例如,在应用于图像的 RealNVP 中,每个步骤之后通道的顺序被翻转,以确保网络有机会转换所有输入。而在 GLOW 中,采用了 1×1 卷积,它有效地充当了产生模型所需的通道排列方法。即使加入了这一步骤,整个分布仍然是可处理的,其行列式和逆矩阵在大规模情况下仍易于计算。

4.3 FFJORD
RealNVP 和 GLOW 是离散时间的归一化流,它们通过一组离散的耦合层来转换输入。FFJORD (Free-Form Continuous Dynamics for Scalable Reversible Generative Models) 于 2019 年提出,其将转换建模为连续时间过程(即,通过将流中的步骤数趋近无穷大、步长趋近于零)。在这种情况下,使用一个普通微分方程 (Ordinary Differential Equation, ODE) 来建模动力学,其参数由一个神经网络
(
f
θ
)
(fθ)
(fθ) 生成。使用一个黑盒求解器来解决 ODE 在时间
t
1
t_1
t1 时的问题,即给定从时间
t
0
t_0
t0 采样的高斯分布中的初始点
z
0
z_0
z0,找到
z
1
z_1
z1:
z
0
∼
p
(
z
0
)
∂
z
(
t
)
∂
t
=
f
θ
(
x
(
t
)
,
t
)
x
=
z
1
z_0 \sim p(z_0)\\ \frac {∂z(t)}{∂t} = f_θ(x(t), t)\\ x = z_1
z0∼p(z0)∂t∂z(t)=fθ(x(t),t)x=z1
转换过程如下图所示。

小结
归一化流模型是由神经网络定义的可逆函数,通过变量变换,直接对数据密度函数进行建模。在一般情况下,变量变换方程需要计算高度复杂的雅可比行列式,但这并不实际。为了解决这一问题,RealNVP 模型限制了神经网络的形式,使其满足两个基本条件:可逆性和易于计算的雅可比行列式。GLOW 进一步扩展了这一思想,消除了硬编码的掩码变换的必要性。FFJORD 模型通过使用由神经网络定义的 ODE,将转换过程建模为连续时间归一化流。归一化流是一种强大的生成建模方法,可以产生高质量的样本,并能够可靠地描述数据密度函数。
系列链接
AIGC实战——生成模型简介
AIGC实战——深度学习 (Deep Learning, DL)
AIGC实战——卷积神经网络(Convolutional Neural Network, CNN)
AIGC实战——自编码器(Autoencoder)
AIGC实战——变分自编码器(Variational Autoencoder, VAE)
AIGC实战——使用变分自编码器生成面部图像
AIGC实战——生成对抗网络(Generative Adversarial Network, GAN)
AIGC实战——WGAN(Wasserstein GAN)
AIGC实战——条件生成对抗网络(Conditional Generative Adversarial Net, CGAN)
AIGC实战——自回归模型(Autoregressive Model)
AIGC实战——改进循环神经网络
AIGC实战——像素卷积神经网络(PixelCNN)