在生产环境中部署 PyTorch 模型
通过 Flask 在 Python 中部署 PyTorch 的 REST API
原文:
pytorch.org/tutorials/intermediate/flask_rest_api_tutorial.html译者:飞龙
协议:CC BY-NC-SA 4.0
注意
点击这里下载完整的示例代码
作者:Avinash Sajjanshetty
在本教程中,我们将使用 Flask 部署 PyTorch 模型,并为模型推理暴露一个 REST API。特别是,我们将部署一个预训练的 DenseNet 121 模型来检测图像。
提示
这里使用的所有代码都是根据 MIT 许可发布的,并且可以在Github上找到。
这代表了一系列关于在生产中部署 PyTorch 模型的教程中的第一篇。以这种方式使用 Flask 是迄今为止最简单的开始为您的 PyTorch 模型提供服务的方法,但对于高性能要求的用例不适用。为此:
- 如果您已经熟悉 TorchScript,可以直接查看我们的C++中加载 TorchScript 模型教程。
- 如果您需要关于 TorchScript 的复习,请查看我们的TorchScript 简介教程。
API 定义
我们将首先定义我们的 API 端点、请求和响应类型。我们的 API 端点将位于/predict,接受带有file参数的 HTTP POST 请求,该参数包含图像。响应将是一个包含预测的 JSON 响应:
{"class_id": "n02124075", "class_name": "Egyptian_cat"}
依赖项
通过运行以下命令安装所需的依赖项:
pip install Flask==2.0.1 torchvision==0.10.0
简单的 Web 服务器
以下是一个简单的 Web 服务器,摘自 Flask 的文档
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello():
return 'Hello World!'
我们还将更改响应类型,以便返回一个包含 ImageNet 类别 ID 和名称的 JSON 响应。更新后的app.py文件将是:
from flask import Flask, jsonify
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():
return jsonify({'class_id': 'IMAGE_NET_XXX', 'class_name': 'Cat'})
推理
在接下来的部分中,我们将专注于编写推理代码。这将涉及两个部分,一个是我们准备图像以便它可以被馈送到 DenseNet 中,接下来,我们将编写代码从模型中获取实际预测。
准备图像
DenseNet 模型要求图像为尺寸为 224 x 224 的 3 通道 RGB 图像。我们还将使用所需的均值和标准差值对图像张量进行归一化。您可以在这里了解更多信息。
我们将使用torchvision库中的transforms构建一个转换管道,根据需要转换我们的图像。您可以在这里了解更多关于转换的信息。
import io
import torchvision.transforms as transforms
from PIL import Image
def transform_image(image_bytes):
my_transforms = transforms.Compose([transforms.Resize(255),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
[0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
image = Image.open(io.BytesIO(image_bytes))
return my_transforms(image).unsqueeze(0)
上述方法接受字节形式的图像数据,应用一系列转换并返回一个张量。要测试上述方法,请以字节模式读取图像文件(首先用您计算机上文件的实际路径替换…/_static/https://gitcode.net/OpenDocCN/pytorch-doc-zh/-/raw/master/docs/2.2/img/sample_file.jpeg),看看是否返回一个张量:
with open("../_static/https://gitcode.net/OpenDocCN/pytorch-doc-zh/-/raw/master/docs/2.2/img/sample_file.jpeg", 'rb') as f:
image_bytes = f.read()
tensor = transform_image(image_bytes=image_bytes)
print(tensor)
预测
现在我们将使用一个预训练的 DenseNet 121 模型来预测图像类别。我们将使用torchvision库中的一个模型,加载模型并进行推理。虽然在此示例中我们将使用一个预训练模型,但您可以使用相同的方法来加载您自己的模型。在这个 tutorial 中了解更多关于加载您的模型的信息。
from torchvision import models
# Make sure to set `weights` as `'IMAGENET1K_V1'` to use the pretrained weights:
model = models.densenet121(weights='IMAGENET1K_V1')
# Since we are using our model only for inference, switch to `eval` mode:
model.eval()
def get_prediction(image_bytes):
tensor = transform_image(image_bytes=image_bytes)
outputs = model.forward(tensor)
_, y_hat = outputs.max(1)
return y_hat
张量y_hat将包含预测类别 ID 的索引。然而,我们需要一个可读的类别名称。为此,我们需要一个类别 ID 到名称的映射。下载此文件作为imagenet_class_index.json并记住保存的位置(或者,如果您按照本教程中的确切步骤进行操作,请将其保存在 tutorials/_static 中)。该文件包含 ImageNet 类别 ID 到 ImageNet 类别名称的映射。我们将加载此 JSON 文件并获取预测索引的类别名称。
import json
imagenet_class_index = json.load(open('../_static/imagenet_class_index.json'))
def get_prediction(image_bytes):
tensor = transform_image(image_bytes=image_bytes)
outputs = model.forward(tensor)
_, y_hat = outputs.max(1)
predicted_idx = str(y_hat.item())
return imagenet_class_index[predicted_idx]
在使用imagenet_class_index字典之前,我们将首先将张量值转换为字符串值,因为imagenet_class_index字典中的键是字符串。我们将测试我们上面的方法:
with open("../_static/https://gitcode.net/OpenDocCN/pytorch-doc-zh/-/raw/master/docs/2.2/img/sample_file.jpeg", 'rb') as f:
image_bytes = f.read()
print(get_prediction(image_bytes=image_bytes))
您应该会收到这样的响应:
['n02124075', 'Egyptian_cat']
数组中的第一项是 ImageNet 类别 ID,第二项是可读的名称。
将模型集成到我们的 API 服务器中
在最后一部分中,我们将把我们的模型添加到我们的 Flask API 服务器中。由于我们的 API 服务器应该接受一个图像文件,我们将更新我们的predict方法以从请求中读取文件:
from flask import request
@app.route('/predict', methods=['POST'])
def predict():
if request.method == 'POST':
# we will get the file from the request
file = request.files['file']
# convert that to bytes
img_bytes = file.read()
class_id, class_name = get_prediction(image_bytes=img_bytes)
return jsonify({'class_id': class_id, 'class_name': class_name})
import io import json from torchvision import models import torchvision.transforms as transforms from PIL import Image from flask import Flask, jsonify, request app = Flask(__name__) imagenet_class_index = json.load(open('<PATH/TO/.json/FILE>/imagenet_class_index.json')) model = models.densenet121(weights='IMAGENET1K_V1') model.eval() def transform_image(image_bytes): my_transforms = transforms.Compose([transforms.Resize(255), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize( [0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]) image = Image.open(io.BytesIO(image_bytes)) return my_transforms(image).unsqueeze(0) def get_prediction(image_bytes): tensor = transform_image(image_bytes=image_bytes) outputs = model.forward(tensor) _, y_hat = outputs.max(1) predicted_idx = str(y_hat.item()) return imagenet_class_index[predicted_idx] @app.route('/predict', methods=['POST']) def predict(): if request.method == 'POST': file = request.files['file'] img_bytes = file.read() class_id, class_name = get_prediction(image_bytes=img_bytes) return jsonify({'class_id': class_id, 'class_name': class_name}) if __name__ == '__main__': app.run()FLASK_ENV=development FLASK_APP=app.py flask run发送 POST 请求到我们的应用程序的库:
import requests resp = requests.post("http://localhost:5000/predict", files={"file": open('<PATH/TO/.jpg/FILE>/cat.jpg','rb')})
现在打印 resp.json()将显示以下内容:
{"class_id": "n02124075", "class_name": "Egyptian_cat"}我们编写的服务器相当简单,可能无法满足您的生产应用程序的所有需求。因此,以下是一些可以改进的事项:
- 端点
/predict假定请求中始终会有一个图像文件。这可能并非对所有请求都成立。我们的用户可能使用不同的参数发送图像,或者根本不发送图像。- 用户也可以发送非图像类型的文件。由于我们没有处理错误,这将破坏我们的服务器。添加一个明确的错误处理路径,将抛出异常,这样我们就可以更好地处理不良输入。
- 尽管模型可以识别大量图像类别,但可能无法识别所有图像。增强实现以处理模型无法识别图像的情况。
- 我们以开发模式运行 Flask 服务器,这不适合在生产中部署。您可以查看此教程以在生产中部署 Flask 服务器。
- 您还可以通过创建一个带有表单的页面来添加 UI,该表单接受图像并显示预测结果。查看类似项目的演示及其源代码。
- 在本教程中,我们仅展示了如何构建一个可以一次返回单个图像预测的服务。我们可以修改我们的服务,使其能够一次返回多个图像的预测。此外,service-streamer库会自动将请求排入您的服务队列,并将其抽样成可以馈送到模型中的小批次。您可以查看此教程。
- 最后,我们鼓励您查看我们在页面顶部链接的其他部署 PyTorch 模型的教程。
脚本的总运行时间:(0 分钟 0.000 秒)
下载 Python 源代码:flask_rest_api_tutorial.py
下载 Jupyter 笔记本:flask_rest_api_tutorial.ipynb
Sphinx-Gallery 生成的图库
TorchScript 介绍
原文:
pytorch.org/tutorials/beginner/Intro_to_TorchScript_tutorial.html译者:飞龙
协议:CC BY-NC-SA 4.0
注意
点击这里下载完整的示例代码
作者: James Reed (jamesreed@fb.com), Michael Suo (suo@fb.com), rev2
本教程是 TorchScript 的介绍,TorchScript 是 PyTorch 模型(nn.Module子类)的中间表示,然后可以在高性能环境(如 C++)中运行。
在本教程中,我们将涵盖:
- PyTorch 中模型编写的基础,包括:
-
模块
-
定义
forward函数 -
将模块组合成模块层次结构
- 将 PyTorch 模块转换为 TorchScript 的特定方法,我们的高性能部署运行时
-
跟踪现有模块
-
使用脚本编译模块
-
如何组合这两种方法
-
保存和加载 TorchScript 模块
我们希望在完成本教程后,您将继续阅读后续教程,该教程将指导您实际从 C++中调用 TorchScript 模型的示例。
import torch # This is all you need to use both PyTorch and TorchScript!
print(torch.__version__)
torch.manual_seed(191009) # set the seed for reproducibility
2.2.0+cu121
<torch._C.Generator object at 0x7fcf1e81f070>
PyTorch 模型编写基础
让我们从定义一个简单的Module开始。Module是 PyTorch 中的组合基本单元。它包含:
-
一个构造函数,为调用准备模块
-
一组
Parameters和子Modules。这些由构造函数初始化,并且可以在调用期间被模块使用。 -
一个
forward函数。这是在调用模块时运行的代码。
让我们来看一个小例子:
class MyCell(torch.nn.Module):
def __init__(self):
super(MyCell, self).__init__()
def forward(self, x, h):
new_h = torch.tanh(x + h)
return new_h, new_h
my_cell = MyCell()
x = torch.rand(3, 4)
h = torch.rand(3, 4)
print(my_cell(x, h))
(tensor([[0.8219, 0.8990, 0.6670, 0.8277],
[0.5176, 0.4017, 0.8545, 0.7336],
[0.6013, 0.6992, 0.2618, 0.6668]]), tensor([[0.8219, 0.8990, 0.6670, 0.8277],
[0.5176, 0.4017, 0.8545, 0.7336],
[0.6013, 0.6992, 0.2618, 0.6668]]))
所以我们:
-
创建了一个继承
torch.nn.Module的类。 -
定义了一个构造函数。构造函数并没有做太多事情,只是调用了
super的构造函数。 -
定义了一个
forward函数,它接受两个输入并返回两个输出。forward函数的实际内容并不是很重要,但它有点像一个虚假的RNN 单元——也就是说——它是一个在循环中应用的函数。
我们实例化了模块,并创建了x和h,它们只是随机值的 3x4 矩阵。然后我们用my_cell(x, h)调用了这个单元。这反过来调用了我们的forward函数。
让我们做一些更有趣的事情:
class MyCell(torch.nn.Module):
def __init__(self):
super(MyCell, self).__init__()
self.linear = torch.nn.Linear(4, 4)
def forward(self, x, h):
new_h = torch.tanh(self.linear(x) + h)
return new_h, new_h
my_cell = MyCell()
print(my_cell)
print(my_cell(x, h))
MyCell(
(linear): Linear(in_features=4, out_features=4, bias=True)
)
(tensor([[ 0.8573, 0.6190, 0.5774, 0.7869],
[ 0.3326, 0.0530, 0.0702, 0.8114],
[ 0.7818, -0.0506, 0.4039, 0.7967]], grad_fn=<TanhBackward0>), tensor([[ 0.8573, 0.6190, 0.5774, 0.7869],
[ 0.3326, 0.0530, 0.0702, 0.8114],
[ 0.7818, -0.0506, 0.4039, 0.7967]], grad_fn=<TanhBackward0>))
我们重新定义了我们的模块MyCell,但这次我们添加了一个self.linear属性,并在前向函数中调用了self.linear。
这里到底发生了什么?torch.nn.Linear是 PyTorch 标准库中的一个Module。就像MyCell一样,它可以使用调用语法来调用。我们正在构建一个Module的层次结构。
在Module上使用print将给出Module子类层次结构的可视化表示。在我们的示例中,我们可以看到我们的Linear子类及其参数。
通过这种方式组合Module,我们可以简洁而易读地编写具有可重用组件的模型。
您可能已经注意到输出中的grad_fn。这是 PyTorch 自动微分方法的一个细节,称为autograd。简而言之,这个系统允许我们通过可能复杂的程序计算导数。这种设计允许在模型编写中具有极大的灵活性。
现在让我们来看看这种灵活性:
class MyDecisionGate(torch.nn.Module):
def forward(self, x):
if x.sum() > 0:
return x
else:
return -x
class MyCell(torch.nn.Module):
def __init__(self):
super(MyCell, self).__init__()
self.dg = MyDecisionGate()
self.linear = torch.nn.Linear(4, 4)
def forward(self, x, h):
new_h = torch.tanh(self.dg(self.linear(x)) + h)
return new_h, new_h
my_cell = MyCell()
print(my_cell)
print(my_cell(x, h))
MyCell(
(dg): MyDecisionGate()
(linear): Linear(in_features=4, out_features=4, bias=True)
)
(tensor([[ 0.8346, 0.5931, 0.2097, 0.8232],
[ 0.2340, -0.1254, 0.2679, 0.8064],
[ 0.6231, 0.1494, -0.3110, 0.7865]], grad_fn=<TanhBackward0>), tensor([[ 0.8346, 0.5931, 0.2097, 0.8232],
[ 0.2340, -0.1254, 0.2679, 0.8064],
[ 0.6231, 0.1494, -0.3110, 0.7865]], grad_fn=<TanhBackward0>))
我们再次重新定义了MyCell类,但这次我们定义了MyDecisionGate。这个模块利用控制流。控制流包括循环和if语句。
许多框架采用计算符号导数的方法,给定完整程序表示。然而,在 PyTorch 中,我们使用梯度磁带。我们记录操作的发生,并在计算导数时向后重放它们。通过这种方式,框架不必为语言中的所有构造显式定义导数。

自动求导的工作原理
TorchScript 的基础知识
现在让我们拿我们正在运行的示例来看看我们如何应用 TorchScript。
简而言之,TorchScript 提供了工具来捕获您模型的定义,即使在 PyTorch 灵活和动态的特性下。让我们开始检查我们所谓的跟踪。
跟踪模块
class MyCell(torch.nn.Module):
def __init__(self):
super(MyCell, self).__init__()
self.linear = torch.nn.Linear(4, 4)
def forward(self, x, h):
new_h = torch.tanh(self.linear(x) + h)
return new_h, new_h
my_cell = MyCell()
x, h = torch.rand(3, 4), torch.rand(3, 4)
traced_cell = torch.jit.trace(my_cell, (x, h))
print(traced_cell)
traced_cell(x, h)
MyCell(
original_name=MyCell
(linear): Linear(original_name=Linear)
)
(tensor([[-0.2541, 0.2460, 0.2297, 0.1014],
[-0.2329, -0.2911, 0.5641, 0.5015],
[ 0.1688, 0.2252, 0.7251, 0.2530]], grad_fn=<TanhBackward0>), tensor([[-0.2541, 0.2460, 0.2297, 0.1014],
[-0.2329, -0.2911, 0.5641, 0.5015],
[ 0.1688, 0.2252, 0.7251, 0.2530]], grad_fn=<TanhBackward0>))
我们已经倒带了一点,拿到了我们MyCell类的第二个版本。和以前一样,我们已经实例化了它,但这次,我们调用了torch.jit.trace,传入了Module,并传入了示例输入网络可能会看到的。
这到底做了什么?它调用了Module,记录了Module运行时发生的操作,并创建了torch.jit.ScriptModule的一个实例(其中TracedModule是一个实例)
TorchScript 将其定义记录在一个中间表示(IR)中,在深度学习中通常被称为图。我们可以使用.graph属性检查图:
print(traced_cell.graph)
graph(%self.1 : __torch__.MyCell,
%x : Float(3, 4, strides=[4, 1], requires_grad=0, device=cpu),
%h : Float(3, 4, strides=[4, 1], requires_grad=0, device=cpu)):
%linear : __torch__.torch.nn.modules.linear.Linear = prim::GetAttrname="linear"
%20 : Tensor = prim::CallMethodname="forward"
%11 : int = prim::Constant[value=1]() # /var/lib/jenkins/workspace/beginner_source/Intro_to_TorchScript_tutorial.py:189:0
%12 : Float(3, 4, strides=[4, 1], requires_grad=1, device=cpu) = aten::add(%20, %h, %11) # /var/lib/jenkins/workspace/beginner_source/Intro_to_TorchScript_tutorial.py:189:0
%13 : Float(3, 4, strides=[4, 1], requires_grad=1, device=cpu) = aten::tanh(%12) # /var/lib/jenkins/workspace/beginner_source/Intro_to_TorchScript_tutorial.py:189:0
%14 : (Float(3, 4, strides=[4, 1], requires_grad=1, device=cpu), Float(3, 4, strides=[4, 1], requires_grad=1, device=cpu)) = prim::TupleConstruct(%13, %13)
return (%14)
然而,这是一个非常低级的表示,图中包含的大部分信息对最终用户来说并不有用。相反,我们可以使用.code属性来给出代码的 Python 语法解释:
print(traced_cell.code)
def forward(self,
x: Tensor,
h: Tensor) -> Tuple[Tensor, Tensor]:
linear = self.linear
_0 = torch.tanh(torch.add((linear).forward(x, ), h))
return (_0, _0)
那么为什么我们要做所有这些?有几个原因:
-
TorchScript 代码可以在其自己的解释器中调用,这基本上是一个受限制的 Python 解释器。这个解释器不会获取全局解释器锁定,因此可以同时处理同一实例上的许多请求。
-
这种格式允许我们将整个模型保存到磁盘,并加载到另一个环境中,比如在一个不是 Python 语言编写的服务器中
-
TorchScript 为我们提供了一个表示,我们可以对代码进行编译优化,以提供更高效的执行
-
TorchScript 允许我们与许多需要比单个运算符更广泛视图的后端/设备运行时进行接口。
我们可以看到调用traced_cell产生与 Python 模块相同的结果:
print(my_cell(x, h))
print(traced_cell(x, h))
(tensor([[-0.2541, 0.2460, 0.2297, 0.1014],
[-0.2329, -0.2911, 0.5641, 0.5015],
[ 0.1688, 0.2252, 0.7251, 0.2530]], grad_fn=<TanhBackward0>), tensor([[-0.2541, 0.2460, 0.2297, 0.1014],
[-0.2329, -0.2911, 0.5641, 0.5015],
[ 0.1688, 0.2252, 0.7251, 0.2530]], grad_fn=<TanhBackward0>))
(tensor([[-0.2541, 0.2460, 0.2297, 0.1014],
[-0.2329, -0.2911, 0.5641, 0.5015],
[ 0.1688, 0.2252, 0.7251, 0.2530]], grad_fn=<TanhBackward0>), tensor([[-0.2541, 0.2460, 0.2297, 0.1014],
[-0.2329, -0.2911, 0.5641, 0.5015],
[ 0.1688, 0.2252, 0.7251, 0.2530]], grad_fn=<TanhBackward0>))
使用脚本化转换模块
我们之所以使用我们模块的第二个版本,而不是带有控制流的子模块的版本,是有原因的。现在让我们来检查一下:
class MyDecisionGate(torch.nn.Module):
def forward(self, x):
if x.sum() > 0:
return x
else:
return -x
class MyCell(torch.nn.Module):
def __init__(self, dg):
super(MyCell, self).__init__()
self.dg = dg
self.linear = torch.nn.Linear(4, 4)
def forward(self, x, h):
new_h = torch.tanh(self.dg(self.linear(x)) + h)
return new_h, new_h
my_cell = MyCell(MyDecisionGate())
traced_cell = torch.jit.trace(my_cell, (x, h))
print(traced_cell.dg.code)
print(traced_cell.code)
/var/lib/jenkins/workspace/beginner_source/Intro_to_TorchScript_tutorial.py:261: TracerWarning:
Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
def forward(self,
argument_1: Tensor) -> NoneType:
return None
def forward(self,
x: Tensor,
h: Tensor) -> Tuple[Tensor, Tensor]:
dg = self.dg
linear = self.linear
_0 = (linear).forward(x, )
_1 = (dg).forward(_0, )
_2 = torch.tanh(torch.add(_0, h))
return (_2, _2)
查看.code输出,我们可以看到if-else分支不见了!为什么?跟踪确切地做了我们说过的事情:运行代码,记录发生的操作,并构建一个完全做同样操作的ScriptModule。不幸的是,像控制流这样的东西被擦除了。
我们如何在 TorchScript 中忠实地表示这个模块?我们提供了一个脚本编译器,它直接分析您的 Python 源代码,将其转换为 TorchScript。让我们使用脚本编译器转换MyDecisionGate:
scripted_gate = torch.jit.script(MyDecisionGate())
my_cell = MyCell(scripted_gate)
scripted_cell = torch.jit.script(my_cell)
print(scripted_gate.code)
print(scripted_cell.code)
def forward(self,
x: Tensor) -> Tensor:
if bool(torch.gt(torch.sum(x), 0)):
_0 = x
else:
_0 = torch.neg(x)
return _0
def forward(self,
x: Tensor,
h: Tensor) -> Tuple[Tensor, Tensor]:
dg = self.dg
linear = self.linear
_0 = torch.add((dg).forward((linear).forward(x, ), ), h)
new_h = torch.tanh(_0)
return (new_h, new_h)
万岁!我们现在已经忠实地捕获了我们程序在 TorchScript 中的行为。现在让我们尝试运行程序:
# New inputs
x, h = torch.rand(3, 4), torch.rand(3, 4)
print(scripted_cell(x, h))
(tensor([[ 0.5679, 0.5762, 0.2506, -0.0734],
[ 0.5228, 0.7122, 0.6985, -0.0656],
[ 0.6187, 0.4487, 0.7456, -0.0238]], grad_fn=<TanhBackward0>), tensor([[ 0.5679, 0.5762, 0.2506, -0.0734],
[ 0.5228, 0.7122, 0.6985, -0.0656],
[ 0.6187, 0.4487, 0.7456, -0.0238]], grad_fn=<TanhBackward0>))
混合脚本化和跟踪
有些情况需要使用跟踪而不是脚本化(例如,一个模块有许多基于常量 Python 值做出的架构决策,我们希望这些值不会出现在 TorchScript 中)。在这种情况下,脚本化可以与跟踪组合使用:torch.jit.script将内联跟踪模块的代码,而跟踪将内联脚本化模块的代码。
第一个案例的示例:
class MyRNNLoop(torch.nn.Module):
def __init__(self):
super(MyRNNLoop, self).__init__()
self.cell = torch.jit.trace(MyCell(scripted_gate), (x, h))
def forward(self, xs):
h, y = torch.zeros(3, 4), torch.zeros(3, 4)
for i in range(xs.size(0)):
y, h = self.cell(xs[i], h)
return y, h
rnn_loop = torch.jit.script(MyRNNLoop())
print(rnn_loop.code)
def forward(self,
xs: Tensor) -> Tuple[Tensor, Tensor]:
h = torch.zeros([3, 4])
y = torch.zeros([3, 4])
y0 = y
h0 = h
for i in range(torch.size(xs, 0)):
cell = self.cell
_0 = (cell).forward(torch.select(xs, 0, i), h0, )
y1, h1, = _0
y0, h0 = y1, h1
return (y0, h0)
以及第二种情况的示例:
class WrapRNN(torch.nn.Module):
def __init__(self):
super(WrapRNN, self).__init__()
self.loop = torch.jit.script(MyRNNLoop())
def forward(self, xs):
y, h = self.loop(xs)
return torch.relu(y)
traced = torch.jit.trace(WrapRNN(), (torch.rand(10, 3, 4)))
print(traced.code)
def forward(self,
xs: Tensor) -> Tensor:
loop = self.loop
_0, y, = (loop).forward(xs, )
return torch.relu(y)
这样,当情况需要时,可以同时使用脚本化和跟踪。
保存和加载模型
我们提供 API 来保存和加载 TorchScript 模块到/从磁盘的存档格式中。这种格式包括代码、参数、属性和调试信息,这意味着存档是模型的一个独立表示,可以在完全不同的进程中加载。让我们保存和加载我们包装的 RNN 模块:
traced.save('wrapped_rnn.pt')
loaded = torch.jit.load('wrapped_rnn.pt')
print(loaded)
print(loaded.code)
RecursiveScriptModule(
original_name=WrapRNN
(loop): RecursiveScriptModule(
original_name=MyRNNLoop
(cell): RecursiveScriptModule(
original_name=MyCell
(dg): RecursiveScriptModule(original_name=MyDecisionGate)
(linear): RecursiveScriptModule(original_name=Linear)
)
)
)
def forward(self,
xs: Tensor) -> Tensor:
loop = self.loop
_0, y, = (loop).forward(xs, )
return torch.relu(y)
正如您所看到的,序列化保留了模块层次结构和我们一直在检查的代码。该模型也可以被加载,例如,到 C++中以进行无 Python 执行。
进一步阅读
我们已经完成了我们的教程!要进行更深入的演示,请查看 NeurIPS 演示,了解如何使用 TorchScript 转换机器翻译模型:colab.research.google.com/drive/1HiICg6jRkBnr5hvK2-VnMi88Vi9pUzEJ
脚本的总运行时间:(0 分钟 0.244 秒)
下载 Python 源代码:Intro_to_TorchScript_tutorial.py
下载 Jupyter 笔记本:Intro_to_TorchScript_tutorial.ipynb
Sphinx-Gallery 生成的画廊
在 C++中加载 TorchScript 模型
原文:
pytorch.org/tutorials/advanced/cpp_export.html译者:飞龙
协议:CC BY-NC-SA 4.0
正如其名称所示,PyTorch 的主要接口是 Python 编程语言。虽然 Python 是许多需要动态性和迭代便利性的场景的合适和首选语言,但同样有许多情况下,Python 的这些特性并不理想。其中一个经常适用后者的环境是生产 - 低延迟和严格部署要求的领域。对于生产场景,C++往往是首选的语言,即使只是将其绑定到另一种语言如 Java、Rust 或 Go 中。以下段落将概述 PyTorch 提供的路径,从现有的 Python 模型到可以纯粹从 C++中加载和执行的序列化表示形式,而不依赖于 Python。
第 1 步:将您的 PyTorch 模型转换为 Torch Script
PyTorch 模型从 Python 到 C++的旅程是由Torch Script实现的,这是 PyTorch 模型的一种表示形式,可以被 Torch Script 编译器理解、编译和序列化。如果您从使用原始“eager”API 编写的现有 PyTorch 模型开始,您必须首先将您的模型转换为 Torch Script。在下面讨论的最常见情况下,这只需要很少的努力。如果您已经有了一个 Torch Script 模块,您可以跳过本教程的下一部分。
将 PyTorch 模型转换为 Torch Script 有两种方法。第一种被称为跟踪,通过使用示例输入对模型进行一次评估并记录这些输入通过模型的流程来捕获模型的结构。这适用于对控制流使用有限的模型。第二种方法是向您的模型添加显式注释,通知 Torch Script 编译器可以直接解析和编译您的模型代码,受 Torch Script 语言的约束。
提示
您可以在官方Torch Script 参考文档中找到这两种方法的完整文档,以及关于使用哪种方法的进一步指导。
通过跟踪转换为 Torch Script
要通过跟踪将 PyTorch 模型转换为 Torch Script,必须将模型实例和示例输入传递给torch.jit.trace函数。这将生成一个带有模型评估跟踪的torch.jit.ScriptModule对象,嵌入在模块的forward方法中:
import torch
import torchvision
# An instance of your model.
model = torchvision.models.resnet18()
# An example input you would normally provide to your model's forward() method.
example = torch.rand(1, 3, 224, 224)
# Use torch.jit.trace to generate a torch.jit.ScriptModule via tracing.
traced_script_module = torch.jit.trace(model, example)
跟踪的ScriptModule现在可以像常规 PyTorch 模块一样进行评估:
In[1]: output = traced_script_module(torch.ones(1, 3, 224, 224))
In[2]: output[0, :5]
Out[2]: tensor([-0.2698, -0.0381, 0.4023, -0.3010, -0.0448], grad_fn=<SliceBackward>)
通过注释转换为 Torch Script
在某些情况下,例如如果您的模型使用特定形式的控制流,您可能希望直接在 Torch Script 中编写您的模型并相应地注释您的模型。例如,假设您有以下基本的 Pytorch 模型:
import torch
class MyModule(torch.nn.Module):
def __init__(self, N, M):
super(MyModule, self).__init__()
self.weight = torch.nn.Parameter(torch.rand(N, M))
def forward(self, input):
if input.sum() > 0:
output = self.weight.mv(input)
else:
output = self.weight + input
return output
由于此模块的forward方法使用依赖于输入的控制流,因此不适合跟踪。相反,我们可以将其转换为ScriptModule。为了将模块转换为ScriptModule,需要使用torch.jit.script编译模块,如下所示:
class MyModule(torch.nn.Module):
def __init__(self, N, M):
super(MyModule, self).__init__()
self.weight = torch.nn.Parameter(torch.rand(N, M))
def forward(self, input):
if input.sum() > 0:
output = self.weight.mv(input)
else:
output = self.weight + input
return output
my_module = MyModule(10,20)
sm = torch.jit.script(my_module)
如果您需要排除nn.Module中的某些方法,因为它们使用 TorchScript 尚不支持的 Python 特性,您可以使用@torch.jit.ignore对其进行注释。
sm是一个准备好进行序列化的ScriptModule实例。
第 2 步:将您的脚本模块序列化到文件
一旦您手头有一个ScriptModule,无论是通过跟踪还是注释 PyTorch 模型获得的,您就可以将其序列化到文件中。稍后,您将能够在 C++中从此文件加载模块并执行它,而无需依赖 Python。假设我们想要序列化前面在跟踪示例中显示的ResNet18模型。要执行此序列化,只需在模块上调用save并传递一个文件名:
traced_script_module.save("traced_resnet_model.pt")
这将在您的工作目录中生成一个traced_resnet_model.pt文件。如果您还想序列化sm,请调用sm.save("my_module_model.pt")。我们现在正式离开了 Python 领域,准备进入 C++领域。
第 3 步:在 C++中加载您的脚本模块
在 C++中加载您序列化的 PyTorch 模型,您的应用程序必须依赖于 PyTorch C++ API - 也称为LibTorch。LibTorch 分发包括一组共享库、头文件和 CMake 构建配置文件。虽然 CMake 不是依赖于 LibTorch 的必需条件,但它是推荐的方法,并且将在未来得到很好的支持。在本教程中,我们将构建一个最小的 C++应用程序,使用 CMake 和 LibTorch 简单地加载和执行一个序列化的 PyTorch 模型。
一个最小的 C++应用程序
让我们从讨论加载模块的代码开始。以下内容已经足够:
#include <torch/script.h> // One-stop header.
#include <iostream>
#include <memory>
int main(int argc, const char* argv[]) {
if (argc != 2) {
std::cerr << "usage: example-app <path-to-exported-script-module>\n";
return -1;
}
torch::jit::script::Module module;
try {
// Deserialize the ScriptModule from a file using torch::jit::load().
module = torch::jit::load(argv[1]);
}
catch (const c10::Error& e) {
std::cerr << "error loading the model\n";
return -1;
}
std::cout << "ok\n";
}
<torch/script.h>头文件包含了 LibTorch 库中运行示例所需的所有相关包含。我们的应用程序接受一个序列化的 PyTorch ScriptModule的文件路径作为唯一的命令行参数,然后使用torch::jit::load()函数对模块进行反序列化,该函数以此文件路径作为输入。作为返回,我们收到一个torch::jit::script::Module对象。我们将在稍后看看如何执行它。
依赖于 LibTorch 并构建应用程序
假设我们将上面的代码存储到一个名为example-app.cpp的文件中。一个用于构建它的最小CMakeLists.txt可能看起来就像这样简单:
cmake_minimum_required(VERSION 3.0 FATAL_ERROR)
project(custom_ops)
find_package(Torch REQUIRED)
add_executable(example-app example-app.cpp)
target_link_libraries(example-app "${TORCH_LIBRARIES}")
set_property(TARGET example-app PROPERTY CXX_STANDARD 14)
构建示例应用程序所需的最后一件事是 LibTorch 分发。您可以随时从 PyTorch 网站的下载页面上获取最新的稳定版本。如果下载并解压最新的存档,您应该会收到一个具有以下目录结构的文件夹:
libtorch/
bin/
include/
lib/
share/
-
lib/文件夹包含了您必须链接的共享库, -
include/文件夹包含了您的程序需要包含的头文件, -
share/文件夹包含了必要的 CMake 配置,以启用上面简单的find_package(Torch)命令。
提示
在 Windows 上,调试版本和发布版本不兼容。如果您计划在调试模式下构建项目,请尝试使用 LibTorch 的调试版本。此外,请确保在下面的cmake --build .行中指定正确的配置。
最后一步是构建应用程序。为此,假设我们的示例目录布局如下:
example-app/
CMakeLists.txt
example-app.cpp
我们现在可以运行以下命令来从example-app/文件夹中构建应用程序:
mkdir build
cd build
cmake -DCMAKE_PREFIX_PATH=/path/to/libtorch ..
cmake --build . --config Release
其中/path/to/libtorch应该是解压后的 LibTorch 分发的完整路径。如果一切顺利,它应该看起来像这样:
root@4b5a67132e81:/example-app# mkdir build
root@4b5a67132e81:/example-app# cd build
root@4b5a67132e81:/example-app/build# cmake -DCMAKE_PREFIX_PATH=/path/to/libtorch ..
-- The C compiler identification is GNU 5.4.0
-- The CXX compiler identification is GNU 5.4.0
-- Check for working C compiler: /usr/bin/cc
-- Check for working C compiler: /usr/bin/cc -- works
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Detecting C compile features
-- Detecting C compile features - done
-- Check for working CXX compiler: /usr/bin/c++
-- Check for working CXX compiler: /usr/bin/c++ -- works
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Looking for pthread.h
-- Looking for pthread.h - found
-- Looking for pthread_create
-- Looking for pthread_create - not found
-- Looking for pthread_create in pthreads
-- Looking for pthread_create in pthreads - not found
-- Looking for pthread_create in pthread
-- Looking for pthread_create in pthread - found
-- Found Threads: TRUE
-- Configuring done
-- Generating done
-- Build files have been written to: /example-app/build
root@4b5a67132e81:/example-app/build# make
Scanning dependencies of target example-app
[ 50%] Building CXX object CMakeFiles/example-app.dir/example-app.cpp.o
[100%] Linking CXX executable example-app
[100%] Built target example-app
如果我们将之前创建的跟踪的ResNet18模型traced_resnet_model.pt的路径提供给生成的example-app二进制文件,我们应该会得到一个友好的“ok”。请注意,如果尝试使用my_module_model.pt运行此示例,您将收到一个错误,指出您的输入形状不兼容。my_module_model.pt期望的是 1D 而不是 4D。
root@4b5a67132e81:/example-app/build# ./example-app <path_to_model>/traced_resnet_model.pt
ok
第 4 步:在 C++中执行脚本模块
在 C++中成功加载我们序列化的ResNet18之后,我们现在只需再加入几行代码就可以执行它了!让我们将这些行添加到我们的 C++应用程序的main()函数中:
// Create a vector of inputs.
std::vector<torch::jit::IValue> inputs;
inputs.push_back(torch::ones({1, 3, 224, 224}));
// Execute the model and turn its output into a tensor.
at::Tensor output = module.forward(inputs).toTensor();
std::cout << output.slice(/*dim=*/1, /*start=*/0, /*end=*/5) << '\n';
前两行设置了我们模型的输入。我们创建了一个torch::jit::IValue向量(一种类型擦除的值类型,script::Module方法接受和返回),并添加了一个单一的输入。为了创建输入张量,我们使用torch::ones(),相当于 C++ API 中的torch.ones。然后我们运行script::Module的forward方法,将我们创建的输入向量传递给它。作为返回,我们得到一个新的IValue,通过调用toTensor()将其转换为张量。
提示
要了解更多关于torch::ones等函数和 PyTorch C++ API 的信息,请参考其文档:pytorch.org/cppdocs。PyTorch C++ API 几乎与 Python API 具有相同的功能,允许你像在 Python 中一样进一步操作和处理张量。
在最后一行,我们打印输出的前五个条目。由于我们在本教程中之前在 Python 中向模型提供了相同的输入,我们应该理想情况下看到相同的输出。让我们尝试重新编译我们的应用程序,并使用相同的序列化模型运行它:
root@4b5a67132e81:/example-app/build# make
Scanning dependencies of target example-app
[ 50%] Building CXX object CMakeFiles/example-app.dir/example-app.cpp.o
[100%] Linking CXX executable example-app
[100%] Built target example-app
root@4b5a67132e81:/example-app/build# ./example-app traced_resnet_model.pt
-0.2698 -0.0381 0.4023 -0.3010 -0.0448
[ Variable[CPUFloatType]{1,5} ]
作为参考,之前在 Python 中的输出是:
tensor([-0.2698, -0.0381, 0.4023, -0.3010, -0.0448], grad_fn=<SliceBackward>)
看起来很匹配!
提示
要将模型移动到 GPU 内存,你可以写model.to(at::kCUDA);。确保模型的输入也在 CUDA 内存中,通过调用tensor.to(at::kCUDA),这将返回一个在 CUDA 内存中的新张量。
第五步:获取帮助和探索 API
这个教程希望能让你对 PyTorch 模型从 Python 到 C++的路径有一个基本的理解。有了这个教程中描述的概念,你应该能够从一个普通的“eager” PyTorch 模型,转换为 Python 中编译的ScriptModule,再到磁盘上的序列化文件,最后到 C++中可执行的script::Module。
当然,还有许多概念我们没有涉及。例如,你可能会发现自己想要在 C++或 CUDA 中实现自定义运算符来扩展你的ScriptModule,并在纯 C++生产环境中加载这个自定义运算符并在你的ScriptModule中执行。好消息是:这是可能的,并且得到了很好的支持!目前,你可以在这里探索示例,我们将很快推出教程。在此期间,以下链接可能会有所帮助:
-
Torch Script 参考:
pytorch.org/docs/master/jit.html -
PyTorch C++ API 文档:
pytorch.org/cppdocs/ -
PyTorch Python API 文档:
pytorch.org/docs/
如果遇到任何问题或有疑问,你可以使用我们的论坛或GitHub 问题来联系我们。
(可选)将模型从 PyTorch 导出到 ONNX 并使用 ONNX Runtime 运行
原文:
pytorch.org/tutorials/advanced/super_resolution_with_onnxruntime.html译者:飞龙
协议:CC BY-NC-SA 4.0
注意
点击这里下载完整示例代码。
注意
截至 PyTorch 2.1,ONNX Exporter 有两个版本。
-
``torch.onnx.dynamo_export`是基于 TorchDynamo 技术发布的最新(仍处于测试阶段)导出器,随 PyTorch 2.0 发布。
-
torch.onnx.export基于 TorchScript 后端,自 PyTorch 1.2.0 以来一直可用。
在本教程中,我们描述了如何使用 TorchScript ``torch.onnx.export` ONNX 导出器将在 PyTorch 中定义的模型转换为 ONNX 格式。
导出的模型将使用 ONNX Runtime 执行。ONNX Runtime 是一个专注于性能的引擎,用于有效地推断跨多个平台和硬件(Windows、Linux 和 Mac 以及 CPU 和 GPU)的 ONNX 模型。ONNX Runtime 已被证明在多个模型上显著提高性能,如此处所述。
在本教程中,您需要安装ONNX和ONNX Runtime。您可以通过以下方式获取 ONNX 和 ONNX Runtime 的二进制构建。
%%bash
pip install onnx onnxruntime
ONNX Runtime 建议使用最新的稳定运行时环境来运行 PyTorch。
# Some standard imports
import numpy as np
from torch import nn
import torch.utils.model_zoo as model_zoo
import torch.onnx
超分辨率是一种增加图像、视频分辨率的方法,在图像处理或视频编辑中被广泛使用。在本教程中,我们将使用一个小型的超分辨率模型。
首先,在 PyTorch 中创建一个SuperResolution模型。该模型使用了在“使用高效子像素卷积神经网络实现实时单图像和视频超分辨率” - Shi 等人中描述的高效子像素卷积层,通过一个放大因子增加图像的分辨率。该模型期望图像的YCbCr的 Y 分量作为输入,并输出超分辨率中的放大 Y 分量。
该模型直接来自 PyTorch 的示例,没有修改:
# Super Resolution model definition in PyTorch
import torch.nn as nn
import torch.nn.init as init
class SuperResolutionNet(nn.Module):
def __init__(self, upscale_factor, inplace=False):
super(SuperResolutionNet, self).__init__()
self.relu = nn.ReLU(inplace=inplace)
self.conv1 = nn.Conv2d(1, 64, (5, 5), (1, 1), (2, 2))
self.conv2 = nn.Conv2d(64, 64, (3, 3), (1, 1), (1, 1))
self.conv3 = nn.Conv2d(64, 32, (3, 3), (1, 1), (1, 1))
self.conv4 = nn.Conv2d(32, upscale_factor ** 2, (3, 3), (1, 1), (1, 1))
self.pixel_shuffle = nn.PixelShuffle(upscale_factor)
self._initialize_weights()
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
x = self.relu(self.conv3(x))
x = self.pixel_shuffle(self.conv4(x))
return x
def _initialize_weights(self):
init.orthogonal_(self.conv1.weight, init.calculate_gain('relu'))
init.orthogonal_(self.conv2.weight, init.calculate_gain('relu'))
init.orthogonal_(self.conv3.weight, init.calculate_gain('relu'))
init.orthogonal_(self.conv4.weight)
# Create the super-resolution model by using the above model definition.
torch_model = SuperResolutionNet(upscale_factor=3)
通常情况下,您现在会训练这个模型;但是,在本教程中,我们将下载一些预训练权重。请注意,这个模型并没有完全训练以获得良好的准确性,仅用于演示目的。
在导出模型之前,重要的是调用torch_model.eval()或torch_model.train(False),将模型转换为推断模式。这是必需的,因为像 dropout 或 batchnorm 这样的操作符在推断和训练模式下的行为是不同的。
# Load pretrained model weights
model_url = 'https://s3.amazonaws.com/pytorch/test_data/export/superres_epoch100-44c6958e.pth'
batch_size = 1 # just a random number
# Initialize model with the pretrained weights
map_location = lambda storage, loc: storage
if torch.cuda.is_available():
map_location = None
torch_model.load_state_dict(model_zoo.load_url(model_url, map_location=map_location))
# set the model to inference mode
torch_model.eval()
在 PyTorch 中导出模型可以通过跟踪或脚本化来实现。本教程将使用一个通过跟踪导出的模型作为示例。要导出一个模型,我们调用torch.onnx.export()函数。这将执行模型,记录计算输出所使用的操作符的跟踪。因为export运行模型,我们需要提供一个输入张量x。这个张量中的值可以是随机的,只要它是正确的类型和大小。请注意,在导出的 ONNX 图中,所有输入的维度的大小将被固定,除非指定为动态轴。在这个示例中,我们导出具有批大小 1 的模型,但然后在torch.onnx.export()的dynamic_axes参数中将第一个维度指定为动态。因此,导出的模型将接受大小为[batch_size, 1, 224, 224]的输入,其中 batch_size 可以是可变的。
要了解更多关于 PyTorch 导出接口的细节,请查看torch.onnx 文档。
# Input to the model
x = torch.randn(batch_size, 1, 224, 224, requires_grad=True)
torch_out = torch_model(x)
# Export the model
torch.onnx.export(torch_model, # model being run
x, # model input (or a tuple for multiple inputs)
"super_resolution.onnx", # where to save the model (can be a file or file-like object)
export_params=True, # store the trained parameter weights inside the model file
opset_version=10, # the ONNX version to export the model to
do_constant_folding=True, # whether to execute constant folding for optimization
input_names = ['input'], # the model's input names
output_names = ['output'], # the model's output names
dynamic_axes={'input' : {0 : 'batch_size'}, # variable length axes
'output' : {0 : 'batch_size'}})
我们还计算了torch_out,模型输出之后的结果,我们将使用它来验证我们导出的模型在 ONNX Runtime 中运行时是否计算出相同的值。
但在使用 ONNX Runtime 验证模型输出之前,我们将使用 ONNX API 检查 ONNX 模型。首先,onnx.load("super_resolution.onnx")将加载保存的模型,并输出一个onnx.ModelProto结构(用于捆绑 ML 模型的顶层文件/容器格式。更多信息请参阅onnx.proto 文档)。然后,onnx.checker.check_model(onnx_model)将验证模型的结构,并确认模型具有有效的模式。通过检查模型的版本、图的结构以及节点及其输入和输出来验证 ONNX 图的有效性。
import onnx
onnx_model = onnx.load("super_resolution.onnx")
onnx.checker.check_model(onnx_model)
现在让我们使用 ONNX Runtime 的 Python API 计算输出。这部分通常可以在单独的进程或另一台机器上完成,但我们将继续在同一进程中进行,以便验证 ONNX Runtime 和 PyTorch 为网络计算相同的值。
为了使用 ONNX Runtime 运行模型,我们需要为模型创建一个推理会话,并选择配置参数(这里我们使用默认配置)。会话创建后,我们使用 run() API 评估模型。此调用的输出是一个包含 ONNX Runtime 计算的模型输出的列表。
import onnxruntime
ort_session = onnxruntime.InferenceSession("super_resolution.onnx", providers=["CPUExecutionProvider"])
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
# compute ONNX Runtime output prediction
ort_inputs = {ort_session.get_inputs()[0].name: to_numpy(x)}
ort_outs = ort_session.run(None, ort_inputs)
# compare ONNX Runtime and PyTorch results
np.testing.assert_allclose(to_numpy(torch_out), ort_outs[0], rtol=1e-03, atol=1e-05)
print("Exported model has been tested with ONNXRuntime, and the result looks good!")
我们应该看到 PyTorch 和 ONNX Runtime 的输出在给定精度(rtol=1e-03和atol=1e-05)下数值匹配。值得一提的是,如果它们不匹配,则 ONNX 导出器存在问题,请在这种情况下与我们联系。
在 ONNX Runtime 上运行图像模型
到目前为止,我们已经从 PyTorch 导出了一个模型,并展示了如何加载它并在 ONNX Runtime 中使用一个虚拟张量作为输入来运行它。
在本教程中,我们将使用广泛使用的一张著名的猫图像,如下所示

首先,让我们加载图像,使用标准的 PIL Python 库对其进行预处理。请注意,这种预处理是训练/测试神经网络数据的标准做法。
我们首先将图像调整大小以适应模型的输入大小(224x224)。然后我们将图像分割为其 Y、Cb 和 Cr 组件。这些组件代表灰度图像(Y)以及蓝差(Cb)和红差(Cr)色度分量。Y 分量对人眼更敏感,我们对这个分量感兴趣,我们将对其进行转换。提取 Y 分量后,我们将其转换为一个张量,这将是我们模型的输入。
from PIL import Image
import torchvision.transforms as transforms
img = Image.open("./_static/https://gitcode.net/OpenDocCN/pytorch-doc-zh/-/raw/master/docs/2.2/img/cat.jpg")
resize = transforms.Resize([224, 224])
img = resize(img)
img_ycbcr = img.convert('YCbCr')
img_y, img_cb, img_cr = img_ycbcr.split()
to_tensor = transforms.ToTensor()
img_y = to_tensor(img_y)
img_y.unsqueeze_(0)
现在,作为下一步,让我们取代表灰度调整后的猫图像的张量,并像之前解释的那样在 ONNX Runtime 中运行超分辨率模型。
ort_inputs = {ort_session.get_inputs()[0].name: to_numpy(img_y)}
ort_outs = ort_session.run(None, ort_inputs)
img_out_y = ort_outs[0]
此时,模型的输出是一个张量。现在,我们将处理模型的输出,从输出张量中构建最终的输出图像,并保存图像。后处理步骤是从 PyTorch 超分辨率模型的实现中采用的这里。
img_out_y = Image.fromarray(np.uint8((img_out_y[0] * 255.0).clip(0, 255)[0]), mode='L')
# get the output image follow post-processing step from PyTorch implementation
final_img = Image.merge(
"YCbCr", [
img_out_y,
img_cb.resize(img_out_y.size, Image.BICUBIC),
img_cr.resize(img_out_y.size, Image.BICUBIC),
]).convert("RGB")
# Save the image, we will compare this with the output image from mobile device
final_img.save("./_static/https://gitcode.net/OpenDocCN/pytorch-doc-zh/-/raw/master/docs/2.2/img/cat_superres_with_ort.jpg")

ONNX Runtime 是一个跨平台引擎,可以在多个平台上以及 CPU 和 GPU 上运行。
ONNX Runtime 也可以部署到云端,用于使用 Azure 机器学习服务进行模型推断。更多信息在这里。
关于 ONNX Runtime 性能的更多信息在这里。
关于 ONNX Runtime 的更多信息在这里。
脚本的总运行时间: (0 分钟 0.000 秒)
下载 Python 源代码:super_resolution_with_onnxruntime.py
下载 Jupyter 笔记本:super_resolution_with_onnxruntime.ipynb
Sphinx-Gallery 生成的图库
树莓派 4 上的实时推理(30 fps!)
原文:
pytorch.org/tutorials/intermediate/realtime_rpi.html译者:飞龙
协议:CC BY-NC-SA 4.0
作者:Tristan Rice
PyTorch 对树莓派 4 有开箱即用的支持。本教程将指导您如何为运行 PyTorch 的树莓派 4 设置树莓派 4,并在 CPU 上实时运行 MobileNet v2 分类模型(30 fps+)。
这一切都是在树莓派 4 型 B 4GB 上测试的,但也应该适用于 2GB 变体以及性能降低的 3B。

先决条件
要按照本教程进行操作,您需要一个树莓派 4,一个相机以及所有其他标准配件。
-
树莓派 4 型 B 2GB+
-
树莓派摄像头模块
-
散热片和风扇(可选但建议)
-
5V 3A USB-C 电源适配器
-
SD 卡(至少 8GB)
-
SD 卡读/写器
树莓派 4 设置
PyTorch 仅为 Arm 64 位(aarch64)提供 pip 软件包,因此您需要在树莓派上安装 64 位版本的操作系统
您可以从downloads.raspberrypi.org/raspios_arm64/images/下载最新的 arm64 树莓派 OS,并通过 rpi-imager 安装它。
32 位树莓派 OS 将无法工作。

安装将至少需要几分钟,具体取决于您的互联网速度和 sd 卡速度。完成后,应如下所示:
现在是时候将您的 sd 卡放入树莓派中,连接摄像头并启动它。
一旦启动并完成初始设置,您需要编辑/boot/config.txt文件以启用摄像头。
# This enables the extended features such as the camera.
start_x=1
# This needs to be at least 128M for the camera processing, if it's bigger you can just leave it as is.
gpu_mem=128
# You need to commment/remove the existing camera_auto_detect line since this causes issues with OpenCV/V4L2 capture.
#camera_auto_detect=1
然后重新启动。重新启动后,video4linux2 设备/dev/video0应该存在。
安装 PyTorch 和 OpenCV
PyTorch 和我们需要的所有其他库都有 ARM 64 位/aarch64 变体,因此您可以通过 pip 安装它们,并使其像任何其他 Linux 系统一样工作。
$ pip install torch torchvision torchaudio
$ pip install opencv-python
$ pip install numpy --upgrade
我们现在可以检查所有安装是否正确:
$ python -c "import torch; print(torch.__version__)"
视频捕获
对于视频捕获,我们将使用 OpenCV 来流式传输视频帧,而不是更常见的picamera。 picamera 在 64 位树莓派 OS 上不可用,而且比 OpenCV 慢得多。 OpenCV 直接访问/dev/video0设备以抓取帧。
我们正在使用的模型(MobileNetV2)接受224x224的图像尺寸,因此我们可以直接从 OpenCV 请求 36fps。我们的目标是模型的 30fps,但我们请求的帧率略高于此,以确保始终有足够的帧。
import cv2
from PIL import Image
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 224)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 224)
cap.set(cv2.CAP_PROP_FPS, 36)
OpenCV 以 BGR 返回一个numpy数组,因此我们需要读取并进行一些调整,以使其符合预期的 RGB 格式。
ret, image = cap.read()
# convert opencv output from BGR to RGB
image = image[:, :, [2, 1, 0]]
这个数据读取和处理大约需要3.5 毫秒。
图像预处理
我们需要获取帧并将其转换为模型期望的格式。这与您在任何具有标准 torchvision 转换的机器上执行的处理相同。
from torchvision import transforms
preprocess = transforms.Compose([
# convert the frame to a CHW torch tensor for training
transforms.ToTensor(),
# normalize the colors to the range that mobilenet_v2/3 expect
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(image)
# The model can handle multiple images simultaneously so we need to add an
# empty dimension for the batch.
# [3, 224, 224] -> [1, 3, 224, 224]
input_batch = input_tensor.unsqueeze(0)
模型选择
您可以选择多种模型,具有不同的性能特征。并非所有模型都提供qnnpack预训练变体,因此为了测试目的,您应该选择一个提供此功能的模型,但如果您训练和量化自己的模型,可以使用其中任何一个。
我们在本教程中使用mobilenet_v2,因为它具有良好的性能和准确性。
树莓派 4 基准测试结果:
| 模型 | FPS | 总时间(毫秒/帧) | 模型时间(毫秒/帧) | qnnpack 预训练 |
|---|---|---|---|---|
| mobilenet_v2 | 33.7 | 29.7 | 26.4 | True |
| mobilenet_v3_large | 29.3 | 34.1 | 30.7 | True |
| resnet18 | 9.2 | 109.0 | 100.3 | False |
| resnet50 | 4.3 | 233.9 | 225.2 | False |
| resnext101_32x8d | 1.1 | 892.5 | 885.3 | False |
| inception_v3 | 4.9 | 204.1 | 195.5 | False |
| googlenet | 7.4 | 135.3 | 132.0 | False |
| shufflenet_v2_x0_5 | 46.7 | 21.4 | 18.2 | False |
| shufflenet_v2_x1_0 | 24.4 | 41.0 | 37.7 | False |
| shufflenet_v2_x1_5 | 16.8 | 59.6 | 56.3 | False |
| shufflenet_v2_x2_0 | 11.6 | 86.3 | 82.7 | False |
MobileNetV2:量化和 JIT
为了获得最佳性能,我们希望使用量化和融合的模型。量化意味着使用 int8 进行计算,这比标准的 float32 数学更高效。融合意味着连续的操作已经被合并成更高效的版本,可能会合并像激活函数(ReLU)这样的操作到推断期间的前一层(Conv2d)中。
pytorch 的 aarch64 版本需要使用qnnpack引擎。
import torch
torch.backends.quantized.engine = 'qnnpack'
在这个示例中,我们将使用 torchvision 提供的预量化和融合版本的 MobileNetV2。
from torchvision import models
net = models.quantization.mobilenet_v2(pretrained=True, quantize=True)
然后,我们希望对模型进行 jit 以减少 Python 开销并融合任何操作。jit 使我们的帧率达到了约 30fps,而没有 jit 时只有约 20fps。
net = torch.jit.script(net)
将其放在一起
现在我们可以将所有部分组合在一起并运行它:
import time
import torch
import numpy as np
from torchvision import models, transforms
import cv2
from PIL import Image
torch.backends.quantized.engine = 'qnnpack'
cap = cv2.VideoCapture(0, cv2.CAP_V4L2)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 224)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 224)
cap.set(cv2.CAP_PROP_FPS, 36)
preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
net = models.quantization.mobilenet_v2(pretrained=True, quantize=True)
# jit model to take it from ~20fps to ~30fps
net = torch.jit.script(net)
started = time.time()
last_logged = time.time()
frame_count = 0
with torch.no_grad():
while True:
# read frame
ret, image = cap.read()
if not ret:
raise RuntimeError("failed to read frame")
# convert opencv output from BGR to RGB
image = image[:, :, [2, 1, 0]]
permuted = image
# preprocess
input_tensor = preprocess(image)
# create a mini-batch as expected by the model
input_batch = input_tensor.unsqueeze(0)
# run model
output = net(input_batch)
# do something with output ...
# log model performance
frame_count += 1
now = time.time()
if now - last_logged > 1:
print(f"{frame_count / (now-last_logged)} fps")
last_logged = now
frame_count = 0
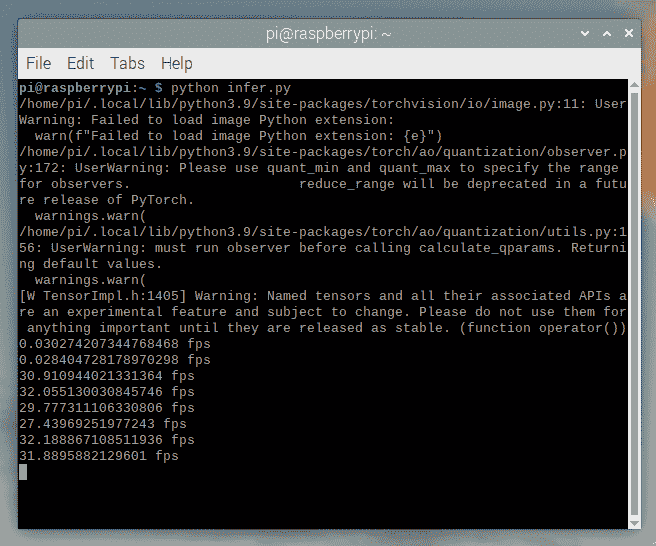
运行后,我们发现帧率约为 30fps。
这是在 Raspberry Pi OS 中的所有默认设置下。如果您禁用了默认启用的 UI 和所有其他后台服务,性能和稳定性会更好。
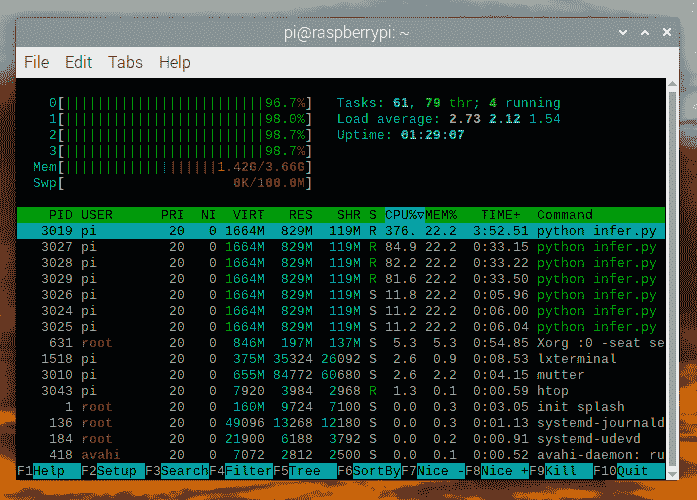
如果我们检查htop,我们会看到几乎 100%的利用率。
为了验证它是否正常工作,我们可以计算类别的概率并使用 ImageNet 类标签来打印检测结果。
top = list(enumerate(output[0].softmax(dim=0)))
top.sort(key=lambda x: x[1], reverse=True)
for idx, val in top[:10]:
print(f"{val.item()*100:.2f}% {classes[idx]}")
mobilenet_v3_large实时运行:
检测一个橙色物体:

检测一个杯子:

故障排除:性能
PyTorch 默认会使用所有可用的核心。如果您的树莓派上有任何后台运行的东西,可能会导致模型推断时出现延迟峰值。为了缓解这个问题,您可以减少线程数,这将减少峰值延迟,但会有一点性能损失。
torch.set_num_threads(2)
对于shufflenet_v2_x1_5,使用2 个线程而不是4 个线程会将最佳情况下的延迟增加到72 毫秒,而不是60 毫秒,但会消除128 毫秒的延迟峰值。
下一步
您可以创建自己的模型或微调现有模型。如果您在torchvision.models.quantized中的一个模型上进行微调,大部分融合和量化的工作已经为您完成,因此您可以直接在树莓派上部署并获得良好的性能。
查看更多:
-
量化获取有关如何量化和融合您的模型的更多信息。
-
迁移学习教程介绍如何使用迁移学习来微调预先存在的模型以适应您的数据集。
PyTorch 性能分析
分析您的 PyTorch 模块
原文:
pytorch.org/tutorials/beginner/profiler.html译者:飞龙
协议:CC BY-NC-SA 4.0
注意
点击这里下载完整示例代码
作者:Suraj Subramanian
PyTorch 包含一个分析器 API,可用于识别代码中各种 PyTorch 操作的时间和内存成本。分析器可以轻松集成到您的代码中,并且结果可以打印为表格或返回为 JSON 跟踪文件。
注意
分析器支持多线程模型。分析器在与操作相同的线程中运行,但也会分析可能在另一个线程中运行的子操作符。同时运行的分析器将被限定在自己的线程中,以防止结果混合。
注意
PyTorch 1.8 引入了新的 API,将在未来版本中取代旧的分析器 API。请查看新 API 页面:此处。
前往此处的教程快速了解分析器 API 的使用。
import torch
import numpy as np
from torch import nn
import torch.autograd.profiler as profiler
使用分析器进行性能调试
分析器可用于识别模型中的性能瓶颈。在此示例中,我们构建了一个执行两个子任务的自定义模块:
-
对输入进行线性变换,并
-
使用转换结果在掩码张量上获取索引。
我们使用profiler.record_function("label")将每个子任务的代码包装在单独的带标签的上下文管理器中。在分析器输出中,子任务中所有操作的聚合性能指标将显示在相应的标签下。
请注意,使用分析器会产生一些开销,最好仅用于调查代码。如果您正在进行运行时间基准测试,请记得将其删除。
class MyModule(nn.Module):
def __init__(self, in_features: int, out_features: int, bias: bool = True):
super(MyModule, self).__init__()
self.linear = nn.Linear(in_features, out_features, bias)
def forward(self, input, mask):
with profiler.record_function("LINEAR PASS"):
out = self.linear(input)
with profiler.record_function("MASK INDICES"):
threshold = out.sum(axis=1).mean().item()
hi_idx = np.argwhere(mask.cpu().numpy() > threshold)
hi_idx = torch.from_numpy(hi_idx).cuda()
return out, hi_idx
分析前向传递
我们初始化随机输入和掩码张量,以及模型。
在运行分析器之前,我们先热身 CUDA 以确保准确的性能基准测试。我们将模块的前向传递包装在profiler.profile上下文管理器中。with_stack=True参数会在跟踪中附加操作的文件和行号。
警告
with_stack=True会产生额外的开销,更适合用于调查代码。如果您正在进行性能基准测试,请记得将其删除。
model = MyModule(500, 10).cuda()
input = torch.rand(128, 500).cuda()
mask = torch.rand((500, 500, 500), dtype=torch.double).cuda()
# warm-up
model(input, mask)
with profiler.profile(with_stack=True, profile_memory=True) as prof:
out, idx = model(input, mask)
打印分析器结果
最后,我们打印分析器结果。profiler.key_averages按运算符名称聚合结果,并可选择按输入形状和/或堆栈跟踪事件进行分组。按输入形状分组有助于识别模型使用的张量形状。
在这里,我们使用group_by_stack_n=5,它按操作及其回溯(截断为最近的 5 个事件)对运行时间进行聚合,并按其注册顺序显示事件。表格也可以通过传递sort_by参数进行排序(请参考文档以获取有效的排序键)。
注意
在笔记本中运行分析器时,您可能会看到类似<ipython-input-18-193a910735e8>(13): forward的条目,而不是堆栈跟踪中的文件名。这些对应于<notebook-cell>(行号): 调用函数。
print(prof.key_averages(group_by_stack_n=5).table(sort_by='self_cpu_time_total', row_limit=5))
"""
(Some columns are omitted)
------------- ------------ ------------ ------------ ---------------------------------
Name Self CPU % Self CPU Self CPU Mem Source Location
------------- ------------ ------------ ------------ ---------------------------------
MASK INDICES 87.88% 5.212s -953.67 Mb /mnt/xarfuse/.../torch/au
<ipython-input-...>(10): forward
/mnt/xarfuse/.../torch/nn
<ipython-input-...>(9): <module>
/mnt/xarfuse/.../IPython/
aten::copy_ 12.07% 715.848ms 0 b <ipython-input-...>(12): forward
/mnt/xarfuse/.../torch/nn
<ipython-input-...>(9): <module>
/mnt/xarfuse/.../IPython/
/mnt/xarfuse/.../IPython/
LINEAR PASS 0.01% 350.151us -20 b /mnt/xarfuse/.../torch/au
<ipython-input-...>(7): forward
/mnt/xarfuse/.../torch/nn
<ipython-input-...>(9): <module>
/mnt/xarfuse/.../IPython/
aten::addmm 0.00% 293.342us 0 b /mnt/xarfuse/.../torch/nn
/mnt/xarfuse/.../torch/nn
/mnt/xarfuse/.../torch/nn
<ipython-input-...>(8): forward
/mnt/xarfuse/.../torch/nn
aten::mean 0.00% 235.095us 0 b <ipython-input-...>(11): forward
/mnt/xarfuse/.../torch/nn
<ipython-input-...>(9): <module>
/mnt/xarfuse/.../IPython/
/mnt/xarfuse/.../IPython/
----------------------------- ------------ ---------- ----------------------------------
Self CPU time total: 5.931s
"""
提高内存性能
请注意,从内存和时间方面来看,最昂贵的操作是forward (10),代表 MASK INDICES 内的操作。让我们先尝试解决内存消耗问题。我们可以看到第 12 行的.to()操作消耗了 953.67 Mb。此操作将mask复制到 CPU。mask是用torch.double数据类型初始化的。我们是否可以通过将其转换为torch.float来减少内存占用?
model = MyModule(500, 10).cuda()
input = torch.rand(128, 500).cuda()
mask = torch.rand((500, 500, 500), dtype=torch.float).cuda()
# warm-up
model(input, mask)
with profiler.profile(with_stack=True, profile_memory=True) as prof:
out, idx = model(input, mask)
print(prof.key_averages(group_by_stack_n=5).table(sort_by='self_cpu_time_total', row_limit=5))
"""
(Some columns are omitted)
----------------- ------------ ------------ ------------ --------------------------------
Name Self CPU % Self CPU Self CPU Mem Source Location
----------------- ------------ ------------ ------------ --------------------------------
MASK INDICES 93.61% 5.006s -476.84 Mb /mnt/xarfuse/.../torch/au
<ipython-input-...>(10): forward
/mnt/xarfuse/ /torch/nn
<ipython-input-...>(9): <module>
/mnt/xarfuse/.../IPython/
aten::copy_ 6.34% 338.759ms 0 b <ipython-input-...>(12): forward
/mnt/xarfuse/.../torch/nn
<ipython-input-...>(9): <module>
/mnt/xarfuse/.../IPython/
/mnt/xarfuse/.../IPython/
aten::as_strided 0.01% 281.808us 0 b <ipython-input-...>(11): forward
/mnt/xarfuse/.../torch/nn
<ipython-input-...>(9): <module>
/mnt/xarfuse/.../IPython/
/mnt/xarfuse/.../IPython/
aten::addmm 0.01% 275.721us 0 b /mnt/xarfuse/.../torch/nn
/mnt/xarfuse/.../torch/nn
/mnt/xarfuse/.../torch/nn
<ipython-input-...>(8): forward
/mnt/xarfuse/.../torch/nn
aten::_local 0.01% 268.650us 0 b <ipython-input-...>(11): forward
_scalar_dense /mnt/xarfuse/.../torch/nn
<ipython-input-...>(9): <module>
/mnt/xarfuse/.../IPython/
/mnt/xarfuse/.../IPython/
----------------- ------------ ------------ ------------ --------------------------------
Self CPU time total: 5.347s
"""
此操作的 CPU 内存占用减半。
提高时间性能
虽然消耗的时间也有所减少,但仍然太高。原来从 CUDA 到 CPU 复制矩阵是非常昂贵的!forward (12)中的aten::copy_操作符将mask复制到 CPU,以便可以使用 NumPy 的argwhere函数。forward(13)中的aten::copy_将数组复制回 CUDA 作为张量。如果我们在这里使用torch函数nonzero(),就可以消除这两个操作。
class MyModule(nn.Module):
def __init__(self, in_features: int, out_features: int, bias: bool = True):
super(MyModule, self).__init__()
self.linear = nn.Linear(in_features, out_features, bias)
def forward(self, input, mask):
with profiler.record_function("LINEAR PASS"):
out = self.linear(input)
with profiler.record_function("MASK INDICES"):
threshold = out.sum(axis=1).mean()
hi_idx = (mask > threshold).nonzero(as_tuple=True)
return out, hi_idx
model = MyModule(500, 10).cuda()
input = torch.rand(128, 500).cuda()
mask = torch.rand((500, 500, 500), dtype=torch.float).cuda()
# warm-up
model(input, mask)
with profiler.profile(with_stack=True, profile_memory=True) as prof:
out, idx = model(input, mask)
print(prof.key_averages(group_by_stack_n=5).table(sort_by='self_cpu_time_total', row_limit=5))
"""
(Some columns are omitted)
-------------- ------------ ------------ ------------ ---------------------------------
Name Self CPU % Self CPU Self CPU Mem Source Location
-------------- ------------ ------------ ------------ ---------------------------------
aten::gt 57.17% 129.089ms 0 b <ipython-input-...>(12): forward
/mnt/xarfuse/.../torch/nn
<ipython-input-...>(25): <module>
/mnt/xarfuse/.../IPython/
/mnt/xarfuse/.../IPython/
aten::nonzero 37.38% 84.402ms 0 b <ipython-input-...>(12): forward
/mnt/xarfuse/.../torch/nn
<ipython-input-...>(25): <module>
/mnt/xarfuse/.../IPython/
/mnt/xarfuse/.../IPython/
INDEX SCORE 3.32% 7.491ms -119.21 Mb /mnt/xarfuse/.../torch/au
<ipython-input-...>(10): forward
/mnt/xarfuse/.../torch/nn
<ipython-input-...>(25): <module>
/mnt/xarfuse/.../IPython/
aten::as_strided 0.20% 441.587us 0 b <ipython-input-...>(12): forward
/mnt/xarfuse/.../torch/nn
<ipython-input-...>(25): <module>
/mnt/xarfuse/.../IPython/
/mnt/xarfuse/.../IPython/
aten::nonzero
_numpy 0.18% 395.602us 0 b <ipython-input-...>(12): forward
/mnt/xarfuse/.../torch/nn
<ipython-input-...>(25): <module>
/mnt/xarfuse/.../IPython/
/mnt/xarfuse/.../IPython/
-------------- ------------ ------------ ------------ ---------------------------------
Self CPU time total: 225.801ms
"""
进一步阅读
我们已经看到了如何使用分析器来调查 PyTorch 模型中的时间和内存瓶颈。在这里关于分析器的信息:
-
分析器使用方法
-
基于 RPC 的工作负载分析
-
分析器 API 文档
脚本的总运行时间: ( 0 分钟 0.000 秒)
下载 Python 源代码: profiler.py
下载 Jupyter 笔记本: profiler.ipynb
Sphinx-Gallery 生成的图库
全面跟踪分析简介
原文:
pytorch.org/tutorials/beginner/hta_intro_tutorial.html译者:飞龙
协议:CC BY-NC-SA 4.0
作者:Anupam Bhatnagar
在本教程中,我们演示如何使用全面跟踪分析(HTA)来分析分布式训练作业的跟踪。要开始,请按照以下步骤操作。
安装 HTA
我们建议使用 Conda 环境安装 HTA。要安装 Anaconda,请参阅官方 Anaconda 文档。
-
使用 pip 安装 HTA:
pip install HolisticTraceAnalysis -
(可选但建议)设置一个 Conda 环境:
# create the environment env_name conda create -n env_name # activate the environment conda activate env_name # When you are done, deactivate the environment by running ``conda deactivate``
入门指南
启动 Jupyter 笔记本,并将trace_dir变量设置为跟踪位置。
from hta.trace_analysis import TraceAnalysis
trace_dir = "/path/to/folder/with/traces"
analyzer = TraceAnalysis(trace_dir=trace_dir)
时间细分
为了有效利用 GPU,了解它们为特定作业花费时间至关重要。它们主要是在计算、通信、内存事件中还是空闲?时间细分功能提供了这三个类别中所花费时间的详细分析。
-
空闲时间 - GPU 空闲。
-
计算时间 - GPU 用于矩阵乘法或向量操作。
-
非计算时间 - GPU 用于通信或内存事件。
为了实现高效的训练,代码应最大化计算时间,最小化空闲时间和非计算时间。以下函数生成一个数据框,提供每个等级的时间使用情况的详细分解。
analyzer = TraceAnalysis(trace_dir = "/path/to/trace/folder")
time_spent_df = analyzer.get_temporal_breakdown()
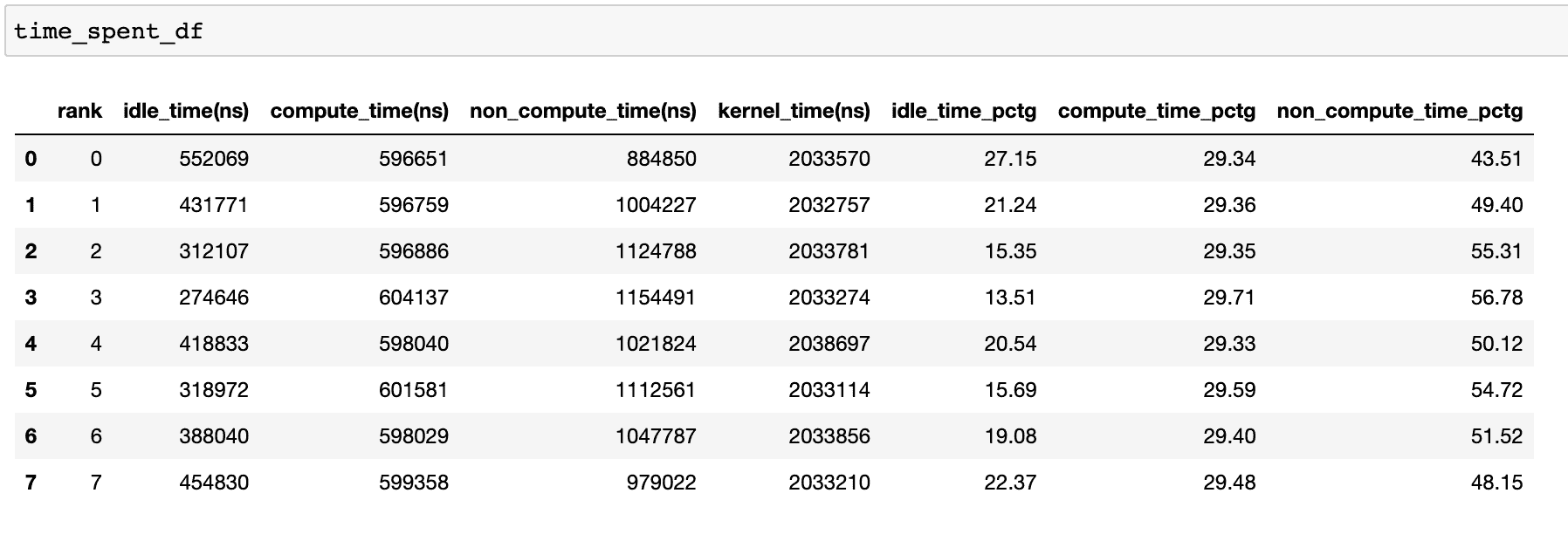
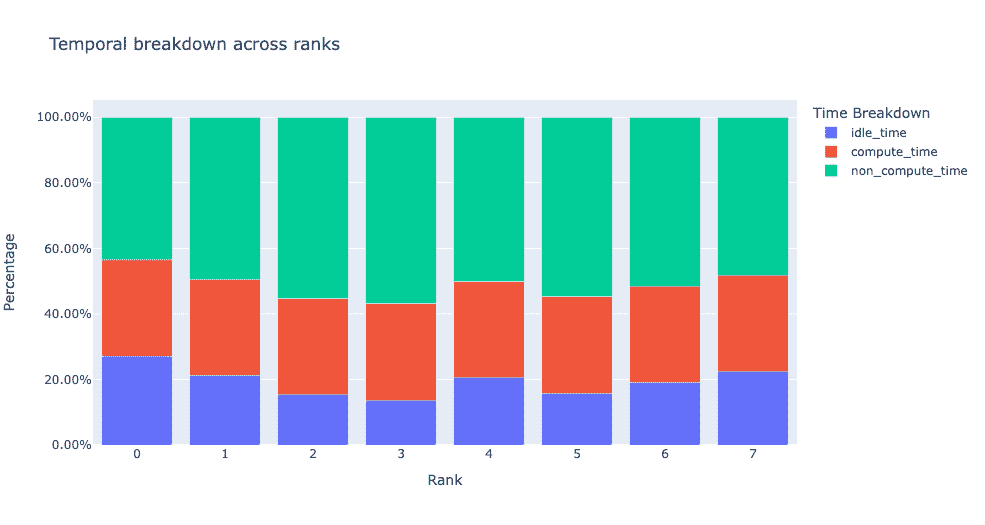
当在get_temporal_breakdown函数中将visualize参数设置为True时,它还会生成一个按等级分解的条形图。
空闲时间细分
深入了解 GPU 空闲时间及其原因可以帮助指导优化策略。当 GPU 上没有运行任何内核时,GPU 被视为空闲。我们开发了一种算法,将空闲时间分类为三个不同的类别:
-
**主机等待:**指的是由于 CPU 未能快速排队内核以使 GPU 完全利用而导致的 GPU 上的空闲时间。这些类型的低效率可以通过检查导致减速的 CPU 运算符、增加批量大小和应用运算符融合来解决。
-
**内核等待:**指的是在 GPU 上连续启动内核时伴随的短暂开销。归因为此类别的空闲时间可以通过使用 CUDA 图优化来最小化。
-
**其他等待:**此类别包括由于信息不足而目前无法归因的空闲时间。可能的原因包括使用 CUDA 事件在 CUDA 流之间同步以及启动内核时的延迟。
主机等待时间可以解释为 GPU 由于 CPU 而停滞的时间。为了将空闲时间归因为内核等待,我们使用以下启发式方法:
连续内核之间的间隔<阈值
默认阈值为 30 纳秒,可以使用consecutive_kernel_delay参数进行配置。默认情况下,仅为等级 0 计算空闲时间细分。为了计算其他等级的细分,可以在get_idle_time_breakdown函数中使用ranks参数。空闲时间细分可以按以下方式生成:
analyzer = TraceAnalysis(trace_dir = "/path/to/trace/folder")
idle_time_df = analyzer.get_idle_time_breakdown()
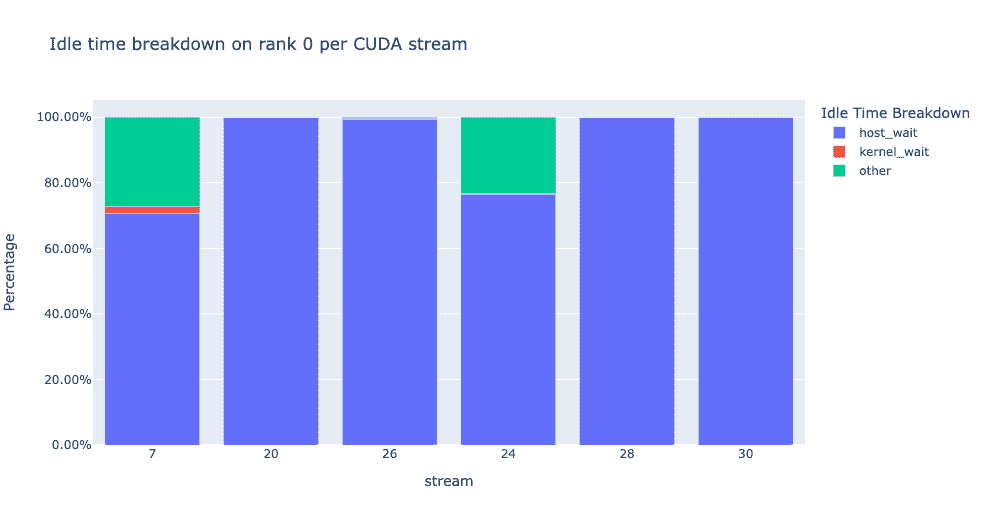
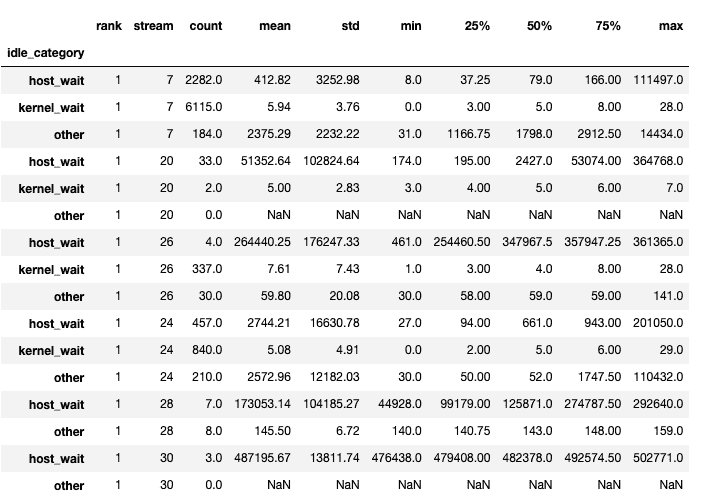
该函数返回一个数据框的元组。第一个数据框包含每个流中每个等级的类别空闲时间。
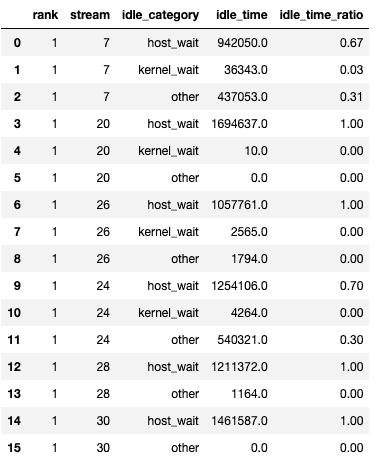
第二个数据框是在将show_idle_interval_stats设置为True时生成的。它包含每个流在每个 rank 上的空闲时间的摘要统计信息。
提示
默认情况下,空闲时间分解显示每个空闲时间类别的百分比。将visualize_pctg参数设置为False,函数将以 y 轴上的绝对时间呈现。
内核分解
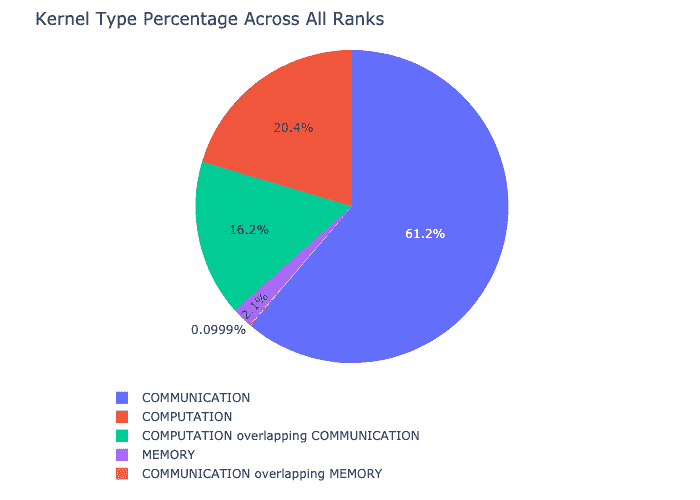
内核分解功能将每种内核类型(如通信(COMM)、计算(COMP)和内存(MEM))花费的时间分解,跨所有 rank,并呈现在每个类别中花费的时间比例。这是每个类别中花费的时间的百分比饼图:
内核分解可以按以下方式计算:
analyzer = TraceAnalysis(trace_dir = "/path/to/trace/folder")
kernel_type_metrics_df, kernel_metrics_df = analyzer.get_gpu_kernel_breakdown()
函数返回的第一个数据框包含生成饼图所使用的原始值。
内核持续时间分布
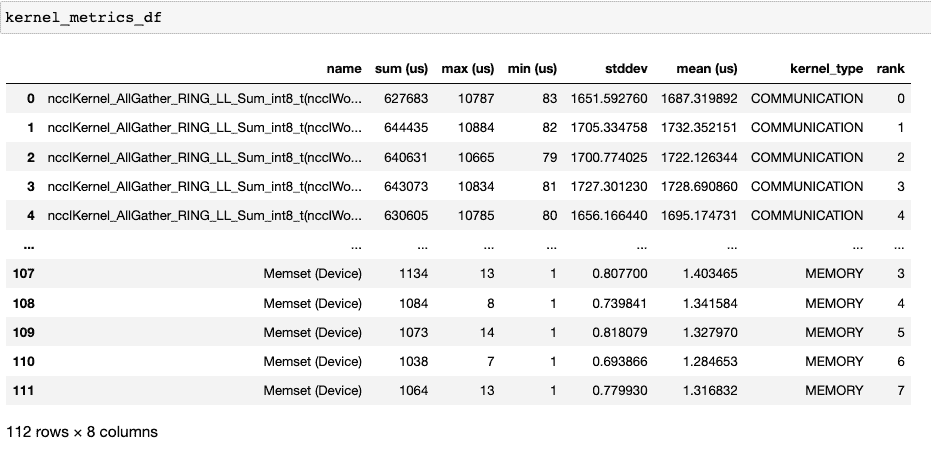
由get_gpu_kernel_breakdown返回的第二个数据框包含每个内核的持续时间摘要统计信息。特别是,这包括每个 rank 上每个内核的计数、最小值、最大值、平均值、标准偏差、总和和内核类型。
使用这些数据,HTA 创建许多可视化来识别性能瓶颈。
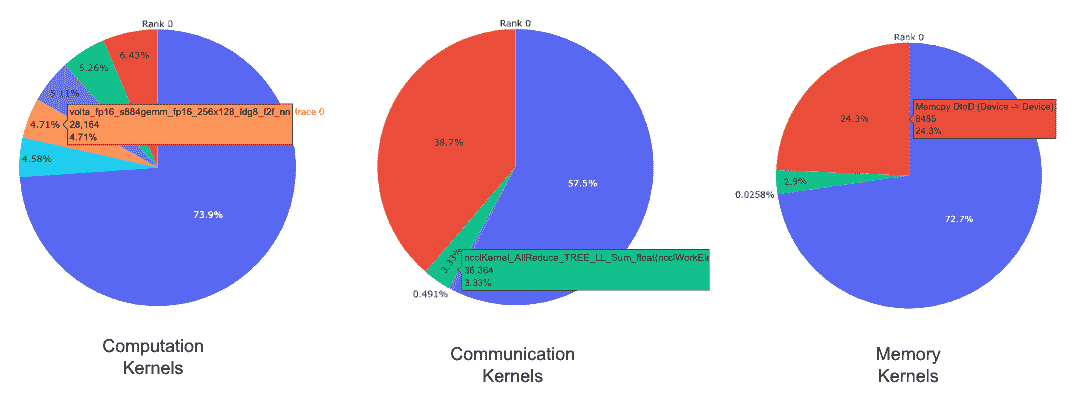
-
每个 rank 上每种内核类型的前 5 个内核的饼图。
-
每个顶级内核和每种内核类型的所有 rank 上的平均持续时间的条形图。
提示
所有图像均使用 plotly 生成。在图表上悬停会显示位于右上角的模式栏,允许用户缩放、平移、选择和下载图表。
上面的饼图显示了前 5 个计算、通信和内存内核。为每个 rank 生成类似的饼图。可以使用传递给 get_gpu_kernel_breakdown 函数的num_kernels参数配置饼图以显示前 k 个内核。此外,可以使用duration_ratio参数来调整需要分析的时间百分比。如果同时指定了num_kernels和duration_ratio,则num_kernels优先。
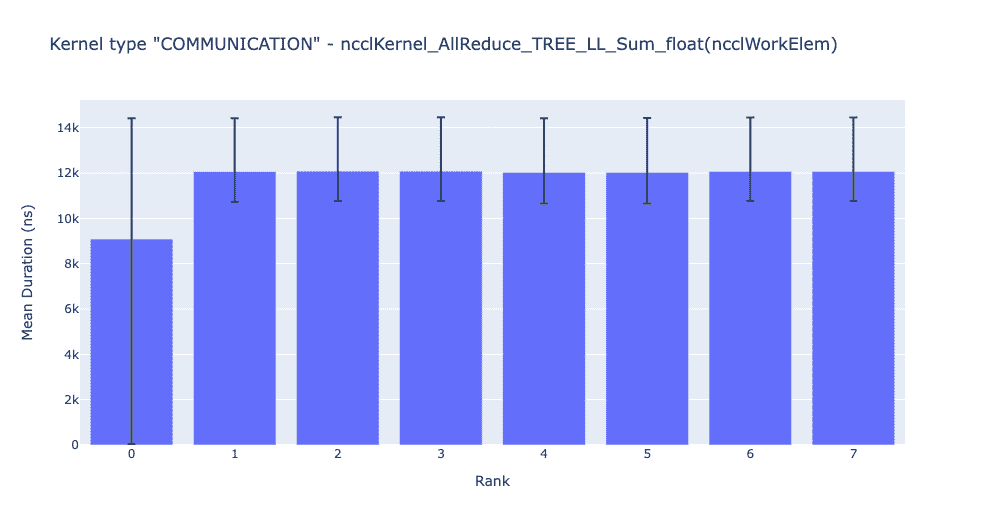
上面的条形图显示了所有 rank 上 NCCL AllReduce 内核的平均持续时间。黑线表示每个 rank 上所花费的最短和最长时间。
警告
在使用 jupyter-lab 时,将“image_renderer”参数值设置为“jupyterlab”,否则图形将无法在笔记本中呈现。
有关此功能的详细演练,请参阅存储库的示例文件夹中的gpu_kernel_breakdown notebook。
通信计算重叠
在分布式训练中,大量时间花费在 GPU 之间的通信和同步事件上。为了实现高 GPU 效率(如 TFLOPS/GPU),保持 GPU 过度订阅计算内核是至关重要的。换句话说,GPU 不应因未解决的数据依赖关系而被阻塞。衡量计算受数据依赖关系阻塞程度的一种方法是计算通信计算重叠。如果通信事件与计算事件重叠,就会观察到更高的 GPU 效率。缺乏通信和计算重叠将导致 GPU 空闲,从而导致效率低下。总之,更高的通信计算重叠是可取的。为了计算每个 rank 的重叠百分比,我们测量以下比率:
(在通信时花费的时间) / (在通信中花费的时间)
通信计算重叠可以计算如下:
analyzer = TraceAnalysis(trace_dir = "/path/to/trace/folder")
overlap_df = analyzer.get_comm_comp_overlap()
该函数返回一个包含每个 rank 的重叠百分比的数据框。
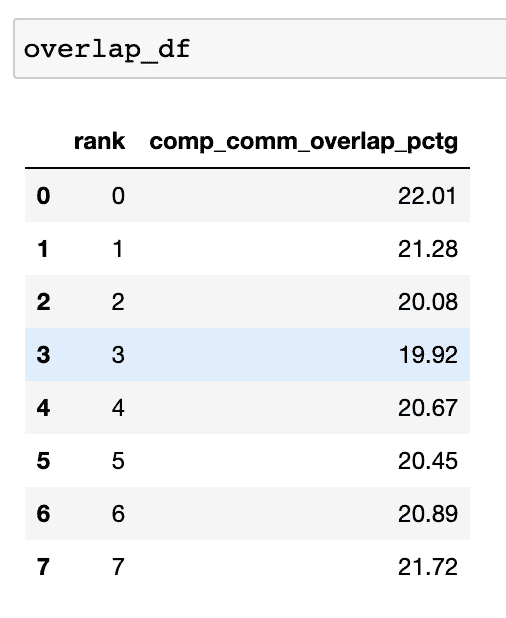
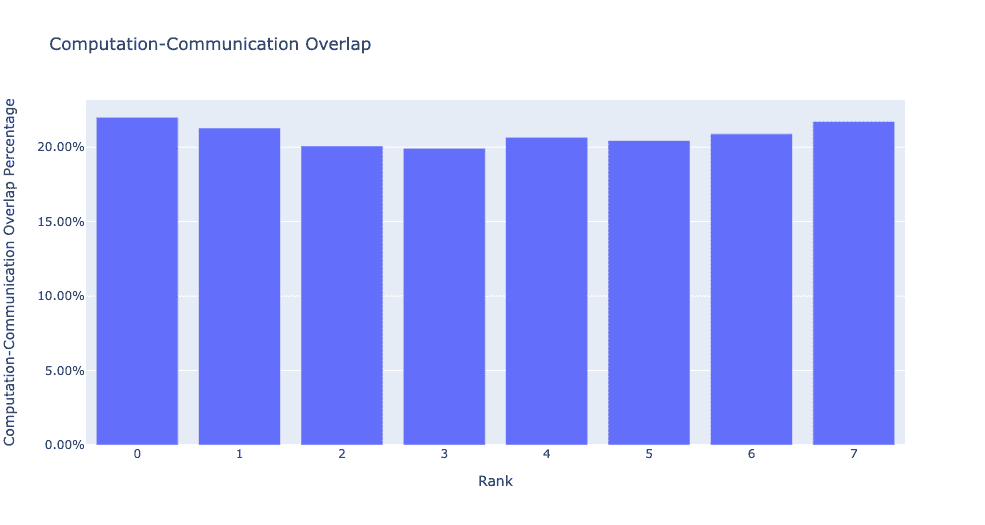
当visualize参数设置为 True 时,get_comm_comp_overlap函数还会生成一个柱状图,表示每个 rank 的重叠。
增强计数器
内存带宽和队列长度计数器
内存带宽计数器测量从 H2D、D2H 和 D2D 复制数据时使用的内存复制带宽(memcpy)和内存设置(memset)事件。HTA 还计算每个 CUDA 流中未完成操作的数量。我们将其称为队列长度。当流上的队列长度为 1024 或更大时,新事件无法在该流上调度,CPU 将停止,直到 GPU 流上的事件被处理。
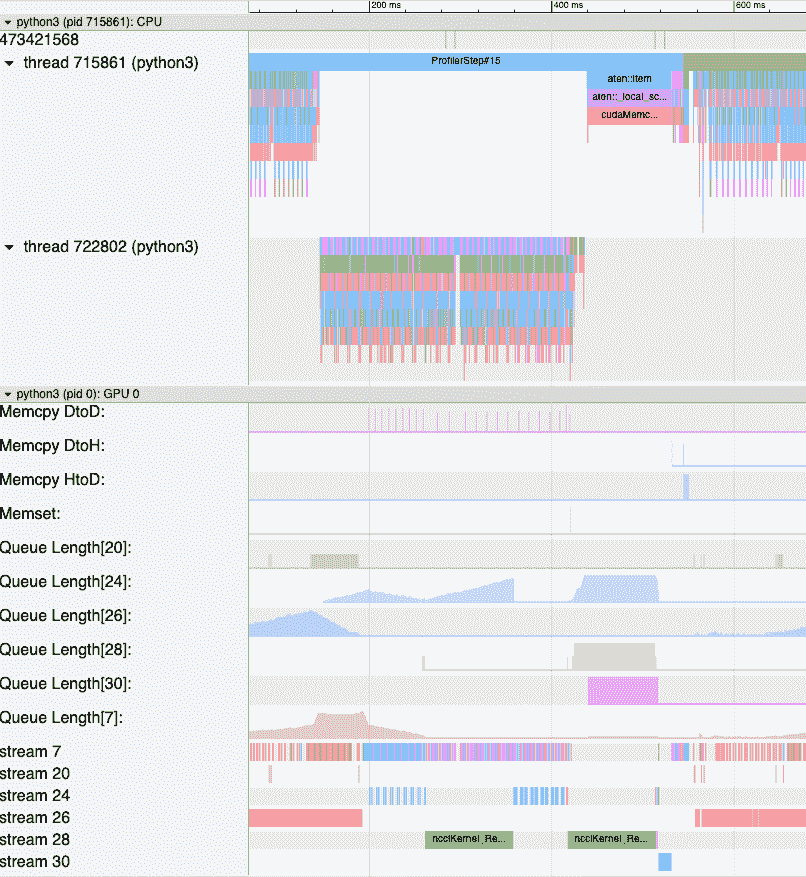
使用generate_trace_with_counters API 输出一个带有内存带宽和队列长度计数器的新跟踪文件。新的跟踪文件包含指示由 memcpy/memset 操作使用的内存带宽的轨道,以及每个流的队列长度的轨道。默认情况下,这些计数器是使用 rank 0 跟踪文件生成的,新文件的名称包含后缀_with_counters。用户可以通过在generate_trace_with_counters API 中使用ranks参数来为多个 rank 生成计数器。
analyzer = TraceAnalysis(trace_dir = "/path/to/trace/folder")
analyzer.generate_trace_with_counters()
生成的带有增强计数器的跟踪文件的屏幕截图。
HTA 还提供了内存复制带宽和队列长度计数器的摘要,以及使用以下 API 对代码的 profile 部分的计数器的时间序列:
-
get_memory_bw_summary
-
get_queue_length_summary
-
get_memory_bw_time_series
-
get_queue_length_time_series
要查看摘要和时间序列,请使用:
# generate summary
mem_bw_summary = analyzer.get_memory_bw_summary()
queue_len_summary = analyzer.get_queue_length_summary()
# get time series
mem_bw_series = analyzer.get_memory_bw_time_series()
queue_len_series = analyzer.get_queue_length_series()
摘要包含计数、最小值、最大值、平均值、标准差、25th、50th 和 75th 百分位数。
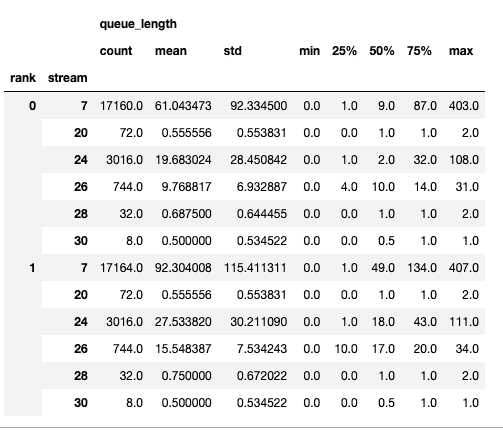
时间序列仅包含数值更改时的点。一旦观察到一个值,时间序列将保持恒定直到下一次更新。内存带宽和队列长度时间序列函数返回一个字典,其键是等级,值是该等级的时间序列。默认情况下,时间序列仅为等级 0 计算。
CUDA 内核启动统计
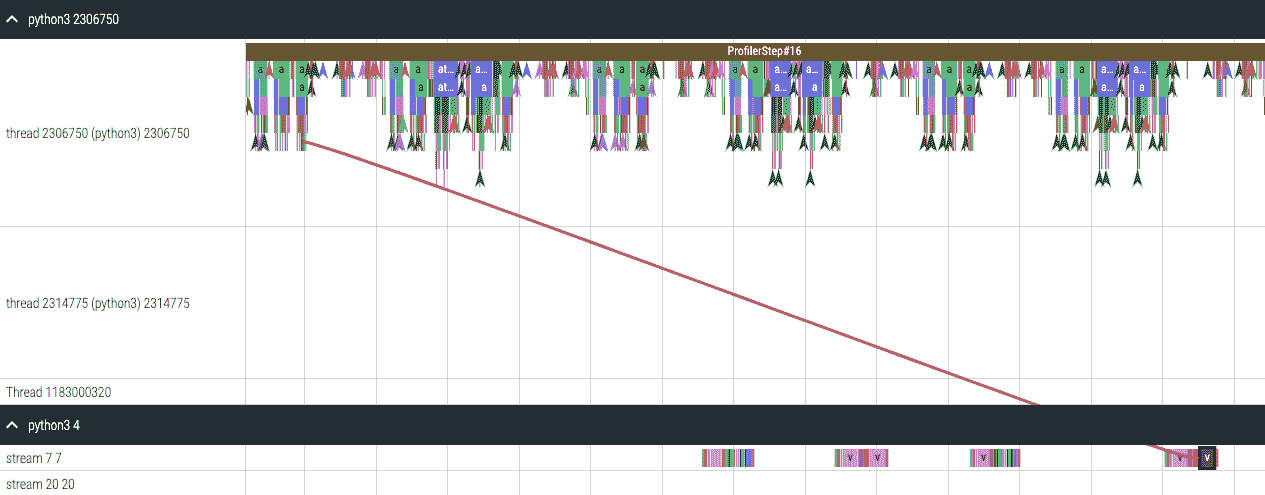
对于在 GPU 上启动的每个事件,CPU 上都有相应的调度事件,例如CudaLaunchKernel,CudaMemcpyAsync,CudaMemsetAsync。这些事件通过追踪中的一个共同的相关 ID 相互关联 - 请参见上图。此功能计算 CPU 运行时事件的持续时间,其相应的 GPU 内核和启动延迟,例如,GPU 内核启动和 CPU 操作结束之间的差异。内核启动信息可以按如下方式生成:
analyzer = TraceAnalysis(trace_dir="/path/to/trace/dir")
kernel_info_df = analyzer.get_cuda_kernel_launch_stats()
下面给出了生成的数据框的屏幕截图。
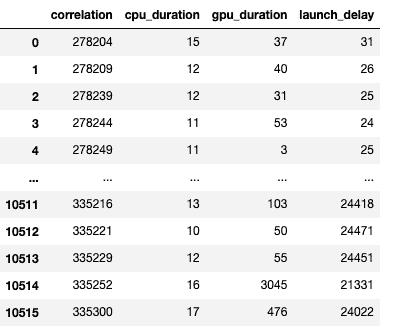
CPU 操作持续时间,GPU 内核和启动延迟使我们能够找到以下内容:
-
短 GPU 内核 - GPU 内核持续时间低于相应的 CPU 运行时事件。
-
运行时事件异常值 - CPU 运行时事件持续时间过长。
-
启动延迟异常值 - GPU 内核调度时间过长。
HTA 为上述三个类别生成分布图。
短 GPU 内核
通常,CPU 端的启动时间范围为 5-20 微秒。在某些情况下,GPU 执行时间低于启动时间本身。下面的图表帮助我们找出代码中这种情况发生的频率。
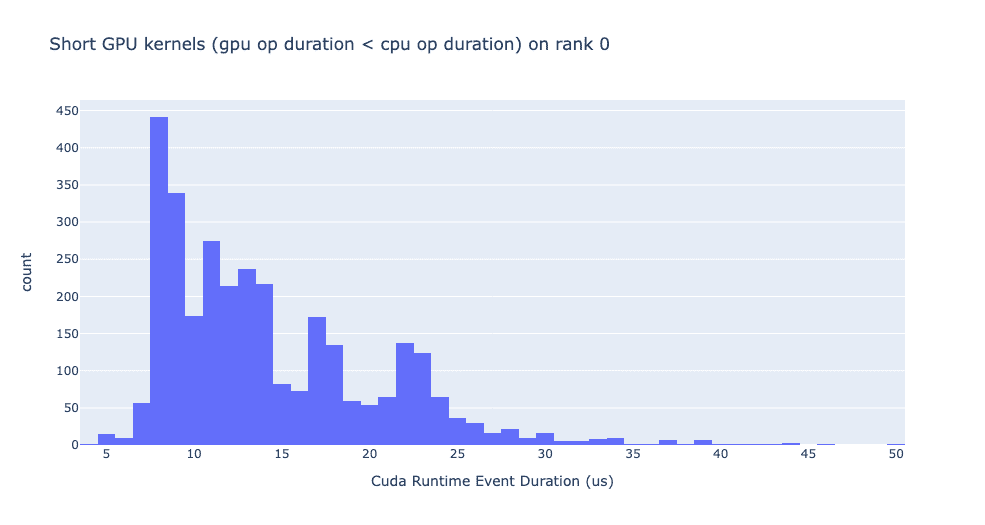
运行时事件异常值
运行时异常值取决于用于分类异常值的截止值,因此get_cuda_kernel_launch_stats API 提供runtime_cutoff参数来配置该值。
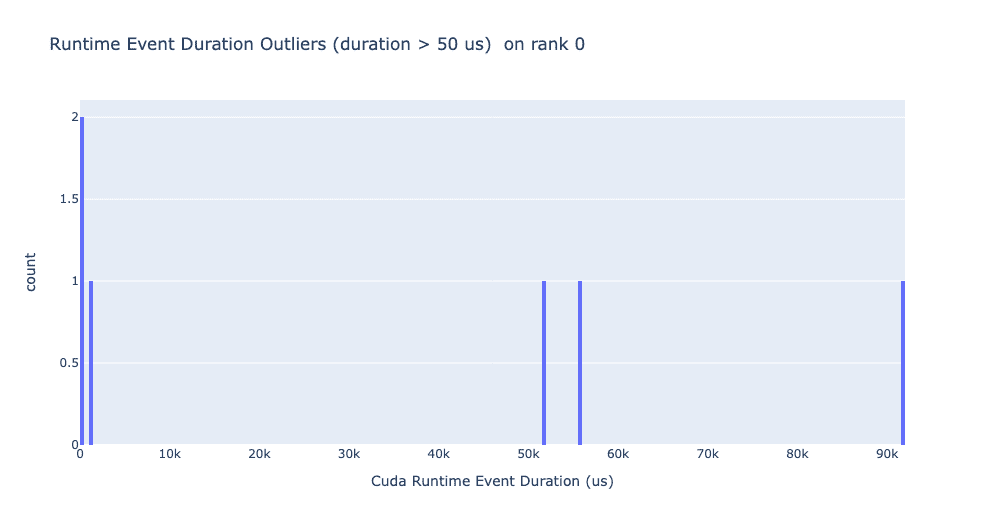
启动延迟异常值
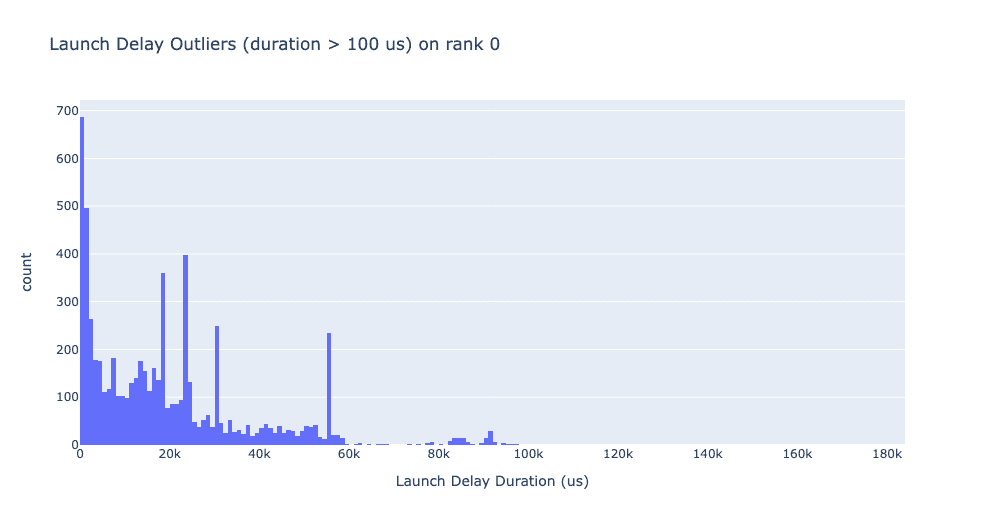
启动延迟异常值取决于用于分类异常值的截止值,因此 get_cuda_kernel_launch_stats API 提供launch_delay_cutoff参数来配置该值。
结论
在本教程中,您已经学会了如何安装和使用 HTA,这是一种性能工具,可以帮助您分析分布式训练工作流中的瓶颈。要了解如何使用 HTA 工具执行跟踪差异分析,请参阅使用全面跟踪分析进行跟踪差异。





![[Python] scikit-learn中数据集模块介绍和使用案例](https://img-blog.csdnimg.cn/direct/61fb9a63a6fa4395b6eeed3e166d2de8.png)