记elasticsearch CPU负载100%问题
- 环境:
- 问题表现:
- 初步排查:
- 日志
- 查询hot_thread
- 深入
- 查询当前elasticsearch正在运行的Task
- 查看Task详情
- 解决问题
- 对导致问题的原因的几个猜测
- 问题复现:
- 导致问题的原因。
- json导入规则问题
- json导入规则问题解决
- 中英文非ndjson格式数据上传问题
- 中英文非ndjson格式数据问题解决
- reference
- 附录
- elasticsearch,index基本数据格式
- elasticsearch的analyzer
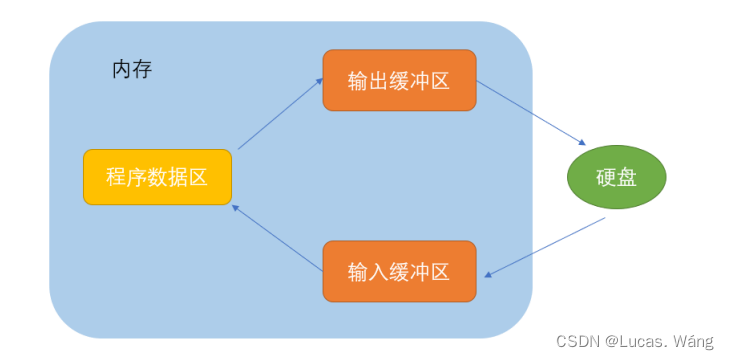
环境:
单台2核4G的阿里云ecs,部署单node的elasticsearch+kibana。
测试环境,刚上手elasticsearch学习用。本来是构建LLM的RAG系统的,结果突然来了个100%CPU占用,而且居高不下,没办法,干回老本行,运维工程师,启动!
问题表现:
在上午9.50分开始,阿里云控制台可看见ecs的CPU从原本的4%占用左右,快速飙到了100%,并且长时间居高不下。

初步排查:
日志
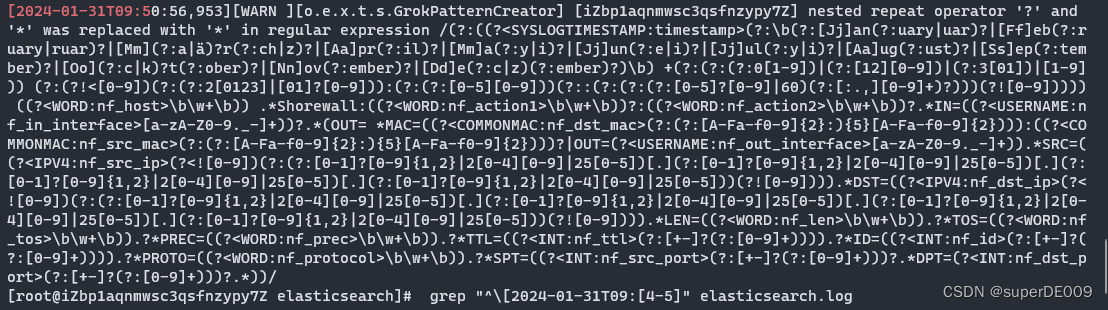
先看日志,通过正则筛选elasticsearch.log中9.40-50分中的所有日志。
cd /var/log/elasticsearch
grep "^\[2024-01-31T09:[4-5]" elasticsearch.log
可以见到,日志中有多段如下日志。其主要内容是Grok在对非结构化数据的正则匹配,提取信息。而我从未进行过任何的Grok配置与操作。
查询hot_thread
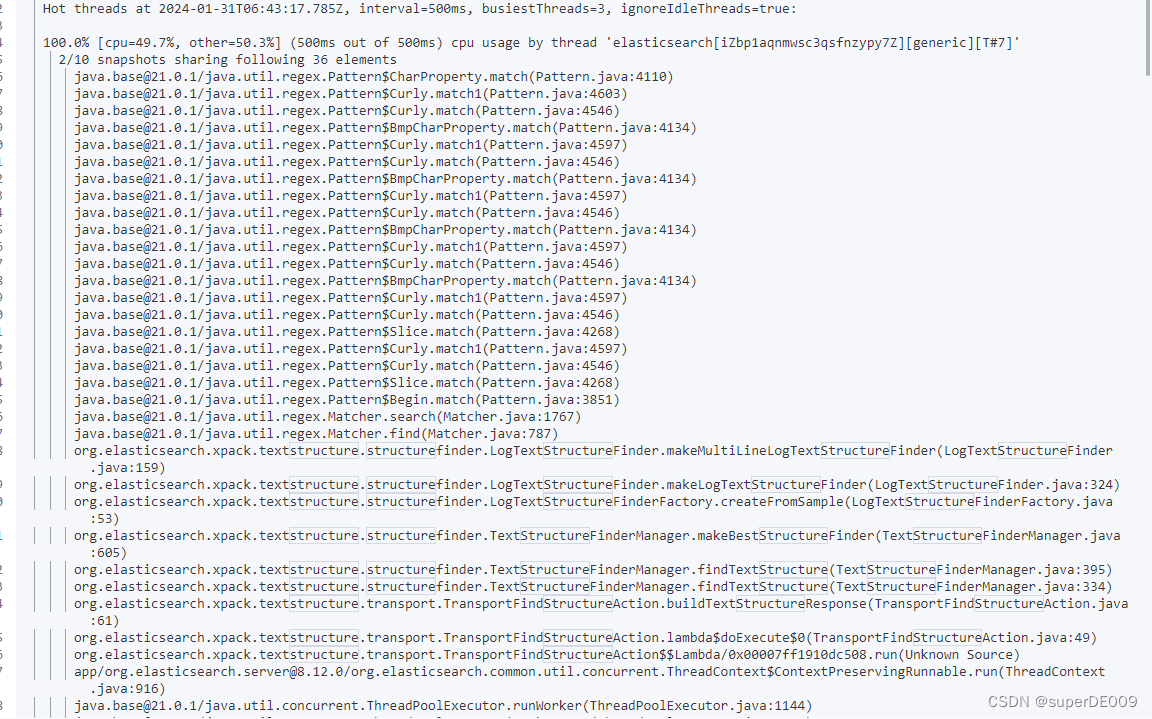
elasticsearch的API中,提供了一个查询当前node中资源占用量大的进程的接口。
GET /_nodes/hot_threads
查询结果如下,可以详细看到,这些进程大部分都在进行正则匹配的工作,和之前log中看到的一致。并且,下方textstructure.structurefinder这个类,即是Gork提取非结构化数据信息的类。
深入
查询当前elasticsearch正在运行的Task
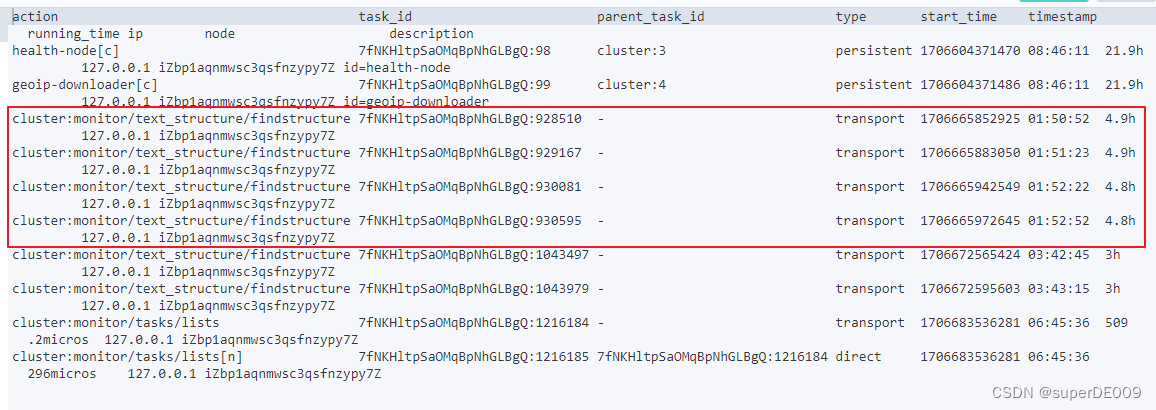
通过API,可以详细的查找到当前elasticsearch中,正在运行的Task的详细内容。
GET /_cat/tasks?v&detailed=true
可以看到,其中存在几个text_structure/findstructure的Task,和hot_thread中看到的一致,并且启动的时间也基本对应CPU升高的时间。
查看Task详情
通过通配符匹配,查询这几个Task的详细信息。
GET /_tasks?detailed=true&actions=*/text_structure/findstructure
可以看到,这几个任务的Type为Transport的类型。
从elasticsearch文档中,可以看到,Transport类型的任务的主要功能是:

到这,卡住了
transport类型,一般的node之间通信的任务,但是我是单node
所以我又找到,发现我创建的index,默认replica=1,即分片有一个备份,而我是单node,备份必须是存储在不同的node上,导致备份分片一直不能被分配,使得index状态处于yellow状态。
但是不确定这个和我当前的任务是否有关系
好了,更新的replica,但是问题还在,现在index都是绿的了
解决问题
重启解决问题,重启后,所有的structurefinder进程都消失了
OK,不用查了,es崩了,直接重启了。
在此之前,还检查了是否是pipeline的问题,但是pipeline都没有在使用。
OK,重启了,之前看到的structurefinder进程都没有了,CPU也降下来。
问题虽然解决,但是还是不知道为啥。
对导致问题的原因的几个猜测
几个怀疑:看看之后我会不会再复现这个问题
- 多副本问题,导致有副本切片一直没有合适的node分配(但是不应该占用CPU啊?
- 因为导入的时候,使用了默认的pipeline,导致对导入的数据,进行的非结构化分析和提取,导致CPU占用高。(但是,不应该一直持续存在吧?
- 中间有玩了一次,kibanaUI界面,添加集成,直接上传了一个json格式的问题,不知道是不是这个问题。返回的结果是失败,说需要结构化的数据?并且是请求超时(我认为这个最有可能)。
问题复现:
因为对于原因3最为怀疑,而且确实时间点也对的上,就是上传完之后开始CPU飙升,同时上传失败的返回也确实怪怪的。所以重新上传。
json内容:值为中文的unicode

重新上传之后,仍然是以下的问题。
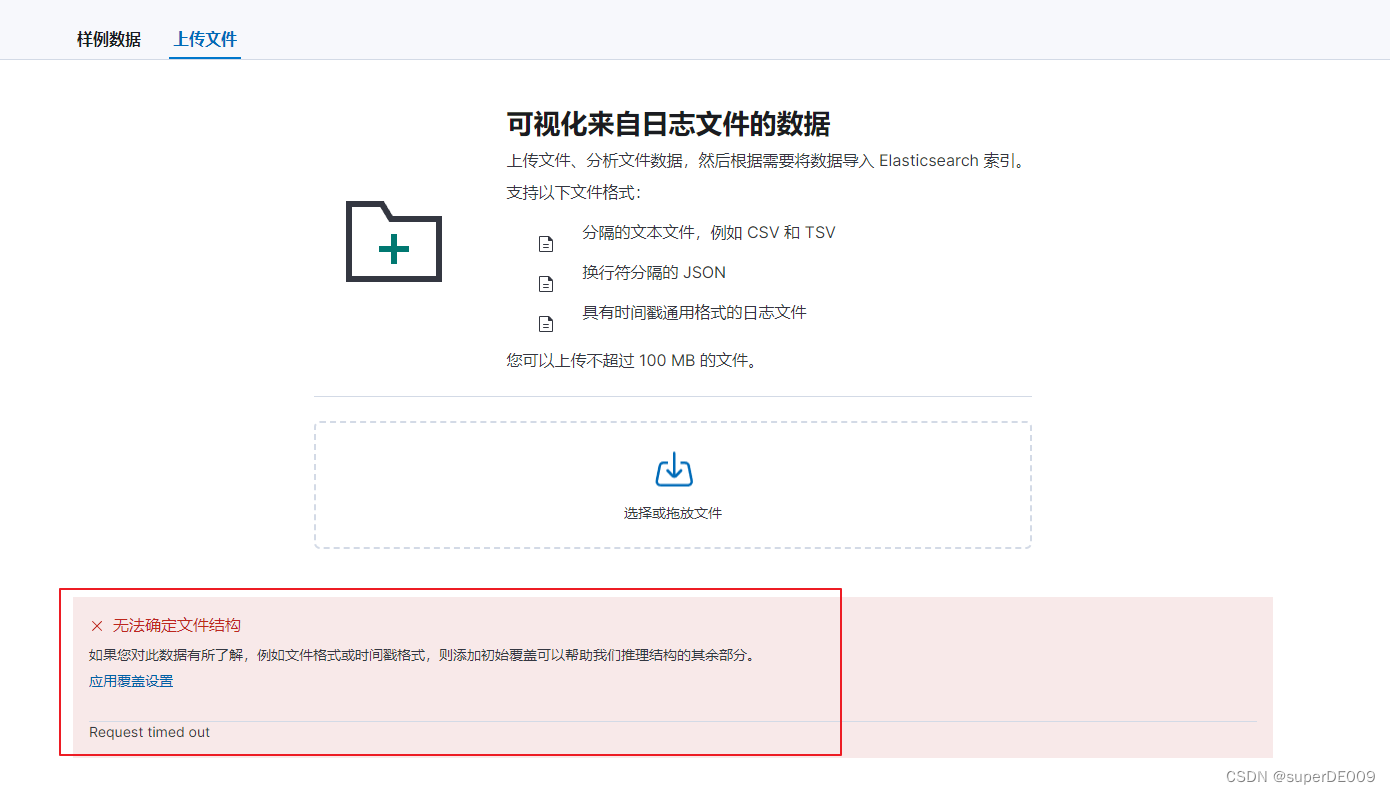
再次查看,发现CPU又100%负载了。并且之前的structurefinder进程又出现:
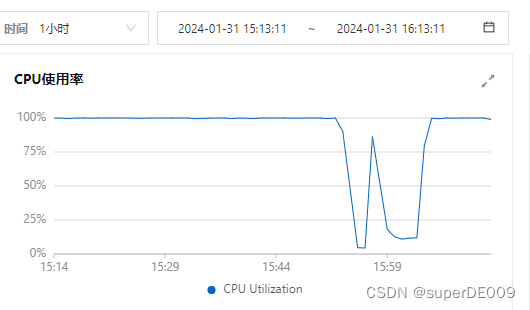

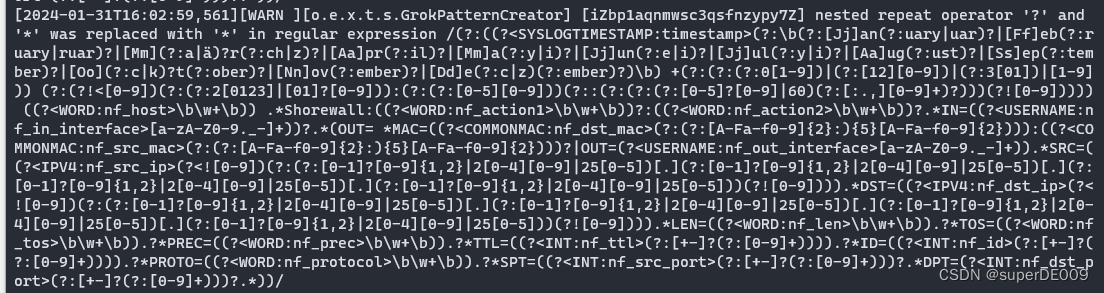
导致问题的原因。
那么基本可以确定,就是在解析上传的文件时,通过grok尝试解析,失败后,却没有关闭进程。从而导致CPU不断被占用。
而上图UI界面中返回的Request:time out 基本可以确定是structurefinder在尝试解析json内容时,花费的时间太久从而返回的time out。
json导入规则问题
只是问题是,为什么我的json文件,会解析这么久,并且仍然没有结束。上午的解析进程,最长的一个运行了近6个消失,但是仍然没有结果。
我的json文件,是python直接dump出来的,并且json格式校验也没有问题。
json导入规则问题解决
因为es要求的上传的json格式为ndjson。即换行符分割的json,每一行都是一个完整的json对象。
而我上传的,只是传统json格式,导致无法解析。
中英文非ndjson格式数据上传问题
仍然还有一个问题没有解决:
当一个英文的非ndjson格式的json被上传时,会报错非ndjson格式。直接返回,没有timeout
当一个unicode中文的非ndjson的json被上传时,会直接无限等待,导致CPU100%占用,返回timeout。并且后台持续存在一个task在进行解析,并且不结束,占用CPU100%
中英文非ndjson格式数据问题解决
我又去看了一遍hot_thread,可以看到这里的进程中,主要的函数是log Text Structure Finder。即对log的格式解析。
在上传文件时,es有明确,可以上传带标准时间戳格式的log问题。

由此推测:当unicode的json被上传后,不符合ndjson,但是不知为何,被当作了log去解析,而又并非log,导致了一些奇奇怪怪的bug,导致解析的进程无限等待,并没有进入任何一个错误返回。从而导致timeout,同时解析的进程卡死,CPU占用100%
而英文可能更方便,所以并没有触发这个bug。
reference
https://www.elastic.co/guide/en/elasticsearch/reference/8.12/high-cpu-usage.html#high-cpu-usage
聊聊 Elasticsearch 中的任务管理机制
red-yellow-cluster-status
你所不知道的ndJSON:序列化与管道流
附录
elasticsearch,index基本数据格式
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": "simple" //整个index使用的analyzer
},
"default_search": {
"type": "whitespace" //默认对这个index的搜索关键字使用的analyzer 也就是分词,tokenizer+去停用词等操作。
}
}
},
"number_of_shards": 3,// 分片存储,将数据分块,存储在集群中,搜索时,将请求发向对应的分片,类似hadoop(也能增加搜索时的并行性)
"number_of_replicas": 1 // 副本,即整个集群上,不同机器中存储副本。默认为1,即有一个副本,但是,副本必须存在不同的机器上,单node,多余的副本会无法被alloc,导致node状态为yellow
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_smart" //对单个field定义分析器,仅对该field生效。
},
"field1": {
"type": "keyword"
},
"field2": {
"type": "date"
}
}
}
}
elasticsearch的analyzer
analyzer主要做分词,去除停用词等数据预处理的工作。
默认有一个standard,whitespace,simple,等
分别对应不同的分词方法。
但是,都不支持中文分词,所以,只用中文文本数据,一定要使用ik分词的插件,否则分词效果差会非常影响搜索的准确性。
具体安装配置IK分词器的方法详见:
ElasticSearch中文分词