(beta)计算机视觉的量化迁移学习教程
原文:
pytorch.org/tutorials/intermediate/quantized_transfer_learning_tutorial.html译者:飞龙
协议:CC BY-NC-SA 4.0
提示
为了充分利用本教程,我们建议使用这个Colab 版本。这将允许您尝试下面提供的信息。
作者:Zafar Takhirov
审阅者:Raghuraman Krishnamoorthi
编辑:Jessica Lin
本教程是基于原始的PyTorch 迁移学习教程构建的,由Sasank Chilamkurthy编写。
迁移学习是指利用预训练模型应用于不同数据集的技术。迁移学习的主要使用方式有两种:
-
将 ConvNet 作为固定特征提取器:在这里,您会“冻结”网络中除最后几层(通常是完全连接的层,也称为“头部”)之外的所有参数的权重。这些最后的层将被新的层替换,并用随机权重初始化,只有这些层会被训练。
-
微调 ConvNet:不是随机初始化,而是使用预训练网络初始化模型,然后训练过程与通常情况下不同数据集的训练相同。通常还会替换网络中的头部(或其中的一部分),以适应不同数量的输出。在这种方法中,通常将学习率设置为较小的值。这是因为网络已经训练过,只需要对其进行“微调”以适应新数据集。
您也可以结合上述两种方法:首先可以冻结特征提取器,并训练头部。之后,您可以解冻特征提取器(或其中的一部分),将学习率设置为较小的值,并继续训练。
在本部分中,您将使用第一种方法——使用量化模型提取特征。
第 0 部分。先决条件
在深入研究迁移学习之前,让我们回顾一下“先决条件”,如安装和数据加载/可视化。
# Imports
import copy
import matplotlib.pyplot as plt
import numpy as np
import os
import time
plt.ion()
安装夜间版本
由于您将使用 PyTorch 的 beta 部分,建议安装最新版本的torch和torchvision。您可以在本地安装的最新说明这里。例如,要安装不带 GPU 支持的版本:
pip install numpy
pip install --pre torch torchvision -f https://download.pytorch.org/whl/nightly/cpu/torch_nightly.html
# For CUDA support use https://download.pytorch.org/whl/nightly/cu101/torch_nightly.html
加载数据
注意
本节与原始迁移学习教程相同。
我们将使用torchvision和torch.utils.data包来加载数据。
今天您要解决的问题是从图像中对蚂蚁和蜜蜂进行分类。数据集包含大约 120 张蚂蚁和蜜蜂的训练图像。每个类别有 75 张验证图像。这被认为是一个非常小的数据集来进行泛化。但是,由于我们使用迁移学习,我们应该能够进行合理的泛化。
此数据集是 imagenet 的一个非常小的子集。
注意
从这里下载数据并将其解压缩到data目录中。
import torch
from torchvision import transforms, datasets
# Data augmentation and normalization for training
# Just normalization for validation
data_transforms = {
'train': transforms.Compose([
transforms.Resize(224),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = 'data/hymenoptera_data'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=16,
shuffle=True, num_workers=8)
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
可视化几张图片
让我们可视化一些训练图像,以便了解数据增强。
import torchvision
def imshow(inp, title=None, ax=None, figsize=(5, 5)):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
if ax is None:
fig, ax = plt.subplots(1, figsize=figsize)
ax.imshow(inp)
ax.set_xticks([])
ax.set_yticks([])
if title is not None:
ax.set_title(title)
# Get a batch of training data
inputs, classes = next(iter(dataloaders['train']))
# Make a grid from batch
out = torchvision.utils.make_grid(inputs, nrow=4)
fig, ax = plt.subplots(1, figsize=(10, 10))
imshow(out, title=[class_names[x] for x in classes], ax=ax)
用于模型训练的支持函数
以下是用于模型训练的通用函数。此函数还
-
调整学习率
-
保存最佳模型
def train_model(model, criterion, optimizer, scheduler, num_epochs=25, device='cpu'):
"""
Support function for model training.
Args:
model: Model to be trained
criterion: Optimization criterion (loss)
optimizer: Optimizer to use for training
scheduler: Instance of ``torch.optim.lr_scheduler``
num_epochs: Number of epochs
device: Device to run the training on. Must be 'cpu' or 'cuda'
"""
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model
用于可视化模型预测的支持函数
用于显示几张图片预测的通用函数
def visualize_model(model, rows=3, cols=3):
was_training = model.training
model.eval()
current_row = current_col = 0
fig, ax = plt.subplots(rows, cols, figsize=(cols*2, rows*2))
with torch.no_grad():
for idx, (imgs, lbls) in enumerate(dataloaders['val']):
imgs = imgs.cpu()
lbls = lbls.cpu()
outputs = model(imgs)
_, preds = torch.max(outputs, 1)
for jdx in range(imgs.size()[0]):
imshow(imgs.data[jdx], ax=ax[current_row, current_col])
ax[current_row, current_col].axis('off')
ax[current_row, current_col].set_title('predicted: {}'.format(class_names[preds[jdx]]))
current_col += 1
if current_col >= cols:
current_row += 1
current_col = 0
if current_row >= rows:
model.train(mode=was_training)
return
model.train(mode=was_training)
第 1 部分。基于量化特征提取器训练自定义分类器
在本节中,您将使用一个“冻结”的可量化特征提取器,并在其顶部训练一个自定义分类器头。与浮点模型不同,您不需要为可量化模型设置 requires_grad=False,因为它没有可训练的参数。请参考文档以获取更多详细信息。
加载预训练模型:在本练习中,您将使用ResNet-18。
import torchvision.models.quantization as models
# You will need the number of filters in the `fc` for future use.
# Here the size of each output sample is set to 2.
# Alternatively, it can be generalized to nn.Linear(num_ftrs, len(class_names)).
model_fe = models.resnet18(pretrained=True, progress=True, quantize=True)
num_ftrs = model_fe.fc.in_features
此时,您需要修改预训练模型。该模型在开头和结尾有量化/去量化块。但是,因为您只会使用特征提取器,所以去量化层必须移动到线性层(头部)的右侧。最简单的方法是将模型包装在nn.Sequential模块中。
第一步是在 ResNet 模型中隔离特征提取器。尽管在这个例子中,您被要求使用除fc之外的所有层作为特征提取器,但实际上,您可以取需要的部分。这在您想要替换一些卷积层时会很有用。
注意
当将特征提取器与量化模型的其余部分分离时,您必须手动将量化器/去量化器放置在您想要保持量化的部分的开头和结尾。
下面的函数创建了一个带有自定义头的模型。
from torch import nn
def create_combined_model(model_fe):
# Step 1\. Isolate the feature extractor.
model_fe_features = nn.Sequential(
model_fe.quant, # Quantize the input
model_fe.conv1,
model_fe.bn1,
model_fe.relu,
model_fe.maxpool,
model_fe.layer1,
model_fe.layer2,
model_fe.layer3,
model_fe.layer4,
model_fe.avgpool,
model_fe.dequant, # Dequantize the output
)
# Step 2\. Create a new "head"
new_head = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(num_ftrs, 2),
)
# Step 3\. Combine, and don't forget the quant stubs.
new_model = nn.Sequential(
model_fe_features,
nn.Flatten(1),
new_head,
)
return new_model
警告
目前,量化模型只能在 CPU 上运行。但是,可以将模型的非量化部分发送到 GPU 上。
import torch.optim as optim
new_model = create_combined_model(model_fe)
new_model = new_model.to('cpu')
criterion = nn.CrossEntropyLoss()
# Note that we are only training the head.
optimizer_ft = optim.SGD(new_model.parameters(), lr=0.01, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
训练和评估
这一步在 CPU 上大约需要 15-25 分钟。由于量化模型只能在 CPU 上运行,因此无法在 GPU 上运行训练。
new_model = train_model(new_model, criterion, optimizer_ft, exp_lr_scheduler,
num_epochs=25, device='cpu')
visualize_model(new_model)
plt.tight_layout()
第 2 部分。微调可量化模型
在这部分中,我们微调用于迁移学习的特征提取器,并对特征提取器进行量化。请注意,在第 1 部分和第 2 部分中,特征提取器都被量化。不同之处在于,在第 1 部分中,我们使用了一个预训练的量化模型。而在这部分中,我们在感兴趣的数据集上微调后创建了一个量化的特征提取器,因此这是一种在迁移学习中获得更好准确性并具有量化优势的方法。请注意,在我们的具体示例中,训练集非常小(120 张图像),因此整个模型微调的好处并不明显。然而,这里展示的过程将提高在具有更大数据集的迁移学习中的准确性。
预训练的特征提取器必须是可量化的。为确保它是可量化的,请执行以下步骤:
- 使用
torch.quantization.fuse_modules融合(Conv, BN, ReLU)、(Conv, BN)和(Conv, ReLU)。- 将特征提取器与自定义头连接。这需要对特征提取器的输出进行去量化。
- 在特征提取器的适当位置插入伪量化模块,以在训练过程中模拟量化。
对于第(1)步,我们使用torchvision/models/quantization中的模型,这些模型具有成员方法fuse_model。此函数将所有conv、bn和relu模块融合在一起。对于自定义模型,这将需要手动调用torch.quantization.fuse_modules API,并提供要手动融合的模块列表。
第(2)步由前一节中使用的create_combined_model函数执行。
第(3)步通过使用torch.quantization.prepare_qat来实现,该函数插入了伪量化模块。
作为第(4)步,您可以开始“微调”模型,然后将其转换为完全量化的版本(第 5 步)。
要将微调后的模型转换为量化模型,您可以调用torch.quantization.convert函数(在我们的情况下,只有特征提取器被量化)。
注意
由于随机初始化,您的结果可能与本教程中显示的结果不同。
# notice `quantize=False`
model = models.resnet18(pretrained=True, progress=True, quantize=False)
num_ftrs = model.fc.in_features
# Step 1
model.train()
model.fuse_model()
# Step 2
model_ft = create_combined_model(model)
model_ft[0].qconfig = torch.quantization.default_qat_qconfig # Use default QAT configuration
# Step 3
model_ft = torch.quantization.prepare_qat(model_ft, inplace=True)
微调模型
在当前教程中,整个模型都被微调。一般来说,这会导致更高的准确性。然而,由于这里使用的训练集很小,我们最终会过拟合训练集。
步骤 4. 微调模型
for param in model_ft.parameters():
param.requires_grad = True
model_ft.to(device) # We can fine-tune on GPU if available
criterion = nn.CrossEntropyLoss()
# Note that we are training everything, so the learning rate is lower
# Notice the smaller learning rate
optimizer_ft = optim.SGD(model_ft.parameters(), lr=1e-3, momentum=0.9, weight_decay=0.1)
# Decay LR by a factor of 0.3 every several epochs
exp_lr_scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=5, gamma=0.3)
model_ft_tuned = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,
num_epochs=25, device=device)
步骤 5. 转换为量化模型
from torch.quantization import convert
model_ft_tuned.cpu()
model_quantized_and_trained = convert(model_ft_tuned, inplace=False)
让我们看看量化模型在几张图片上的表现
visualize_model(model_quantized_and_trained)
plt.ioff()
plt.tight_layout()
plt.show()
(beta)在 PyTorch 中使用急切模式的静态量化
原文:
pytorch.org/tutorials/advanced/static_quantization_tutorial.html译者:飞龙
协议:CC BY-NC-SA 4.0
作者:Raghuraman Krishnamoorthi 编辑:Seth Weidman,Jerry Zhang
本教程展示了如何进行后训练静态量化,以及展示了两种更高级的技术 - 按通道量化和量化感知训练 - 以进一步提高模型的准确性。请注意,目前量化仅支持 CPU,因此在本教程中我们将不使用 GPU/CUDA。通过本教程,您将看到 PyTorch 中的量化如何导致模型尺寸显著减小,同时提高速度。此外,您将看到如何轻松应用一些高级量化技术,使您的量化模型比以往更少地准确性下降。警告:我们从其他 PyTorch 存储库中使用了大量样板代码,例如定义MobileNetV2模型架构,定义数据加载器等。当然我们鼓励您阅读它;但如果您想了解量化功能,请随时跳到“4. 后训练静态量化”部分。我们将从进行必要的导入开始:
import os
import sys
import time
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision
from torchvision import datasets
import torchvision.transforms as transforms
# Set up warnings
import warnings
warnings.filterwarnings(
action='ignore',
category=DeprecationWarning,
module=r'.*'
)
warnings.filterwarnings(
action='default',
module=r'torch.ao.quantization'
)
# Specify random seed for repeatable results
torch.manual_seed(191009)
1. 模型架构
我们首先定义 MobileNetV2 模型架构,进行了几个显著的修改以实现量化:
-
用
nn.quantized.FloatFunctional替换加法 -
在网络的开头和结尾插入
QuantStub和DeQuantStub。 -
用 ReLU 替换 ReLU6
注意:此代码取自这里。
from torch.ao.quantization import QuantStub, DeQuantStub
def _make_divisible(v, divisor, min_value=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
:param v:
:param divisor:
:param min_value:
:return:
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
class ConvBNReLU(nn.Sequential):
def __init__(self, in_planes, out_planes, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_planes, momentum=0.1),
# Replace with ReLU
nn.ReLU(inplace=False)
)
class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
hidden_dim = int(round(inp * expand_ratio))
self.use_res_connect = self.stride == 1 and inp == oup
layers = []
if expand_ratio != 1:
# pw
layers.append(ConvBNReLU(inp, hidden_dim, kernel_size=1))
layers.extend([
# dw
ConvBNReLU(hidden_dim, hidden_dim, stride=stride, groups=hidden_dim),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup, momentum=0.1),
])
self.conv = nn.Sequential(*layers)
# Replace torch.add with floatfunctional
self.skip_add = nn.quantized.FloatFunctional()
def forward(self, x):
if self.use_res_connect:
return self.skip_add.add(x, self.conv(x))
else:
return self.conv(x)
class MobileNetV2(nn.Module):
def __init__(self, num_classes=1000, width_mult=1.0, inverted_residual_setting=None, round_nearest=8):
"""
MobileNet V2 main class
Args:
num_classes (int): Number of classes
width_mult (float): Width multiplier - adjusts number of channels in each layer by this amount
inverted_residual_setting: Network structure
round_nearest (int): Round the number of channels in each layer to be a multiple of this number
Set to 1 to turn off rounding
"""
super(MobileNetV2, self).__init__()
block = InvertedResidual
input_channel = 32
last_channel = 1280
if inverted_residual_setting is None:
inverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
# only check the first element, assuming user knows t,c,n,s are required
if len(inverted_residual_setting) == 0 or len(inverted_residual_setting[0]) != 4:
raise ValueError("inverted_residual_setting should be non-empty "
"or a 4-element list, got {}".format(inverted_residual_setting))
# building first layer
input_channel = _make_divisible(input_channel * width_mult, round_nearest)
self.last_channel = _make_divisible(last_channel * max(1.0, width_mult), round_nearest)
features = [ConvBNReLU(3, input_channel, stride=2)]
# building inverted residual blocks
for t, c, n, s in inverted_residual_setting:
output_channel = _make_divisible(c * width_mult, round_nearest)
for i in range(n):
stride = s if i == 0 else 1
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
input_channel = output_channel
# building last several layers
features.append(ConvBNReLU(input_channel, self.last_channel, kernel_size=1))
# make it nn.Sequential
self.features = nn.Sequential(*features)
self.quant = QuantStub()
self.dequant = DeQuantStub()
# building classifier
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(self.last_channel, num_classes),
)
# weight initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x):
x = self.quant(x)
x = self.features(x)
x = x.mean([2, 3])
x = self.classifier(x)
x = self.dequant(x)
return x
# Fuse Conv+BN and Conv+BN+Relu modules prior to quantization
# This operation does not change the numerics
def fuse_model(self, is_qat=False):
fuse_modules = torch.ao.quantization.fuse_modules_qat if is_qat else torch.ao.quantization.fuse_modules
for m in self.modules():
if type(m) == ConvBNReLU:
fuse_modules(m, ['0', '1', '2'], inplace=True)
if type(m) == InvertedResidual:
for idx in range(len(m.conv)):
if type(m.conv[idx]) == nn.Conv2d:
fuse_modules(m.conv, [str(idx), str(idx + 1)], inplace=True)
2. 辅助函数
接下来,我们定义了几个辅助函数来帮助模型评估。这些大部分来自这里。
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self, name, fmt=':f'):
self.name = name
self.fmt = fmt
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def __str__(self):
fmtstr = '{name} {val' + self.fmt + '} ({avg' + self.fmt + '})'
return fmtstr.format(**self.__dict__)
def accuracy(output, target, topk=(1,)):
"""Computes the accuracy over the k top predictions for the specified values of k"""
with torch.no_grad():
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].reshape(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res
def evaluate(model, criterion, data_loader, neval_batches):
model.eval()
top1 = AverageMeter('Acc@1', ':6.2f')
top5 = AverageMeter('Acc@5', ':6.2f')
cnt = 0
with torch.no_grad():
for image, target in data_loader:
output = model(image)
loss = criterion(output, target)
cnt += 1
acc1, acc5 = accuracy(output, target, topk=(1, 5))
print('.', end = '')
top1.update(acc1[0], image.size(0))
top5.update(acc5[0], image.size(0))
if cnt >= neval_batches:
return top1, top5
return top1, top5
def load_model(model_file):
model = MobileNetV2()
state_dict = torch.load(model_file)
model.load_state_dict(state_dict)
model.to('cpu')
return model
def print_size_of_model(model):
torch.save(model.state_dict(), "temp.p")
print('Size (MB):', os.path.getsize("temp.p")/1e6)
os.remove('temp.p')
3. 定义数据集和数据加载器
作为我们最后的主要设置步骤,我们为训练集和测试集定义数据加载器。
ImageNet 数据
要使用整个 ImageNet 数据集运行本教程中的代码,请首先按照ImageNet 数据中的说明下载 imagenet。将下载的文件解压缩到“data_path”文件夹中。
数据下载完成后,我们展示下面的函数定义数据加载器,我们将使用这些数据读取。这些函数大部分来自这里。
def prepare_data_loaders(data_path):
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
dataset = torchvision.datasets.ImageNet(
data_path, split="train", transform=transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]))
dataset_test = torchvision.datasets.ImageNet(
data_path, split="val", transform=transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
]))
train_sampler = torch.utils.data.RandomSampler(dataset)
test_sampler = torch.utils.data.SequentialSampler(dataset_test)
data_loader = torch.utils.data.DataLoader(
dataset, batch_size=train_batch_size,
sampler=train_sampler)
data_loader_test = torch.utils.data.DataLoader(
dataset_test, batch_size=eval_batch_size,
sampler=test_sampler)
return data_loader, data_loader_test
接下来,我们将加载预训练的 MobileNetV2 模型。我们提供了下载模型的 URL here。
data_path = '~/.data/imagenet'
saved_model_dir = 'data/'
float_model_file = 'mobilenet_pretrained_float.pth'
scripted_float_model_file = 'mobilenet_quantization_scripted.pth'
scripted_quantized_model_file = 'mobilenet_quantization_scripted_quantized.pth'
train_batch_size = 30
eval_batch_size = 50
data_loader, data_loader_test = prepare_data_loaders(data_path)
criterion = nn.CrossEntropyLoss()
float_model = load_model(saved_model_dir + float_model_file).to('cpu')
# Next, we'll "fuse modules"; this can both make the model faster by saving on memory access
# while also improving numerical accuracy. While this can be used with any model, this is
# especially common with quantized models.
print('\n Inverted Residual Block: Before fusion \n\n', float_model.features[1].conv)
float_model.eval()
# Fuses modules
float_model.fuse_model()
# Note fusion of Conv+BN+Relu and Conv+Relu
print('\n Inverted Residual Block: After fusion\n\n',float_model.features[1].conv)
最后,为了获得“基线”准确性,让我们看看我们未量化模型与融合模块的准确性。
num_eval_batches = 1000
print("Size of baseline model")
print_size_of_model(float_model)
top1, top5 = evaluate(float_model, criterion, data_loader_test, neval_batches=num_eval_batches)
print('Evaluation accuracy on %d images, %2.2f'%(num_eval_batches * eval_batch_size, top1.avg))
torch.jit.save(torch.jit.script(float_model), saved_model_dir + scripted_float_model_file)
在整个模型上,我们在包含 50,000 张图像的评估数据集上获得了 71.9%的准确率。
这将是我们用来比较的基线。接下来,让我们尝试不同的量化方法
4. 后训练静态量化
静态后训练量化不仅涉及将权重从浮点转换为整数,如动态量化那样,还包括首先通过网络传递数据批次并计算不同激活的结果分布的额外步骤(具体来说,这是通过在不同点插入观察器模块记录这些数据来完成的)。然后使用这些分布来确定如何在推断时量化不同的激活(一个简单的技术是将整个激活范围分成 256 个级别,但我们也支持更复杂的方法)。重要的是,这个额外的步骤允许我们在操作之间传递量化值,而不是在每个操作之间将这些值转换为浮点数 - 然后再转换为整数,从而实现显著的加速。
num_calibration_batches = 32
myModel = load_model(saved_model_dir + float_model_file).to('cpu')
myModel.eval()
# Fuse Conv, bn and relu
myModel.fuse_model()
# Specify quantization configuration
# Start with simple min/max range estimation and per-tensor quantization of weights
myModel.qconfig = torch.ao.quantization.default_qconfig
print(myModel.qconfig)
torch.ao.quantization.prepare(myModel, inplace=True)
# Calibrate first
print('Post Training Quantization Prepare: Inserting Observers')
print('\n Inverted Residual Block:After observer insertion \n\n', myModel.features[1].conv)
# Calibrate with the training set
evaluate(myModel, criterion, data_loader, neval_batches=num_calibration_batches)
print('Post Training Quantization: Calibration done')
# Convert to quantized model
torch.ao.quantization.convert(myModel, inplace=True)
# You may see a user warning about needing to calibrate the model. This warning can be safely ignored.
# This warning occurs because not all modules are run in each model runs, so some
# modules may not be calibrated.
print('Post Training Quantization: Convert done')
print('\n Inverted Residual Block: After fusion and quantization, note fused modules: \n\n',myModel.features[1].conv)
print("Size of model after quantization")
print_size_of_model(myModel)
top1, top5 = evaluate(myModel, criterion, data_loader_test, neval_batches=num_eval_batches)
print('Evaluation accuracy on %d images, %2.2f'%(num_eval_batches * eval_batch_size, top1.avg))
对于这个量化模型,在评估数据集上看到准确率为 56.7%。这是因为我们使用简单的最小/最大观察器来确定量化参数。尽管如此,我们将模型的大小减小到了将近 3.6 MB,几乎减少了 4 倍。
此外,我们可以通过使用不同的量化配置显着提高准确性。我们使用为 x86 架构量化推荐的配置重复相同的练习。此配置执行以下操作:
-
按通道对权重进行量化
-
使用直方图观察器收集激活的直方图,然后以最佳方式选择量化参数。
per_channel_quantized_model = load_model(saved_model_dir + float_model_file)
per_channel_quantized_model.eval()
per_channel_quantized_model.fuse_model()
# The old 'fbgemm' is still available but 'x86' is the recommended default.
per_channel_quantized_model.qconfig = torch.ao.quantization.get_default_qconfig('x86')
print(per_channel_quantized_model.qconfig)
torch.ao.quantization.prepare(per_channel_quantized_model, inplace=True)
evaluate(per_channel_quantized_model,criterion, data_loader, num_calibration_batches)
torch.ao.quantization.convert(per_channel_quantized_model, inplace=True)
top1, top5 = evaluate(per_channel_quantized_model, criterion, data_loader_test, neval_batches=num_eval_batches)
print('Evaluation accuracy on %d images, %2.2f'%(num_eval_batches * eval_batch_size, top1.avg))
torch.jit.save(torch.jit.script(per_channel_quantized_model), saved_model_dir + scripted_quantized_model_file)
仅改变这种量化配置方法就使准确率提高到 67.3%以上!但是,这仍然比上面实现的 71.9%的基准差 4%。所以让我们尝试量化感知训练。
5. 量化感知训练
量化感知训练(QAT)通常是产生最高准确率的量化方法。使用 QAT 时,在训练的前向和后向传递中,所有权重和激活都被“伪量化”:即,浮点值被四舍五入以模拟 int8 值,但所有计算仍然使用浮点数。因此,在训练期间进行的所有权重调整都是在“意识到”模型最终将被量化的情况下进行的;因此,在量化之后,这种方法通常会产生比动态量化或静态后训练量化更高的准确率。
实际执行 QAT 的整体工作流程与以前非常相似:
-
我们可以使用与以前相同的模型:对于量化感知训练,不需要额外的准备工作。
-
我们需要使用一个
qconfig指定在权重和激活之后要插入什么样的伪量化,而不是指定观察器
我们首先定义一个训练函数:
def train_one_epoch(model, criterion, optimizer, data_loader, device, ntrain_batches):
model.train()
top1 = AverageMeter('Acc@1', ':6.2f')
top5 = AverageMeter('Acc@5', ':6.2f')
avgloss = AverageMeter('Loss', '1.5f')
cnt = 0
for image, target in data_loader:
start_time = time.time()
print('.', end = '')
cnt += 1
image, target = image.to(device), target.to(device)
output = model(image)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc1, acc5 = accuracy(output, target, topk=(1, 5))
top1.update(acc1[0], image.size(0))
top5.update(acc5[0], image.size(0))
avgloss.update(loss, image.size(0))
if cnt >= ntrain_batches:
print('Loss', avgloss.avg)
print('Training: * Acc@1 {top1.avg:.3f} Acc@5 {top5.avg:.3f}'
.format(top1=top1, top5=top5))
return
print('Full imagenet train set: * Acc@1 {top1.global_avg:.3f} Acc@5 {top5.global_avg:.3f}'
.format(top1=top1, top5=top5))
return
我们像以前一样融合模块
qat_model = load_model(saved_model_dir + float_model_file)
qat_model.fuse_model(is_qat=True)
optimizer = torch.optim.SGD(qat_model.parameters(), lr = 0.0001)
# The old 'fbgemm' is still available but 'x86' is the recommended default.
qat_model.qconfig = torch.ao.quantization.get_default_qat_qconfig('x86')
最后,prepare_qat执行“伪量化”,为量化感知训练准备模型
torch.ao.quantization.prepare_qat(qat_model, inplace=True)
print('Inverted Residual Block: After preparation for QAT, note fake-quantization modules \n',qat_model.features[1].conv)
训练一个准确率高的量化模型需要准确地模拟推断时的数值。因此,对于量化感知训练,我们通过修改训练循环来进行:
-
在训练结束时切换批量归一化以使用运行时均值和方差,以更好地匹配推断数值。
-
我们还会冻结量化器参数(比例和零点)并微调权重。
num_train_batches = 20
# QAT takes time and one needs to train over a few epochs.
# Train and check accuracy after each epoch
for nepoch in range(8):
train_one_epoch(qat_model, criterion, optimizer, data_loader, torch.device('cpu'), num_train_batches)
if nepoch > 3:
# Freeze quantizer parameters
qat_model.apply(torch.ao.quantization.disable_observer)
if nepoch > 2:
# Freeze batch norm mean and variance estimates
qat_model.apply(torch.nn.intrinsic.qat.freeze_bn_stats)
# Check the accuracy after each epoch
quantized_model = torch.ao.quantization.convert(qat_model.eval(), inplace=False)
quantized_model.eval()
top1, top5 = evaluate(quantized_model,criterion, data_loader_test, neval_batches=num_eval_batches)
print('Epoch %d :Evaluation accuracy on %d images, %2.2f'%(nepoch, num_eval_batches * eval_batch_size, top1.avg))
量化感知训练在整个 imagenet 数据集上的准确率超过 71.5%,接近 71.9%的浮点准确率。
更多关于量化感知训练:
-
QAT 是一种超集,包含了更多的调试后量化技术。例如,我们可以分析模型的准确性是否受到权重或激活量化的限制。
-
由于我们使用伪量化来模拟实际量化算术的数值,因此我们还可以模拟量化模型在浮点数上的准确性。
-
我们也可以轻松地模拟后训练量化。
从量化中加速
最后,让我们确认我们上面提到的一点:我们的量化模型是否确实执行推断更快?让我们测试一下:
def run_benchmark(model_file, img_loader):
elapsed = 0
model = torch.jit.load(model_file)
model.eval()
num_batches = 5
# Run the scripted model on a few batches of images
for i, (images, target) in enumerate(img_loader):
if i < num_batches:
start = time.time()
output = model(images)
end = time.time()
elapsed = elapsed + (end-start)
else:
break
num_images = images.size()[0] * num_batches
print('Elapsed time: %3.0f ms' % (elapsed/num_images*1000))
return elapsed
run_benchmark(saved_model_dir + scripted_float_model_file, data_loader_test)
run_benchmark(saved_model_dir + scripted_quantized_model_file, data_loader_test)
在 MacBook Pro 上本地运行,常规模型的运行时间为 61 毫秒,量化模型仅为 20 毫秒,显示了与浮点模型相比,我们通常看到的 2-4 倍加速。
结论
在本教程中,我们展示了两种量化方法 - 后训练静态量化和量化感知训练 - 描述了它们在 PyTorch 中的使用方法。
感谢阅读!我们始终欢迎任何反馈意见,如果您有任何问题,请在这里创建一个问题。
从第一原则理解 PyTorch Intel CPU 性能
原文:
pytorch.org/tutorials/intermediate/torchserve_with_ipex.html译者:飞龙
协议:CC BY-NC-SA 4.0
一个关于使用Intel® PyTorch 扩展*优化的 TorchServe 推理框架的案例研究。
作者:Min Jean Cho, Mark Saroufim
审阅者:Ashok Emani, Jiong Gong
在 CPU 上获得强大的深度学习开箱即用性能可能有些棘手,但如果您了解影响性能的主要问题,如何衡量它们以及如何解决它们,那么就会更容易。
简而言之
| 问题 | 如何衡量 | 解决方案 |
|---|---|---|
| 瓶颈的 GEMM 执行单元 |
-
不平衡或串行旋转
-
前端受限
-
核心受限
| 通过核心固定将线程亲和性设置为物理核心以避免使用逻辑核心 |
|---|
| 非均匀内存访问(NUMA) |
-
本地与远程内存访问
-
UPI 利用率
-
内存访问延迟
-
线程迁移
| 通过核心固定将线程亲和性设置为特定插槽以避免跨插槽计算 |
|---|
GEMM(通用矩阵乘法)在融合乘加(FMA)或点积(DP)执行单元上运行,这将成为瓶颈,并在启用超线程时导致线程等待/旋转在同步屏障时出现延迟 - 因为使用逻辑核心会导致所有工作线程的并发性不足,因为每个逻辑线程争夺相同的核心资源。相反,如果我们每个物理核心使用 1 个线程,我们就可以避免这种争夺。因此,我们通常建议通过核心固定将 CPU 线程亲和性设置为物理核心,从而避免逻辑核心。
多插槽系统具有非均匀内存访问(NUMA),这是一种共享内存架构,描述了主存储模块相对于处理器的放置方式。但是,如果一个进程不是 NUMA 感知的,那么在运行时,当线程通过Intel Ultra Path Interconnect (UPI)跨插槽迁移时,会频繁访问慢远程内存。我们通过将 CPU 线程亲和性设置为特定插槽以通过核心固定解决这个问题。
牢记这些原则,适当的 CPU 运行时配置可以显著提升开箱即用的性能。
在这篇博客中,我们将带您了解CPU 性能调优指南中应该注意的重要运行时配置,解释它们的工作原理,如何对其进行分析以及如何将其集成到像TorchServe这样的模型服务框架中,通过一个易于使用的启动脚本,我们已经原生地集成了。
我们将从第一原则以及大量概要中直观地解释所有这些想法,并向您展示我们如何应用我们的学习,以改善 TorchServe 的开箱即用 CPU 性能。
- 必须通过在config.properties中设置cpu_launcher_enable=true来显式启用该功能。
避免逻辑核心进行深度学习
通常,避免逻辑核心进行深度学习工作负载会提高性能。为了理解这一点,让我们回到 GEMM。
优化 GEMM 优化深度学习
深度学习训练或推断中的大部分时间都花在了 GEMM 的数百万次重复操作上,这是完全连接层的核心。自从多层感知器(MLP)被证明是任何连续函数的通用逼近器以来,完全连接层已经被使用了几十年。任何 MLP 都可以完全表示为 GEMM。甚至卷积也可以通过使用Toepliz 矩阵表示为 GEMM。
回到原来的话题,大多数 GEMM 运算符受益于使用非超线程,因为深度学习训练或推断中的大部分时间都花在了运行在超线程核心上的融合乘加(FMA)或点积(DP)执行单元上的数百万次重复操作上。启用超线程后,OpenMP 线程将争夺相同的 GEMM 执行单元。
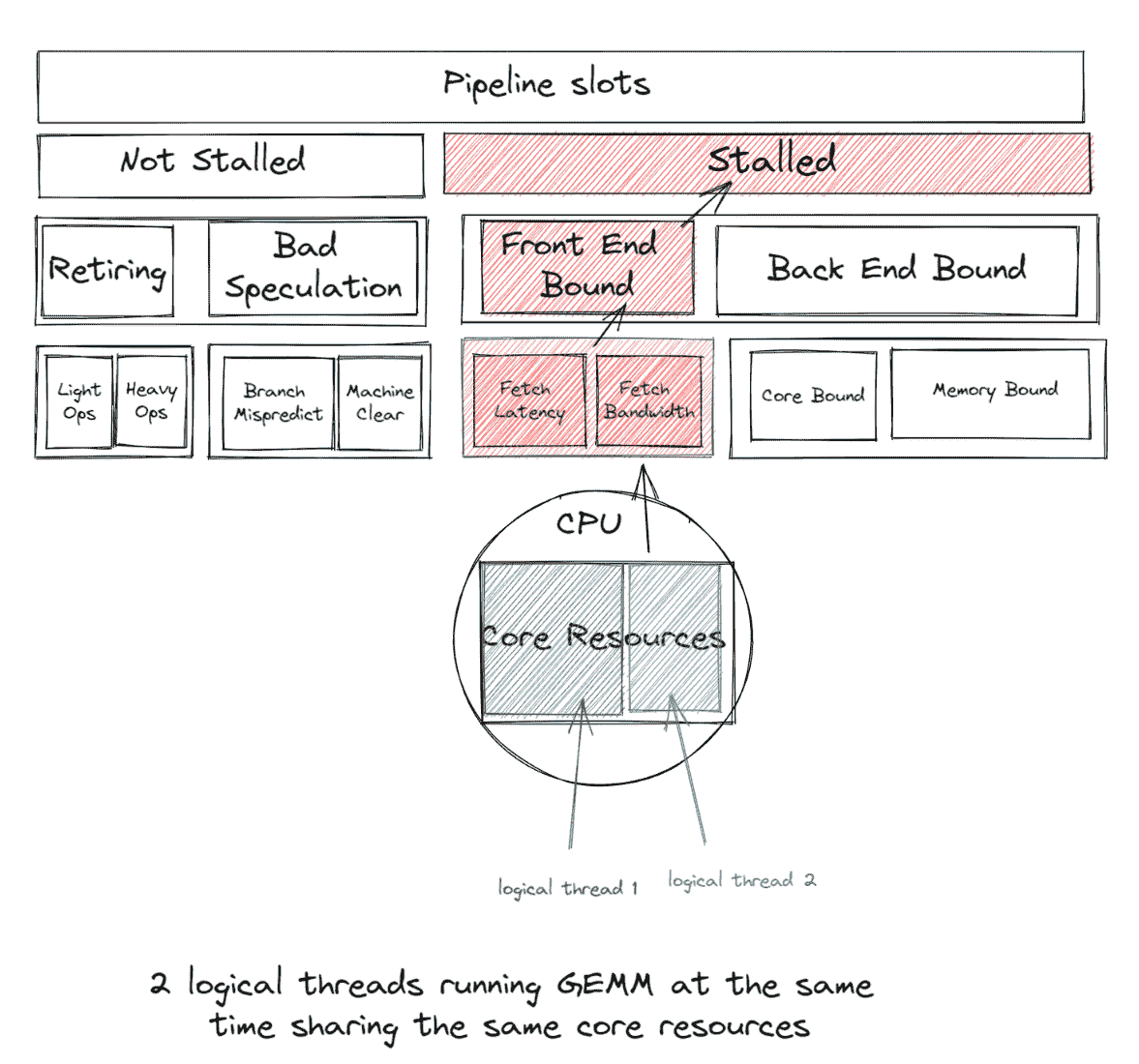
如果 2 个逻辑线程同时运行 GEMM,它们将共享相同的核心资源,导致前端绑定,这样前端绑定带来的开销大于同时运行两个逻辑线程带来的收益。
因此,我们通常建议避免在深度学习工作负载中使用逻辑核心以获得良好的性能。默认情况下,启动脚本仅使用物理核心;但是,用户可以通过简单切换--use_logical_core启动脚本旋钮来轻松尝试逻辑核心与物理核心。
练习
我们将使用以下示例来提供 ResNet50 虚拟张量:
import torch
import torchvision.models as models
import time
model = models.resnet50(pretrained=False)
model.eval()
data = torch.rand(1, 3, 224, 224)
# warm up
for _ in range(100):
model(data)
start = time.time()
for _ in range(100):
model(data)
end = time.time()
print('Inference took {:.2f} ms in average'.format((end-start)/100*1000))
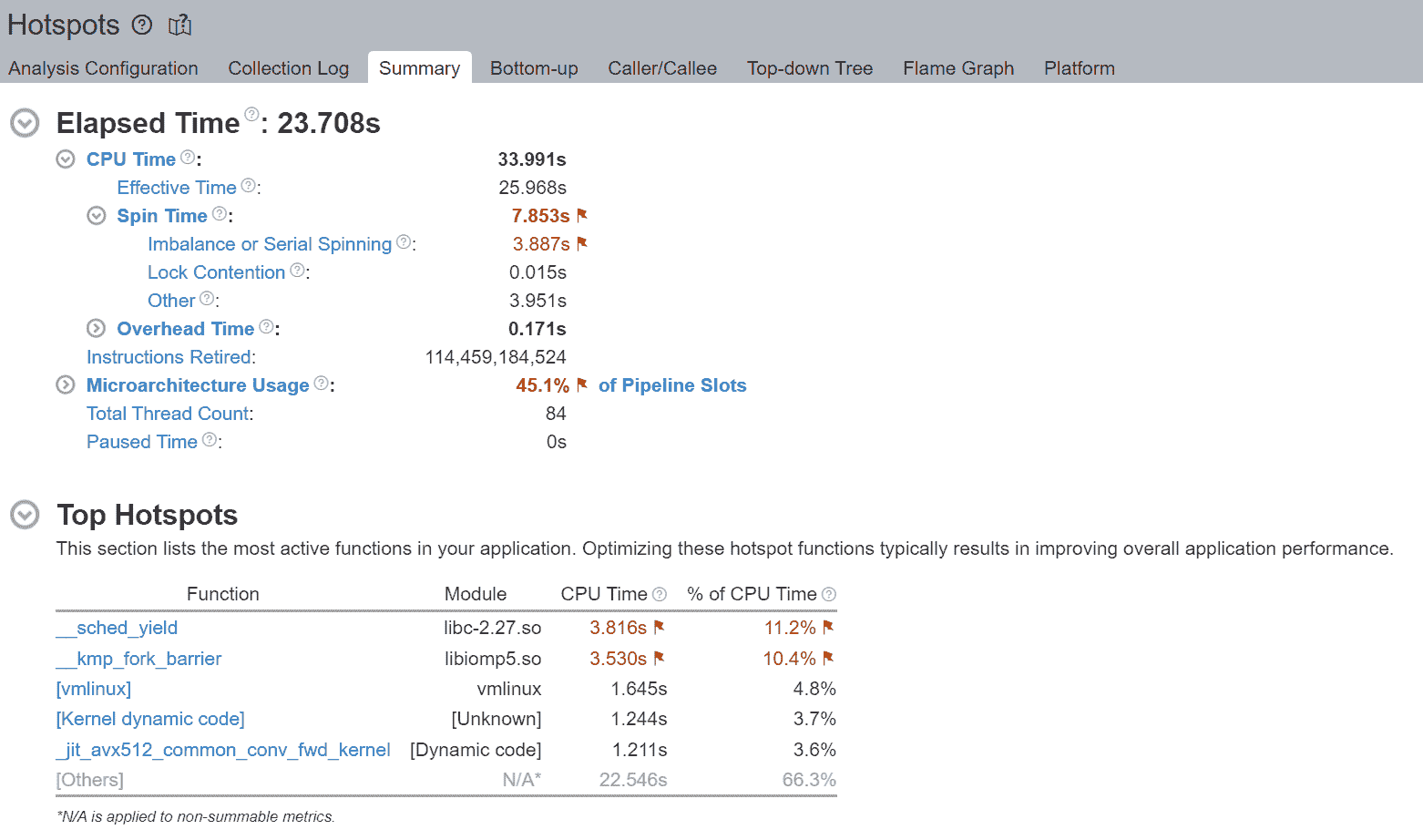
在博客中,我们将使用Intel® VTune™ Profiler来进行分析和验证优化。我们将在一台配备两个 Intel® Xeon® Platinum 8180M CPU 的机器上运行所有练习。CPU 信息如图 2.1 所示。
环境变量OMP_NUM_THREADS用于设置并行区域的线程数。我们将比较OMP_NUM_THREADS=2与(1)使用逻辑核心和(2)仅使用物理核心。
- 两个 OpenMP 线程尝试利用由超线程核心(0, 56)共享的相同 GEMM 执行单元
我们可以通过在 Linux 上运行htop命令来可视化这一点。
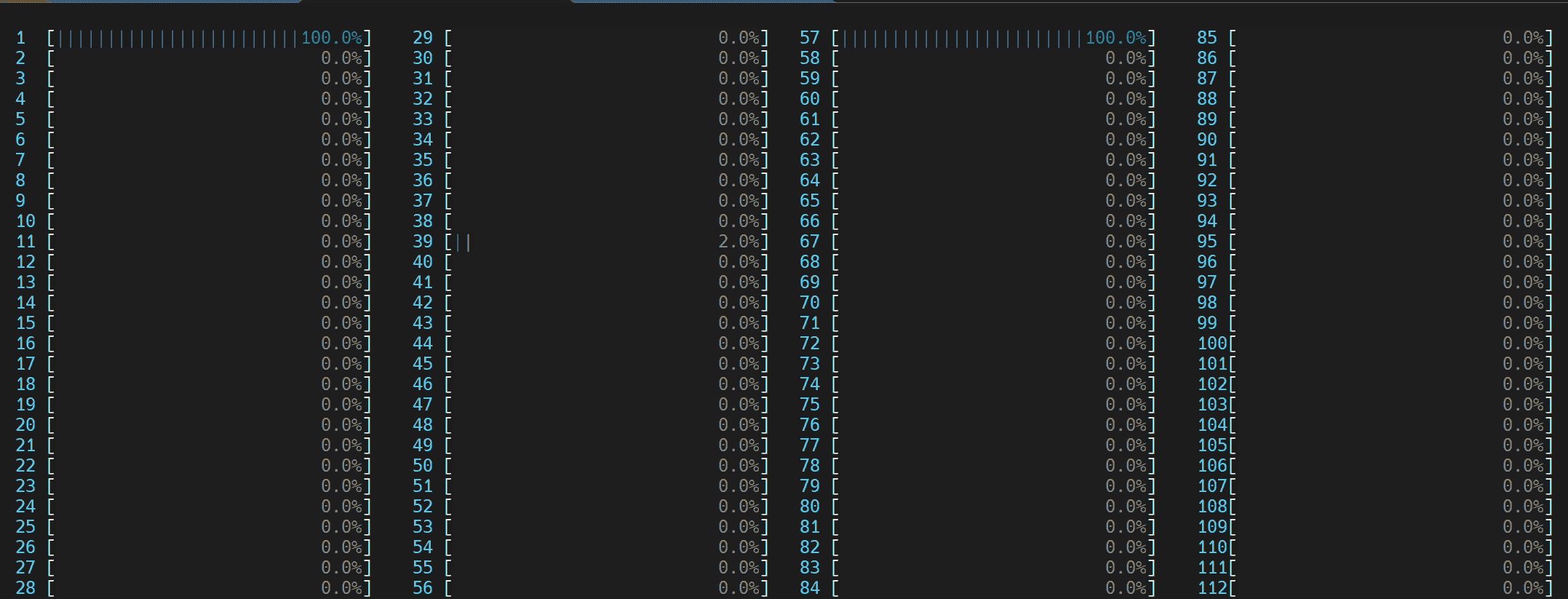
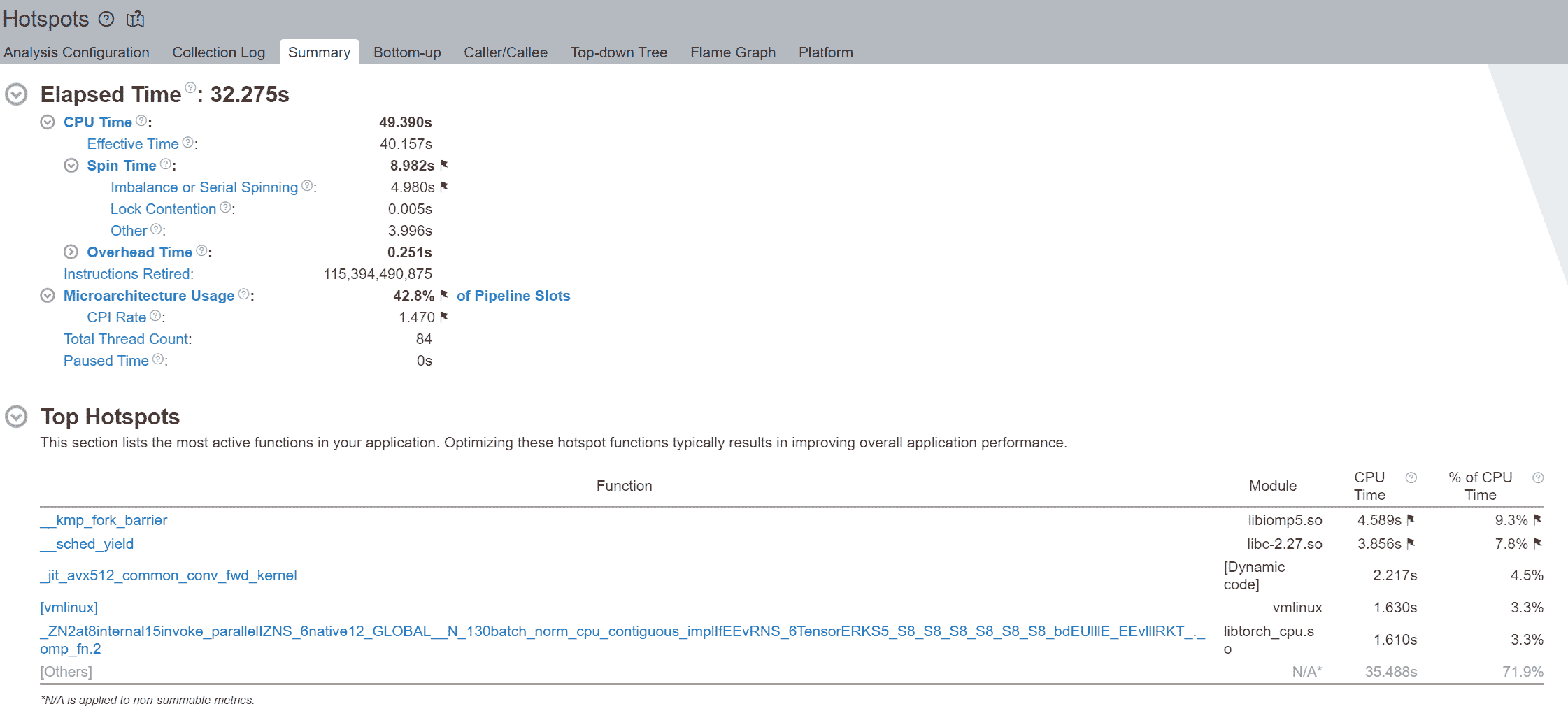
我们注意到旋转时间被标记,并且不平衡或串行旋转占据了大部分时间 - 在总共 8.982 秒中的 4.980 秒。使用逻辑核心时的不平衡或串行旋转是由于工作线程的并发性不足,因为每个逻辑线程争夺相同的核心资源。
执行摘要的 Top Hotspots 部分显示,__kmp_fork_barrier占用了 4.589 秒的 CPU 时间 - 在 CPU 执行时间的 9.33%期间,线程在这个屏障处旋转以进行线程同步。
- 每个 OpenMP 线程利用各自物理核心(0,1)中的 GEMM 执行单元
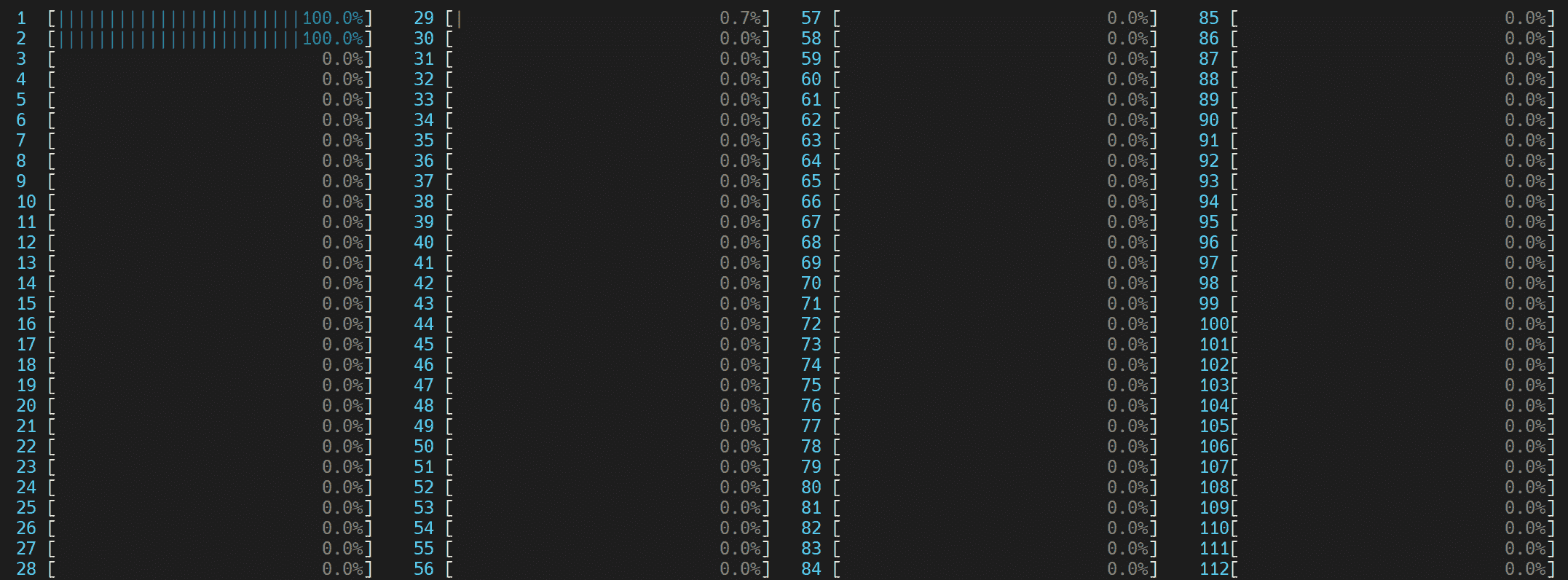
我们首先注意到,通过避免逻辑核心,执行时间从 32 秒降至 23 秒。虽然仍存在一些不可忽略的不平衡或串行旋转,但我们注意到从 4.980 秒到 3.887 秒的相对改善。
通过不使用逻辑线程(而是每个物理核心使用 1 个线程),我们避免了逻辑线程争夺相同核心资源。Top Hotspots 部分还显示了__kmp_fork_barrier时间从 4.589 秒改善到 3.530 秒的相对改善。
本地内存访问始终比远程内存访问快。
通常我们建议将一个进程绑定到本地插槽,以便该进程不会在不同插槽之间迁移。通常这样做的目的是利用本地内存上的高速缓存,并避免远程内存访问,后者可能慢大约 2 倍。
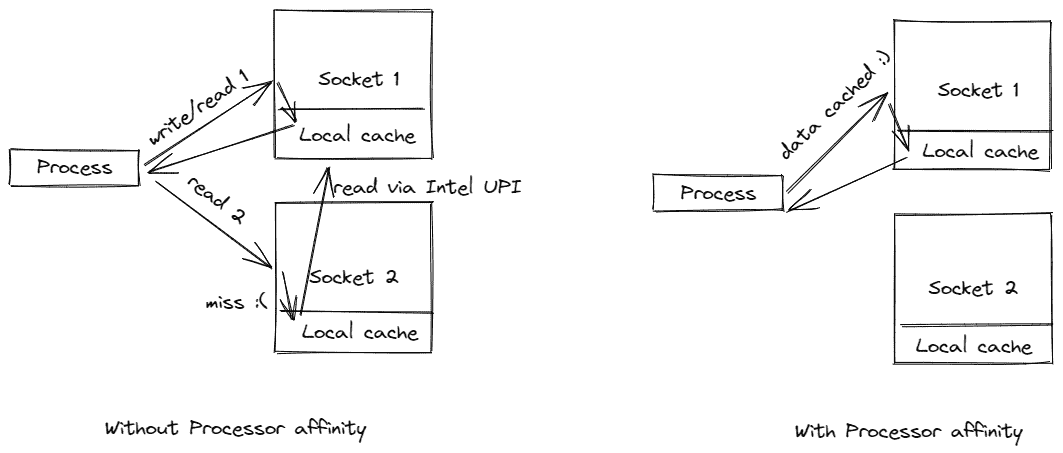
图 1. 双插槽配置
图 1. 显示了一个典型的双插槽配置。请注意,每个插槽都有自己的本地内存。插槽通过 Intel Ultra Path Interconnect (UPI)连接到彼此,这允许每个插槽访问另一个插槽的本地内存,称为远程内存。本地内存访问始终比远程内存访问快。
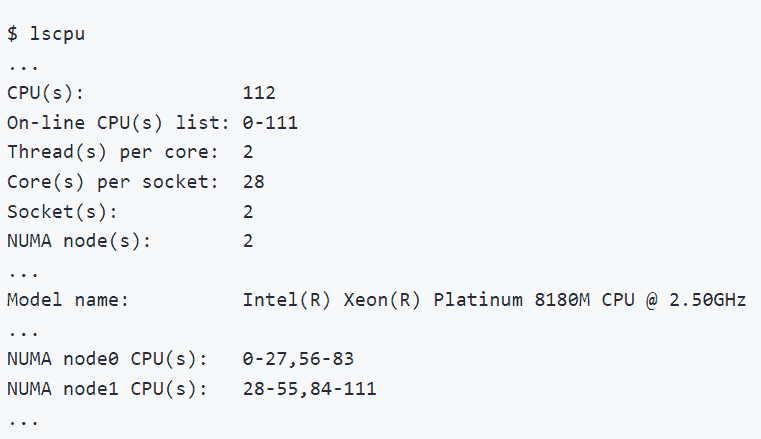
图 2.1. CPU 信息
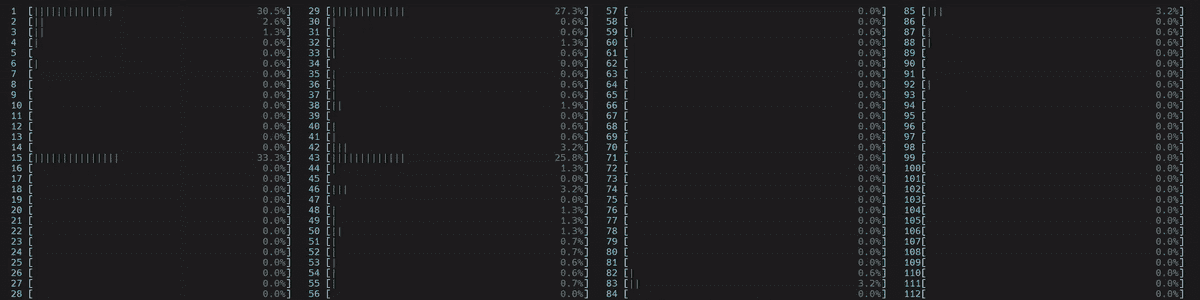
用户可以通过在他们的 Linux 机器上运行lscpu命令来获取他们的 CPU 信息。图 2.1. 显示了在一台装有两个 Intel® Xeon® Platinum 8180M CPU 的机器上执行lscpu的示例。请注意,每个插槽有 28 个核心,每个核心有 2 个线程(即启用了超线程)。换句话说,除了 28 个物理核心外,还有 28 个逻辑核心,每个插槽总共有 56 个核心。而且有 2 个插槽,总共有 112 个核心(每个核心的线程数 x 每个插槽的核心数 x 插槽数)。
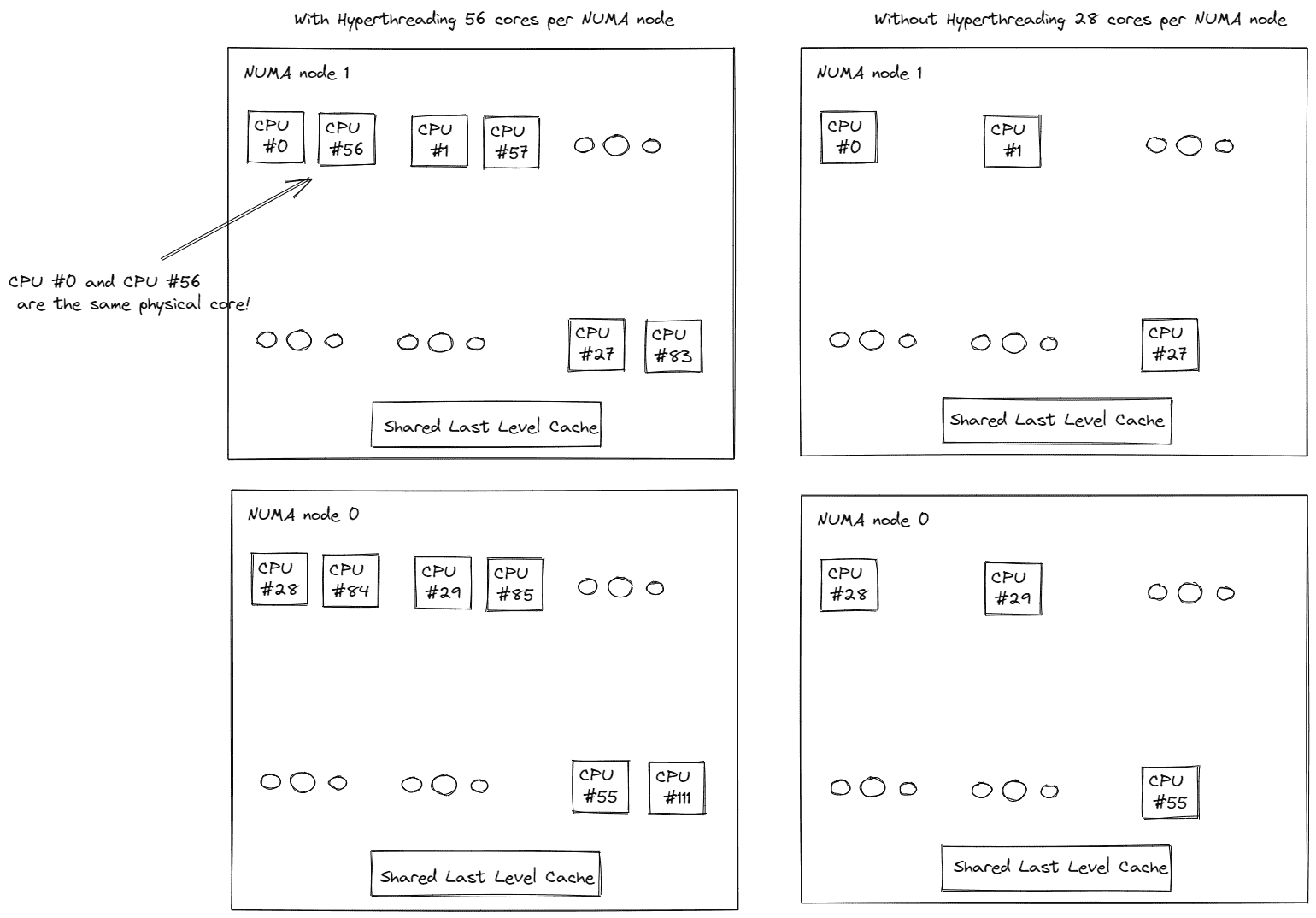
图 2.2. CPU 信息
这 2 个插槽分别映射到 2 个 NUMA 节点(NUMA 节点 0,NUMA 节点 1)。物理核心在逻辑核心之前进行索引。如图 2.2.所示,第一个插槽上的前 28 个物理核心(0-27)和前 28 个逻辑核心(56-83)位于 NUMA 节点 0。第二个插槽上的第 28 个物理核心(28-55)和第二个插槽上的第 28 个逻辑核心(84-111)位于 NUMA 节点 1。同一插槽上的核心共享本地内存和最后一级缓存(LLC),比通过 Intel UPI 进行跨插槽通信要快得多。
现在我们了解了 NUMA、跨插槽(UPI)流量、多处理器系统中的本地与远程内存访问,让我们对其进行分析和验证。
练习
我们将重用上面的 ResNet50 示例。
由于我们没有将线程固定到特定插槽的处理器核心上,操作系统会定期将线程调度到位于不同插槽中的处理器核心上。
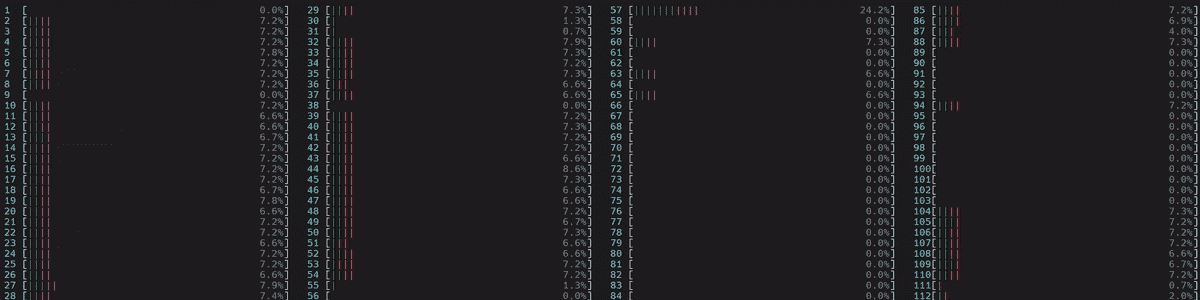
图 3. 非 NUMA 感知应用程序的 CPU 使用情况。启动了 1 个主工作线程,然后在所有核心上启动了一个物理核心编号(56)的线程,包括逻辑核心。
(附注:如果线程数未通过torch.set_num_threads设置,那么默认线程数是启用超线程系统中的物理核心数。这可以通过torch.get_num_threads来验证。因此,我们看到大约一半的核心忙于运行示例脚本。)

图 4. 非均匀内存访问分析图
图 4. 比较了随时间变化的本地与远程内存访问。我们验证了远程内存的使用,这可能导致性能不佳。
设置线程亲和性以减少远程内存访问和跨插槽(UPI)流量
将线程固定到同一插槽上的核心有助于保持内存访问的局部性。在这个例子中,我们将固定到第一个 NUMA 节点上的物理核心(0-27)。通过启动脚本,用户可以通过简单切换--node_id启动脚本旋钮来轻松尝试 NUMA 节点配置。
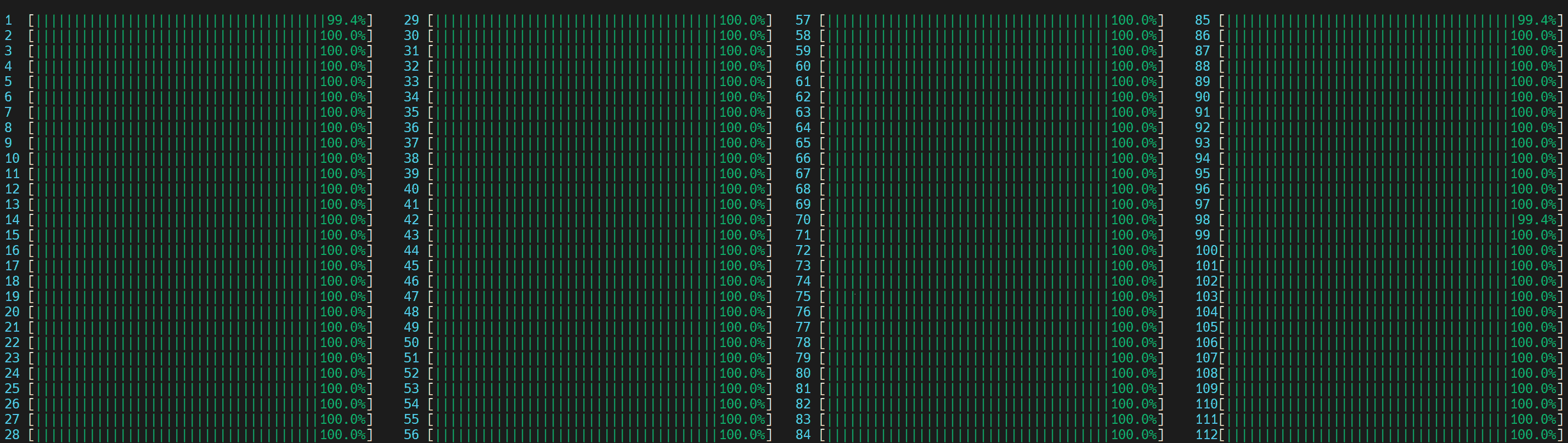
让我们现在来可视化 CPU 使用情况。
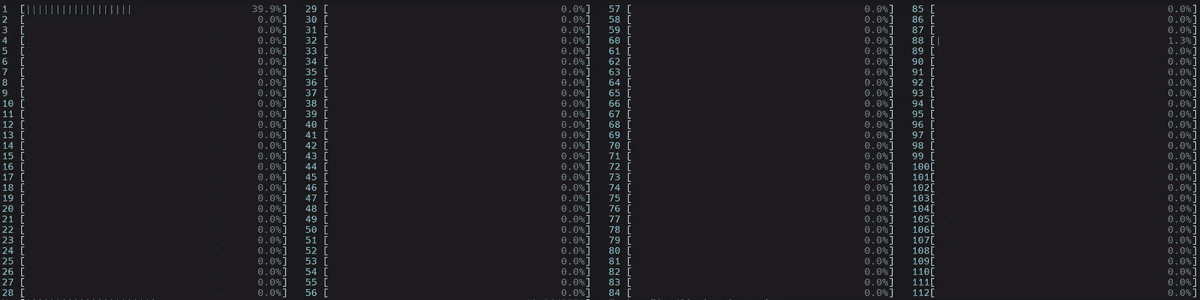
图 5. NUMA 感知应用程序的 CPU 使用情况
启动了 1 个主要工作线程,然后在第一个 NUMA 节点上的所有物理核心上启动了线程。

图 6. 非均匀内存访问分析图
如图 6 所示,现在几乎所有的内存访问都是本地访问。
通过核心固定实现多工作线程推理的高效 CPU 使用率
在运行多工作线程推理时,核心在工作线程之间重叠(或共享),导致 CPU 使用效率低下。为了解决这个问题,启动脚本将可用核心数均等地分配给每个工作线程,使每个工作线程在运行时固定到分配的核心。
使用 TorchServe 进行练习
在这个练习中,让我们将我们迄今讨论过的 CPU 性能调优原则和建议应用到TorchServe apache-bench 基准测试。
我们将使用 ResNet50 进行 4 个工作线程,并发数为 100,请求为 10,000。所有其他参数(例如,batch_size,输入等)与默认参数相同。
我们将比较以下三种配置:
-
默认的 TorchServe 设置(没有核心固定)
-
torch.set_num_threads =
物理核心数 / 工作线程数(没有核心固定) -
通过启动脚本进行核心固定(要求 Torchserve>=0.6.1)
经过这个练习,我们将验证我们更喜欢避免逻辑核心,而是通过核心固定实现本地内存访问,使用真实的 TorchServe 用例。
1. 默认的 TorchServe 设置(没有核心固定)
base_handler没有明确设置torch.set_num_threads。因此,默认线程数是物理 CPU 核心数,如这里所述。用户可以通过在 base_handler 中使用torch.get_num_threads来检查线程数。每个 4 个主要工作线程启动了一个物理核心数(56)的线程,总共启动了 56x4 = 224 个线程,这比总核心数 112 多。因此,核心肯定会严重重叠,逻辑核心利用率高-多个工作线程同时使用多个核心。此外,由于线程没有固定到特定的 CPU 核心,操作系统会定期将线程调度到位于不同插槽中的核心。
- CPU 使用率
启动了 4 个主要工作线程,然后每个线程在所有核心上启动了一个物理核心数(56)的线程,包括逻辑核心。
- 核心绑定停顿
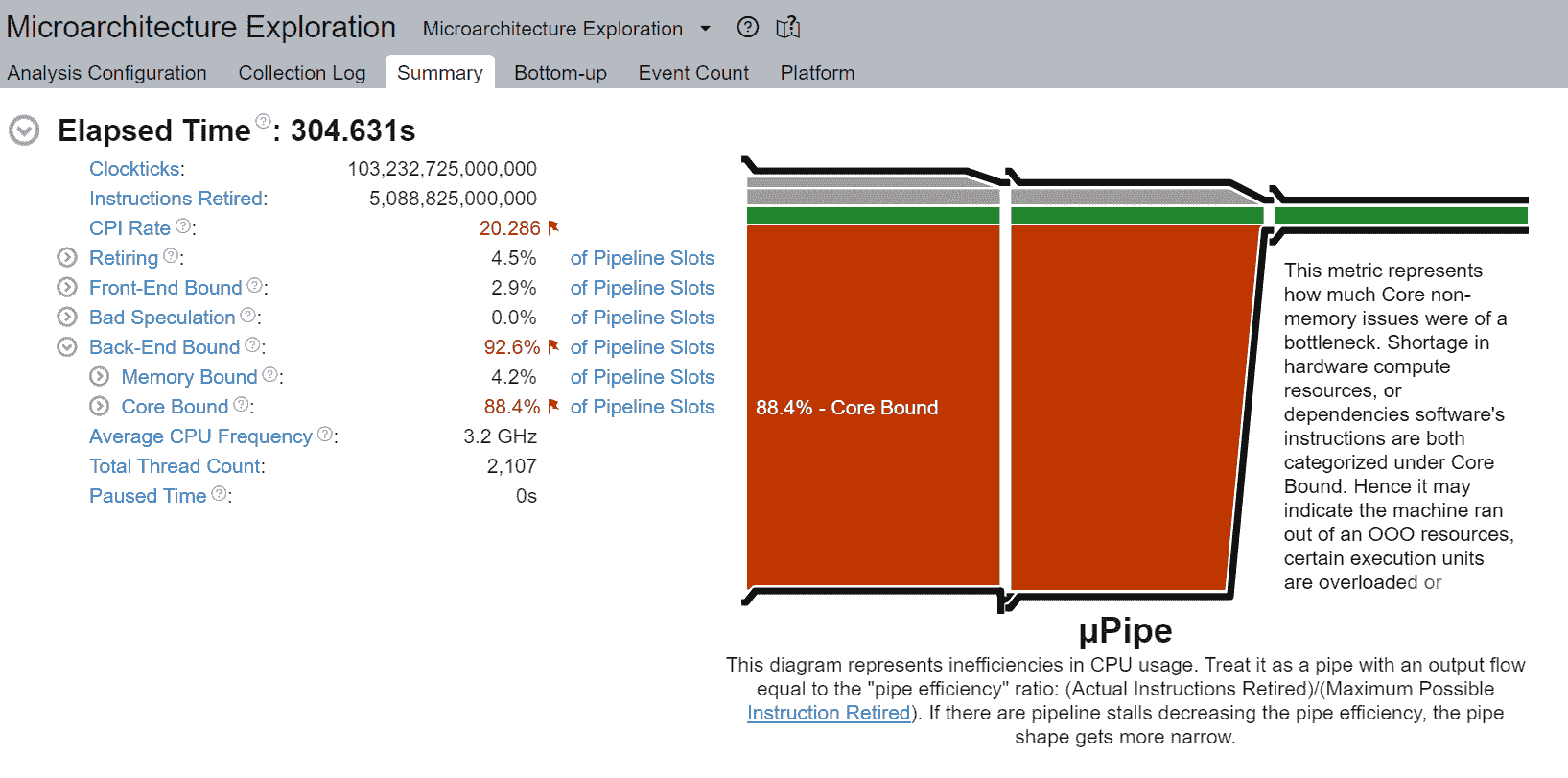
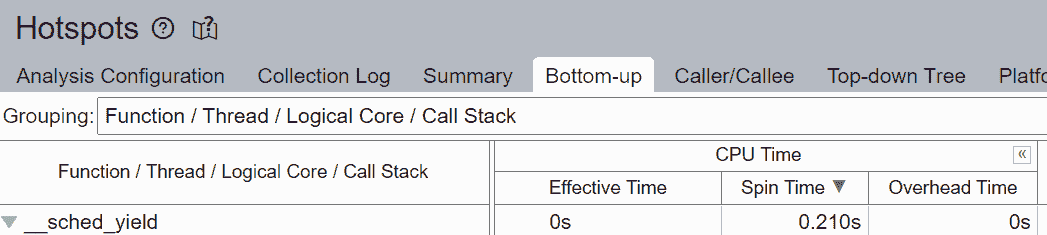
我们观察到 88.4%的非均匀内存访问,降低了管道效率。核心绑定停顿表示 CPU 中可用执行单元的使用不佳。例如,连续的几个 GEMM 指令竞争由超线程核心共享的融合乘加(FMA)或点积(DP)执行单元可能导致核心绑定停顿。正如前一节所述,逻辑核心的使用加剧了这个问题。
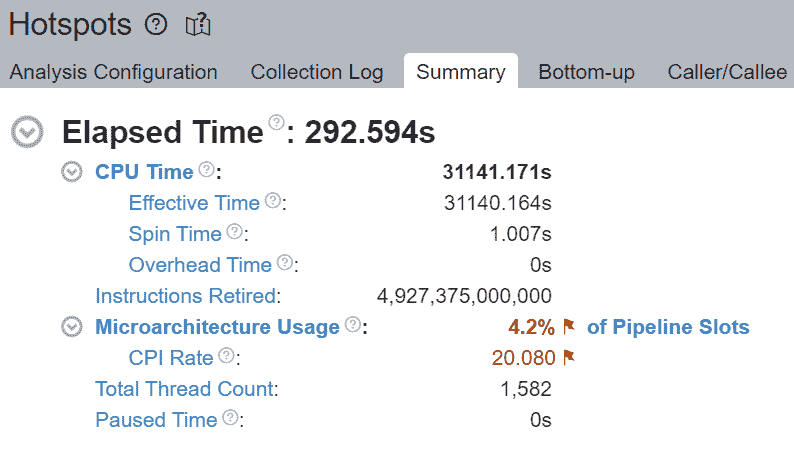
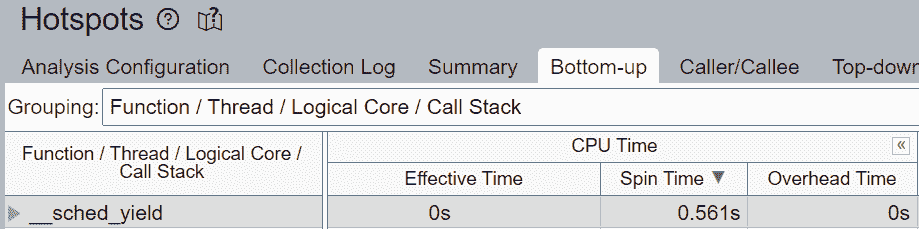
未填充微操作(uOps)的空管道槽位被归因于停顿。例如,没有核心固定时,CPU 使用率可能不会有效地用于计算,而是用于来自 Linux 内核的其他操作,如线程调度。我们可以看到__sched_yield贡献了大部分自旋时间。
- 线程迁移
没有核心固定,调度程序可能会将在一个核心上执行的线程迁移到另一个核心。线程迁移可能会使线程与已经获取到缓存中的数据分离,导致更长的数据访问延迟。在 NUMA 系统中,当线程在插座之间迁移时,这个问题会加剧。已经获取到本地内存高速缓存的数据现在变成了远程内存,速度要慢得多。
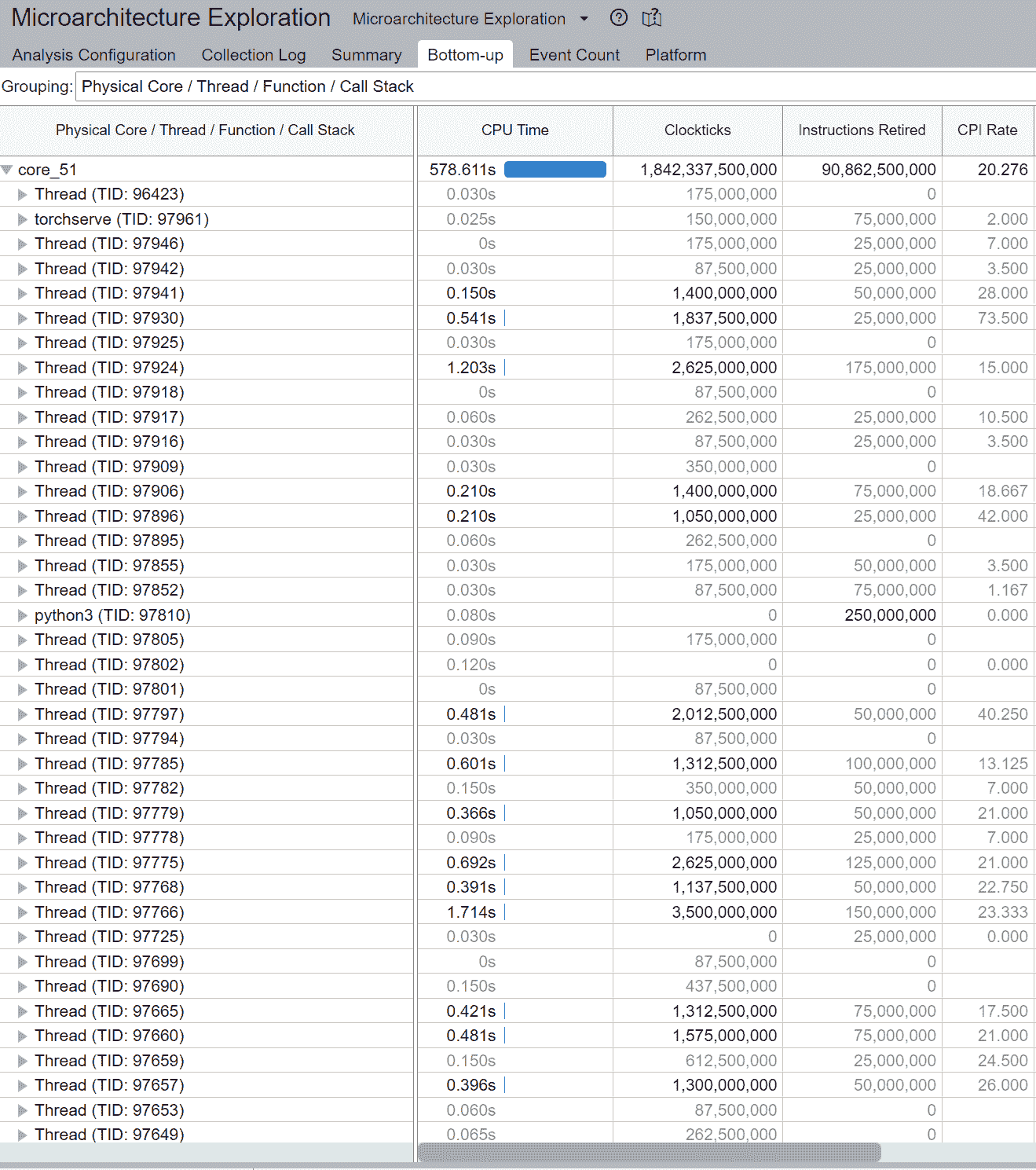
通常,总线程数应小于或等于核心支持的总线程数。在上面的示例中,我们注意到大量线程在 core_51 上执行,而不是预期的 2 个线程(因为 Intel® Xeon® Platinum 8180 CPU 启用了超线程)。这表明线程迁移。

此外,请注意线程(TID:97097)正在大量 CPU 核心上执行,表明 CPU 迁移。例如,此线程在 cpu_81 上执行,然后迁移到 cpu_14,然后迁移到 cpu_5,依此类推。此外,请注意此线程多次在不同插槽之间迁移,导致内存访问非常低效。例如,此线程在 cpu_70(NUMA 节点 0)上执行,然后迁移到 cpu_100(NUMA 节点 1),然后迁移到 cpu_24(NUMA 节点 0)。
- 非均匀内存访问分析

比较随时间变化的本地与远程内存访问。我们观察到大约一半,即 51.09%,的内存访问是远程访问,表明 NUMA 配置不佳。
2. torch.set_num_threads = 物理核心数/工作线程数(无核心固定)
为了与启动器的核心固定进行苹果对苹果的比较,我们将将线程数设置为核心数除以工作线程数(启动器在内部执行此操作)。在base_handler中添加以下代码片段:
torch.set_num_threads(num_physical_cores/num_workers)
与之前一样,没有核心固定,这些线程没有与特定 CPU 核心关联,导致操作系统周期性地在位于不同插座的核心上调度线程。
- CPU 使用率
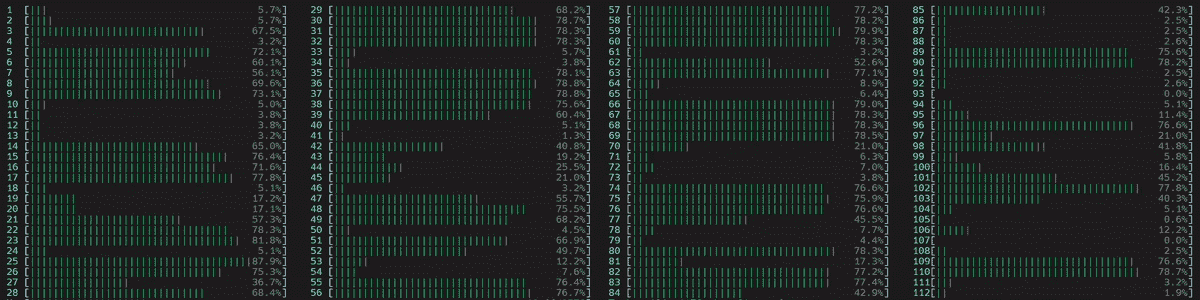
启动了 4 个主要工作线程,然后每个线程在所有核心上启动了num_physical_cores/num_workers(14)个线程,包括逻辑核心。
- 核心绑定停顿
尽管核心绑定停顿的百分比从 88.4%降至 73.5%,但核心绑定仍然非常高。
- 线程迁移
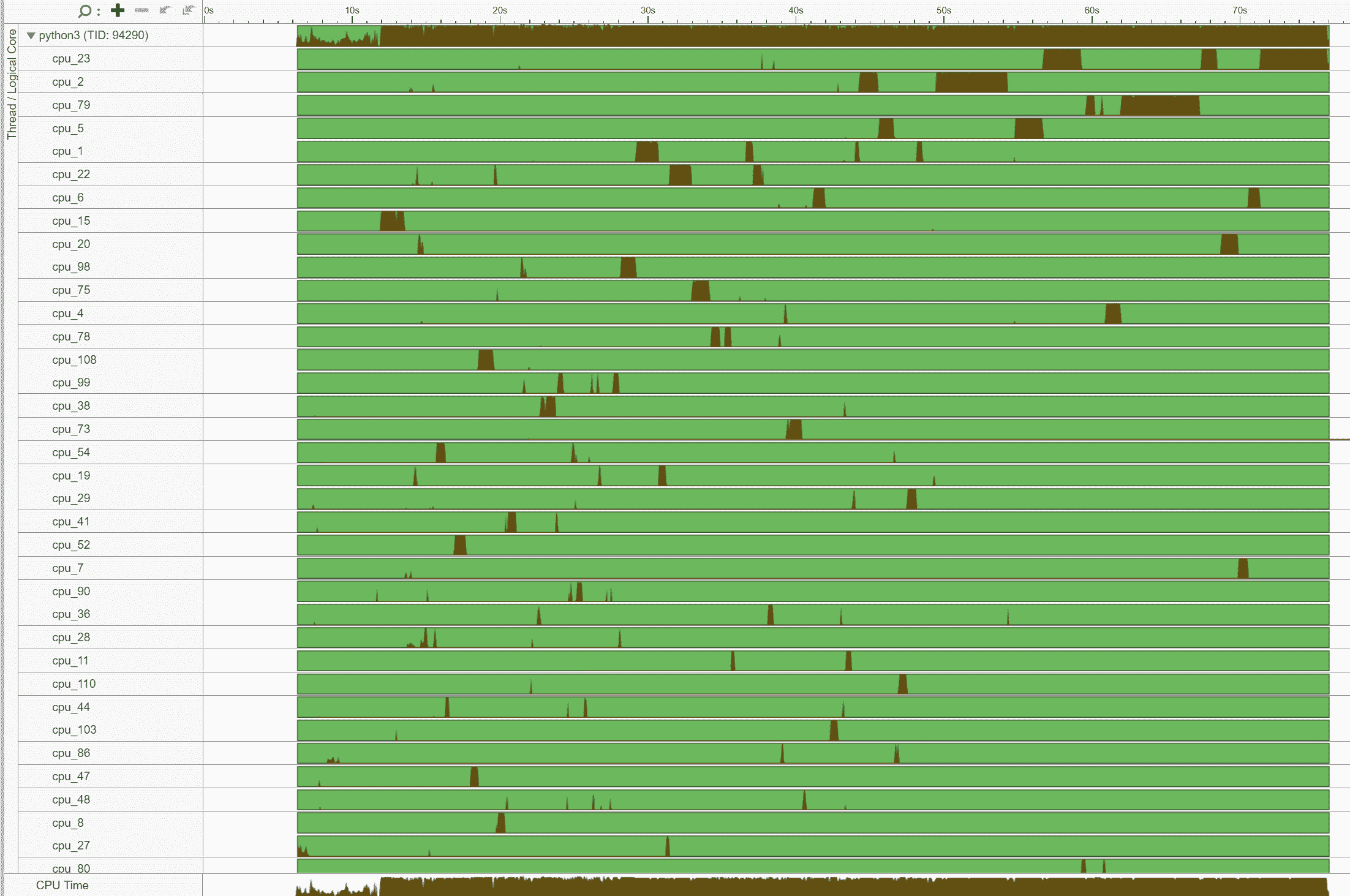
与之前类似,没有核心固定时,线程(TID:94290)在大量 CPU 核心上执行,表明 CPU 迁移。我们再次注意到跨插槽的线程迁移,导致内存访问非常低效。例如,此线程在 cpu_78(NUMA 节点 0)上执行,然后迁移到 cpu_108(NUMA 节点 1)。
- 非均匀内存访问分析

尽管相比原始的 51.09%有所改善,但仍然有 40.45%的内存访问是远程的,表明 NUMA 配置不够理想。
3. 启动器核心绑定
启动器将内部将物理核心均匀分配给工作线程,并将它们绑定到每个工作线程。提醒一下,默认情况下,启动器仅使用物理核心。在此示例中,启动器将工作线程 0 绑定到核心 0-13(NUMA 节点 0),工作线程 1 绑定到核心 14-27(NUMA 节点 0),工作线程 2 绑定到核心 28-41(NUMA 节点 1),工作线程 3 绑定到核心 42-55(NUMA 节点 1)。这样做可以确保核心在工作线程之间不重叠,并避免逻辑核心的使用。
- CPU 使用率
启动了 4 个主要工作线程,然后每个工作线程启动了num_physical_cores/num_workers数量(14)的线程,这些线程与分配的物理核心亲和。
- 核心绑定的停顿

核心绑定的停顿从原始的 88.4%显著减少到 46.2% - 几乎提高了 2 倍。
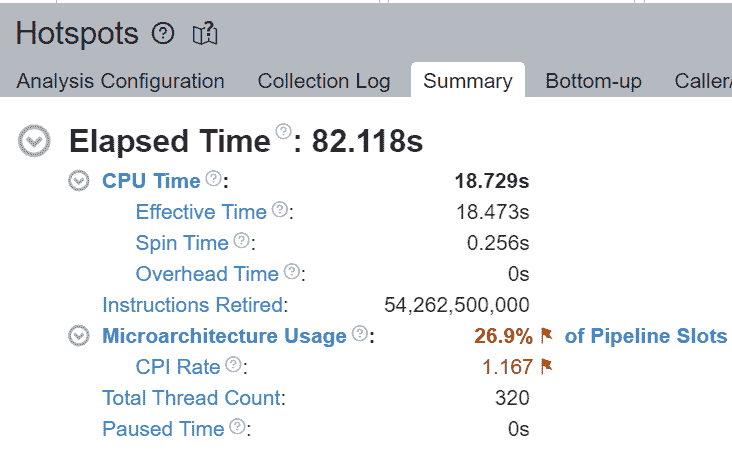
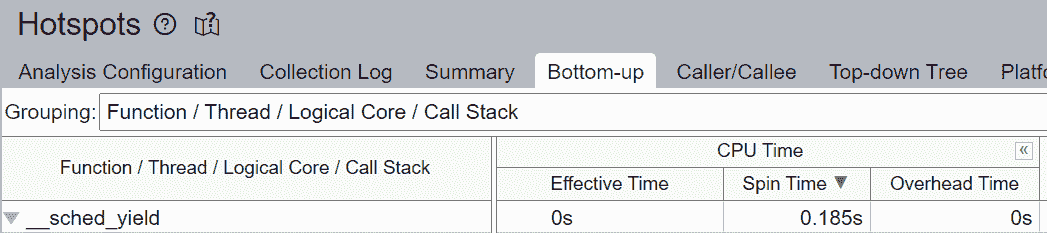
我们验证了通过核心绑定,大部分 CPU 时间有效地用于计算 - 自旋时间为 0.256 秒。
- 线程迁移

我们验证了 OMP 主线程#0 绑定到分配的物理核心(42-55),并且没有跨插槽迁移。
- 非均匀内存访问分析

现在几乎所有,89.52%,内存访问都是本地访问。
结论
在本博客中,我们展示了正确设置 CPU 运行时配置如何显著提升开箱即用的 CPU 性能。
我们已经介绍了一些通用的 CPU 性能调优原则和建议:
-
在启用超线程的系统中,通过核心绑定将线程亲和性设置为仅在物理核心上,避免逻辑核心。
-
在具有 NUMA 的多插槽系统中,通过将线程亲和性设置为特定插槽,避免跨插槽的远程内存访问。
我们从基本原理上直观地解释了这些想法,并通过性能分析验证了性能提升。最后,我们将所有学到的东西应用到 TorchServe 中,以提升开箱即用的 TorchServe CPU 性能。
这些原则可以通过一个易于使用的启动脚本自动配置,该脚本已经集成到 TorchServe 中。
对于感兴趣的读者,请查看以下文档:
-
CPU 特定优化
-
最大化 Intel®软件优化对 CPU 上 PyTorch*性能的影响
-
性能调优指南
-
启动脚本使用指南
-
自上而下的微体系结构分析方法
-
为基准测试配置 oneDNN
-
Intel® VTune™ Profiler
-
Intel® VTune™ Profiler 用户指南
请继续关注有关通过Intel® Extension for PyTorch*优化 CPU 内核和高级启动器配置(如内存分配器)的后续文章。
致谢
我们要感谢 Ashok Emani(Intel)和 Jiong Gong(Intel)在这篇博客的许多步骤中给予我们巨大的指导和支持,以及详尽的反馈和审查。我们还要感谢 Hamid Shojanazeri(Meta)、Li Ning(AWS)和 Jing Xu(Intel)在代码审查中提供的有用反馈。以及 Suraj Subramanian(Meta)和 Geeta Chauhan(Meta)在博客中提供的有用反馈。
从第一原则开始理解 PyTorch 英特尔 CPU 性能(第 2 部分)
原文:
pytorch.org/tutorials/intermediate/torchserve_with_ipex_2.html译者:飞龙
协议:CC BY-NC-SA 4.0
作者:Min Jean Cho,Jing Xu,Mark Saroufim
在Grokking PyTorch 英特尔 CPU 性能从第一原则开始教程中,我们介绍了如何调整 CPU 运行时配置,如何对其进行性能分析,以及如何将它们集成到TorchServe中以获得优化的 CPU 性能。
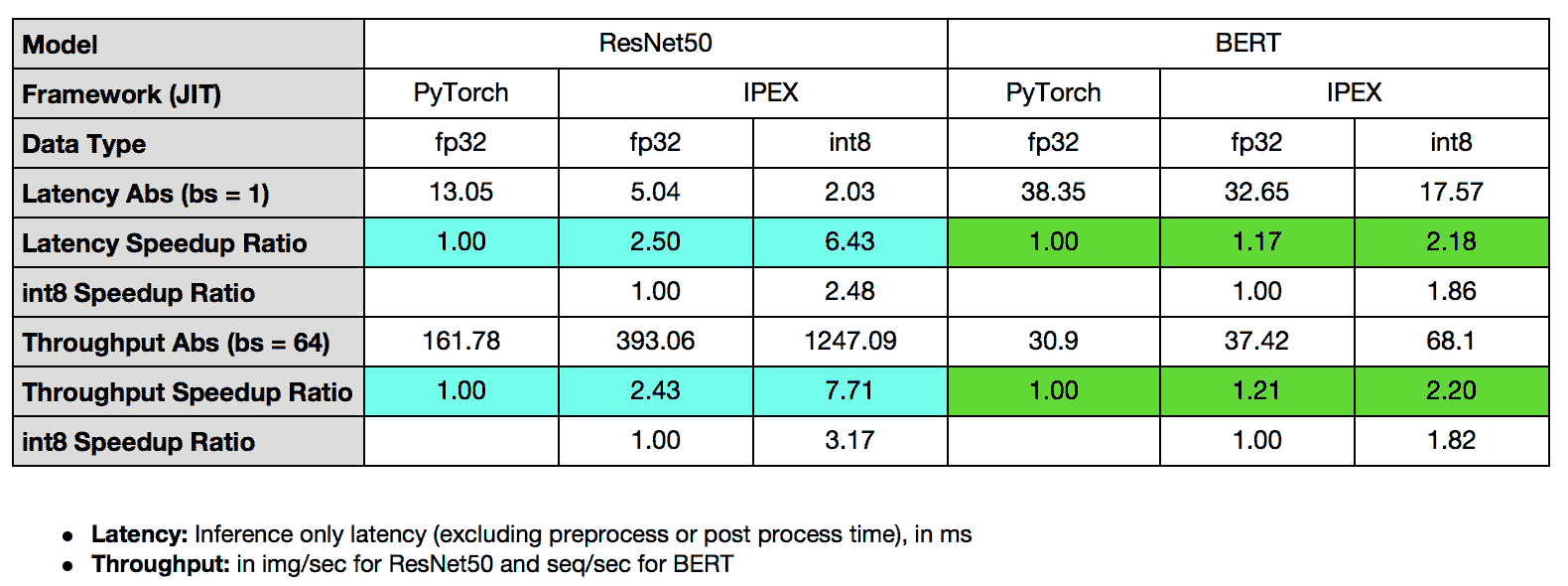
在本教程中,我们将通过英特尔® PyTorch*扩展启动器演示如何通过内存分配器提高性能,并通过英特尔® PyTorch*扩展在 CPU 上优化内核,并将它们应用于 TorchServe,展示 ResNet50 的吞吐量提升了 7.71 倍,BERT 的吞吐量提升了 2.20 倍。
先决条件
在整个本教程中,我们将使用自顶向下的微体系结构分析(TMA)来对性能进行分析,并展示未经优化或未调整的深度学习工作负载通常主要受到后端受限(内存受限、核心受限)的影响,并通过英特尔® PyTorch*扩展演示优化技术以改善后端受限。我们将使用toplev,这是pmu-tools的一部分工具,构建在Linux perf之上,用于 TMA。
我们还将使用英特尔® VTune™ Profiler 的仪器化和跟踪技术(ITT)以更精细的粒度进行性能分析。
自顶向下的微体系结构分析方法(TMA)
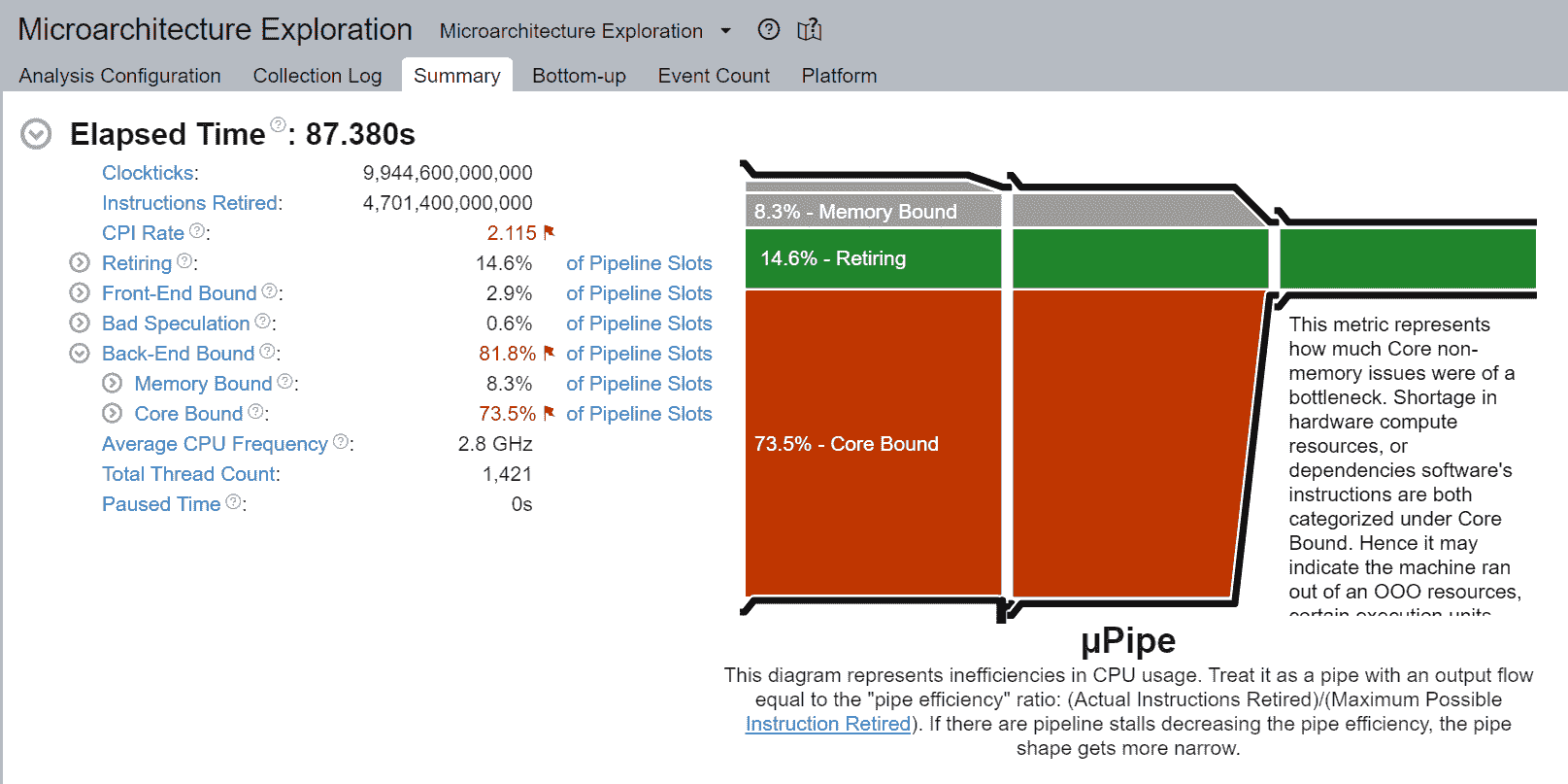
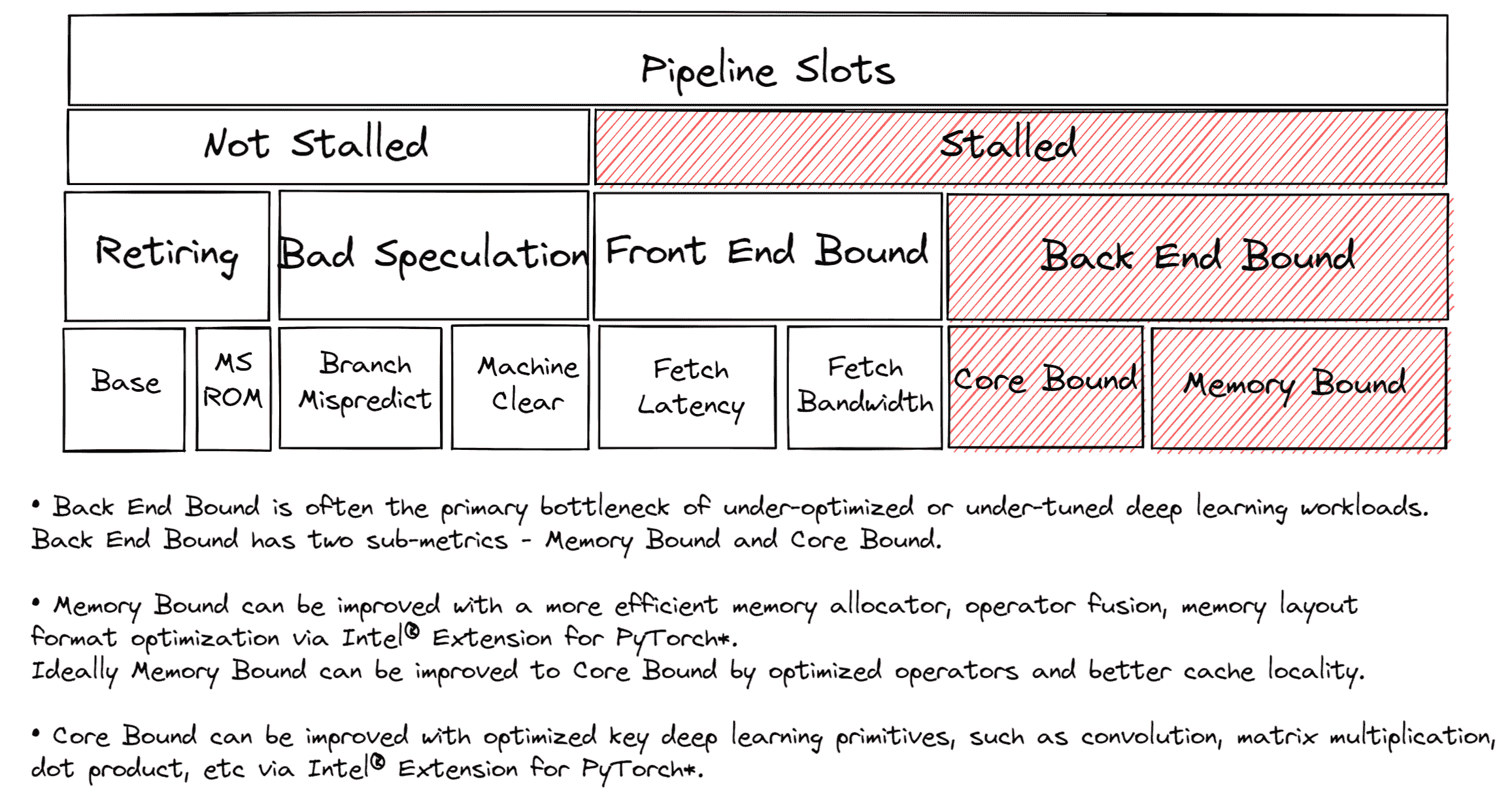
在调整 CPU 以获得最佳性能时,了解瓶颈所在是很有用的。大多数 CPU 核心都有芯片上的性能监控单元(PMUs)。PMUs 是 CPU 核心内的专用逻辑单元,用于计算系统上发生的特定硬件事件。这些事件的示例可能是缓存未命中或分支误预测。PMUs 用于自顶向下的微体系结构分析(TMA)以识别瓶颈。TMA 包括如下层次结构:
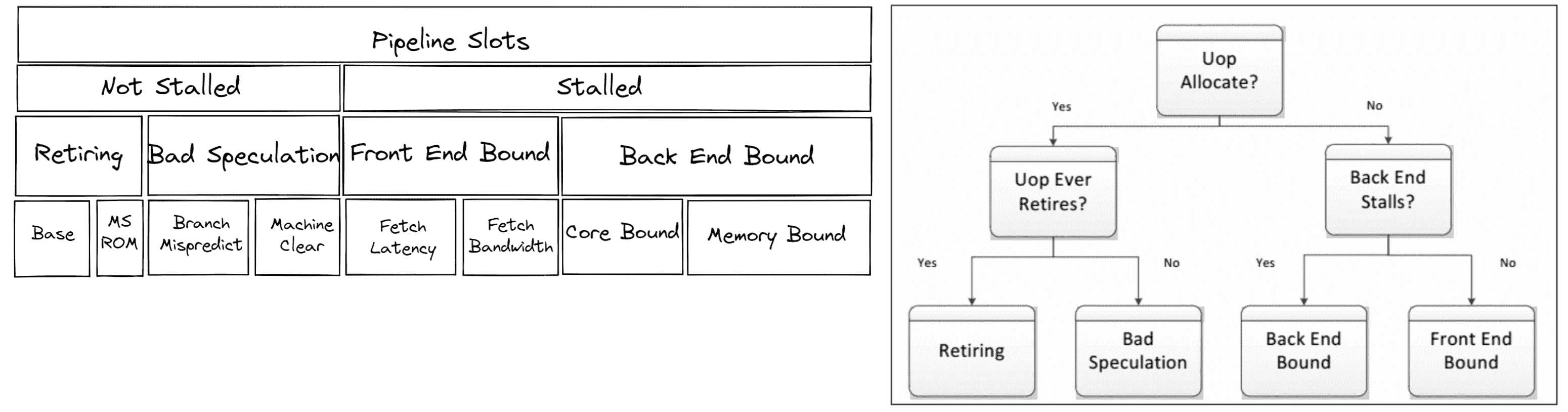
顶层,即一级,指标收集退休、错误猜测、前端受限、后端受限。CPU 的流水线在概念上可以简化并分为两部分:前端和后端。前端负责获取程序代码并将其解码为称为微操作(uOps)的低级硬件操作。然后将 uOps 传送到后端,这个过程称为分配。一旦分配,后端负责在可用的执行单元中执行 uOp。uOp 的执行完成称为退休。相反,错误猜测是指在退休之前取消了被推测获取的 uOps,例如在误预测分支的情况下。这些指标中的每一个都可以进一步细分为后续级别,以确定瓶颈。
调整后端受限
大多数未调整的深度学习工作负载将是后端受限的。解决后端受限通常是解决导致退休时间超过必要时间的延迟源。如上所示,后端受限有两个子指标 - 核心受限和内存受限。
内存绑定停顿与内存子系统相关。例如,最后一级缓存(LLC 或 L3 缓存)缺失导致访问 DRAM。扩展深度学习模型通常需要大量计算。高计算利用率要求在执行单元需要执行 uOps 时数据可用。这需要预取数据并在缓存中重用数据,而不是多次从主存储器中获取相同的数据,这会导致执行单元在数据返回时被饿死。在整个教程中,我们将展示更高效的内存分配器、操作融合、内存布局格式优化如何减少内存绑定的开销,提高缓存局部性。
核心绑定停顿表示可用执行单元的子优化使用,而没有未完成的内存访问。例如,连续的多个通用矩阵乘法(GEMM)指令竞争融合乘加(FMA)或点积(DP)执行单元可能导致核心绑定停顿。关键的深度学习核心,包括 DP 核心,已经通过oneDNN 库(oneAPI 深度神经网络库)进行了优化,减少了核心绑定的开销。
GEMM、卷积、反卷积等操作是计算密集型的。而池化、批量归一化、激活函数如 ReLU 等操作是内存绑定的。
Intel® VTune™ Profiler 的仪器化和跟踪技术(ITT)
Intel® VTune Profiler 的 ITT API 是一个有用的工具,用于注释您的工作负载的区域,以便以更细粒度的注释-OP/函数/子函数粒度进行跟踪和可视化。通过在 PyTorch 模型的 OP 级别进行注释,Intel® VTune Profiler 的 ITT 实现了 OP 级别的性能分析。Intel® VTune Profiler 的 ITT 已经集成到PyTorch Autograd Profiler中。¹
- 该功能必须通过*with torch.autograd.profiler.emit_itt()*来显式启用。
带有 Intel® Extension for PyTorch*的 TorchServe
Intel® Extension for PyTorch*是一个 Python 包,用于通过在 Intel 硬件上进行额外性能优化来扩展 PyTorch。
Intel® Extension for PyTorch已经集成到 TorchServe 中,以提高性能。² 对于自定义处理程序脚本,我们建议添加intel_extension_for_pytorch*包。
- 该功能必须通过在config.properties中设置ipex_enable=true来显式启用。
在本节中,我们将展示后端绑定通常是未经优化或未调整的深度学习工作负载的主要瓶颈,并通过 Intel® Extension for PyTorch演示优化技术,以改善后端绑定,后端绑定有两个子指标-内存绑定和核心绑定。更高效的内存分配器、操作融合、内存布局格式优化改善了内存绑定。理想情况下,通过优化操作符和更好的缓存局部性,内存绑定可以改善为核心绑定。关键的深度学习基元,如卷积、矩阵乘法、点积,已经通过 Intel® Extension for PyTorch和 oneDNN 库进行了优化,改善了核心绑定。
利用高级启动器配置:内存分配器
从性能的角度来看,内存分配器起着重要作用。更高效的内存使用减少了不必要的内存分配或销毁的开销,从而实现更快的执行。在实践中的深度学习工作负载中,特别是在像 TorchServe 这样的大型多核系统或服务器上运行的工作负载中,TCMalloc 或 JeMalloc 通常比默认的 PyTorch 内存分配器 PTMalloc 具有更好的内存使用。
TCMalloc,JeMalloc,PTMalloc
TCMalloc 和 JeMalloc 都使用线程本地缓存来减少线程同步的开销,并通过使用自旋锁和每个线程的竞技场来减少锁争用。TCMalloc 和 JeMalloc 减少了不必要的内存分配和释放的开销。两个分配器通过大小对内存分配进行分类,以减少内存碎片化的开销。
使用启动器,用户可以通过选择三个启动器旋钮之一来轻松尝试不同的内存分配器 –enable_tcmalloc(TCMalloc)、–enable_jemalloc(JeMalloc)、–use_default_allocator(PTMalloc)。
练习
让我们对比 PTMalloc 和 JeMalloc 进行分析。
我们将使用启动器指定内存分配器,并将工作负载绑定到第一个插槽的物理核心,以避免任何 NUMA 复杂性 – 仅对内存分配器的影响进行分析。
以下示例测量了 ResNet50 的平均推理时间:
import torch
import torchvision.models as models
import time
model = models.resnet50(pretrained=False)
model.eval()
batch_size = 32
data = torch.rand(batch_size, 3, 224, 224)
# warm up
for _ in range(100):
model(data)
# measure
# Intel® VTune Profiler's ITT context manager
with torch.autograd.profiler.emit_itt():
start = time.time()
for i in range(100):
# Intel® VTune Profiler's ITT to annotate each step
torch.profiler.itt.range_push('step_{}'.format(i))
model(data)
torch.profiler.itt.range_pop()
end = time.time()
print('Inference took {:.2f} ms in average'.format((end-start)/100*1000))
让我们收集一级 TMA 指标。

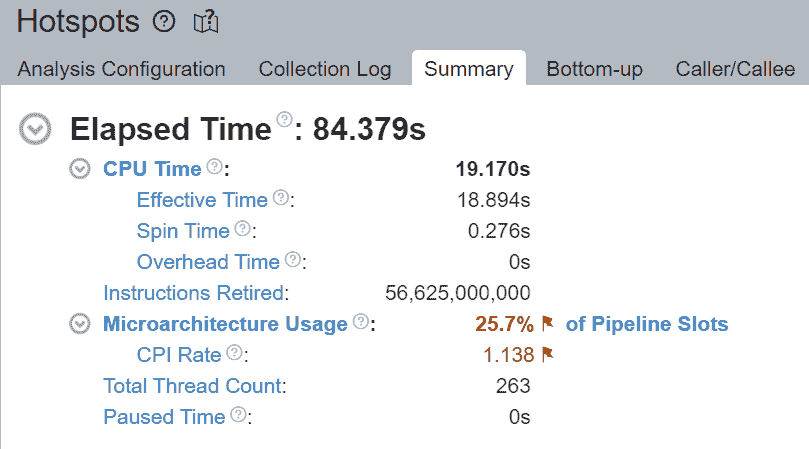
一级 TMA 显示 PTMalloc 和 JeMalloc 都受后端限制。超过一半的执行时间被后端阻塞。让我们再深入一层。

二级 TMA 显示后端受限是由内存受限引起的。让我们再深入一层。
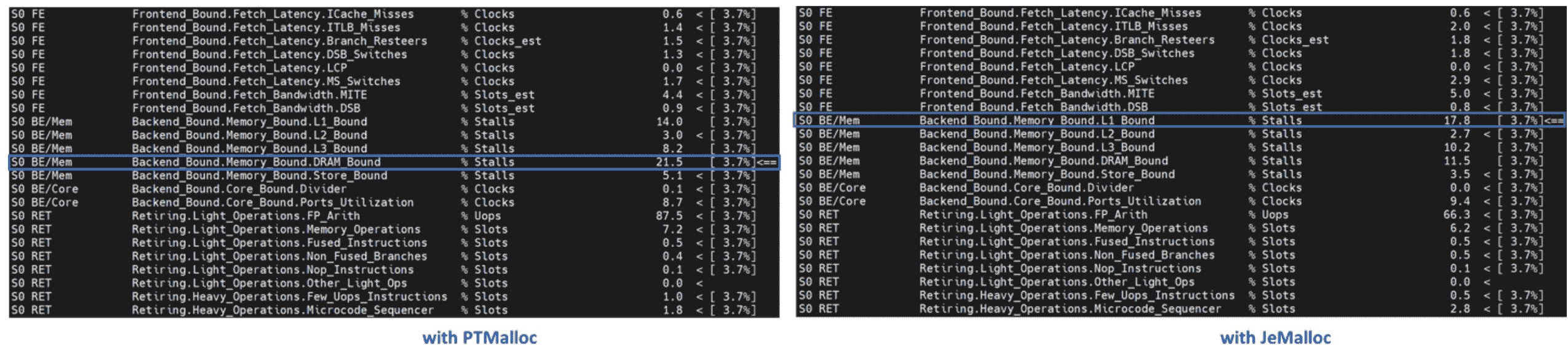
大多数内存受限指标确定了从 L1 缓存到主存储器的内存层次结构中的瓶颈。在给定级别上受限的热点表明大部分数据是从该缓存或内存级别检索的。优化应该专注于将数据移动到核心附近。三级 TMA 显示 PTMalloc 受 DRAM Bound 限制。另一方面,JeMalloc 受 L1 Bound 限制 – JeMalloc 将数据移动到核心附近,从而实现更快的执行。
让我们看看 Intel® VTune Profiler ITT 跟踪。在示例脚本中,我们已经注释了推理循环的每个 step_x。
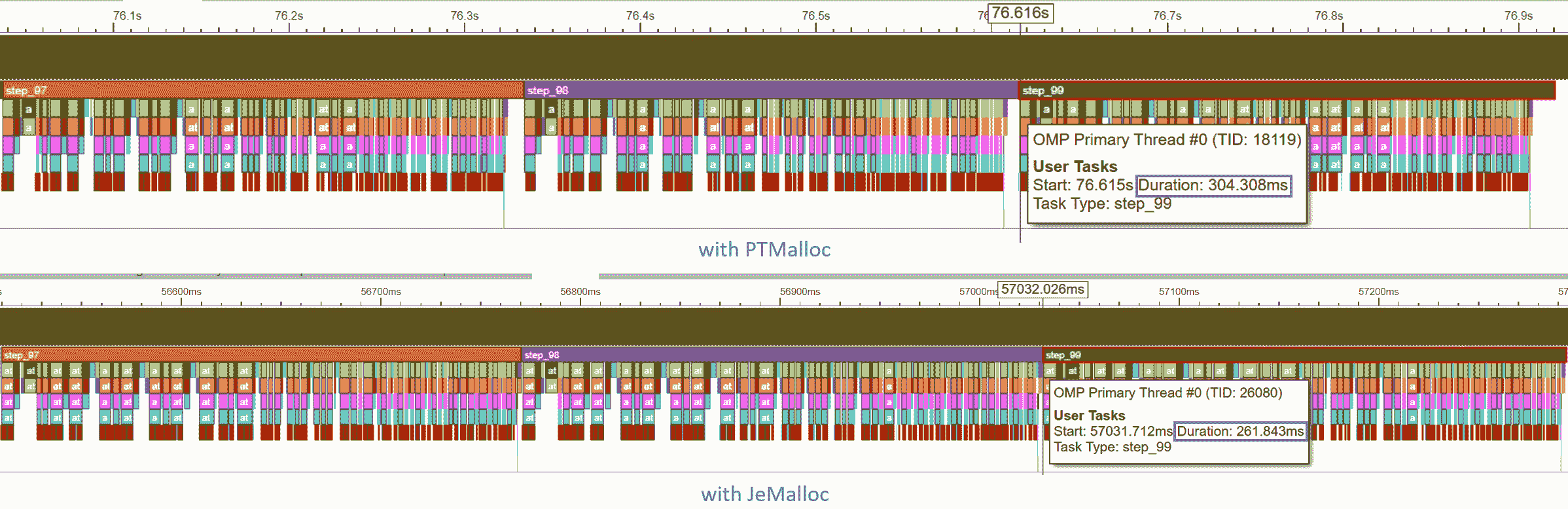
时间轴图中跟踪了每个步骤。在最后一步(step_99)的模型推理持续时间从 304.308 毫秒减少到 261.843 毫秒。
使用 TorchServe 进行练习
让我们使用 TorchServe 对比 PTMalloc 和 JeMalloc 进行分析。
我们将使用 TorchServe apache-bench 基准测试 进行 ResNet50 FP32、批量大小 32、并发数 32、请求数 8960. 其他所有参数与 默认参数 相同。
与之前的练习一样,我们将使用启动器指定内存分配器,并将工作负载绑定到第一个插槽的物理核心。为此,用户只需在 config.properties 中添加几行即可:
PTMalloc
cpu_launcher_enable=true
cpu_launcher_args=--node_id 0 --use_default_allocator
JeMalloc
cpu_launcher_enable=true
cpu_launcher_args=--node_id 0 --enable_jemalloc
让我们收集一级 TMA 指标。

让我们再深入一层。

让我们使用 Intel® VTune Profiler ITT 对 TorchServe 推理范围 进行注释,以便以推理级别的粒度进行分析。由于 TorchServe 架构 包括几个子组件,包括用于处理请求/响应的 Java 前端和用于在模型上运行实际推理的 Python 后端,因此使用 Intel® VTune Profiler ITT 限制在推理级别收集跟踪数据是有帮助的。

每个推断调用都在时间线图中被跟踪。最后一个模型推断的持续时间从 561.688 毫秒减少到 251.287 毫秒 - 加速 2.2 倍。
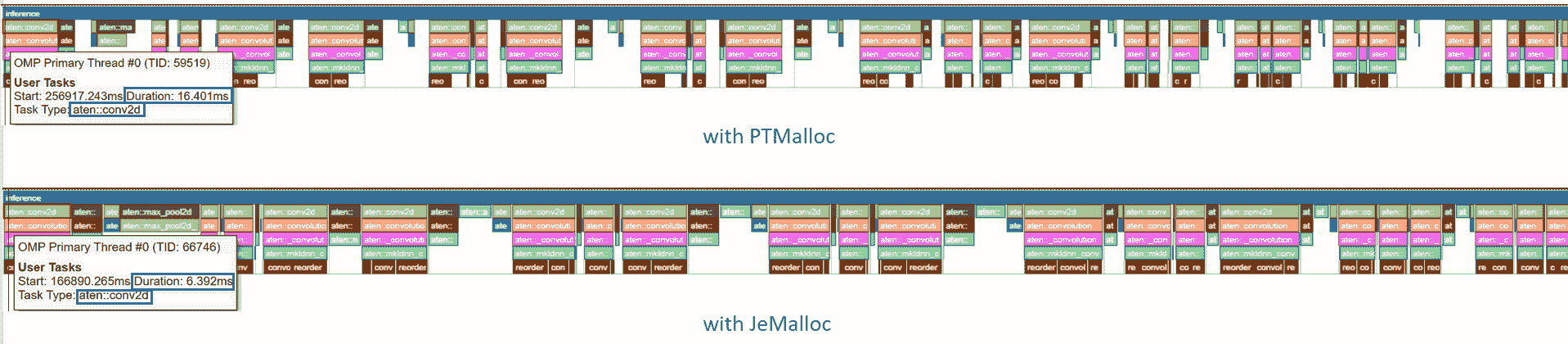
时间线图可以展开以查看操作级别的性能分析结果。aten::conv2d的持续时间从 16.401 毫秒减少到 6.392 毫秒 - 加速 2.6 倍。
在本节中,我们已经证明 JeMalloc 可以比默认的 PyTorch 内存分配器 PTMalloc 提供更好的性能,有效的线程本地缓存可以改善后端绑定。
Intel® Extension for PyTorch*
三个主要的Intel® Extension for PyTorch*优化技术,运算符、图形、运行时,如下所示:
| Intel® Extension for PyTorch* 优化技术 |
|---|
| 运算符 |
|
-
矢量化和多线程
-
低精度 BF16/INT8 计算
-
为了更好的缓存局部性进行的数据布局优化
|
-
常量折叠以减少计算
-
为了更好的缓存局部性而进行的操作融合
|
-
线程亲和性
-
内存缓冲池
-
GPU 运行时
-
启动器
|
运算符优化
优化的运算符和内核通过 PyTorch 调度机制进行注册。这些运算符和内核从英特尔硬件的本机矢量化特性和矩阵计算特性加速。在执行过程中,Intel® Extension for PyTorch拦截 ATen 运算符的调用,并用这些优化的运算符替换原始运算符。像卷积、线性等流行的运算符已经在 Intel® Extension for PyTorch中进行了优化。
练习
让我们使用 Intel® Extension for PyTorch*对优化的运算符进行性能分析。我们将比较在代码中添加和不添加这些行的变化。
与以前的练习一样,我们将将工作负载绑定到第一个插槽的物理核心。
import torch
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv = torch.nn.Conv2d(16, 33, 3, stride=2)
self.relu = torch.nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
model = Model()
model.eval()
data = torch.rand(20, 16, 50, 100)
#################### code changes ####################
import intel_extension_for_pytorch as ipex
model = ipex.optimize(model)
######################################################
print(model)
该模型由两个操作组成——Conv2d 和 ReLU。通过打印模型对象,我们得到以下输出。

让我们收集一级 TMA 指标。

注意后端绑定从 68.9 减少到 38.5 - 加速 1.8 倍。
此外,让我们使用 PyTorch Profiler 进行性能分析。

注意 CPU 时间从 851 微秒减少到 310 微秒 - 加速 2.7 倍。
图形优化
强烈建议用户利用 Intel® Extension for PyTorch与TorchScript进一步优化图形。为了通过 TorchScript 进一步优化性能,Intel® Extension for PyTorch支持常用 FP32/BF16 运算符模式的 oneDNN 融合,如 Conv2D+ReLU、Linear+ReLU 等,以减少运算符/内核调用开销,提高缓存局部性。一些运算符融合允许保持临时计算、数据类型转换、数据布局以提高缓存局部性。此外,对于 INT8,Intel® Extension for PyTorch*具有内置的量化配方,为包括 CNN、NLP 和推荐模型在内的流行 DL 工作负载提供良好的统计精度。量化模型然后通过 oneDNN 融合支持进行优化。
练习
让我们使用 TorchScript 对 FP32 图形优化进行性能分析。
与以前的练习一样,我们将将工作负载绑定到第一个插槽的物理核心。
import torch
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv = torch.nn.Conv2d(16, 33, 3, stride=2)
self.relu = torch.nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
model = Model()
model.eval()
data = torch.rand(20, 16, 50, 100)
#################### code changes ####################
import intel_extension_for_pytorch as ipex
model = ipex.optimize(model)
######################################################
# torchscript
with torch.no_grad():
model = torch.jit.trace(model, data)
model = torch.jit.freeze(model)
让我们收集一级 TMA 指标。

注意后端绑定从 67.1 减少到 37.5 - 加速 1.8 倍。
此外,让我们使用 PyTorch Profiler 进行性能分析。

请注意,使用 Intel® PyTorch 扩展,Conv + ReLU 操作符被融合,CPU 时间从 803 微秒减少到 248 微秒,加速了 3.2 倍。oneDNN eltwise 后操作使得可以将一个原语与一个逐元素原语融合。这是最流行的融合类型之一:一个 eltwise(通常是激活函数,如 ReLU)与前面的卷积或内积。请查看下一节中显示的 oneDNN 详细日志。
Channels Last 内存格式
在模型上调用ipex.optimize时,Intel® PyTorch 扩展会自动将模型转换为优化的内存格式,即 channels last。Channels last 是一种更适合 Intel 架构的内存格式。与 PyTorch 默认的 channels first NCHW(batch, channels, height, width)内存格式相比,channels last NHWC(batch, height, width, channels)内存格式通常可以加速卷积神经网络,具有更好的缓存局部性。
需要注意的一点是,转换内存格式是昂贵的。因此最好在部署之前将内存格式转换一次,并在部署过程中尽量减少内存格式转换。当数据通过模型的层传播时,最后通道的内存格式会通过连续的支持最后通道的层(例如,Conv2d -> ReLU -> Conv2d)保持不变,转换仅在不支持最后通道的层之间进行。有关更多详细信息,请参阅内存格式传播。
练习
让我们演示最后通道优化。
import torch
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv = torch.nn.Conv2d(16, 33, 3, stride=2)
self.relu = torch.nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
model = Model()
model.eval()
data = torch.rand(20, 16, 50, 100)
import intel_extension_for_pytorch as ipex
############################### code changes ###############################
ipex.disable_auto_channels_last() # omit this line for channels_last (default)
############################################################################
model = ipex.optimize(model)
with torch.no_grad():
model = torch.jit.trace(model, data)
model = torch.jit.freeze(model)
我们将使用oneDNN 详细模式,这是一个帮助收集有关 oneDNN 图级别信息的工具,例如操作融合、执行 oneDNN 原语所花费的内核执行时间。有关更多信息,请参考oneDNN 文档。
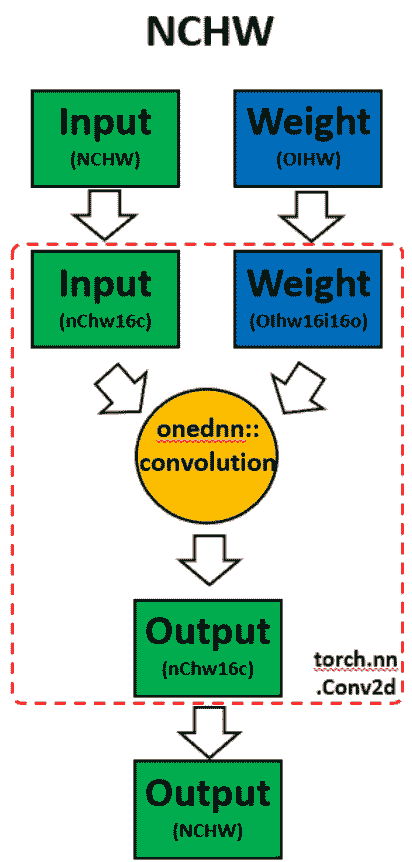
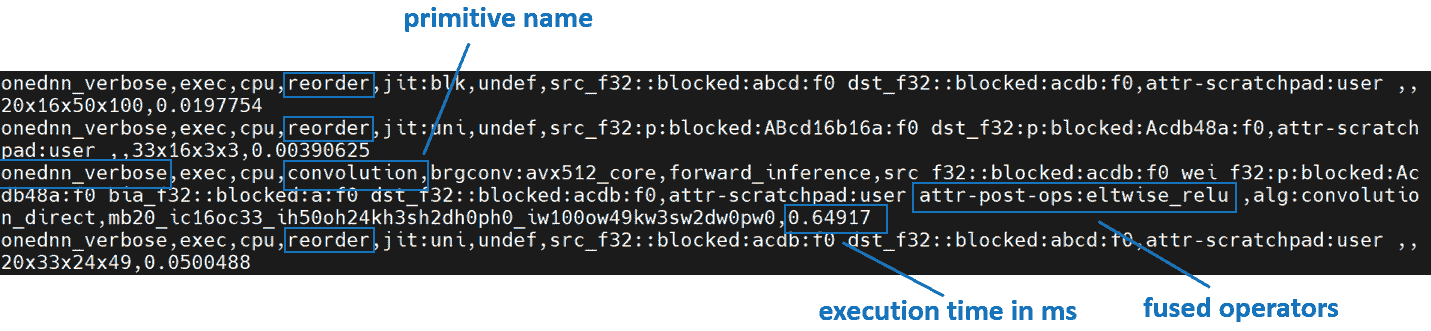
以上是来自通道首的 oneDNN 详细信息。我们可以验证从权重和数据进行重新排序,然后进行计算,最后将输出重新排序。

以上是来自通道最后的 oneDNN 详细信息。我们可以验证通道最后的内存格式避免了不必要的重新排序。
使用 Intel® PyTorch 扩展提升性能
以下总结了 TorchServe 与 Intel® Extension for PyTorch*在 ResNet50 和 BERT-base-uncased 上的性能提升。
使用 TorchServe 进行练习
让我们使用 TorchServe 来分析 Intel® Extension for PyTorch*的优化。
我们将使用 ResNet50 FP32 TorchScript 的TorchServe apache-bench 基准测试,批量大小为 32,并发数为 32,请求为 8960。所有其他参数与默认参数相同。
与上一个练习一样,我们将使用启动器将工作负载绑定到第一个插槽的物理核心。为此,用户只需在config.properties中添加几行代码:
cpu_launcher_enable=true
cpu_launcher_args=--node_id 0
让我们收集一级 TMA 指标。

Level-1 TMA 显示两者都受到后端的限制。正如之前讨论的,大多数未调整的深度学习工作负载将受到后端的限制。注意后端限制从 70.0 降至 54.1。让我们再深入一层。

如前所述,后端绑定有两个子指标 - 内存绑定和核心绑定。内存绑定表示工作负载未经优化或未充分利用,理想情况下,内存绑定操作可以通过优化 OPs 和改善缓存局部性来改善为核心绑定。Level-2 TMA 显示后端绑定从内存绑定改善为核心绑定。让我们深入一层。
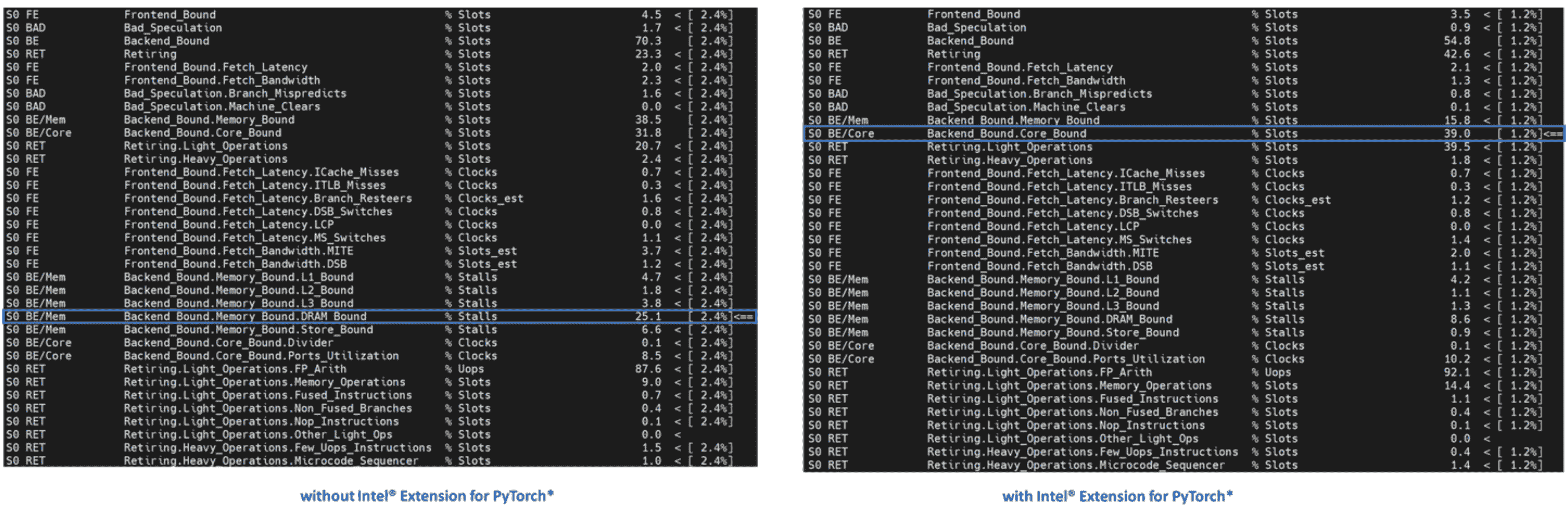
在像 TorchServe 这样的模型服务框架上为生产扩展深度学习模型需要高计算利用率。这要求数据通过预取并在执行单元需要执行 uOps 时在缓存中重复使用。Level-3 TMA 显示后端内存绑定从 DRAM 绑定改善为核心绑定。
与 TorchServe 之前的练习一样,让我们使用 Intel® VTune Profiler ITT 来注释TorchServe 推断范围,以便以推断级别的粒度进行分析。
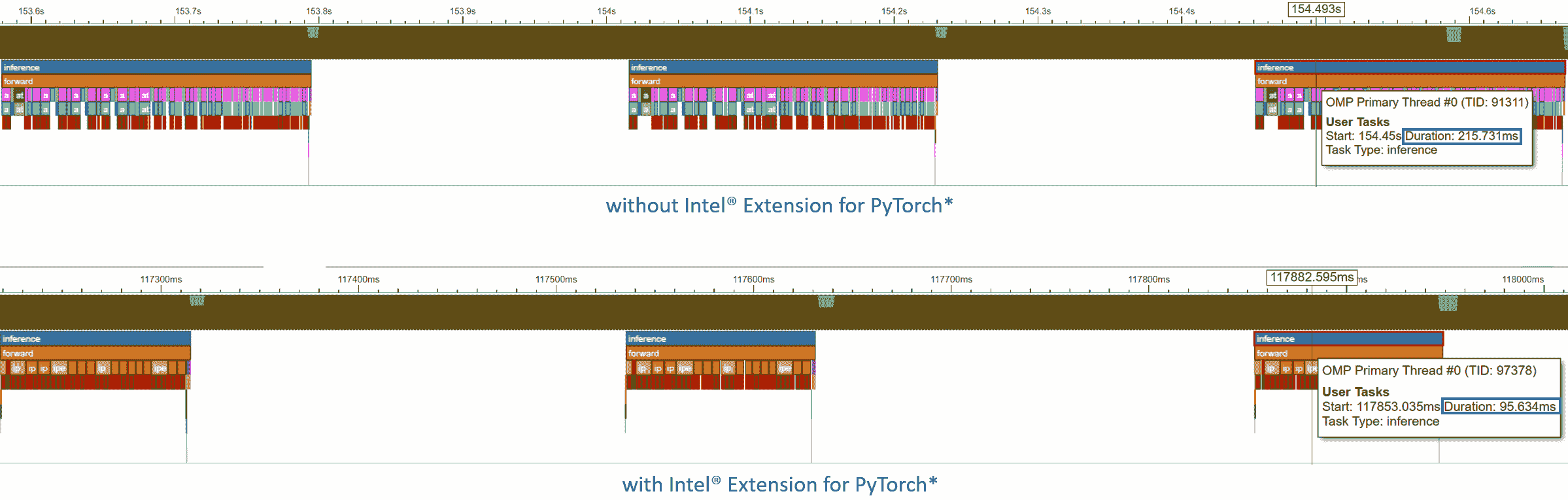
时间轴图中跟踪了每个推断调用。最后一个推断调用的持续时间从 215.731 毫秒减少到 95.634 毫秒 - 2.3 倍加速。

时间轴图可以展开以查看操作级别的分析结果。请注意,Conv + ReLU 已经被融合,持续时间从 6.393 毫秒+1.731 毫秒减少到 3.408 毫秒 - 2.4 倍加速。
结论
在本教程中,我们使用了自顶向下微架构分析(TMA)和 Intel® VTune™ Profiler 的仪器化和跟踪技术(ITT)来演示
-
通常,未经优化或调整不足的深度学习工作负载的主要瓶颈是后端绑定,它有两个子指标,即内存绑定和核心绑定。
-
Intel® PyTorch*的更高效的内存分配器、操作融合、内存布局格式优化改善了内存绑定。
-
关键的深度学习基元,如卷积、矩阵乘法、点积等,已经被 Intel® PyTorch*扩展和 oneDNN 库进行了优化,提高了核心绑定。
-
Intel® PyTorch*扩展已经集成到 TorchServe 中,具有易于使用的 API。
-
TorchServe 与 Intel® PyTorch*扩展展示了 ResNet50 的 7.71 倍吞吐量提升,以及 BERT 的 2.20 倍吞吐量提升。
相关阅读
自顶向下微架构分析方法
自顶向下性能分析方法
使用 Intel® PyTorch*扩展加速 PyTorch
致谢
我们要感谢 Ashok Emani(Intel)和 Jiong Gong(Intel)在本教程的许多步骤中提供的巨大指导和支持,以及全面的反馈和审查。我们还要感谢 Hamid Shojanazeri(Meta)和 Li Ning(AWS)在代码审查和教程中提供的有用反馈。
开始 - 用 nvFuser 加速您的脚本
原文:
pytorch.org/tutorials/intermediate/nvfuser_intro_tutorial.html译者:飞龙
协议:CC BY-NC-SA 4.0
此教程已被弃用。3 秒后将重定向到主页…
使用 Ax 进行多目标 NAS
原文:
pytorch.org/tutorials/intermediate/ax_multiobjective_nas_tutorial.html译者:飞龙
协议:CC BY-NC-SA 4.0
注意
点击这里下载完整示例代码
作者: David Eriksson, Max Balandat,以及 Meta 的自适应实验团队。
在本教程中,我们展示如何使用Ax在流行的 MNIST 数据集上运行简单神经网络模型的多目标神经架构搜索(NAS)。虽然潜在的方法通常用于更复杂的模型和更大的数据集,但我们选择了一个在笔记本电脑上可以轻松运行的教程,不到 20 分钟即可完成。
在许多 NAS 应用中,存在着多个感兴趣目标之间的自然权衡。例如,在部署模型到设备上时,我们可能希望最大化模型性能(例如准确性),同时最小化竞争指标,如功耗、推理延迟或模型大小,以满足部署约束。通常情况下,通过接受略低的模型性能,我们可以大大减少预测的计算需求或延迟。探索这种权衡的原则方法是可扩展和可持续人工智能的关键推动因素,并在 Meta 上有许多成功的应用案例 - 例如,查看我们关于自然语言理解模型的案例研究。
在我们的示例中,我们将调整两个隐藏层的宽度、学习率、dropout 概率、批量大小和训练周期数。目标是在性能(验证集上的准确率)和模型大小(模型参数数量)之间进行权衡。
本教程使用以下 PyTorch 库:
-
PyTorch Lightning(指定模型和训练循环)
-
TorchX(用于远程/异步运行训练作业)
-
BoTorch(为 Ax 的算法提供动力的贝叶斯优化库)
定义 TorchX 应用
我们的目标是优化在mnist_train_nas.py中定义的 PyTorch Lightning 训练作业。为了使用 TorchX 实现这一目标,我们编写了一个辅助函数,该函数接受训练作业的架构和超参数的值,并创建一个具有适当设置的TorchX AppDef。
from pathlib import Path
import torchx
from torchx import specs
from torchx.components import utils
def trainer(
log_path: str,
hidden_size_1: int,
hidden_size_2: int,
learning_rate: float,
epochs: int,
dropout: float,
batch_size: int,
trial_idx: int = -1,
) -> specs.AppDef:
# define the log path so we can pass it to the TorchX ``AppDef``
if trial_idx >= 0:
log_path = Path(log_path).joinpath(str(trial_idx)).absolute().as_posix()
return utils.python(
# command line arguments to the training script
"--log_path",
log_path,
"--hidden_size_1",
str(hidden_size_1),
"--hidden_size_2",
str(hidden_size_2),
"--learning_rate",
str(learning_rate),
"--epochs",
str(epochs),
"--dropout",
str(dropout),
"--batch_size",
str(batch_size),
# other config options
name="trainer",
script="mnist_train_nas.py",
image=torchx.version.TORCHX_IMAGE,
)
设置 Runner
Ax 的Runner抽象允许编写与各种后端的接口。Ax 已经为 TorchX 提供了 Runner,因此我们只需要配置它。在本教程中,我们以完全异步的方式在本地运行作业。
为了在集群上启动它们,您可以指定一个不同的 TorchX 调度程序,并相应地调整配置。例如,如果您有一个 Kubernetes 集群,您只需要将调度程序从local_cwd更改为kubernetes。
import tempfile
from ax.runners.torchx import TorchXRunner
# Make a temporary dir to log our results into
log_dir = tempfile.mkdtemp()
ax_runner = TorchXRunner(
tracker_base="/tmp/",
component=trainer,
# NOTE: To launch this job on a cluster instead of locally you can
# specify a different scheduler and adjust arguments appropriately.
scheduler="local_cwd",
component_const_params={"log_path": log_dir},
cfg={},
)
设置SearchSpace
首先,我们定义我们的搜索空间。Ax 支持整数和浮点类型的范围参数,也支持选择参数,可以具有非数字类型,如字符串。我们将调整隐藏层大小、学习率、丢失率和时代数作为范围参数,并将批量大小调整为有序选择参数,以强制其为 2 的幂。
from ax.core import (
ChoiceParameter,
ParameterType,
RangeParameter,
SearchSpace,
)
parameters = [
# NOTE: In a real-world setting, hidden_size_1 and hidden_size_2
# should probably be powers of 2, but in our simple example this
# would mean that ``num_params`` can't take on that many values, which
# in turn makes the Pareto frontier look pretty weird.
RangeParameter(
name="hidden_size_1",
lower=16,
upper=128,
parameter_type=ParameterType.INT,
log_scale=True,
),
RangeParameter(
name="hidden_size_2",
lower=16,
upper=128,
parameter_type=ParameterType.INT,
log_scale=True,
),
RangeParameter(
name="learning_rate",
lower=1e-4,
upper=1e-2,
parameter_type=ParameterType.FLOAT,
log_scale=True,
),
RangeParameter(
name="epochs",
lower=1,
upper=4,
parameter_type=ParameterType.INT,
),
RangeParameter(
name="dropout",
lower=0.0,
upper=0.5,
parameter_type=ParameterType.FLOAT,
),
ChoiceParameter( # NOTE: ``ChoiceParameters`` don't require log-scale
name="batch_size",
values=[32, 64, 128, 256],
parameter_type=ParameterType.INT,
is_ordered=True,
sort_values=True,
),
]
search_space = SearchSpace(
parameters=parameters,
# NOTE: In practice, it may make sense to add a constraint
# hidden_size_2 <= hidden_size_1
parameter_constraints=[],
)
设置度量
Ax 有一个度量的概念,它定义了结果的属性以及如何获取这些结果的观察。这允许例如编码数据如何从某个分布式执行后端获取并在传递给 Ax 之前进行后处理。
在本教程中,我们将使用多目标优化来最大化验证准确性并最小化模型参数数量。后者代表了模型延迟的简单代理,对于小型机器学习模型来说很难准确估计(在实际应用中,我们会在设备上运行模型时对延迟进行基准测试)。
在我们的示例中,TorchX 将以完全异步的方式在本地运行训练作业,并根据试验索引(参见上面的trainer()函数)将结果写入log_dir。我们将定义一个度量类,该类知道该日志目录。通过子类化TensorboardCurveMetric,我们可以免费获得读取和解析 TensorBoard 日志的逻辑。
from ax.metrics.tensorboard import TensorboardCurveMetric
class MyTensorboardMetric(TensorboardCurveMetric):
# NOTE: We need to tell the new TensorBoard metric how to get the id /
# file handle for the TensorBoard logs from a trial. In this case
# our convention is to just save a separate file per trial in
# the prespecified log dir.
@classmethod
def get_ids_from_trials(cls, trials):
return {
trial.index: Path(log_dir).joinpath(str(trial.index)).as_posix()
for trial in trials
}
# This indicates whether the metric is queryable while the trial is
# still running. We don't use this in the current tutorial, but Ax
# utilizes this to implement trial-level early-stopping functionality.
@classmethod
def is_available_while_running(cls):
return False
现在我们可以实例化准确率和模型参数数量的指标。这里 curve_name 是 TensorBoard 日志中指标的名称,而 name 是 Ax 内部使用的指标名称。我们还指定 lower_is_better 来指示这两个指标的有利方向。
val_acc = MyTensorboardMetric(
name="val_acc",
curve_name="val_acc",
lower_is_better=False,
)
model_num_params = MyTensorboardMetric(
name="num_params",
curve_name="num_params",
lower_is_better=True,
)
设置OptimizationConfig
告诉 Ax 应该优化的方式是通过OptimizationConfig。在这里,我们使用MultiObjectiveOptimizationConfig,因为我们将执行多目标优化。
此外,Ax 支持通过指定目标阈值对不同指标设置约束,这些约束限制了我们想要探索的结果空间的区域。在本例中,我们将约束验证准确率至少为 0.94(94%),模型参数数量最多为 80,000。
from ax.core import MultiObjective, Objective, ObjectiveThreshold
from ax.core.optimization_config import MultiObjectiveOptimizationConfig
opt_config = MultiObjectiveOptimizationConfig(
objective=MultiObjective(
objectives=[
Objective(metric=val_acc, minimize=False),
Objective(metric=model_num_params, minimize=True),
],
),
objective_thresholds=[
ObjectiveThreshold(metric=val_acc, bound=0.94, relative=False),
ObjectiveThreshold(metric=model_num_params, bound=80_000, relative=False),
],
)
创建 Ax 实验
在 Ax 中,Experiment 对象是存储有关问题设置的所有信息的对象。
from ax.core import Experiment
experiment = Experiment(
name="torchx_mnist",
search_space=search_space,
optimization_config=opt_config,
runner=ax_runner,
)
选择生成策略
GenerationStrategy 是我们希望执行优化的抽象表示。虽然这可以定制(如果您愿意这样做,请参阅此教程),但在大多数情况下,Ax 可以根据搜索空间、优化配置和我们想要运行的总试验次数自动确定适当的策略。
通常,Ax 选择在开始基于模型的贝叶斯优化策略之前评估一些随机配置。
total_trials = 48 # total evaluation budget
from ax.modelbridge.dispatch_utils import choose_generation_strategy
gs = choose_generation_strategy(
search_space=experiment.search_space,
optimization_config=experiment.optimization_config,
num_trials=total_trials,
)
[INFO 02-03 05:14:14] ax.modelbridge.dispatch_utils: Using Models.BOTORCH_MODULAR since there are more ordered parameters than there are categories for the unordered categorical parameters.
[INFO 02-03 05:14:14] ax.modelbridge.dispatch_utils: Calculating the number of remaining initialization trials based on num_initialization_trials=None max_initialization_trials=None num_tunable_parameters=6 num_trials=48 use_batch_trials=False
[INFO 02-03 05:14:14] ax.modelbridge.dispatch_utils: calculated num_initialization_trials=9
[INFO 02-03 05:14:14] ax.modelbridge.dispatch_utils: num_completed_initialization_trials=0 num_remaining_initialization_trials=9
[INFO 02-03 05:14:14] ax.modelbridge.dispatch_utils: `verbose`, `disable_progbar`, and `jit_compile` are not yet supported when using `choose_generation_strategy` with ModularBoTorchModel, dropping these arguments.
[INFO 02-03 05:14:14] ax.modelbridge.dispatch_utils: Using Bayesian Optimization generation strategy: GenerationStrategy(name='Sobol+BoTorch', steps=[Sobol for 9 trials, BoTorch for subsequent trials]). Iterations after 9 will take longer to generate due to model-fitting.
配置调度程序
Scheduler 充当优化的循环控制器。它与后端通信,启动试验,检查它们的状态,并检索结果。在本教程中,它只是读取和解析本地保存的日志。在远程执行设置中,它将调用 API。来自 Ax Scheduler 教程 的以下插图总结了 Scheduler 与用于运行试验评估的外部系统的交互方式:
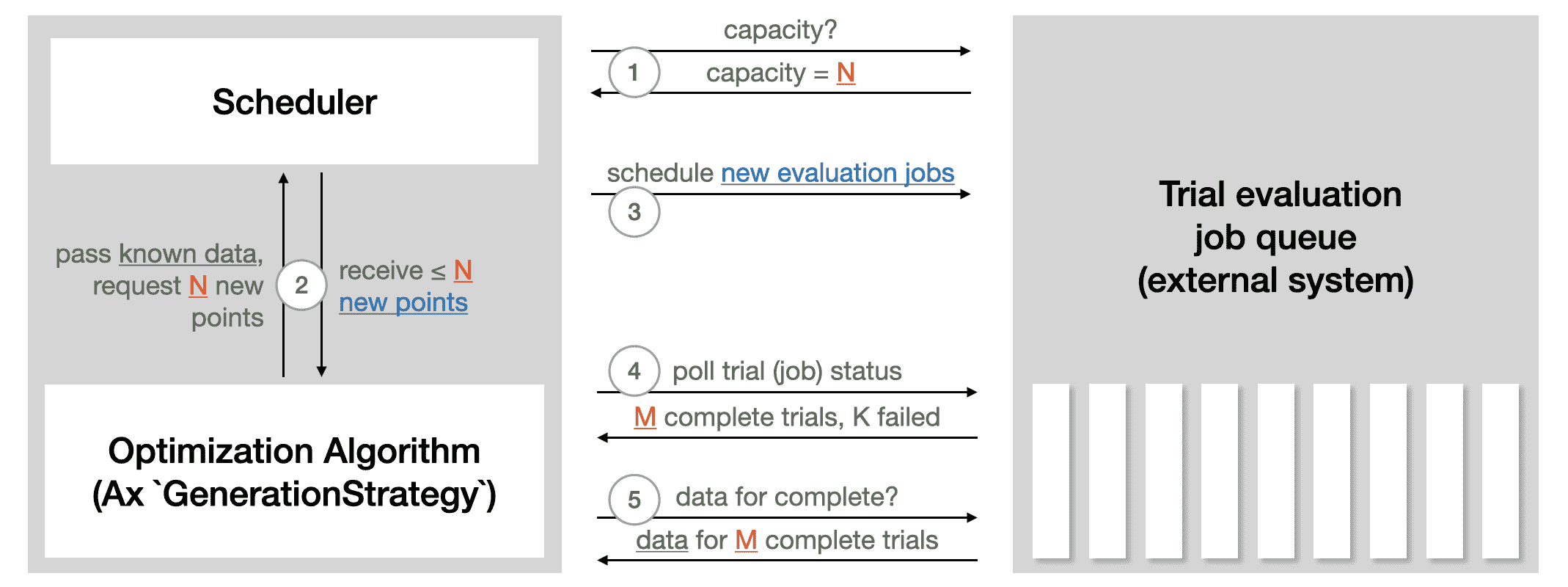
调度程序 需要 实验 和 生成策略。一组选项可以通过 调度程序选项 传递进来。在这里,我们配置了总评估次数以及 max_pending_trials,即应同时运行的最大试验数。在我们的本地设置中,这是作为单独进程运行的训练作业的数量,而在远程执行设置中,这将是您想要并行使用的机器数量。
from ax.service.scheduler import Scheduler, SchedulerOptions
scheduler = Scheduler(
experiment=experiment,
generation_strategy=gs,
options=SchedulerOptions(
total_trials=total_trials, max_pending_trials=4
),
)
[INFO 02-03 05:14:15] Scheduler: `Scheduler` requires experiment to have immutable search space and optimization config. Setting property immutable_search_space_and_opt_config to `True` on experiment.
运行优化
现在一切都配置好了,我们可以让 Ax 以完全自动化的方式运行优化。调度程序将定期检查日志,以获取所有当前运行试验的状态,如果一个试验完成,调度程序将更新其在实验中的状态,并获取贝叶斯优化算法所需的观察结果。
scheduler.run_all_trials()
[INFO 02-03 05:14:15] Scheduler: Running trials [0]...
[INFO 02-03 05:14:16] Scheduler: Running trials [1]...
[INFO 02-03 05:14:17] Scheduler: Running trials [2]...
[INFO 02-03 05:14:18] Scheduler: Running trials [3]...
[INFO 02-03 05:14:19] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 4).
[INFO 02-03 05:14:20] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 4).
[INFO 02-03 05:14:21] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 4).
[INFO 02-03 05:14:23] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 4).
[INFO 02-03 05:14:27] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 4).
[INFO 02-03 05:14:32] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 4).
[INFO 02-03 05:14:39] Scheduler: Waiting for completed trials (for 11 sec, currently running trials: 4).
[INFO 02-03 05:14:51] Scheduler: Waiting for completed trials (for 17 sec, currently running trials: 4).
[INFO 02-03 05:15:08] Scheduler: Retrieved COMPLETED trials: [1, 3].
[INFO 02-03 05:15:08] Scheduler: Fetching data for trials: [1, 3].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:15:08] Scheduler: Running trials [4]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:15:09] Scheduler: Running trials [5]...
[INFO 02-03 05:15:10] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 4).
[INFO 02-03 05:15:11] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 4).
[INFO 02-03 05:15:13] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 4).
[INFO 02-03 05:15:15] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 4).
[INFO 02-03 05:15:18] Scheduler: Retrieved COMPLETED trials: [2].
[INFO 02-03 05:15:18] Scheduler: Fetching data for trials: [2].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:15:18] Scheduler: Running trials [6]...
[INFO 02-03 05:15:19] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 4).
[INFO 02-03 05:15:20] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 4).
[INFO 02-03 05:15:22] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 4).
[INFO 02-03 05:15:24] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 4).
[INFO 02-03 05:15:27] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 4).
[INFO 02-03 05:15:33] Scheduler: Retrieved COMPLETED trials: [0].
[INFO 02-03 05:15:33] Scheduler: Fetching data for trials: [0].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:15:33] Scheduler: Running trials [7]...
[INFO 02-03 05:15:34] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 4).
[INFO 02-03 05:15:35] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 4).
[INFO 02-03 05:15:36] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 4).
[INFO 02-03 05:15:38] Scheduler: Retrieved COMPLETED trials: [4].
[INFO 02-03 05:15:38] Scheduler: Fetching data for trials: [4].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:15:38] Scheduler: Running trials [8]...
[INFO 02-03 05:15:39] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 4).
[INFO 02-03 05:15:40] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 4).
[INFO 02-03 05:15:42] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 4).
[INFO 02-03 05:15:44] Scheduler: Retrieved COMPLETED trials: [5].
[INFO 02-03 05:15:44] Scheduler: Fetching data for trials: [5].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:15:46] Scheduler: Running trials [9]...
[INFO 02-03 05:15:47] Scheduler: Retrieved COMPLETED trials: [6].
[INFO 02-03 05:15:47] Scheduler: Fetching data for trials: [6].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:15:50] Scheduler: Running trials [10]...
[INFO 02-03 05:15:51] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 4).
[INFO 02-03 05:15:52] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 4).
[INFO 02-03 05:15:54] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 4).
[INFO 02-03 05:15:56] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 4).
[INFO 02-03 05:15:59] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 4).
[INFO 02-03 05:16:05] Scheduler: Retrieved COMPLETED trials: [8].
[INFO 02-03 05:16:05] Scheduler: Fetching data for trials: [8].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:16:06] Scheduler: Running trials [11]...
[INFO 02-03 05:16:07] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 4).
[INFO 02-03 05:16:08] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 4).
[INFO 02-03 05:16:10] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 4).
[INFO 02-03 05:16:12] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 4).
[INFO 02-03 05:16:16] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 4).
[INFO 02-03 05:16:21] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 4).
[INFO 02-03 05:16:28] Scheduler: Retrieved COMPLETED trials: [7].
[INFO 02-03 05:16:28] Scheduler: Fetching data for trials: [7].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:16:28] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 02-03 05:16:29] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 02-03 05:16:31] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 02-03 05:16:33] Scheduler: Retrieved COMPLETED trials: [9].
[INFO 02-03 05:16:33] Scheduler: Fetching data for trials: [9].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:16:35] Scheduler: Running trials [12]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:16:36] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:16:36] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:16:36] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 02-03 05:16:37] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 02-03 05:16:39] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 02-03 05:16:41] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 02-03 05:16:45] Scheduler: Retrieved COMPLETED trials: [10].
[INFO 02-03 05:16:45] Scheduler: Fetching data for trials: [10].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:16:48] Scheduler: Running trials [13]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:16:48] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:16:48] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:16:48] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 02-03 05:16:49] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 02-03 05:16:50] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 02-03 05:16:52] Scheduler: Retrieved COMPLETED trials: [11].
[INFO 02-03 05:16:52] Scheduler: Fetching data for trials: [11].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:16:55] Scheduler: Running trials [14]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:16:56] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:16:56] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:16:56] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 02-03 05:16:57] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 02-03 05:16:58] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 02-03 05:17:00] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 02-03 05:17:04] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 02-03 05:17:09] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 3).
[INFO 02-03 05:17:17] Scheduler: Retrieved COMPLETED trials: [12].
[INFO 02-03 05:17:17] Scheduler: Fetching data for trials: [12].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:17:20] Scheduler: Running trials [15]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:17:21] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:17:21] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:17:21] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 02-03 05:17:22] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 02-03 05:17:23] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 02-03 05:17:25] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 02-03 05:17:29] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 02-03 05:17:34] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 3).
[INFO 02-03 05:17:41] Scheduler: Retrieved COMPLETED trials: [14].
[INFO 02-03 05:17:41] Scheduler: Fetching data for trials: [14].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:17:44] Scheduler: Running trials [16]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:17:45] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:17:45] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:17:45] Scheduler: Retrieved COMPLETED trials: [13].
[INFO 02-03 05:17:45] Scheduler: Fetching data for trials: [13].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:17:48] Scheduler: Running trials [17]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:17:49] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:17:49] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:17:49] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 02-03 05:17:50] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 02-03 05:17:52] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 02-03 05:17:54] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 02-03 05:17:58] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 02-03 05:18:03] Scheduler: Retrieved COMPLETED trials: [15].
[INFO 02-03 05:18:03] Scheduler: Fetching data for trials: [15].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:18:08] Scheduler: Running trials [18]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:18:09] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:18:09] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:18:09] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 02-03 05:18:10] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 02-03 05:18:12] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 02-03 05:18:14] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 02-03 05:18:18] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 02-03 05:18:23] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 3).
[INFO 02-03 05:18:30] Scheduler: Retrieved COMPLETED trials: [17].
[INFO 02-03 05:18:30] Scheduler: Fetching data for trials: [17].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:18:34] Scheduler: Running trials [19]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:18:35] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:18:35] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:18:35] Scheduler: Retrieved COMPLETED trials: [16].
[INFO 02-03 05:18:35] Scheduler: Fetching data for trials: [16].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:18:39] Scheduler: Running trials [20]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:18:40] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:18:40] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:18:40] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 02-03 05:18:41] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 02-03 05:18:43] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 02-03 05:18:45] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 02-03 05:18:48] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 02-03 05:18:54] Scheduler: Retrieved COMPLETED trials: [18].
[INFO 02-03 05:18:54] Scheduler: Fetching data for trials: [18].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:18:57] Scheduler: Running trials [21]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:18:58] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:18:58] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:18:58] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 02-03 05:18:59] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 02-03 05:19:00] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 02-03 05:19:02] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 02-03 05:19:06] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 02-03 05:19:11] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 3).
[INFO 02-03 05:19:19] Scheduler: Retrieved COMPLETED trials: [19].
[INFO 02-03 05:19:19] Scheduler: Fetching data for trials: [19].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:19:22] Scheduler: Running trials [22]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:19:23] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:19:23] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:19:23] Scheduler: Retrieved COMPLETED trials: [20].
[INFO 02-03 05:19:23] Scheduler: Fetching data for trials: [20].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:19:26] Scheduler: Running trials [23]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:19:27] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:19:27] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:19:27] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 02-03 05:19:28] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 02-03 05:19:30] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 02-03 05:19:32] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 02-03 05:19:36] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 02-03 05:19:41] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 3).
[INFO 02-03 05:19:48] Scheduler: Waiting for completed trials (for 11 sec, currently running trials: 3).
[INFO 02-03 05:20:00] Scheduler: Retrieved COMPLETED trials: [21, 23].
[INFO 02-03 05:20:00] Scheduler: Fetching data for trials: [21, 23].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:20:03] Scheduler: Running trials [24]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:20:04] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:20:07] Scheduler: Running trials [25]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:20:08] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:20:08] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:20:08] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 02-03 05:20:09] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 02-03 05:20:11] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 02-03 05:20:13] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 02-03 05:20:17] Scheduler: Retrieved COMPLETED trials: [22].
[INFO 02-03 05:20:17] Scheduler: Fetching data for trials: [22].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:20:20] Scheduler: Running trials [26]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:20:21] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:20:21] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:20:21] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 02-03 05:20:22] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 02-03 05:20:24] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 02-03 05:20:26] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 02-03 05:20:29] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 02-03 05:20:34] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 3).
[INFO 02-03 05:20:42] Scheduler: Waiting for completed trials (for 11 sec, currently running trials: 3).
[INFO 02-03 05:20:53] Scheduler: Waiting for completed trials (for 17 sec, currently running trials: 3).
[INFO 02-03 05:21:11] Scheduler: Retrieved COMPLETED trials: 24 - 25.
[INFO 02-03 05:21:11] Scheduler: Fetching data for trials: 24 - 25.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:21:15] Scheduler: Running trials [27]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:21:16] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:21:19] Scheduler: Running trials [28]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:21:20] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:21:20] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:21:20] Scheduler: Retrieved COMPLETED trials: [26].
[INFO 02-03 05:21:20] Scheduler: Fetching data for trials: [26].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:21:25] Scheduler: Running trials [29]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:21:26] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:21:26] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:21:26] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 02-03 05:21:27] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 02-03 05:21:29] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 02-03 05:21:31] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 02-03 05:21:34] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 02-03 05:21:39] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 3).
[INFO 02-03 05:21:47] Scheduler: Waiting for completed trials (for 11 sec, currently running trials: 3).
[INFO 02-03 05:21:58] Scheduler: Waiting for completed trials (for 17 sec, currently running trials: 3).
[INFO 02-03 05:22:16] Scheduler: Retrieved COMPLETED trials: 27 - 29.
[INFO 02-03 05:22:16] Scheduler: Fetching data for trials: 27 - 29.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:22:20] Scheduler: Running trials [30]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:22:21] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:22:24] Scheduler: Running trials [31]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:22:25] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:22:30] Scheduler: Running trials [32]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:22:31] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:22:31] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:22:31] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 02-03 05:22:32] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 02-03 05:22:34] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 02-03 05:22:36] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 02-03 05:22:40] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 02-03 05:22:45] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 3).
[INFO 02-03 05:22:52] Scheduler: Waiting for completed trials (for 11 sec, currently running trials: 3).
[INFO 02-03 05:23:04] Scheduler: Waiting for completed trials (for 17 sec, currently running trials: 3).
[INFO 02-03 05:23:21] Scheduler: Retrieved COMPLETED trials: 30 - 32.
[INFO 02-03 05:23:21] Scheduler: Fetching data for trials: 30 - 32.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:23:26] Scheduler: Running trials [33]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:23:27] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:23:32] Scheduler: Running trials [34]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:23:33] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:23:38] Scheduler: Running trials [35]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:23:38] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:23:38] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:23:38] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 02-03 05:23:39] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 02-03 05:23:41] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 02-03 05:23:43] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 02-03 05:23:47] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 02-03 05:23:52] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 3).
[INFO 02-03 05:23:59] Scheduler: Waiting for completed trials (for 11 sec, currently running trials: 3).
[INFO 02-03 05:24:11] Scheduler: Waiting for completed trials (for 17 sec, currently running trials: 3).
[INFO 02-03 05:24:28] Scheduler: Retrieved COMPLETED trials: 33 - 34.
[INFO 02-03 05:24:28] Scheduler: Fetching data for trials: 33 - 34.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:24:34] Scheduler: Running trials [36]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:24:35] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:24:41] Scheduler: Running trials [37]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:24:42] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:24:42] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:24:42] Scheduler: Retrieved COMPLETED trials: [35].
[INFO 02-03 05:24:42] Scheduler: Fetching data for trials: [35].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:24:48] Scheduler: Running trials [38]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:24:49] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:24:49] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:24:49] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 02-03 05:24:50] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 02-03 05:24:51] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 02-03 05:24:53] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 02-03 05:24:57] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 02-03 05:25:02] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 3).
[INFO 02-03 05:25:10] Scheduler: Waiting for completed trials (for 11 sec, currently running trials: 3).
[INFO 02-03 05:25:21] Scheduler: Waiting for completed trials (for 17 sec, currently running trials: 3).
[INFO 02-03 05:25:38] Scheduler: Retrieved COMPLETED trials: 36 - 38.
[INFO 02-03 05:25:38] Scheduler: Fetching data for trials: 36 - 38.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:25:42] Scheduler: Running trials [39]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:25:42] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:25:47] Scheduler: Running trials [40]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:25:47] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:25:54] Scheduler: Running trials [41]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:25:55] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:25:55] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:25:55] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 02-03 05:25:56] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 02-03 05:25:58] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 02-03 05:26:00] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 02-03 05:26:03] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 02-03 05:26:09] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 3).
[INFO 02-03 05:26:16] Scheduler: Waiting for completed trials (for 11 sec, currently running trials: 3).
[INFO 02-03 05:26:28] Scheduler: Retrieved COMPLETED trials: [39].
[INFO 02-03 05:26:28] Scheduler: Fetching data for trials: [39].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:26:33] Scheduler: Running trials [42]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:26:34] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:26:34] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:26:34] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 02-03 05:26:35] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 02-03 05:26:37] Scheduler: Retrieved COMPLETED trials: [40].
[INFO 02-03 05:26:37] Scheduler: Fetching data for trials: [40].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:26:44] Scheduler: Running trials [43]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:26:45] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:26:45] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:26:45] Scheduler: Retrieved COMPLETED trials: [41].
[INFO 02-03 05:26:45] Scheduler: Fetching data for trials: [41].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:26:50] Scheduler: Running trials [44]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:26:51] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:26:51] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:26:51] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 02-03 05:26:52] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 02-03 05:26:54] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 02-03 05:26:56] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 02-03 05:27:00] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 02-03 05:27:05] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 3).
[INFO 02-03 05:27:12] Scheduler: Retrieved COMPLETED trials: [42].
[INFO 02-03 05:27:12] Scheduler: Fetching data for trials: [42].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:27:18] Scheduler: Running trials [45]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:27:19] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:27:19] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:27:19] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 02-03 05:27:20] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 02-03 05:27:21] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 02-03 05:27:23] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 02-03 05:27:27] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 02-03 05:27:32] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 3).
[INFO 02-03 05:27:40] Scheduler: Retrieved COMPLETED trials: [43].
[INFO 02-03 05:27:40] Scheduler: Fetching data for trials: [43].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:27:45] Scheduler: Running trials [46]...
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:27:46] ax.modelbridge.torch: The observations are identical to the last set of observations used to fit the model. Skipping model fitting.
[INFO 02-03 05:27:46] Scheduler: Generated all trials that can be generated currently. Max parallelism currently reached.
[INFO 02-03 05:27:46] Scheduler: Retrieved COMPLETED trials: [44].
[INFO 02-03 05:27:46] Scheduler: Fetching data for trials: [44].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:27:52] Scheduler: Running trials [47]...
[INFO 02-03 05:27:53] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 3).
[INFO 02-03 05:27:54] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 3).
[INFO 02-03 05:27:55] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 3).
[INFO 02-03 05:27:58] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 3).
[INFO 02-03 05:28:01] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 3).
[INFO 02-03 05:28:06] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 3).
[INFO 02-03 05:28:14] Scheduler: Retrieved COMPLETED trials: [45].
[INFO 02-03 05:28:14] Scheduler: Fetching data for trials: [45].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:28:14] Scheduler: Done submitting trials, waiting for remaining 2 running trials...
[INFO 02-03 05:28:14] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 2).
[INFO 02-03 05:28:15] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 2).
[INFO 02-03 05:28:16] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 2).
[INFO 02-03 05:28:19] Scheduler: Waiting for completed trials (for 3 sec, currently running trials: 2).
[INFO 02-03 05:28:22] Scheduler: Waiting for completed trials (for 5 sec, currently running trials: 2).
[INFO 02-03 05:28:27] Scheduler: Waiting for completed trials (for 7 sec, currently running trials: 2).
[INFO 02-03 05:28:35] Scheduler: Retrieved COMPLETED trials: [46].
[INFO 02-03 05:28:35] Scheduler: Fetching data for trials: [46].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[INFO 02-03 05:28:35] Scheduler: Waiting for completed trials (for 1 sec, currently running trials: 1).
[INFO 02-03 05:28:36] Scheduler: Waiting for completed trials (for 1.5 sec, currently running trials: 1).
[INFO 02-03 05:28:37] Scheduler: Waiting for completed trials (for 2 sec, currently running trials: 1).
[INFO 02-03 05:28:40] Scheduler: Retrieved COMPLETED trials: [47].
[INFO 02-03 05:28:40] Scheduler: Fetching data for trials: [47].
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
OptimizationResult()
评估结果
现在我们可以使用 Ax 提供的辅助函数和可视化工具来检查优化结果。
首先,我们生成一个包含实验结果摘要的数据框。该数据框中的每一行对应一个试验(即运行的训练作业),包含试验的状态、评估的参数配置以及观察到的度量值信息。这提供了一个简单的方法来检查优化的情况。
from ax.service.utils.report_utils import exp_to_df
df = exp_to_df(experiment)
df.head(10)
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[WARNING 02-03 05:28:40] ax.service.utils.report_utils: Column reason missing for all trials. Not appending column.
| 试验索引 | arm 名称 | 试验状态 | 生成方法 | 是否可行 | 参数数量 | 准确率 | 隐藏层大小 1 | 隐藏层大小 2 | 学习率 | 迭代次数 | 丢失率 | 批量大小 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0_0 | 完成 | Sobol | False | 16810.0 | 0.908757 | 19 | 66 | 0.003182 | 4 | 0.190970 | 32 |
| 1 | 1 | 1_0 | 完成 | Sobol | False | 21926.0 | 0.887460 | 23 | 118 | 0.000145 | 3 | 0.465754 | 256 |
| 2 | 2 | 2_0 | 完成 | Sobol | True | 37560.0 | 0.947588 | 40 | 124 | 0.002745 | 4 | 0.196600 | 64 |
| 3 | 3 | 3_0 | 完成 | Sobol | 假 | 14756.0 | 0.893096 | 18 | 23 | 0.000166 | 4 | 0.169496 | 256 |
| 4 | 4 | 4_0 | 完成 | Sobol | 真 | 71630.0 | 0.948927 | 80 | 99 | 0.000642 | 2 | 0.291277 | 128 |
| 5 | 5 | 5_0 | 完成 | Sobol | 假 | 13948.0 | 0.922692 | 16 | 54 | 0.000444 | 2 | 0.057552 | 64 |
| 6 | 6 | 6_0 | 完成 | Sobol | 假 | 24686.0 | 0.863779 | 29 | 50 | 0.000177 | 2 | 0.435030 | 256 |
| 7 | 7 | 7_0 | 完成 | Sobol | 假 | 18290.0 | 0.877033 | 20 | 87 | 0.000119 | 4 | 0.462744 | 256 |
| 8 | 8 | 8_0 | 完成 | Sobol | 假 | 20996.0 | 0.859434 | 26 | 17 | 0.005245 | 1 | 0.455813 | 32 |
| 9 | 9 | 9_0 | 完成 | BoTorch | 真 | 53063.0 | 0.962563 | 57 | 125 | 0.001972 | 3 | 0.177780 | 64 |
我们还可以可视化验证准确性和模型参数数量之间的权衡的帕累托前沿。
提示
Ax 使用 Plotly 生成交互式图表,允许您进行缩放、裁剪或悬停以查看图表组件的详细信息。试试看,并查看可视化教程以了解更多信息。
最终优化结果显示在下面的图中,其中颜色对应于每次试验的迭代次数。我们看到我们的方法能够成功地探索权衡,并找到具有高验证准确性的大型模型,以及具有相对较低验证准确性的小型模型。
from ax.service.utils.report_utils import _pareto_frontier_scatter_2d_plotly
_pareto_frontier_scatter_2d_plotly(experiment)
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/ax/core/map_data.py:188: FutureWarning:
The behavior of DataFrame concatenation with empty or all-NA entries is deprecated. In a future version, this will no longer exclude empty or all-NA columns when determining the result dtypes. To retain the old behavior, exclude the relevant entries before the concat operation.
[WARNING 02-03 05:28:40] ax.service.utils.report_utils: Column reason missing for all trials. Not appending column.
为了更好地了解我们的代理模型对黑匣子目标学到了什么,我们可以看一下留一出交叉验证的结果。由于我们的模型是高斯过程,它们不仅提供点预测,还提供关于这些预测的不确定性估计。一个好的模型意味着预测的均值(图中的点)接近 45 度线,置信区间覆盖 45 度线并且以期望的频率(这里我们使用 95%的置信区间,所以我们期望它们在真实观察中包含 95%的时间)。
如下图所示,模型大小(num_params)指标比验证准确度(val_acc)指标更容易建模。
from ax.modelbridge.cross_validation import compute_diagnostics, cross_validate
from ax.plot.diagnostic import interact_cross_validation_plotly
from ax.utils.notebook.plotting import init_notebook_plotting, render
cv = cross_validate(model=gs.model) # The surrogate model is stored on the ``GenerationStrategy``
compute_diagnostics(cv)
interact_cross_validation_plotly(cv)
我们还可以制作等高线图,以更好地了解不同目标如何依赖于两个输入参数。在下图中,我们显示模型预测的验证准确度与两个隐藏大小的关系。验证准确度明显随着隐藏大小的增加而增加。
from ax.plot.contour import interact_contour_plotly
interact_contour_plotly(model=gs.model, metric_name="val_acc")
同样,我们在下图中显示模型参数数量与隐藏大小的关系,并看到它也随着隐藏大小的增加而增加(对hidden_size_1的依赖性更大)。
interact_contour_plotly(model=gs.model, metric_name="num_params")
致谢
我们感谢 TorchX 团队(特别是 Kiuk Chung 和 Tristan Rice)在将 TorchX 与 Ax 集成方面的帮助。
脚本的总运行时间:(14 分钟 44.258 秒)
下载 Python 源代码:ax_multiobjective_nas_tutorial.py
下载 Jupyter 笔记本: ax_multiobjective_nas_tutorial.ipynb
Sphinx-Gallery 生成的画廊