每一本正式出版的图书都有一个ISBN号码与之对应,ISBN码包括9位数字、1位识别码和3位分隔符,其规定格式如“x-xxx-xxxxx-x”,其中符号“-”就是分隔符(键盘上的减号),最后一位是识别码,例如0-670-82162-4就是一个标准的ISBN码。ISBN码的首位数字表示书籍的出版语言,例如0代表英语;第一个分隔符“-”之后的三位数字代表出版社,例如670代表维京出版社;第二个分隔符后的五位数字代表该书在该出版社的编号;最后一位为识别码。
识别码的计算方法如下:
首位数字乘以1加上次位数字乘以2……以此类推,用所得的结果mod 11,所得的余数即为识别码,如果余数为10,则识别码为大写字母X。例如ISBN号码0-670-82162-4中的识别码4是这样得到的:对067082162这9个数字,从左至右,分别乘以1,2,...,9,再求和,即0×1+6×2+……+2×9=158,然后取158 mod 11的结果4作为识别码。
你的任务是编写程序判断输入的ISBN号码中识别码是否正确,如果正确,则仅输出“Right”;如果错误,则输出你认为是正确的ISBN号码。
输入格式
输入只有一行,是一个字符序列,表示一本书的ISBN号码(保证输入符合ISBN号码的格式要求)。
输出格式
输出共一行,假如输入的ISBN号码的识别码正确,那么输出“Right”,否则,按照规定的格式,输出正确的ISBN号码(包括分隔符“-”)。
输入/输出例子1
输入:
0-670-82162-4
输出:
Right
输入/输出例子2
输入:
0-670-82162-0
输出:
0-670-82162-4
#include<bits/stdc++.h>
using namespace std;
char mod[12]="0123456789X";
int main(){
char s[14];
for(int i=0;i<=12;i++)
cin>>s[i];
int k=1,sum=0;
for(int i=0;i<12;i++){
if(s[i]!='-'){
sum+=(s[i]-'0')*k;
k++;
}
}
if(mod[sum%11]==s[12])cout<<"Right";
else {
s[12]=mod[sum%11];
cout<<s;
}
return 0;
}输入一个十六进制的数,如果输入的不是十六进制,则输出NO,否则输出对应的十进制值。
输入格式
只有一个字符串(字符串长度≤6)。
输出格式
符合十六进制就输出对应的十进制数,否则输出NO。
输入/输出例子1
输入:
1A2b
输出:
6699
#include<bits/stdc++.h>
using namespace std;
const int N=100002;
char c[N];
int main()
{
cin>>c;
for(int i=0;i<strlen(c);i++)
if((c[i]>='0'&&c[i]<='9')||(c[i]>='A'&&c[i]<='F')||(c[i]>='a'&&c[i]<='f')) continue;
else{
cout<<"NO";
return 0;
}
long long sum=0,num,wq=1;
for(int i=strlen(c)-1;i>=0;i--){
if(c[i]>='0'&&c[i]<='9')num=c[i]-'0';
else switch(c[i]){
case 'A':case 'a':num=10;break;
case 'B':case 'b':num=11;break;
case 'C':case 'c':num=12;break;
case 'D':case 'd':num=13;break;
case 'E':case 'e':num=14;break;
case 'F':case 'f':num=15;break;
}
sum+=num*wq;
wq*=16;
}
cout<<sum<<endl;
}
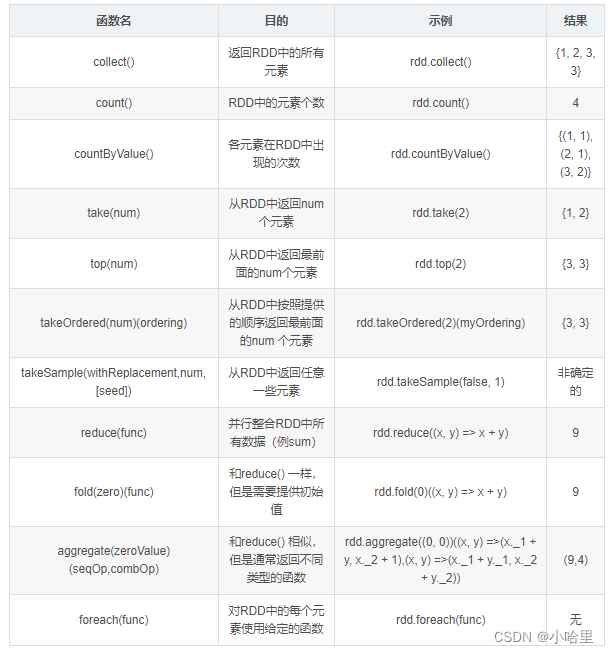
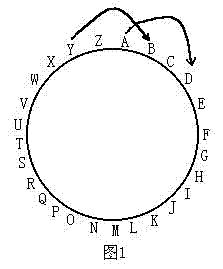
在军事上,通讯的工具往往是收发电文,但敌方会利用仪器设备接收到电文,所以为了使电文保密,可以按一定的规律将电文转换成密码再发送,收报人再按约定的规律将其译回原文,现按这样的规律加密英文电文:将26个英文字母按顺时针围成一圈,把要发送的英文字母转变成其后的第N(1≤N≤25)个字母(除英文字母外,电文中的其它字符不用加密)。例如:如图1,把大写字母A转变成其后的第3个字母是D,把大写字母Y转变成其后的第3个字母是B,小写字母的加密方法也一样,如把b转变成其后的第3个字母是e,把y转变成其后的第三个字母是b。例如电文"1Day."按把字母转变成其后的第3个字母的方法进行加密是:"1Gdb."。
输入格式
输入数据仅1行:A$,N (A$为英文字串,N为转换为其后的第N个字母,1≤N≤25,英文字串与N之间用‘,’隔开)。
输出格式
输出数据仅1行,把英文字串A$转换为其后的第N个字母的新字串。
输入/输出例子1
输入:
Tow.,4
输出:
Xsa.
样例解释
4表示把"Tow."转变成其后的第4个字母
#include<bits/stdc++.h>
using namespace std;
string a;
int main ()
{
getline(cin,a);
int t=a. find(',')+1;
int s=0;
for(int i=t; i<a. size (); i++){
s=s*10+(a[i]-'0');
s%=26;
}
for(int i=0;i<t-1; i++)
{
if(a[i]>='a'&&a[i] <= 'z')//因为直
for(int j=1; j <= s; j++){
a[i]++;
if(a[i]>'z')a[i]='a';
}
else if(a[i]>='A' &&a[i] <= 'Z')
for(int j=1; j <= s; j++){
a[i]++;
if(a[i]>'Z')a[i]='A';
}
cout << a[i];
}
return 0;
}一天,摇摇很荣幸地来到了纳米星球。可他发现一种奇怪的文字——纳米文,就研究起来了。经过不懈的努力,摇摇终于发现改怎么把纳米文转换成地球的文字了:纳米文是一串字符,然后按照下面有一个数字n,然后有n条命令,每条命令有1个或2个字符。如果只有1个字符,就把字符串中的所有这个字符去掉。如果有2个字符,就是把字符串中的所有第一个字符换成那第二个字符。现在摇摇给你纳米文,请把它转成地球文。
输入格式
输入数据共n+2行,第1行:一个字符串。
第2行,一个正整数n。
第3到n+2行,共n行命令字符。
输出格式
输出数据仅1行,即转换后的地球文。
输入/输出例子1
输入:
g31a1333g3ccl11t13hhg
7
z
1
h
c p
t e
g
3
输出:
apple
样例解释
g31a1333g3ccl11t13hhg
7
z {去掉所有的“z”}
1 {去掉所有的“1”}
h {去掉所有的“h”}
c p {把所有的“c”换成“p”}
t e {把所有的“t”换成“e”}
g {去掉所有的“g”}
3 {去掉所有的“3”}
#include<bits/stdc++.h>
using namespace std;
int main(){
string nano;
int n;
getline(cin, nano);
cin>>n;
cin.ignore();
for(int i=0;i<n;i++){
string command;
getline(cin,command);
if(command.size()==1){
size_t pos=nano.find(command);
while(pos!=string::npos){
nano.erase(pos,1);
pos=nano.find(command,pos);
}
}
else if(command.size()==3){
size_t pos=nano.find(command[0]);
while(pos!=string::npos){
nano[pos]=command[2];
pos=nano.find(command[0], pos+1);
}
}
}
cout<<nano<<endl;
return 0;
}乐乐最近玩起了字符游戏,规则是这样的:读入若干字符串,其中的字母都是大写的,乐乐想打印一个柱状图显示每个大写字母的频率。你能帮助她吗?
输入格式
输入文件有若干行:每行为一串字符,不超过72个字符。
输出格式
与样例的格式保持严格的一致。
输入/输出例子1
输入:
THE QUICK BROWN FOX JUMPED OVER THE LAZY DOG.
THIS IS AN EXAMPLE TO TEST FOR YOUR
HISTOGRAM PROGRAM.
HELLO!
输出:
样例解释
1、输出的相邻字符间有一个空格。
2、最后一行的26个大写字母每次必须输出。
3、大写字母A所在的第一列前没有空格。
提示:所读入的字符串个数不确定,有可能4个,或者3个,5个,反正不确定,可以用以下读句读入
while(getline(cin,s)) //一旦读入停止,条件读句会返回一个flase,循环终止。
{
语句组
}
#include<bits/stdc++.h>
using namespace std;
int s[50],mx;
int main(){
int i,j,k,l;
string ss;
for(i=1;i<=4;i++){
getline(cin,ss);
l=ss.length();
for(j=0;j<l;j++){
if(ss[j]>='A'&&ss[j]<='Z'){
s[ss[j]-'A']++;
mx=max(mx,s[ss[j]-'A']);
}
}
}
for(i=mx;i>=1;i--){
for(j=0;j<=25;j++){
if(s[j]>=i)
printf("*");
else
printf(" ");
printf(" ");
}
printf("\n");
}
for(k=0;k<26;k++)
printf("%c ",k+'A');
return 0;
}众所周知,我们通常用一个单词的首字母组成的字符串来代替一个很长的英文名称,例如:ACM是“Association for Computing Machinery”的缩写。现在我们给出一些单词序列,要求按以下规则求出该单词序列的缩写。(缩写有可能是空的)
1.凡是字母个数小于等于2的单词不要。
2.“and”、“for”、“the”这三个单词不要(包括大小写的情况)。
3.除1、2点外的单词取首字母的大写形式按顺序连起来。
输入格式
第一行为一个整数n,表示要求的单词缩写的个数。(n<=100)
接下来n行,每行一个长度小于100的单词序列,每个单词都是由大写或小写字母组成,每个单词之间有一个空格。
输出格式
输出n行,每行为对应的单词缩写。
输入/输出例子1
输入:
5
Association for Computer Machinery
Institute of Electricaland Electronics Engineers
SUN YAT SEN UNIVERSITY
The Lord of the Rings
netease
输出:
ACM
IEEE
SYSU
LR
N
#include<bits/stdc++.h>
using namespace std;
string s, c[4]={" AND ", " FOR ", " THE "};
int n;
int main (){
cin>>n;
getline(cin, s) ;
while(n -- ){
getline(cin, s);
for(int i=0; i<s. size (); i++)
s[i]=toupper(s[i]);
s=" "+s+" ";
for(int i=0;i<3;i++)
while(s. find(c[i]) !=- 1)
s. erase(s. find(c[i])+1,4);
for(int i=0; i<s. size ()-1; i++)
if(s[i] == ' '&&s[i+1] != ' '&&s[i+2] != ' '&&s[i+3] != ' ')
cout << s[i+1];
cout << endl;
}
return 0;
}