9.24. 两两交换链表中的节点
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
示例 1:
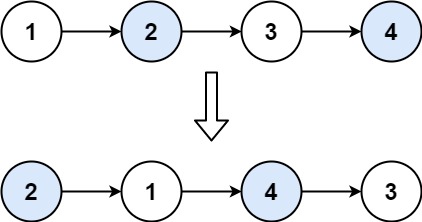
输入:head = [1,2,3,4] 输出:[2,1,4,3]示例 2:
输入:head = [] 输出:[]示例 3:
输入:head = [1] 输出:[1]提示:
- 链表中节点的数目在范围
[0, 100]内0 <= Node.val <= 100
思路:
使用三个同步指针就可以完成原地交换操作;接着依次向下传递,当其中一快指针出现空时停止交换操作。特别地,对于空链表、单节点链表单独处理即可。
代码:
有些单纯,不给过,重看!
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* swapPairs(ListNode* head) {
if(head==nullptr || head->next==nullptr)return head;
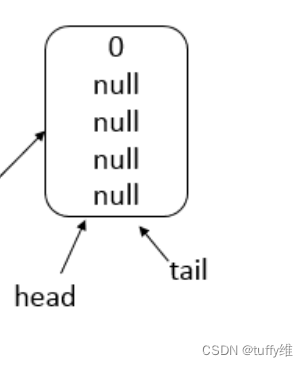
ListNode *pre=new ListNode(0,head);
ListNode *cur1,*cur2;
cur1=head;
cur2=head->next;
while(cur2!=nullptr){
cur1->next=cur2->next;
cur2->next=cur1;
pre->next=cur2;
pre=pre->next->next;
cur2=pre->next->next;
cur1=cur1->next;
}
return head;
}
};改一下:
class Solution {
public:
ListNode* swapPairs(ListNode* head) {
if(head==nullptr || head->next==nullptr)return head;
ListNode *temp=new ListNode(0,head);
ListNode *pre=temp;
while(pre->next!=nullptr && pre->next->next !=nullptr){
ListNode *cur1 =pre->next;
ListNode *cur2 =pre->next->next;
pre->next=cur2;
cur1->next=cur2->next;
cur2->next=cur1;
pre=cur1;
}
return temp->next;
}
};10.25. K 个一组翻转链表
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
示例 1:
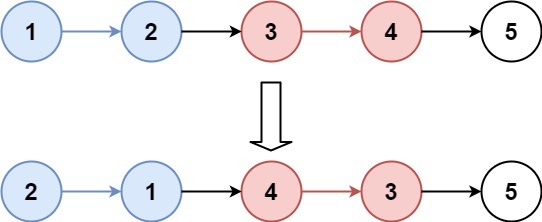
输入:head = [1,2,3,4,5], k = 2 输出:[2,1,4,3,5]示例 2:
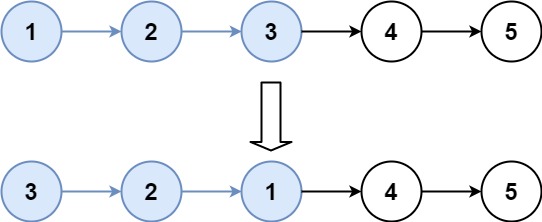
输入:head = [1,2,3,4,5], k = 3 输出:[3,2,1,4,5]提示:
- 链表中的节点数目为
n1 <= k <= n <= 50000 <= Node.val <= 1000进阶:你可以设计一个只用
O(1)额外内存空间的算法解决此问题吗?
思路:
仔细
链表分区为已翻转部分+待翻转部分+未翻转部分
每次翻转前,要确定翻转链表的范围,这个必须通过 k 此循环来确定
需记录翻转链表前驱和后继,方便翻转完成后把已翻转部分和未翻转部分连接起来
初始需要两个变量 pre 和 end,pre 代表待翻转链表的前驱,end 代表待翻转链表的末尾
经过k此循环,end 到达末尾,记录待翻转链表的后继 next = end.next
翻转链表,然后将三部分链表连接起来,然后重置 pre 和 end 指针,然后进入下一次循环
特殊情况,当翻转部分长度不足 k 时,在定位 end 完成后,end==null,已经到达末尾,说明题目已完成,直接返回即可
时间复杂度为 O(n∗K)最好的情况为 O(n)最差的情况未 O(n^2)
空间复杂度为 O(1) 除了几个必须的节点指针外,我们并没有占用其他空间。

该思想源自:
代码:
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode reverseKGroup(ListNode head, int k) {
ListNode dummy = new ListNode(0); // 此处只是设置一个哨兵节点
dummy.next = head; // 哨兵节点的下一个指向首节点
ListNode pre = dummy; // 上一段的最后一个节点 节点初始化
ListNode end = dummy; // 本段最后一个节点
while (end.next != null) {
// 此处是为了找到其中的 k 个子节点
for(int i = 0 ; i < k && end != null; i++){
end = end.next;
}
if(end == null){ // 如果直接到头了,那就说明没有满足 k 个
break;
}
ListNode start = pre.next; // 此处是为记录原始未反转段的起始节点
ListNode nextStart = end.next; // 记录下一个阶段 起始点
end.next = null; // 此处是为了进行后面的反转操作,断开此处链接,让后面反转操作知道截断点在哪里
pre.next = reverse(start); // 反转操作
start.next = nextStart; // 反转之后,start节点实际是已经最后一个节点了,为了和后面的划分段链接,让他的下一个节点连接上下一段的起始点即可
pre = start; // pre再次来到下一段的上一个节点,也就是本段的结尾点
end = pre; // 结束点,准备开始下一段的循环找 k 长度的段操作
}
return dummy.next; // 返回最开始的哨兵
}
private ListNode reverse(ListNode head){
ListNode pre = null;
ListNode curr = head;
while(curr != null){ // 交换操作
ListNode next = curr.next;
curr.next = pre;
pre = curr;
curr = next;
}
return pre; // 返回哨兵,此处是新的翻转序列的起始节点
}
}11.138. 随机链表的复制
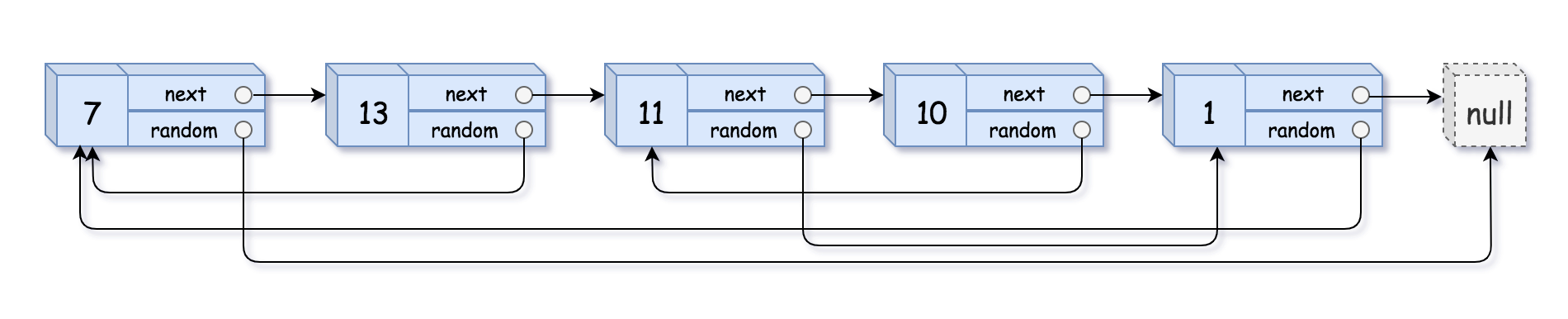
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例 1:
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]] 输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]示例 2:
输入:head = [[1,1],[2,1]] 输出:[[1,1],[2,1]]示例 3:
输入:head = [[3,null],[3,0],[3,null]] 输出:[[3,null],[3,0],[3,null]]提示:
0 <= n <= 1000-10^4 <= Node.val <= 10^4Node.random为null或指向链表中的节点。


思路:
方法:哈希表.
因为本链表与其他链表的不同之处在于多了一个指针,因此一遍不够,可以先遍历一遍正常节点,并建立哈希表,然后再次遍历,补齐指针!
"""
# Definition for a Node.
class Node:
def __init__(self, x: int, next: 'Node' = None, random: 'Node' = None):
self.val = int(x)
self.next = next
self.random = random
"""
class Solution:
def copyRandomList(self, head: 'Node') -> 'Node':
if not head: return
dic = {}
# 3. 复制各节点,并建立 “原节点 -> 新节点” 的 Map 映射
cur = head
while cur:
dic[cur] = Node(cur.val)
cur = cur.next
cur = head
# 4. 构建新节点的 next 和 random 指向
while cur:
dic[cur].next = dic.get(cur.next)
dic[cur].random = dic.get(cur.random)
cur = cur.next
# 5. 返回新链表的头节点
return dic[head]
12.148. 排序链表
给你链表的头结点
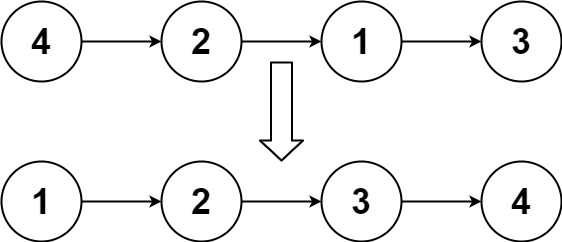
head,请将其按 升序 排列并返回 排序后的链表 。示例 1:
输入:head = [4,2,1,3] 输出:[1,2,3,4]示例 2:
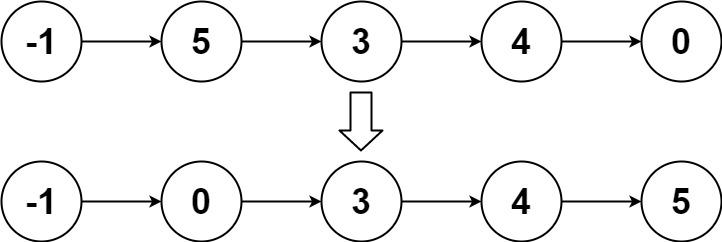
输入:head = [-1,5,3,4,0] 输出:[-1,0,3,4,5]示例 3:
输入:head = [] 输出:[]提示:
- 链表中节点的数目在范围
[0, 5 * 10^4]内-10^5 <= Node.val <= 10^5进阶:你可以在
O(n log n)时间复杂度和常数级空间复杂度下,对链表进行排序吗?
思路:
我这直接都准备嘎嘎排序了,你给我来个链表,行!那我直接插入排序咯?划分有序区和无序区,不过代码还得是写一写!!这感觉时间复杂度得是n^2了。算了,换一下,改个归并排序。
对链表自顶向下归并排序的过程如下。
1.找到链表的中点,以中点为分界,将链表拆分成两个子链表。寻找链表的中点可以使用快慢指针的做法,快指针每次移动 2 步,慢指针每次移动 1 步,当快指针到达链表末尾时,慢指针指向的链表节点即为链表的中点。
2.对两个子链表分别排序。
3.将两个排序后的子链表合并,得到完整的排序后的链表。
上述过程可以通过递归实现。递归的终止条件是链表的节点个数小于或等于 1,即当链表为空或者链表只包含 1个节点时,不需要对链表进行拆分和排序。
代码:
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode sortList(ListNode head) {
return sortList(head,null);
}
public ListNode sortList(ListNode head,ListNode tail){
if(head==null){
return head;
}
if(head.next==tail){
head.next = null;
return head;
}
ListNode slow =head,fast = head;
//快指针走两个,慢指针走一个
//寻找链表中间位置指针
while(fast!=tail){
slow = slow.next;
fast=fast.next;
if(fast!=tail){
fast=fast.next;
}
}
ListNode mid=slow;
ListNode list1=sortList(head,mid);
ListNode list2=sortList(mid,tail);
ListNode sorted=merge(list1,list2);
return sorted;
}
public ListNode merge(ListNode head1,ListNode head2){
ListNode dummyHead = new ListNode(0);
ListNode temp = dummyHead, temp1 = head1, temp2 = head2;
while (temp1 != null && temp2 != null) {
if (temp1.val <= temp2.val) {
temp.next = temp1;
temp1 = temp1.next;
} else {
temp.next = temp2;
temp2 = temp2.next;
}
temp = temp.next;
}
if (temp1 != null) {
temp.next = temp1;
} else if (temp2 != null) {
temp.next = temp2;
}
return dummyHead.next;
}
}13.23. 合并 K 个升序链表