数据是大模型的基石。但传统的数据集创建方法通常依赖人工,耗时耗力成本高,另外数据集的来源复杂,噪声大,比如新闻媒体稿或者社交媒体,数据质量难以保证。为此,IBM研究院了一种名为Genie的新方法,可以自动生成高质量的数据。
作者生成了三个大规模的合成数据,包含长篇问答(LFQA)、摘要和信息提取(IE)。通过人类评估,合成数据是自然且高质量的,可与人类标注数据相媲美的。此外,作者还将基于合成数据 训练的模型与基于人工撰写的数据训练的模型进行比较,其中,LFQA使用ELI5和ASQA数据,摘要使用CNN-DailyMail数据。结果显示合成数据训练模甚至超过基于人工生成数据训练的模型。
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接!
论文标题:
Genie: Achieving Human Parity In Content-Grounded Datasets Generation
论文链接为:
https://arxiv.org/pdf/2401.14367.pdf
Genie方法介绍
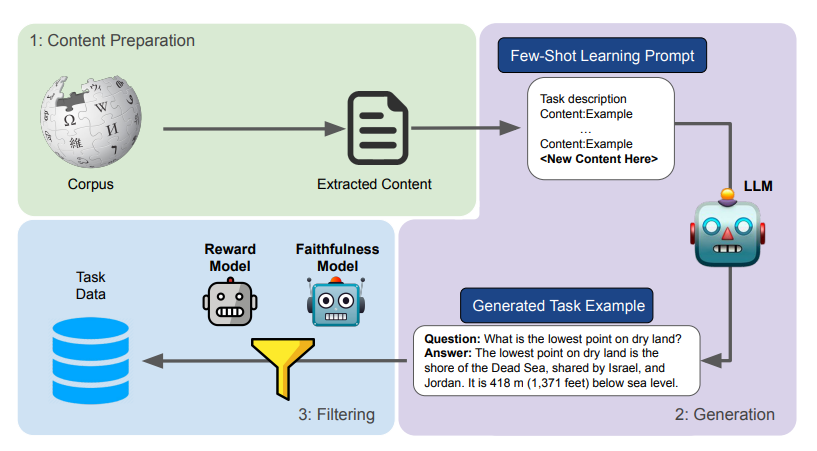
▲image.png
如上图概述了Genie方法的全过程,包含三个主要阶段:
-
在内容准备阶段,研究人员从原始文档中提取出有用的内容段落。
-
在生成阶段,提示LLM根据提供的内容,生成特定于任务的示例。
-
过滤阶段,通过评分机制筛选出低质量和不忠实的例子,以确保数据的质量。
内容准备:从原始数据中提取内容
1. 数据来源与处理细节
在内容准备阶段,研究人员通过基于规则的方式从原始文档中提取内容。例如,使用浏览器仿真技术爬取维基百科页面,以获取动态内容。然后,通过过滤器去除HTML DOM中的噪声(如头部、页脚、侧边栏等),保留主要页面内容。
2. 从网页到Markdown的转换
保留的主要页面内容随后被转换为Markdown格式,以保持文档结构(如列表、表格、链接、图片引用、文章和章节)。基于此结构,研究人员派生出目录,并据此将Markdown页面分解为段落,为后续的生成阶段做好准备。
生成阶段:利用大型语言模型生成合成示例
通过精心设计的提示方法,采用少样本提示,模型根据给定的上下文生成特定任务的示例,比如下图是一个问答任务数据生成的示例。本文使用了两种不同的模型来生成数据:Falcon-40B和Llama-2-70B。值得注意的是,Falcon模型是纯粹的预训练模型,没有额外的对齐和指导步骤,本文主要报告了依赖Falcon的结果,以展示该方法不依赖于进一步的对齐和指导步骤。

▲image.png
过滤机制:确保数据质量和忠实度
为了确保生成数据的质量和忠实度,对每个内容-示例对进行了评分,并过滤掉得分低的对。
-
格式方面:作者过滤了缺少模板部分的示例,例如在问答任务中缺少标志问题开始或回答开始的前缀。此外,还过滤了过短(少于十个词)或过长(超过基准内容长度1.5倍的长文本问答,以及超过0.25倍的摘要)的示例。
-
在忠实度方面,通过将问题映射为文本蕴含或自然语言推理问题,并通过微调的T5-11B NLI模型来评估生成示例的忠实度。
-
在质量方面,使用了基于人类偏好数据训练的奖励模型来自动评估生成示例的质量。使用Open-Assistant模型(基于DeBERTa-v3架构),并过滤掉奖励模型评分低于0.5的生成示例。同时,还使用了T5模型来过滤掉被认为不忠实的示例。
实验设置
1. 数据集
作者使用了ELI5、ASQA、Natural Questions、CNN-DailyMail,并生成了wish-QA、wish-summarization和wish-IE等合成数据集。
-
ELI5:由Reddit论坛上同名帖子的用户提出的开放性问题和详细回答组成的。对于这些问题和回答,还添加了检索到的文档作为基础内容。
-
ASQA:是一个将来自AmbigQA数据集的模棱两可问题与经过精心设计的通过群众众包生成的长篇答案进行配对的数据集。
-
NQ:是一个从Google搜索引擎中获取的真实用户问题的数据集。它包括来自维基百科的问题及其相关段落(称为长答案),这些段落提供了潜在的答案并包含提取式的短答案。该数据集没有长篇答案,而我们将仅使用其文档进行合成数据生成过程,并将我们的合成问题与NQ中的问题进行比较。
-
CNN-DailyMail:是一个常用于文本摘要的数据集。它包含有来自CNN和DailyMail的新闻文章,以及人工撰写的摘要。
-
Wish-QA-NQ:利用NQ passages, 用于合成数据生成。这些passages非常适合,因为它们最初是由注释员从维基百科页面中提取出来的,通常包含以特定主题为中心的结构良好的段落。
-
Wish-QA ELI5/ASQA:为了创建一个模拟ELI5和ASQA条件的数据集,其中答案可以从多个文档中得出,依赖于来自相应语料库的前三个检索到的passages。这些passages被用作构建这个合成数据集的基础文档。
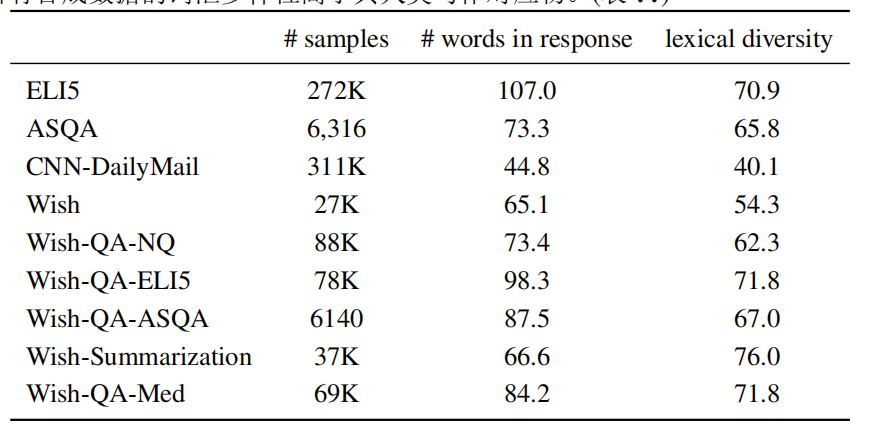
▲image.png
合成的数据包含超过300K个样本,与ELI5和CNN-DailyMail的规模相似,这些数据集是从可用资源中收集的,并且天生具有噪声。另一方面,合成数据比精心注释的ASQA数据大50倍。并且大多数回应的长度与人类写作数据集中的长度相似,而所有合成数据的词汇多样性高于其人类注释的。
2. 模型
为了公平对比在合成的内容相关数据上训练得到的模型与那些在由人类生成的数据上训练得到的模型的性能。保持每个数据集中的示例数量相等,并使用相同的超参数来训练相同的模型。用于训练的模型是Flan-xl 和llama-2-13b-Chat 。
3. 评价指标
作者采用ROUGE作为词汇相似性度量、BERT-Score作为基于模型的参考度量、奖励模型作为基于模型的无参考度量。此外,还使用了ANLI忠实度度量和奖励模型进行评估。为了评估忠实度,还计算了K-Precision词汇相似性度量。在初步试验中,不同的性能度量显示了相似的结果,这表明了不同形式的可靠性。
合成数据评估
本文将合成问题和人类问题并列呈现,对Wish-QA进行内在评估和验证。结果表明,合成生成的问题比大多数现有数据集中的问题更自然。我们还测试了整个工作流程,并展示了过滤器对生成数据质量的贡献,以及Genie在成本和时间上的高效性以及创建多样化数据。
1. 自然性评估
从ELI5、ASQA和NQ中随机选取了100个问题,以及它们的100个合成对应问题,进行人工评估。
对于ELI5,合成问题在72%的情况下被选为人工编写的问题,对于NQ,这个比例为63%,而对于ASQA,这个比例为49%。这些结果表明,合成问题比从Reddit和Google搜索引擎等来源收集到的问题更加自然和接近人类。此外,它们与专家编写的问题(例如ASQA数据集中的问题)几乎无法区分。
2. 多维度质量评估
为了调查生成数据的质量和过滤过程的影响,从未过滤和经过过滤的Wish-QA中随机选择了100个问题。对于每个内容-问题-答案三元组,要求标注员回答下表中显示的问题列表:

前两个评估问题旨在评估问题的相关性和清晰度。清晰度问题即自然事实性问题是否存在歧义。在此基础上,还包括了三个与答案质量有关的问题。这些问题旨在确定答案是否充分回答了问题,同时又忠实于底层内容。最后,要求在一个5级量表上给出总体质量评分。
表中结果显示,经过过滤后的数据质量在相关性、清晰度、与答案的相关度、忠实度都有明显提高,整体评分有所改善,这说明过滤过程对数据集的质量和忠实度有着重要的贡献。
3.多样性
合成数据基于大规模覆盖许多不同独特主题的内容。因此数据包含多样的词汇。作者使用vocd-D来衡量词汇多样性。
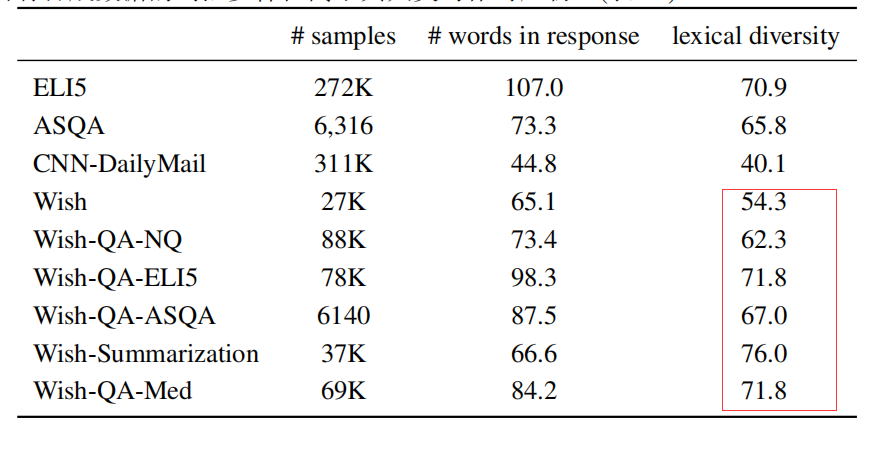
从上表中可以看到,所有合成数据的词汇多样性高于人为生成的对应数据,大部分回答的长度与人工编写数据集中的长度相似。
4. 时间与经济成本
Genie方法的自动化数据生成过程在效率和成本效益方面表现出色。传统的数据集策划通常需要昂贵且耗时的人工过程,而Genie方法可以快速生成大量数据,成本仅为传统方法的一小部分。例如,人工生成300K个例子的成本超过100万美元,而使用Genie方法则大大降低了这一成本。此外,Genie方法生成数据的速度远远超过人类阅读上下文并创建问题的速度,这意味着在更短的时间内可以生成更多的数据。
合成数据VS人类生成数据训练模型对比
在发现合成数据具有较高的质量后,作者还使用合成数据与人工生成数据分别在ASQA和ELI5测试集上训练模型,对比两种训练数据的差距。
下表是使用人工生成和合成数据训练Flan-xl模型的性能比较结果显示,根据ROUGE-L和Bert-Score指标,合成数据始终优于或实现了与人工生成数据相媲美的性能。此外,根据奖励分数,合成数据训练的模型在性能上可与金标准数据一校高下甚至更加优秀。
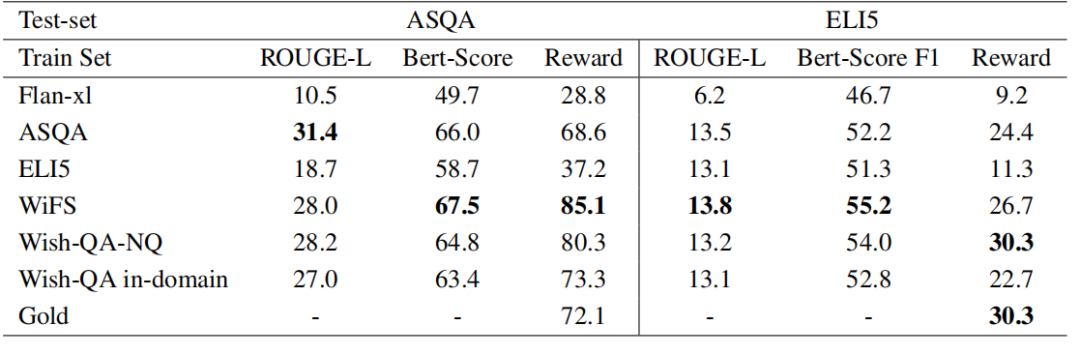
▲image.png
在忠实度方面,使用合成数据训练的模型比使用人类生成数据(如ELI5和ASQA)训练的模型更忠实于内容。结果显示,合成数据在k-Precision和ANLI指标中始终优于人工生成数据和金标准回答。Flan-xl以最高的得分脱颖而出,这可能是其回答更加简短且几乎是抽取式的结果。
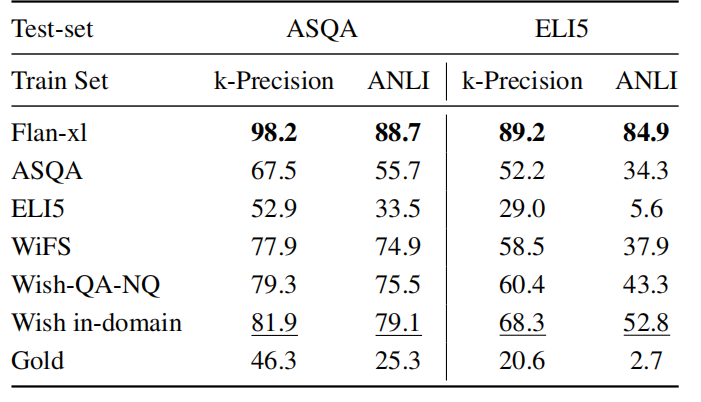
▲image.png
域适应性:在医疗领域的应用
1. 生成目标领域合成数据的假设
我们提出了一个假设,即在目标领域内生成合成数据可能比从其他领域生成同一任务的数据更有效。为了验证这一假设,作者定义了一个以PubMed-QA为基础的医疗领域LFQA任务测试集,并创建了相应领域的合成问答数据(Wish-QA-MED)。然后对比三大数据集训练的模型性能,分别是Wish-QA-MED、Wish-QA-NQ以及人类创建数据集ELI5和ASQA数据集。
2. Wish-QA-MED数据集的表现
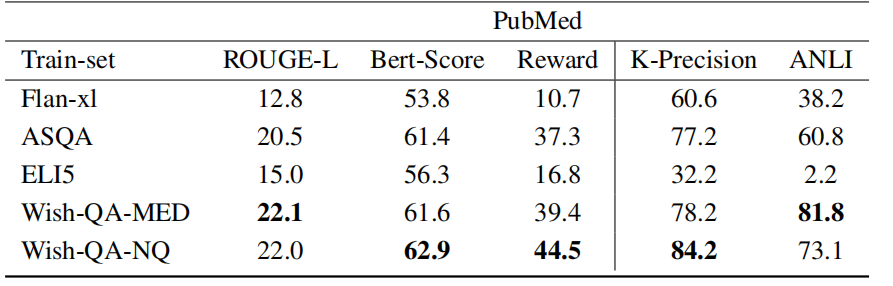
▲image.png
-
Wish-QA-MED数据集在ROUGE-L和Bert-Score上的表现与ASQA相当或略好。
-
Wish-QA-NQ和Wish-QA-MED取得了相似的结果,这表明领域外数据与领域内数据相比几乎没有劣势,甚至域外数据往往能超越领域内数据。这可能意味着,提供任务内容(例如QA)使模型对训练领域的依赖减少。
-
尽管忠实度分数并不确定,但ANLI指标表明领域内合成数据在提高忠实度方面有所改善,而k-Precision则表明至少与领域外数据持平。
总结
Genie方法的创新之处在于其自动化的数据生成过程和确保数据质量的过滤机制。这一方法不仅提高了数据生成的效率和成本效益,还通过生成高质量和真实性的数据,推动了内容聚焦的数据集和模型的发展。Genie方法的成功应用在LFQA、摘要和信息提取等任务中展示了其广泛的适用性和潜力。
未来的研究可以从Genie方法的基础上进一步探索如何优化数据生成和过滤过程,以及如何将这一方法应用到更多的领域和任务中。此外,研究者们还可以探索如何利用合成数据提高模型在特定领域内的表现,以及如何通过提高数据的真实性来解决长篇问答等任务中的挑战。总之,Genie方法为未来的研究提供了新的视角和启示,有望推动内容驱动的生成任务向前发展。
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接!