目录
数据增强方法
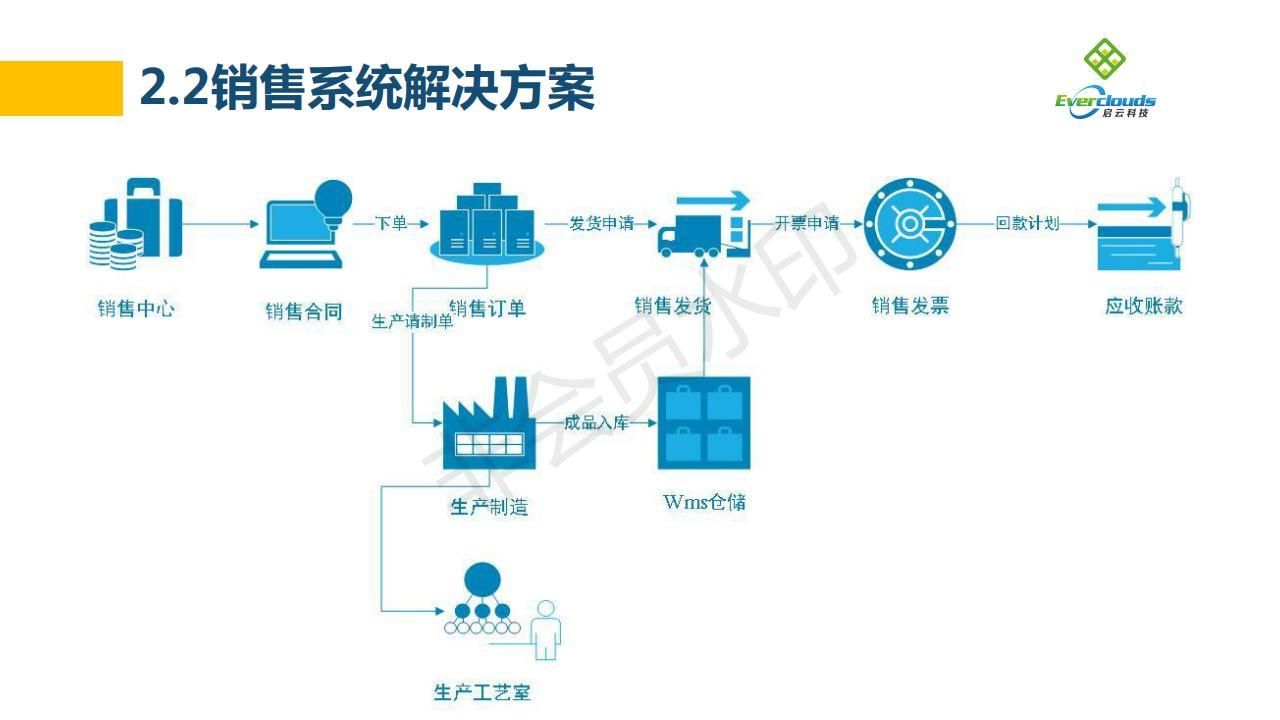
CNN图像分类数据集构建
导入数据集
定义trainer
超参数设置
数据增强
构建CNN网络
开始训练
模型测试
数据增强方法
# 一般情况下,我们不会在验证集和测试集上做数据扩增
# 我们只需要将图片裁剪成同样的大小并装换成Tensor就行
test_tfm = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
])
# 当然,我们也可以再测试集中对数据进行扩增(对同样本的不同装换)
# - 用训练数据的装化方法(train_tfm)去对测试集数据进行转化,产出扩增样本
# - 对同个照片的不同样本分别进行预测
# - 最后可以用soft vote / hard vote 等集成方法输出最后的预测
train_tfm = transforms.Compose([
# 图片裁剪 (height = width = 128)
transforms.Resize((128, 128)),
transforms.AutoAugment(transforms.AutoAugmentPolicy.IMAGENET),
# ToTensor() 放在所有处理的最后
transforms.ToTensor(),
])CNN图像分类数据集构建
class FoodDataset(Dataset):
# 构造函数
def __init__(self, path, tfm=test_tfm, files=None):
# 调用父类的构造函数
super(FoodDataset).__init__()
# 存储图像文件夹路径
self.path = path
# 从路径中获取所有以.jpg结尾的文件,并按字典顺序排序
self.files = sorted([os.path.join(path, x) for x in os.listdir(path) if x.endswith(".jpg")])
# 如果提供了文件列表,则使用该列表代替自动搜索得到的列表
if files is not None:
self.files = files
# 打印路径中的一个样本文件路径
print(f"One {path} sample", self.files[0])
# 存储用于图像变换的函数
self.transform = tfm
# 返回数据集中的样本数
def __len__(self):
return len(self.files)
# 根据索引获取单个样本
def __getitem__(self, idx):
# 获取文件名
fname = self.files[idx]
# 打开图像文件
im = Image.open(fname)
# 应用变换
im = self.transform(im)
# 尝试从文件名中提取标签,如果失败则设置为-1(表示测试集中没有标签)
try:
label = int(fname.split("/")[-1].split("_")[0])
except:
label = -1 # 测试集没有label
# 返回图像和标签
return im, label导入数据集
注意这里的“私有方法”
_dataset_dir = config['dataset_dir']#“_”是为了避免和python中的dataset重名
train_set = FoodDataset(os.path.join(_dataset_dir,"training"), tfm=train_tfm)
train_loader = DataLoader(train_set, batch_size=config['batch_size'],
shuffle=True, num_workers=0, pin_memory=True)
valid_set = FoodDataset(os.path.join(_dataset_dir,"validation"), tfm=test_tfm)
valid_loader = DataLoader(valid_set, batch_size=config['batch_size'],
shuffle=True, num_workers=0, pin_memory=True)
# 测试级保证输出顺序一致
test_set = FoodDataset(os.path.join(_dataset_dir,"test"), tfm=test_tfm)
test_loader = DataLoader(test_set, batch_size=config['batch_size'],
shuffle=False, num_workers=0, pin_memory=True)定义trainer
def trainer(train_loader, valid_loader, model, config, device, rest_net_flag=False):
# 定义交叉熵损失函数,用于评估分类任务的模型性能
criterion = nn.CrossEntropyLoss()
# 初始化优化器,这里使用Adam优化器
optimizer = torch.optim.Adam(model.parameters(), lr=config['learning_rate'], weight_decay=config['weight_decay'])
# 根据rest_net_flag标志选择模型保存路径
save_path = config['save_path'] if rest_net_flag else config['resnet_save_path']
# 初始化TensorBoard的SummaryWriter,用于记录训练过程
writer = SummaryWriter()
# 如果'models'目录不存在,则创建该目录
if not os.path.isdir('./models'):
os.mkdir('./models')
# 初始化训练参数:训练轮数、最佳损失、步骤计数器和早停计数器
n_epochs, best_loss, step, early_stop_count = config['n_epochs'], math.inf, 0, 0
# 进行多个训练周期
for epoch in range(n_epochs):
# 设置模型为训练模式
model.train()
# 初始化损失记录器和准确率记录器
loss_record = []
train_accs = []
# 使用tqdm显示训练进度条
train_pbar = tqdm(train_loader, position=0, leave=True)
# 遍历训练数据
for x, y in train_pbar:
# 重置优化器梯度
optimizer.zero_grad()
# 将数据和标签移动到指定设备(如GPU)
x, y = x.to(device), y.to(device)
# 进行一次前向传播
pred = model(x)
# 计算损失
loss = criterion(pred, y)
# 反向传播
loss.backward()
# 如果启用梯度裁剪,则应用梯度裁剪
if config['clip_flag']:
grad_norm = nn.utils.clip_grad_norm_(model.parameters(), max_norm=10)
# 进行一步优化(梯度下降)
optimizer.step()
# 记录当前步骤
step += 1
# 计算准确率并记录损失和准确率
acc = (pred.argmax(dim=-1) == y.to(device)).float().mean()
l_ = loss.detach().item()
loss_record.append(l_)
train_accs.append(acc.detach().item())
train_pbar.set_description(f'Epoch [{epoch+1}/{n_epochs}]')
train_pbar.set_postfix({'loss': f'{l_:.5f}', 'acc': f'{acc:.5f}'})
# 计算并记录平均训练损失和准确率
mean_train_acc = sum(train_accs) / len(train_accs)
mean_train_loss = sum(loss_record) / len(loss_record)
writer.add_scalar('Loss/train', mean_train_loss, step)
writer.add_scalar('ACC/train', mean_train_acc, step)
# 设置模型为评估模式
model.eval()
# 初始化验证集损失记录器和准确率记录器
loss_record = []
test_accs = []
# 遍历验证数据
for x, y in valid_loader:
x, y = x.to(device), y.to(device)
with torch.no_grad():
pred = model(x)
loss = criterion(pred, y)
acc = (pred.argmax(dim=-1) == y.to(device)).float().mean()
loss_record.append(loss.item())
test_accs.append(acc.detach().item())
# 计算并打印平均验证损失和准确率
mean_valid_acc = sum(test_accs) / len(test_accs)
mean_valid_loss = sum(loss_record) / len(loss_record)
print(f'Epoch [{epoch+1}/{n_epochs}]: Train loss: {mean_train_loss:.4f}, acc: {mean_train_acc:.4f} Valid loss: {mean_valid_loss:.4f}, acc: {mean
超参数设置
device = 'cuda' if torch.cuda.is_available() else 'cpu'
config = {
'seed': 6666,
'dataset_dir': "../input/data",
'n_epochs': 10,
'batch_size': 64,
'learning_rate': 0.0003,
'weight_decay':1e-5,
'early_stop': 300,
'clip_flag': True,
'save_path': './models/model.ckpt',
'resnet_save_path': './models/resnet_model.ckpt'
}
print(device)
all_seed(config['seed'])数据增强
test_set = FoodDataset(os.path.join(_dataset_dir,"test"), tfm=train_tfm)
test_loader_extra1 = DataLoader(test_set, batch_size=config['batch_size'],
shuffle=False, num_workers=0, pin_memory=True)
test_set = FoodDataset(os.path.join(_dataset_dir,"test"), tfm=train_tfm)
test_loader_extra2 = DataLoader(test_set, batch_size=config['batch_size'],
shuffle=False, num_workers=0, pin_memory=True)
test_set = FoodDataset(os.path.join(_dataset_dir,"test"), tfm=train_tfm)
test_loader_extra3 = DataLoader(test_set, batch_size=config['batch_size'],
shuffle=False, num_workers=0, pin_memory=True)构建CNN网络
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
# input 維度 [3, 128, 128]
self.cnn = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), # [64, 128, 128]
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [64, 64, 64]
nn.Conv2d(64, 128, 3, 1, 1), # [128, 64, 64]
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [128, 32, 32]
nn.Conv2d(128, 256, 3, 1, 1), # [256, 32, 32]
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [256, 16, 16]
nn.Conv2d(256, 512, 3, 1, 1), # [512, 16, 16]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 8, 8]
nn.Conv2d(512, 512, 3, 1, 1), # [512, 8, 8]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 4, 4]
)
self.fc = nn.Sequential(
nn.Linear(512*4*4, 1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, 11)
)
def forward(self, x):
out = self.cnn(x)
out = out.view(out.size()[0], -1)
return self.fc(out)举一个具体的例子来解释:
out = out.view(out.size()[0], -1)。假设我们有一个4维的张量
out,其维度是[10, 3, 32, 32]。这个张量可以被理解为一个小批量(batch)的图像数据,其中:
10是批处理大小(batch size),表示有10个图像。3是通道数(channels),例如在RGB图像中有3个颜色通道。32和32是图像的高度和宽度。现在,我们想将这个4维张量转换为2维张量,以便它可以被用作全连接层(dense layer)的输入。这就是
out.view(out.size()[0], -1)用途所在。执行这个操作后,张量的形状将会是:
- 第一个维度仍然是10,这保持了批处理大小不变。
- 第二个维度是由
-1指定的,这让PyTorch自动计算这个维度的大小。在我们的例子中,其余的维度(3, 32, 32)将被展平,所以第二个维度的大小是 3 * 32 * 32 = 3072。因此,执行
out = out.view(out.size()[0], -1)后,out的形状将会从[10, 3, 32, 32]变为[10, 3072]。这个新的二维张量可以被看作是一个包含10个样本的数据批次,每个样本都被展平为3072个特征的一维数组。这种形状的张量适合作为全连接层的输入。
1. Conv2d(卷积层)
卷积层的输出尺寸可以用以下公式计算:
其中:
- 输入尺寸是输入特征图的高度或宽度。
- 卷积核尺寸是卷积核的高度或宽度。
- 填充(Padding)是在输入特征图周围添加的零的层数。
- 步长(Stride)是卷积核移动的步幅。

2. MaxPool2d(最大池化层)
最大池化层的输出尺寸可以用类似的公式计算:
对于最大池化,通常不使用填充。

假设我们有一个大小为
[32, 32](高度32,宽度32)的输入特征图,并且我们想应用以下两个层:
Conv2d层,卷积核大小为[3, 3],步长为1,填充为1。MaxPool2d层,池化核大小为[2, 2],步长为2。对于
Conv2d层,输出尺寸计算如下:
对于
MaxPool2d层,输出尺寸计算如下:
所以,经过这两层处理后,最终输出的特征图尺寸将会是
[16, 16]。
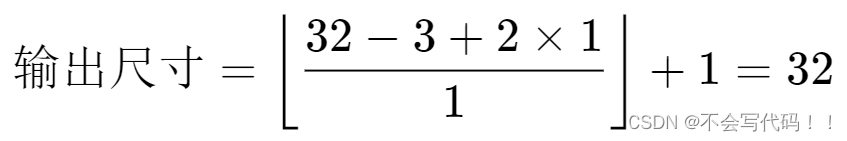
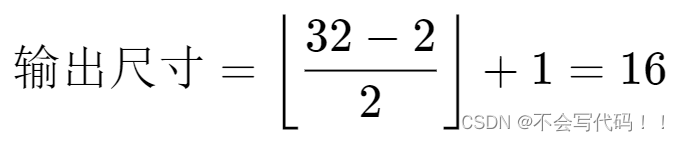
开始训练
model = Classifier().to(device)
trainer(train_loader, valid_loader, model, config, device)或者可以通过调用pytorch官方的一些标准model进行训
from torchvision.models import resnet50
resNet = resnet50(pretrained=False)
# 残差网络
resNet = resNet.to(device)
trainer(train_loader, valid_loader, resNet, config, device)模型测试
model_best = Classifier().to(device)
model_best.load_state_dict(torch.load(config['save_path']))
model_best.eval()
prediction = []
with torch.no_grad():
for data,_ in test_loader:
test_pred = model_best(data.to(device))
test_label = np.argmax(test_pred.cpu().data.numpy(), axis=1)
prediction += test_label.squeeze().tolist()