文章目录
- 5.1 选择数据存储方案
- 5.1.1 重点基础知识讲解
- 5.1.2 重点案例:使用 SQLite 存储博客文章数据
- 5.1.3 拓展案例 1:使用 MongoDB 存储社交媒体动态
- 5.1.4 拓展案例 2:使用 Elasticsearch 存储和检索日志数据
- 5.2 数据清洗与预处理
- 5.2.1 重点基础知识讲解
- 5.2.2 重点案例:清洗抓取的评论数据
- 5.2.3 拓展案例 1:格式化日期数据
- 5.2.4 拓展案例 2:处理缺失值
- 5.3 数据存储最佳实践
- 5.3.1 重点基础知识讲解
- 5.3.2 重点案例:自动化数据库备份
- 5.3.3 拓展案例 1:实现数据加密
- 5.3.4 拓展案例 2:使用 MongoDB 实现数据归档
5.1 选择数据存储方案
当我们的船满载着珍贵的数据宝藏回到港口时,我们需要一个安全可靠的地方来存放这些宝贝。这就是选择合适的数据存储方案的重要时刻了。不同的宝藏可能需要不同的宝箱——同样,不同类型的数据也需要不同的存储方案。
5.1.1 重点基础知识讲解
- 关系型数据库(RDBMS):如 MySQL、PostgreSQL。适合存储结构化数据,强调数据之间的关系和完整性。如果你的数据需要频繁的查询和事务操作,这可能是一个好选择。
- NoSQL 数据库:如 MongoDB、Cassandra。适合存储半结构化或非结构化数据,强调可扩展性和灵活性。如果你的数据模型不断变化,或者你需要处理大量数据,NoSQL 可能更合适。
- 文件存储:如 CSV、JSON 文件。对于小型项目或数据量不大的情况,直接将数据保存为文件可能是最简单快捷的方法。文件存储易于理解和操作,但随着数据量的增长,查询和更新效率可能会成问题。
5.1.2 重点案例:使用 SQLite 存储博客文章数据
假设我们正在抓取一个博客网站,希望将文章的标题、作者和发布日期存储起来。对于这种小型项目,SQLite 是一个轻量级且易于设置的选择。
import sqlite3
# 创建或打开数据库
conn = sqlite3.connect('blog_articles.db')
c = conn.cursor()
# 创建表
c.execute('''CREATE TABLE IF NOT EXISTS articles
(title TEXT, author TEXT, publish_date TEXT)''')
# 插入数据
c.execute("INSERT INTO articles VALUES ('Python Tips', 'Jane Doe', '2021-07-01')")
# 保存(提交)更改
conn.commit()
# 关闭连接
conn.close()
5.1.3 拓展案例 1:使用 MongoDB 存储社交媒体动态
当我们需要抓取并存储社交媒体上的动态信息时,这些数据往往是半结构化的,并且数据模型可能会频繁变化。在这种情况下,MongoDB 提供了足够的灵活性和可扩展性。
from pymongo import MongoClient
# 连接到 MongoDB
client = MongoClient('mongodb://localhost:27017/')
# 选择数据库和集合
db = client['social_media']
collection = db['posts']
# 插入数据
post_data = {
'user': 'johndoe',
'text': 'Exploring MongoDB with Python!',
'tags': ['mongodb', 'python', 'database']
}
collection.insert_one(post_data)
5.1.4 拓展案例 2:使用 Elasticsearch 存储和检索日志数据
对于需要快速检索的大量文本数据(如日志文件),Elasticsearch 提供了强大的全文搜索能力和实时分析。
from elasticsearch import Elasticsearch
# 连接到 Elasticsearch
es = Elasticsearch(['http://localhost:9200'])
# 插入数据
log_data = {
'timestamp': '2021-07-01T12:00:00',
'level': 'INFO',
'message': 'Starting web server'
}
es.index(index='logs', body=log_data)
# 检索数据
res = es.search(index="logs", body={"query": {"match": {'level': 'INFO'}}})
print(res['hits']['hits'])
通过掌握这些存储方案,你将能够为你的数据宝藏选择最合适的“宝箱”,无论是宝石还是古董,都可以得到妥善的保护和管理。选择正确的数据存储方案,让你的数据宝藏更加安全、易于访问和使用。

5.2 数据清洗与预处理
在数据的宝库中,不是所有的宝石都是闪亮的,也不是所有的金子都是纯净的。同样,在我们抓取的数据中,也充满了各种“杂质”——无效数据、错误、缺失值等。在这一部分,我们将学习如何成为一名数据的炼金术士,将这些原始的、粗糙的数据“炼化”成干净、有用的信息。
5.2.1 重点基础知识讲解
- 去除无效数据:无效数据包括空白字符、无意义的占位符等。这些数据对分析没有任何帮助,甚至会引起错误。
- 格式化和类型转换:确保数据的格式和类型符合我们的需求,例如将字符串格式的日期转换为日期类型,可以让我们更方便地进行日期计算。
- 处理缺失值:数据中的缺失值可以通过多种方法处理,包括删除、填充默认值或使用统计方法(如平均值、中位数)估算。
- 数据规范化:为了便于比较或后续处理,有时需要将数据规范化到特定的范围或格式。
5.2.2 重点案例:清洗抓取的评论数据
假设我们抓取了一系列产品评论,但这些评论包含了大量的空格、HTML 标签等无效信息,我们需要清洗这些数据。
from bs4 import BeautifulSoup
import re
# 假设这是我们抓取的一条评论
raw_comment = " <p>这是一条<em>非常好的</em>评论!</p> "
# 使用 BeautifulSoup 去除 HTML 标签
clean_comment = ''.join(BeautifulSoup(raw_comment, "html.parser").stripped_strings)
# 进一步去除前后空格
clean_comment = clean_comment.strip()
print(clean_comment) # 输出: "这是一条非常好的评论!"
5.2.3 拓展案例 1:格式化日期数据
在处理抓取的数据时,我们可能遇到各种格式的日期数据,需要将它们统一格式化为 Python 的日期类型。
from datetime import datetime
# 假设我们抓取的日期是字符串格式
raw_date = "2021-07-01"
# 将字符串格式的日期转换为 datetime 类型
formatted_date = datetime.strptime(raw_date, "%Y-%m-%d")
print(formatted_date) # 输出: 2021-07-01 00:00:00
5.2.4 拓展案例 2:处理缺失值
在抓取的数据中,经常会遇到缺失值,尤其是在大规模的数据集中。处理这些缺失值是数据清洗的重要步骤。
import pandas as pd
import numpy as np
# 创建一个包含缺失值的 DataFrame
df = pd.DataFrame({
'name': ['产品A', '产品B', np.nan, '产品D'],
'price': [10, 20, 15, np.nan]
})
# 填充缺失的产品名称为 "未知产品"
df['name'].fillna('未知产品', inplace=True)
# 填充缺失的价格为列的平均值
df['price'].fillna(df['price'].mean(), inplace=True)
print(df)
通过这些案例,我们学习了如何清洗和预处理数据,确保我们的数据宝藏纯净且有用。记住,干净的数据是进行有效分析和获得有意义洞察的基础。掌握了数据清洗的技能,你就更接近成为数据分析大师了!

5.3 数据存储最佳实践
在数据的大海中航行,我们不仅需要捕获数据,还要确保它们能够安全、有效地存储。这就像是将珍贵的宝藏安放在海盗无法触及的地方。让我们探索一些数据存储的最佳实践,确保我们的数据宝藏既安全又容易访问。
5.3.1 重点基础知识讲解
- 数据备份:定期备份数据是防止数据丢失的关键步骤。这可以通过自动化脚本或使用数据库管理系统的内置功能来实现。
- 安全性:保护数据不被未授权访问是至关重要的。这包括实施加密措施、设置强密码和使用安全的连接协议等。
- 一致性和完整性:确保数据的一致性和完整性可以避免数据冗余和潜在的错误。数据库的约束、触发器和事务都是实现这一目标的有效工具。
- 数据归档:对于不再频繁访问的旧数据,应该将其归档,以优化存储资源和提高查询性能。
5.3.2 重点案例:自动化数据库备份
假设我们正在运行一个在线商店,并且使用 MySQL 数据库来存储产品信息和用户订单。为了防止数据丢失,我们需要定期备份数据库。
import os
from datetime import datetime
# 设置数据库连接信息
db_host = "localhost"
db_name = "online_store"
db_user = "user"
db_pass = "password"
# 生成备份文件名
backup_time = datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
backup_file = f"{db_name}-{backup_time}.sql"
# 执行备份命令
backup_cmd = f"mysqldump -u {db_user} -p{db_pass} {db_name} > {backup_file}"
os.system(backup_cmd)
print(f"数据库备份完成,文件名:{backup_file}")
5.3.3 拓展案例 1:实现数据加密
在存储包含敏感信息的数据时(如用户个人信息),加密是保护数据安全的关键。
from cryptography.fernet import Fernet
# 生成密钥
key = Fernet.generate_key()
cipher_suite = Fernet(key)
# 加密数据
user_data = "用户的敏感信息"
encrypted_data = cipher_suite.encrypt(user_data.encode())
# 解密数据
decrypted_data = cipher_suite.decrypt(encrypted_data).decode()
print(f"加密前的数据: {user_data}")
print(f"加密后的数据: {encrypted_data}")
print(f"解密后的数据: {decrypted_data}")
5.3.4 拓展案例 2:使用 MongoDB 实现数据归档
当处理日志数据或其他形式的时序数据时,归档旧数据可以帮助维持系统的性能。
from pymongo import MongoClient
from datetime import datetime, timedelta
# 连接到 MongoDB
client = MongoClient('mongodb://localhost:27017/')
db = client['log_data']
# 定义归档策略:归档 30 天前的数据
archive_date = datetime.now() - timedelta(days=30)
# 移动旧数据到归档集合
db.logs.aggregate([
{"$match": {"timestamp": {"$lt": archive_date}}},
{"$out": "logs_archive"}
])
print("数据归档完成。")
通过采用这些最佳实践,我们可以确保数据的安全性、可访问性和完整性。无论是定期备份,保护数据安全,还是优化存储和查询性能,这些策略都将帮助我们有效管理数据宝藏。记住,良好的数据管理习惯是成功数据分析的基石。
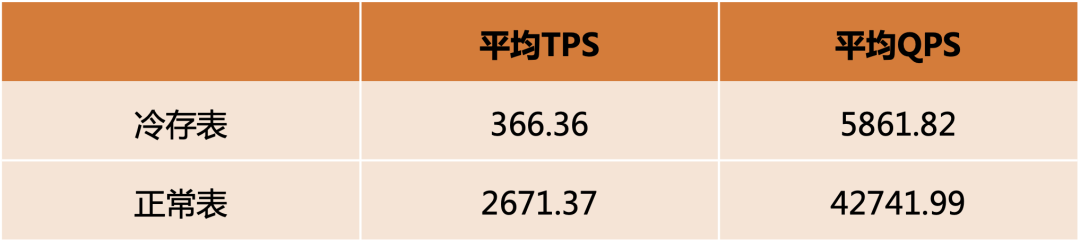


![[设计模式Java实现附plantuml源码~结构型]处理多维度变化——桥接模式](https://img-blog.csdnimg.cn/direct/8e811a73550d49e6a55c49a070a733e8.png)