大家好,我是 方圆。本文介绍线性排序,即时间复杂度为 O(n) 的排序算法,包括桶排序,计数排序和基数排序,它们都不是基于比较的排序算法,大家重点关注一下这些算法的适用场景。
桶排序
桶排序是分治策略的一个典型应用。它通过设置一些具有大小顺序的桶,每个桶对应一个数据范围,将数据平均分配到各个桶中;然后,在每个桶内部分别执行排序;最终按照桶的顺序将所有数据依次取出合并,组成的序列就是有序的了,如下图所示:
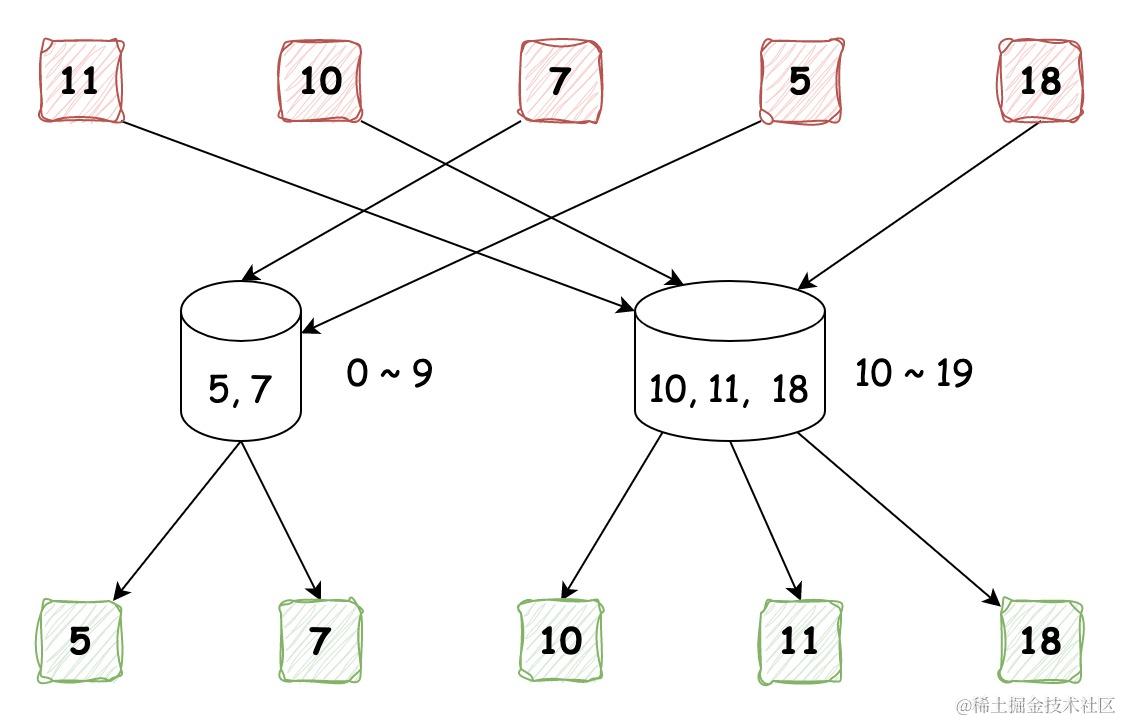
桶排序的算法流程我将其分成三个步骤:
-
初始化桶:以范围为 0 - 49 的数据为例,分为 5 个桶
-
分桶:将要排序数组中的元素加入桶中
-
出桶:该步骤需要在桶中完成排序后,依次出桶合并
/**
* 桶排序:指定数据范围为0 - 49,分桶为5个,每10个数为一个桶
*/
public void sort(int[] nums) {
// 声明5个桶
List<ArrayList<Integer>> buckets = new ArrayList<>();
for (int i = 0; i < 5; i++) {
buckets.add(new ArrayList<>());
}
// 数组元素分桶
intoBucket(buckets, nums);
// 出桶
outOfBucket(buckets, nums);
}
/**
* 分桶
*/
private void intoBucket(List<ArrayList<Integer>> buckets, int[] nums) {
for (int num : nums) {
int bucketIndex = num / 10;
buckets.get(bucketIndex).add(num);
}
}
/**
* 出桶
*/
private void outOfBucket(List<ArrayList<Integer>> buckets, int[] nums) {
// 出桶覆盖原数组值
int numsIndex = 0;
for (ArrayList<Integer> bucket : buckets) {
// 先排序 再出桶
bucket.sort(Comparator.comparingInt(x -> x));
for (Integer num : bucket) {
nums[numsIndex++] = num;
}
}
}
算法特性:
-
空间复杂度:O(n + k)
-
自适应排序:与桶划分情况和桶内使用的排序算法有关
-
稳定排序/非稳定排序:与桶内使用的排序算法有关
-
非原地排序
桶排序比较适用于 外部排序,所谓的外部排序就是数据存储在外部磁盘中,数据量很大,但是内存又有限,无法将所有数据全部加载进来,比如有 1G 的数据需要排序,但是内存只有几百MB的情况。我们可以根据数据范围将其划分到 N 个桶中,划分完成后每个桶的大小不超过可用内存大小,对每个桶内的数据进行排序,排序完成后生成 N 个小文件,最后我们再将这 N 个小文件写入到一个大文件中即可。如果数据在某些范围内并不是均匀分布的话,有些范围内的数据特别多,那么这就需要我们再对其划分成更细粒度的桶,直到满足内存的使用要求,但是这样我们的桶就不是按照范围均匀划分的了。
计数排序
计数排序是桶排序的一种特殊情况,只是它定义的“桶”的粒度更细,每个桶中只包含一个单位范围的数字,那么每个“桶”内的数值都是相等的。它适合数据范围不大,但数据量很大的排序场景,比如高考考生成绩排名,86 万考生,满分 750 分,需要划分 751 个桶,将这些考生的成绩划分到各个桶中后,依次取出即可。
看到这里你可能会觉得这不就是桶排序吗?计数排序的计数体现在哪里呢?别急,我们看下下面这个排序的例子,简单起见,假设有 8 个考生,他们的分数为 [2, 5, 3, 0, 2, 3, 0, 3],分数范围为 0 ~ 5,那么我们需要创建 6 个桶,规定桶中保存的不是对应的元素,而是对应分数元素出现的数量,并根据分数将桶中的计数值累加,如下图所示:
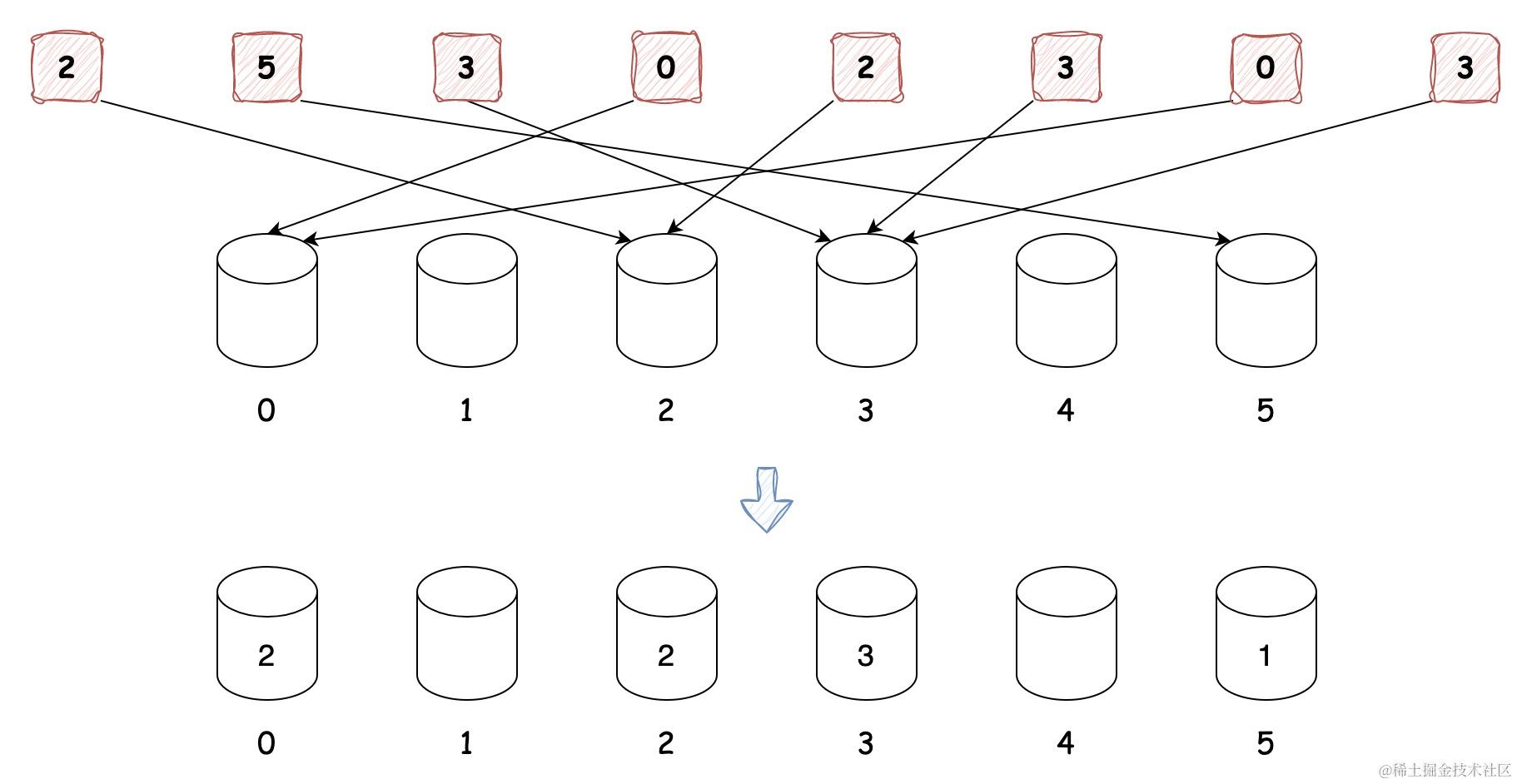
我们先看分数 0 的桶,它是该数据范围内最小的分数,它的计数为 2,根据计数值我们可以确定分数为 0 的两个元素占用该数据范围的前两个索引位置,所以计数表示的是对应数值的索引位置。我们再看看其他的桶来验证一下:可以发现分数 2 的桶计数也为 2,但是前两个索引位置已经被分数 0 占用了呀,分数 2 的计数应该是 4 才对,所以,我们还需要一步操作:叠加前面分数出现的次数,这样分数 2 的计数值便为 4,可以发现计数值其实表示的是某数字占用的第 N 个索引,如果我们想知道其中分数 2 的索引位置,将计数值 4 进行减 1 即可,即它的索引值为 3,而且每取完某数字一次,需要将该计数值减 1。排序流程如下:
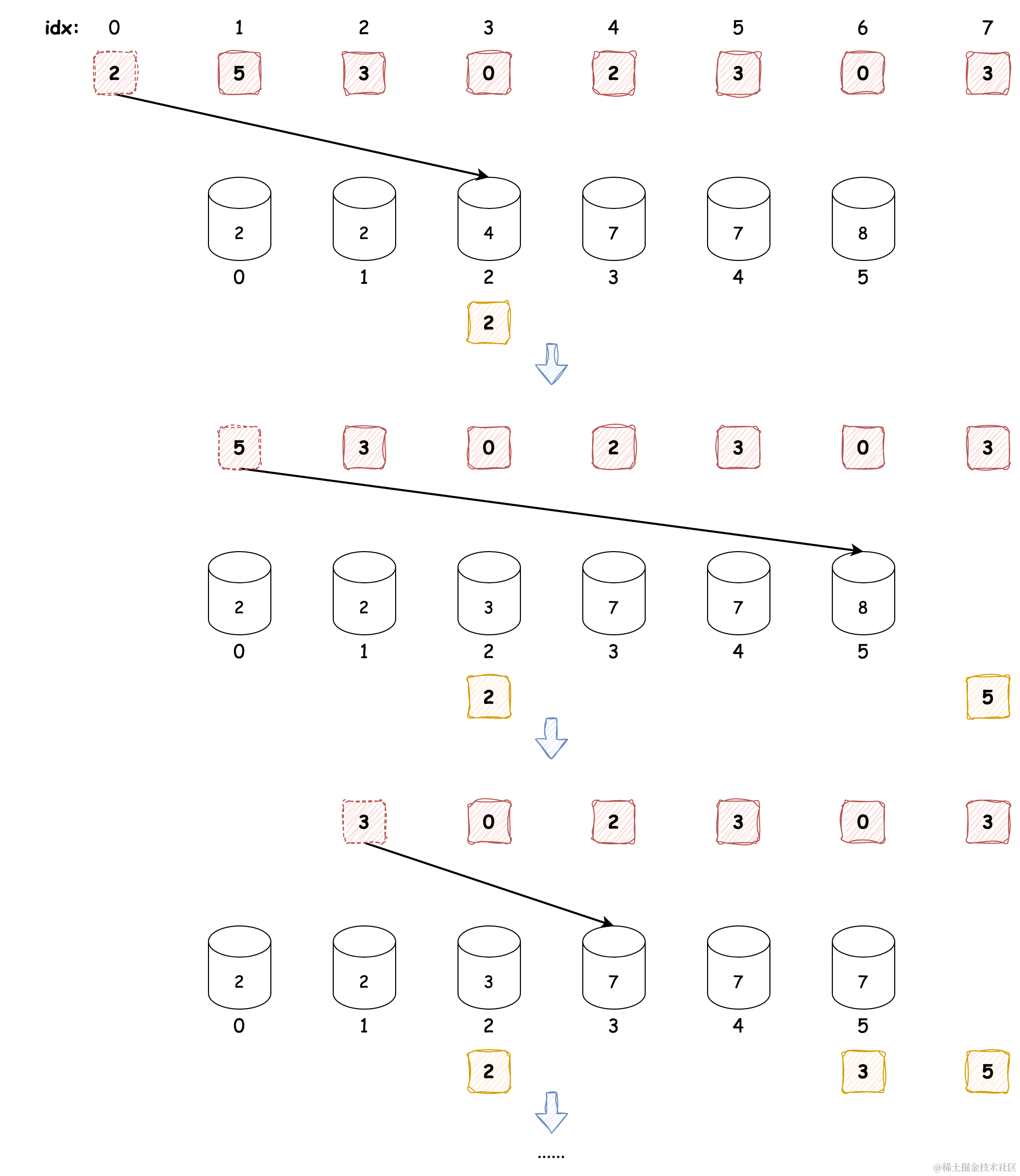
这样一步步操作完成之后,最终数组是有序的。计数排序的代码如下:
/**
* 计数排序的计数体现在小于等于某个数出现的次数 - 1 即为该数在原数组排序后的位置
*/
public void sort(int[] nums) {
if (nums.length <= 1) {
return;
}
// 寻找数组中的最大值来以此定义max + 1个桶
int max = Arrays.stream(nums).max().getAsInt();
// 定义桶,索引范围即数组值的最大范围,每个桶中保存的是该数字出现的次数,计数排序的计数概念出现
int[] bucket = new int[max + 1];
// 计算每个数的个数在桶中累加
Arrays.stream(bucket).forEach(x -> bucket[x]++);
// 依次累加桶中的数,该数表示小于等于该索引值的数量
for (int i = 1; i < bucket.length; i++) {
bucket[i] += bucket[i - 1];
}
// 创建临时数组来保存排序结果值
int[] res = new int[nums.length];
// 倒序遍历原数组,不改变相同元素的相对顺序
for (int i = nums.length - 1; i >= 0; i--) {
// 根据桶中的 计数 找出该数的索引
int index = bucket[nums[i]] - 1;
// 根据索引在结果数组中赋值
res[index] = nums[i];
// 该数分配完成后,需要将桶中的计数-1
bucket[nums[i]]--;
}
// 结果数组覆盖原数组
System.arraycopy(res, 0, nums, 0, res.length);
}
基数排序
基数排序对待排序数据是有特殊要求的,需要数据可以分割出独立的“位”,并且位与位之间要有递进关系,根据递进关系对每一位进行排序,获得最终排序结果。
我们先来看一下使用基数排序处理 [3, 4, 100, 11, 33] 数组的过程:
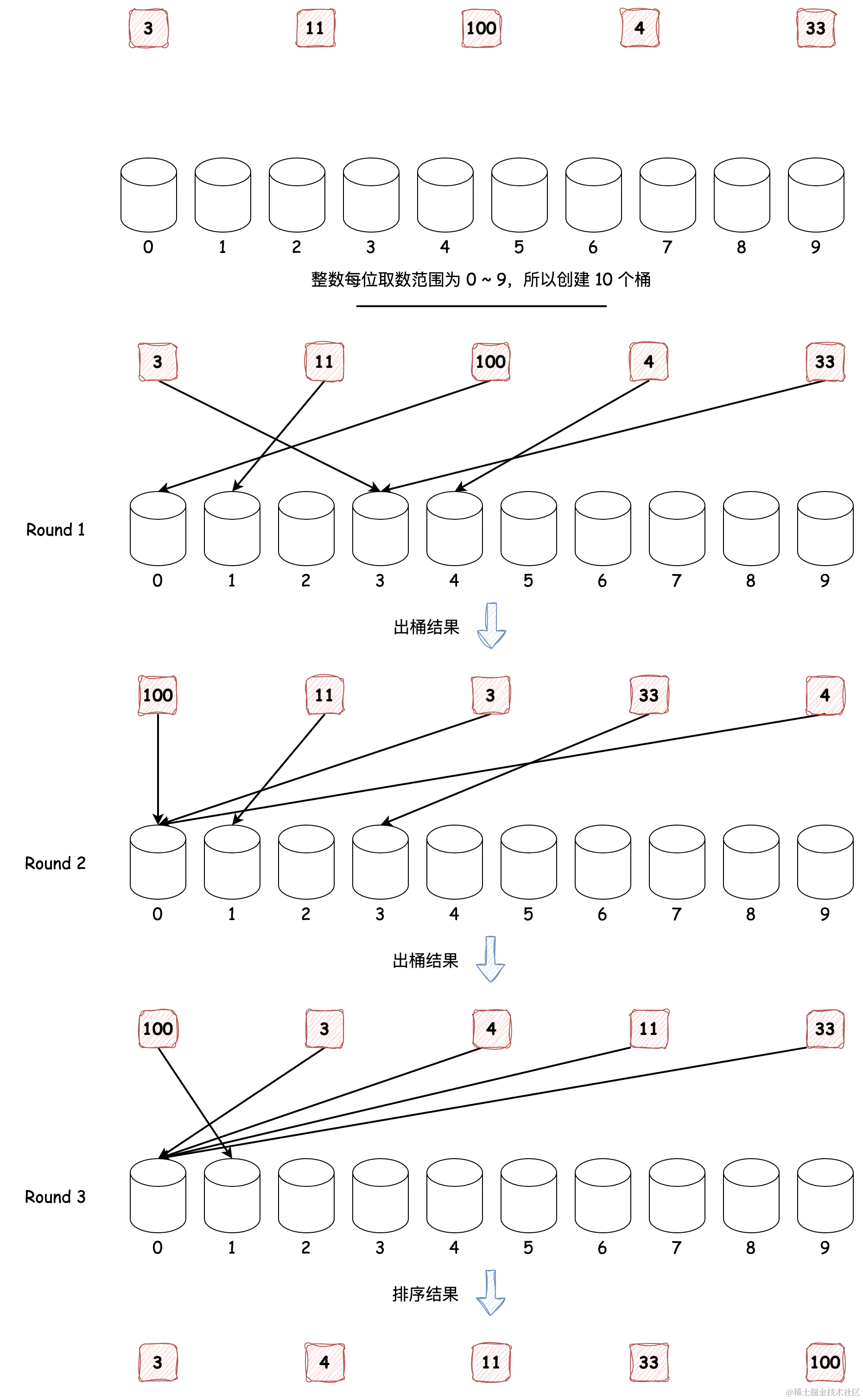
因为整数每位取数范围为 0 ~ 9,所以创建了 10 个桶,这 10 个桶已经有了从大到小的顺序。排序时从整数的个位开始,到最高位终止,排序的轮次为最大整数的位数,在每轮排序中,根据当前位数值大小入桶,完成后再按顺序出桶,最终结果即为排序结果。代码如下:
private void sort(int[] nums) {
if (nums.length <= 1) {
return;
}
// 1. 整数的每位取值范围为 0-9,因此需要创建10个桶
Queue<Integer>[] buckets = createBuckets();
// 2. 获取基数排序的执行轮次
int radixRounds = getRadixRounds(nums);
// 3. 根据执行轮次处理各个"位",eg: 第一轮处理个位...
for (int round = 1; round <= radixRounds; round++) {
for (int num : nums) {
// 获取所在桶的索引
int bucketIndex = getBucketIndex(num, round);
// 进桶
buckets[bucketIndex].offer(num);
}
// 出桶赋值,当前结果为根据当前位排序的结果
int numsIndex = 0;
for (Queue<Integer> bucket : buckets) {
while (!bucket.isEmpty()) {
nums[numsIndex++] = bucket.poll();
}
}
}
}
/**
* 创建大小为10的数组作为桶,每个桶都是一个队列
*/
@SuppressWarnings("unchecked")
private Queue<Integer>[] createBuckets() {
Queue<Integer>[] buckets = new Queue[10];
for (int i = 0; i < buckets.length; i++) {
buckets[i] = new LinkedList<>();
}
return buckets;
}
/**
* 获取基数排序的执行轮次
*/
private int getRadixRounds(int[] nums) {
return String.valueOf(Arrays.stream(nums).max().getAsInt()).length();
}
/**
* 获取该数所在桶的索引
*/
private int getBucketIndex(int num, int round) {
int bucketIndex = 0;
while (round != 0) {
bucketIndex = num % 10;
num /= 10;
round--;
}
return bucketIndex;
}
基数排序比较适用于数据范围比较大且位数相对均匀的数据排序,比如排序手机号或者学号,它的时间复杂度接近于 O(n)。
巨人的肩膀
-
《数据结构与算法之美》:第 3.6 章 线性排序:如何根据年龄给 100 万个用户排序
-
《Hello 算法》:第 11.8、11.9 和 11.10 章
-
《算法导论》:第 8 章 线性时间排序