手把手+零基础带你玩转大数据流式处理引擎Flink(运行机制+原理加深)
- 前提介绍
- 运行Flink应用
- 运行机制
- Flink的两大核心组件
- JobManager
- TaskManager
- TaskSlot
- Flink分层架构
- Stateful Stream Processing
- DataStream和DataSet
- DataStream(数据流)
- 特点
- DataSet(数据集):
- 特点
- Table SQL
- DataStream API 编程模型
- 批处理
- 流处理
- 流式处理系统
- 流处理系统的特点
- DAG图
- 物理模型并行计算
前提介绍
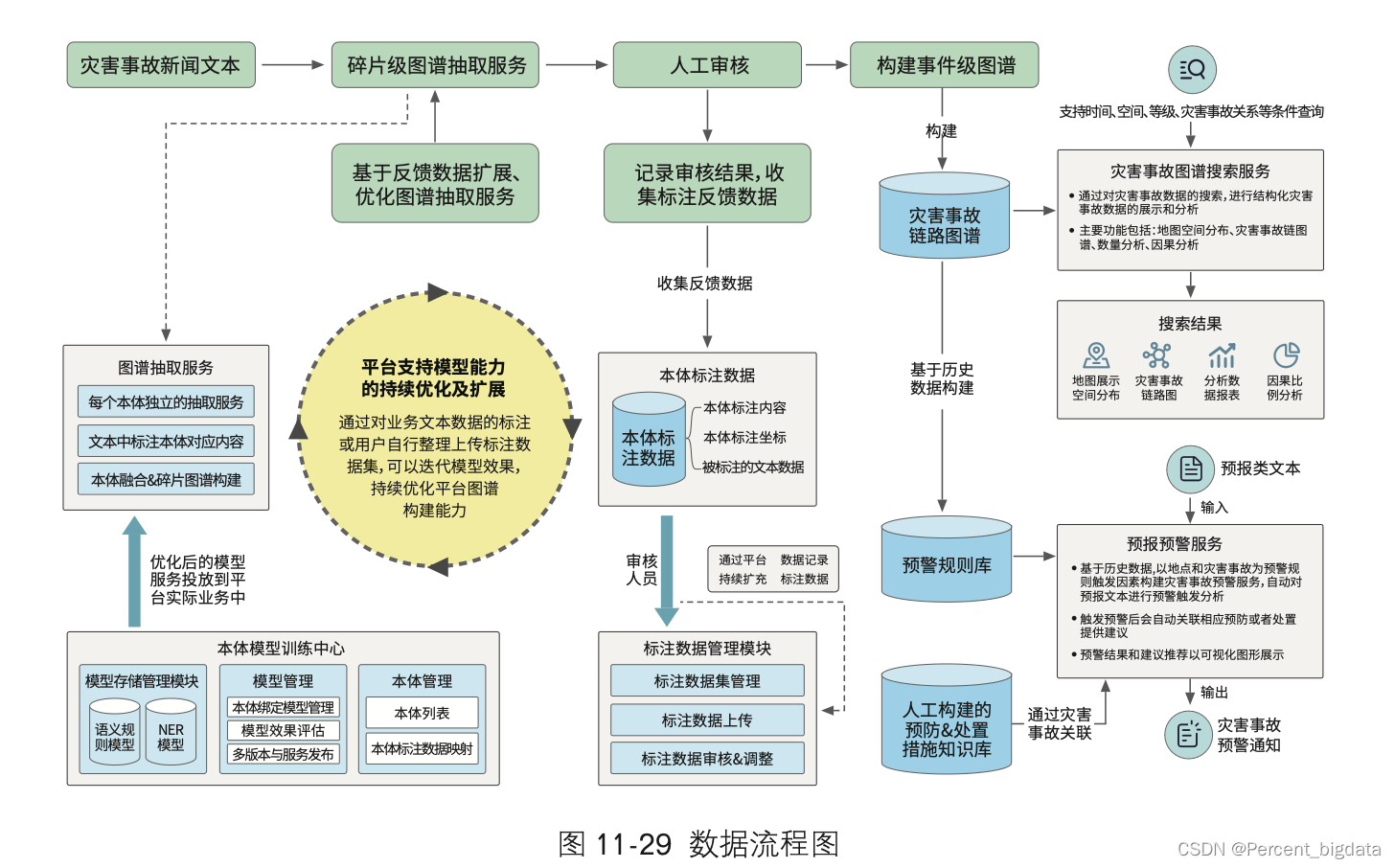
关于Flink服务的搭建与部署,由于其涉及诸多实战操作而理论部分相对较少,小编打算采用一个独立的版本和环境来进行详尽的实战讲解。考虑到文字描述可能无法充分展现操作的细节和流程,我们决定以视频的形式进行分析和介绍。因此,在本文中,我们将暂时不涉及具体的搭建和部署步骤。
为确保大家能够更直观地掌握Flink服务的搭建与部署技巧,我们将专注于制作高质量的教学视频。后续,我们还会编写一篇与视频内容相辅相成的辅助教材,以帮助大家更好地理解和巩固所学知识。目前,我们的首要任务是录制部署视频,敬请期待!
运行Flink应用
在运行Flink应用之前,深入了解其运行时组件是必不可少的环节,因为这些组件的配置直接关系到应用的性能和稳定性。
运行机制
在Flink的分布式计算框架中,Task是其资源调度的最小单位。正确理解和配置这些组件,对于确保Flink应用的稳定运行和高效性能至关重要。如下图所示:
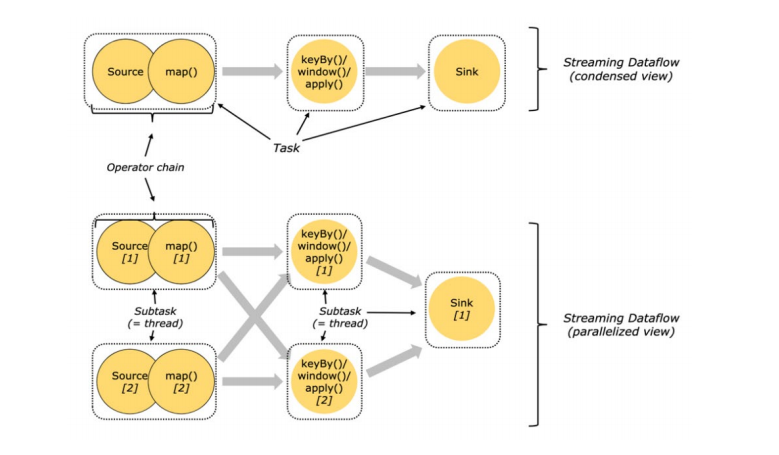
上图所展示的是一个使用DataStream API编写的数据处理程序。在图中,我们可以清晰地看到,那些无法被串联在一起的Operator被分隔到了不同的Task中。
Flink的两大核心组件
Flink作为流处理领域的佼佼者,其高效稳定的运行离不开两大核心组件的密切协作:JobManager和TaskManager。它们各司其职,共同支撑着整个Flink运作体系的顺畅运行,如下图所示:

JobManager
JobManager(也被称作JobMaster)是Flink作业执行的“大脑”,负责协调Task的分布式执行。具体来说,它会负责调度Task,确保它们在集群中的各个节点上按计划执行。
负责协调创建Checkpoint,这是Flink的容错机制之一,用于在作业发生故障时能够恢复到之前的状态。当Job发生failover时,JobManager会协调各个Task从最近的Checkpoint恢复,确保作业的持续执行。
TaskManager
TaskManager(也被称作Worker)则是Flink作业执行的“手脚”,负责具体执行Dataflow中的Tasks。它会分配内存Buffer,确保数据在各个Task之间高效传递。
执行Data Stream的处理逻辑,包括数据的接收、处理和发送等。通过多个TaskManager的并行执行,Flink能够实现大规模数据的实时处理和分析。
下面时JobManager和TaskManager连个核心组件的整体合作处理的架构图:

TaskSlot
从下面的图中可以看出来Task Slot是TaskManager中的最小资源分配单位,它决定了TaskManager能够支持的并发Task处理数量。
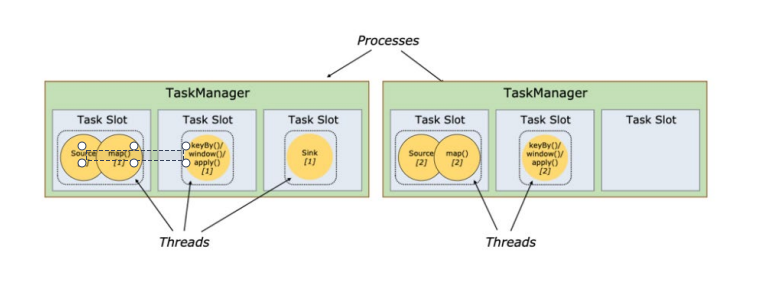
一个TaskManager中的Task Slot数量直接影响到其并发处理能力和资源利用率。通过合理配置Task Slot的数量,可以根据实际需求调整TaskManager的工作负载,从而实现更高效的任务处理和资源利用。
Flink分层架构

Stateful Stream Processing
Flink的分层架构分析,位于架构的最底层核心部分,ProcessFunction扮演着实现Flink Core API基础逻辑的关键角色。它提供了直接操作和处理流数据流的底层接口,使得开发者能够基于此构建出高度定制化的组件或功能模块,例如通过巧妙利用其内置的定时机制进行特定条件下的数据匹配与缓存。
尽管ProcessFunction带来了无可比拟的灵活性,允许对数据流处理过程进行细粒度控制,但同时也意味着开发工作相对复杂,需要对Flink的工作原理和并行计算有深入理解才能更好地驾驭这一强大工具。
DataStream和DataSet
DataStream 和 DataSet 是两个核心概念。它们是 Flink 中用于处理数据的两种不同的抽象。

- DataStream:适用于处理连续的实时数据流,提供了丰富的流处理操作符和函数,可以实现实时流处理的需求;
- DataSet:适用于处理有限的离线数据集,提供了丰富的批处理操作符和函数,可以实现离线数据处理的需求。
DataStream(数据流)
DataStream 是 Flink 中处理连续流数据的抽象。它表示无限的数据流,可以是来自消息队列、日志文件、传感器等源的实时数据。
特点
- 有序的、可变长度的数据记录序列,每个记录都包含一个或多个字段。每个记录都有一个时间戳,用于指示记录的时间顺序。
- 丰富的操作符和函数,可以对数据流进行转换、过滤、聚合等操作。可以通过窗口操作来处理有限大小的数据窗口,也可以进行流处理的时间语义控制。
- 基于事件时间(Event Time)或处理时间(Processing Time)进行处理的,可以实现事件驱动的流处理。
DataSet(数据集):
DataSet 是 Flink 中处理有限数据集的抽象。它表示有限的、静态的数据集合,可以是来自文件、数据库、批处理作业等离线数据。
特点
- 不可变的、有限长度的数据集合,每个数据集合由一组记录组成,每个记录都包含一个或多个字段。
- 丰富的操作符和函数,可以对数据集进行转换、过滤、聚合等操作。可以通过分组、排序、连接等操作来处理数据集。
- 基于批处理模式进行处理的,适用于离线数据处理和批处理作业。
Table SQL
- SQL 是基于 Table 的,因此在使用 SQL 之前需要创建一个 Table 环境。
- 不同类型的 Table 需要使用相应的 Table 环境进行构建。
- Table 可以与 DataStream 或 DataSet 相互转换,这使得我们可以在流处理和批处理之间无缝切换。
- Streaming SQL 与存储的 SQL 有所不同,它会被转化为流式执行计划,以实现实时流处理的需求。
后面的章节会针对性详细介绍,此处大概了解就可以了。
DataStream API 编程模型
流处理和批处理是大数据处理中的两个核心概念,它们从不同的角度对数据进行处理。它们的关系可以类比于 Java 中的 ArrayList 中的元素,可以通过下标直接访问,也可以通过迭代器进行访问。
批处理
批处理是对有限的静态数据集进行处理的方式。它以批量的方式处理数据,数据是一次性加载并进行处理。批处理适用于离线数据处理和批量作业,如数据清洗、数据分析等。在批处理中,数据被视为有限的数据集合,可以通过分组、排序、连接等操作进行处理。
流处理
流处理是对连续的实时数据流进行处理的方式。它以事件驱动的方式处理数据,数据是逐个到达的,并且可以立即进行处理。流处理适用于实时性要求较高的场景,如实时监控、实时分析等。在流处理中,数据被视为无限的流,可以通过窗口操作来处理有限大小的数据窗口。
流式处理系统
流处理系统具有许多独特的特点。通常情况下,由于需要处理无限数据集,流处理系统采用一种数据驱动的处理方式。它会预先设置一些算子,并在数据到达时对数据进行处理。
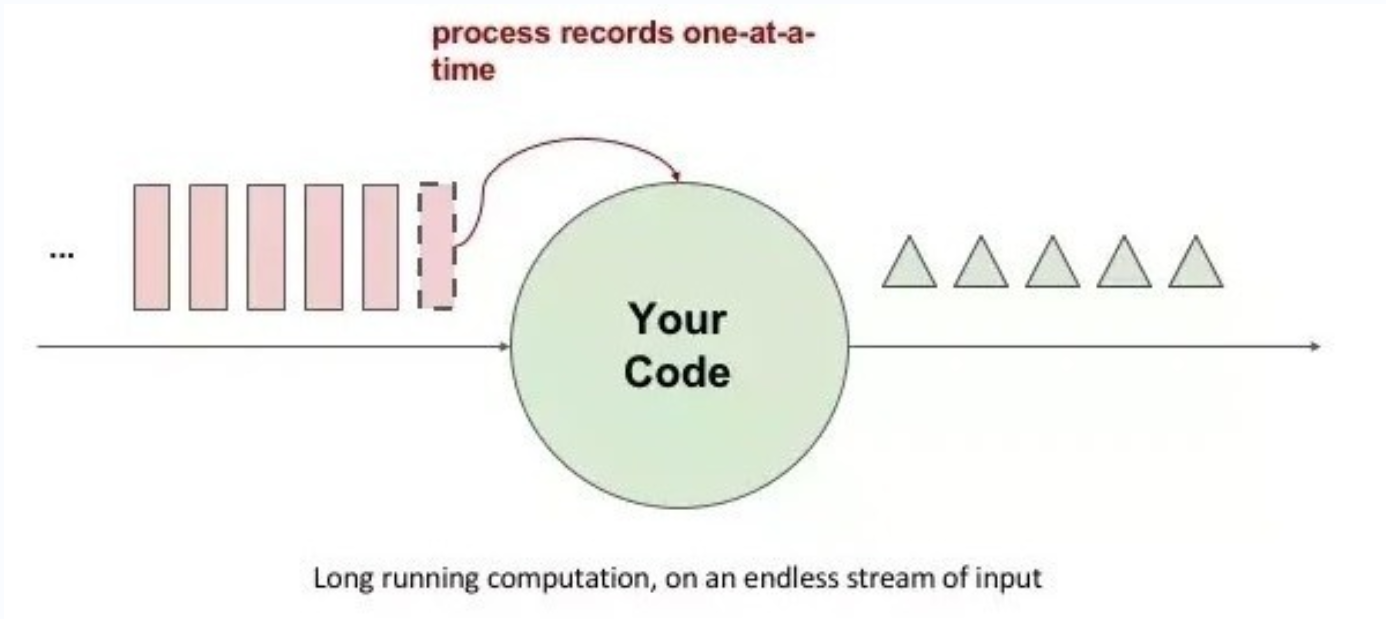
流处理系统的特点
- 实时处理:流处理系统能够实时处理连续的数据流,数据到达后立即进行处理,实现实时性要求较高的应用场景。
- 无限数据集:流处理系统能够处理无限的数据流,不受数据大小的限制。它能够处理持续不断产生的数据,而不需要等待所有数据都可用。
- 数据驱动:流处理系统是以数据为驱动的,即数据到达时才进行处理。系统会根据数据的到达情况来触发相应的处理操作,而不是按照固定的时间间隔进行处理。
DAG图
为了表达复杂的计算逻辑,包括 Flink 在内的分布式流处理引擎一般采用DAG图来表示整个计算逻辑,其中 DAG 图中的每一个点就代表一个基本的逻辑单元,也就是算子。
由于计算逻辑被组织成有向图,数据会按照边的方向,从一些特殊的 Source 节点流入系统,然后通过网络传输、本地传输等不同的数据传输方式在算子之间进行发送和处理,最后会通过另外一些特殊的 Sink 节点将计算结果发送到某个外部系统或数据库中,下面是执行计划的DAG逻辑图
物理模型并行计算
在物理模型中,我们根据计算逻辑的需求,通过系统自动优化或人为指定的方式将计算工作分布到不同的实例中。只有当算子实例分布到不同的进程上时,才需要通过网络进行数据传输。而在同一进程中的多个实例之间的数据传输通常是不需要通过网络的。
通过将计算工作分布到不同的实例中,可以实现并行计算和分布式处理,以提高整体的计算性能和吞吐量。在分布式流处理引擎中,系统会根据算子的并行度和资源配置,将算子实例分布到不同的计算节点上,使得每个实例可以独立地处理数据。
对于实际的分布式流处理引擎,它们的实际运行时物理模型要更复杂一些,这是由于每个算子都可能有多个实例。如下图所示:
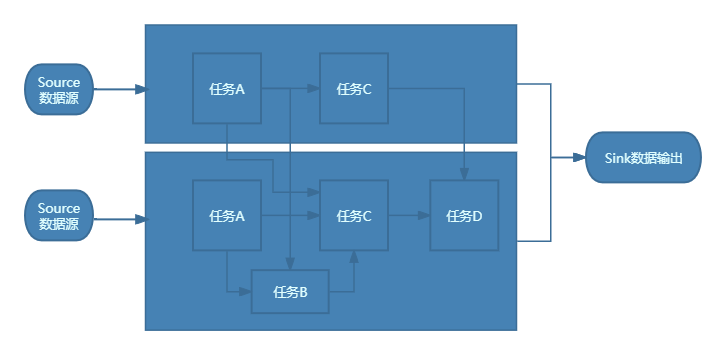
在实际的分布式流处理引擎中,物理模型比逻辑模型更加复杂。这种复杂性是由于分布式流处理引擎的并行性和分布式计算的特性所导致的。为了实现高吞吐量和低延迟的数据处理,引擎会将算子实例分布在多个计算节点上,并通过网络进行数据交换和通信。
例如,图中的算子 A 作为数据源有两个实例,而中间算子 C 也有两个实例。在逻辑模型中,A 和 B 是 C 的上游节点,但在物理模型中,C 的每个实例与 A 和 B 的每个实例之间都可能存在数据交换。
当算子实例分布到不同的进程上时,数据传输就会发生。这时,需要通过网络进行数据的传输和交换。而在同一进程中的多个实例之间,数据传输通常是通过共享内存或进程间通信的方式进行,而不需要通过网络。


![[python] os.fork](https://img-blog.csdnimg.cn/direct/03980548ee644be2ab86a045756628d9.png)