启动新项目时需要做出的决定之一是使用哪个数据库。如果您使用的是Django这样的包含电池的框架,那么没有理由再三考虑。选择一个受支持的数据库引擎,就可以了。另一方面,如果你使用像FastAPI或Flask这样的微框架,你需要自己做出这个决定。您的决策会影响您需要哪些库以及如何进行数据建模。虽然你可能只是接触Postgres,但还有其他选择。其中之一是DynamoDB。与Postgres一样,它也是Python项目的绝佳选择。
在本文中,我将比较Postgres和DynamoDB。我将描述如何使用它们,解释它们的区别,并帮助您决定为Python应用程序选择哪一个。
什么是Postgres?什么是DynamoDB
Postgres是一个关系数据库管理系统(RDBMS)。这是一个开源项目,已经存在了35年多。它是一个成熟稳定的数据库引擎。对于大多数项目来说,这是一个不错的选择。
DynamoDB是AWS提供的NoSQL数据库服务。这是一项完全管理的服务,这意味着您不需要担心扩展、备份或可用性。对于需要快速扩展并且不想花时间管理数据库的项目来说,这是一个很好的选择。
第一个明显的区别是Postgres是SQL数据库,而DynamoDB是NoSQL数据库。这并不能告诉我们什么。是的,DynamoDB不是SQL数据库,但它是什么?DynamoDB实际上是一个键/值数据库。这对你的申请意味着什么?我们怎么能比较这两个数据库呢?密钥/值存储真的不就是Redis吗?我们现在还不要妄下结论。让我们先来看一个例子。
比如说我们需要管理TODO任务。一种经典的SQL方法是创建这样一个表:

然后我们可以查询它以获取给定所有者的所有任务:
SELECT * FROM tasks WHERE owner = ' john@doe.com';
DynamoDB的情况有所不同。DynamoDB是一个密钥/值存储。我们可以在两个关键模式之间进行选择。我们只能使用HASH密钥。在这种情况下,我们需要知道ID才能查询记录(可以将其视为Redis)。使用这个密钥模式,我们会有一个这样的表:

我们可以查询它以获取给定ID的任务:
import boto3
dynamodb = boto3.resource("dynamodb")
table = dynamodb.Table("tasks")
table.get_item(
Key={
"ID": "some_id",
},
)
因此,没有办法有效地列出给定所有者的任务。
实际上,您可以使用扫描来扫描整个表,但这是非常低效的,应该避免。
幸运的是,还有另一个选项,HASH&RANGE密钥模式。在这种情况下,我们可以使用两个键来识别一个记录。我们可以使用HASH键来标识分区,使用RANGE键来标识该分区内的记录。HASH和RANGE键组合对于每个记录都必须是唯一的。在我们的情况下,我们可以将owner用作HASH密钥,将ID用作RANGE密钥。在这种情况下,我们会有这样的表格:

有了这样的结构,我们可以查询给定所有者的所有任务,如下所示:
import boto3
from boto3.dynamodb.conditions import Key
dynamodb = boto3.resource("dynamodb")
table = dynamodb.Table("tasks")
table.query(
KeyConditionExpression=Key("Owner").eq("john@doe.com"),
)
现在,您将获得所有者为 john@doe.com 的所有记录,这些记录将按ID排序。
尽管我们只是触及了表面,但我想指出一点:您可以使用Postgres或DynamoDB作为您的应用程序数据库。您只需要以不同的方式处理数据建模。
ORMs
ORM(对象关系映射器)是允许您轻松地将数据库记录映射到Python对象的库。它们大多遵循活动记录或数据映射器模式。使用活动记录模式,模型对象负责业务逻辑和数据持久性。Django ORM就是这样一个例子。对于数据映射器,这两个职责被委派给两个对象,模型对象包含属性和业务逻辑,而映射器对象负责数据持久性。一个例子是SQLAlchemy。它们构建在SQL数据库之上。因此,Postgres有很多ORM选项可供选择也就不足为奇了——SQLAlchemy、Django ORM、Peewee、PonyORM等等。
选择哪一个主要取决于个人喜好。虽然语法可能不同,但它们都允许您轻松定义模型和查询数据库。让我们来看看使用SQLAlchemy的示例:
from sqlalchemy import Column, Integer, String, create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
class Task(Base):
__tablename__ = "tasks"
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String)
status = Column(String)
owner = Column(String)
engine = create_engine("postgresql://postgres:postgres@localhost:5432/postgres")
Base.metadata.create_all(engine)
Session = sessionmaker(bind=engine)
session = Session()
task = Task(title="Clean your office", status="OPEN", owner="john@doe.com")
session.add(task)
session.commit()
tasks = session.query(Task).filter(Task.owner == "john@doe.com").all()
print(tasks)
正如您所看到的,这非常简单:定义模型,创建会话,然后查询数据库。您可以对其他ORM使用相同/相似的方法。
虽然在Postgres中使用ORM时情况会非常好,但我不能对DynamoDB说同样的话。DynamoDB有一些ORM,例如PynamoDB和DynamORM,但在我看来,它们破坏了DynamoDB的整个目的。如果你想真正从DynamoDB中受益,你应该采用单表设计——ORM不支持这种设计。我所说的“真正的好处”是指实际使用DynamoDB,而不是在其上构建另一个带有UUID的关系数据库。让我们来看看如何使用它。
等效于NoSQL数据库的ORM是ODM(对象文档映射器)。例如,请参阅MongoDB的ODM。与ORM一样,它们简化了与数据库的交互。您也可以为DynamoDB找到类似的解决方案,例如,DynamoDB mapper。深入了解后,您会意识到它们没有得到广泛使用,没有得到维护,没有做好生产准备,或者它们强制执行了不必要的约束。
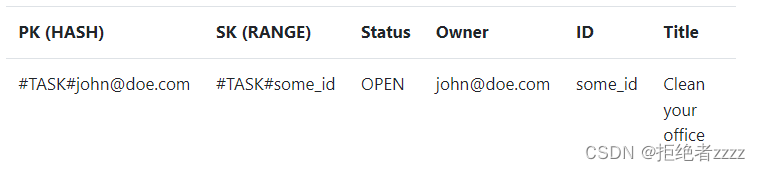
您可以看到以下内容:
- HASH键有一个通用名称 PK (分区键)。它可以用于不同类型的记录。
- RANGE键有一个通用名称 SK (排序键)。它可以用于不同类型的记录。
我们保留了其余的内容,所以我们可以很容易地将数据映射回模型对象。由于DynamoDB是无模式的,所以我们只需要为每个记录提供PK和SK。其他一切都是可选的。这使我们能够对不同类型的记录使用一个表。
为了支持更复杂的示例(和查询),需要对PK和SK使用复合密钥。例如,任务和板的密钥结构不同:
Tasks: PK=#TASK#{owner}, SK=#TASK#{task_id}.
Boards: PK=#BOARD#{owner}, SK=#BOARD#{contact_id}.
这使您能够按所有者轻松查询所有任务或按所有者查询所有板。ORM不鼓励使用单表设计所必需的复合键。这也是ORM在DynamoDB中表现不佳的原因之一。你可以阅读这篇有趣的文章来了解更多。
DynamoDB注重可预测的性能。这就是为什么我们只能通过HASH和RANGE键查询记录(HASH键必须始终存在于查询中)。
无法按其他列进行查询;您可以使用索引来支持更多的查询,但稍后会详细介绍。
因此,我们必须围绕查询而不是数据构建数据模型。这也适用于建立关系模型。使用ORM,您只需定义两个模型之间的外键关系。然后,您将能够通过其父对象访问相关对象,反之亦然。没有必要做任何其他事情。虽然这对于简单的应用程序来说可能很方便,但它可能会成为应用程序中的一个巨大瓶颈(N+1查询)。使用DynamoDB单表设计,希望通过一个查询加载所需的所有内容。
例如,如果你想加载一个包含所有任务的板,你必须对DynamoDB进行单个查询。它将返回不同类型的记录:板(名称、上次更新…)、打开的任务、关闭的任务等等。然后,由您将这些内容映射到包含任务等的板对象。因此,几乎不可能为DynamoDB构建通用ORM。所有内容都非常特定于用例/查询。虽然这听起来像是一项艰巨的工作,但它迫使你进行高效的设计。因此,使用DynamoDB,您需要为数据持久性构建自己的抽象——例如,存储库。您可以指定您的纯Python(或pydantic或其他)模型,并使用Boto3来实现您的存储库。
Models:
from dataclasses import dataclass
from enum import Enum
from uuid import UUID
class TaskStatus(str, Enum):
OPEN = "OPEN"
CLOSED = "CLOSED"
@dataclass
class Task:
id: UUID
title: str
status: TaskStatus
owner: str
@classmethod
def create(cls, id_, title, owner):
return cls(id_, title, TaskStatus.OPEN, owner)
Store:
from uuid import UUID
import boto3
from boto3.dynamodb.conditions import Key
from models import Task, TaskStatus
class TaskStore:
def __init__(self, table_name):
self.table_name = table_name
def add(self, task):
dynamodb = boto3.resource("dynamodb")
table = dynamodb.Table(self.table_name)
table.put_item(
Item={
"PK": f"#TASK#{task.owner}",
"SK": f"#TASK#{task.id}",
"id": str(task.id),
"title": task.title,
"status": task.status.value,
"owner": task.owner,
}
)
def list_by_owner(self, owner):
dynamodb = boto3.resource("dynamodb")
table = dynamodb.Table(self.table_name)
last_key = None
query_kwargs = {
"IndexName": "GS1",
"KeyConditionExpression": Key("PK").eq(f"#TASK#{owner}"),
}
tasks = []
while True:
if last_key is not None:
query_kwargs["ExclusiveStartKey"] = last_key
response = table.query(**query_kwargs)
tasks.extend(
[
Task(
id=UUID(record["id"]),
title=record["title"],
owner=record["owner"],
status=TaskStatus[record["status"]],
)
for record in response["Items"]
]
)
last_key = response.get("LastEvaluatedKey")
if last_key is None:
break
return tasks
简而言之,Postgres和DynamoDB都有ORM。您可能想在Postgres中使用一个,但可能不想在DynamoDB中使用。
Migrations
另一个有趣的主题–数据库迁移。数据库迁移提供了一种更新数据库模式的方法。对于Postgres,有一些工具可以简化迁移
- Alembic
- Django migrations
您可以使用它们轻松地将表/索引/列/约束添加到数据库中。它们甚至可以通过ORM从模型定义中自动生成。Alembic迁移示例:
"""create tasks table
Revision ID: 1f8b5f5d1f5a
Revises:
Create Date: 2021-12-05 12:00:00.000000
"""
from alembic import op
import sqlalchemy as sa
# revision identifiers, used by Alembic.
revision = "1f8b5f5d1f5a"
down_revision = None
branch_labels = None
depends_on = None
def upgrade():
op.create_table(
"tasks",
sa.Column("id", sa.Integer, primary_key=True, autoincrement=True),
sa.Column("title", sa.String),
sa.Column("status", sa.String),
sa.Column("owner", sa.String),
)
def downgrade():
op.drop_table("tasks")
对于大多数常见的操作,它非常简单。对于自动生成的迁移,没有太多工作要做。如果需要,您可以随时手动编写。
对于DynamoDB,没有模式——我们也说过我们想要一个表。无法更改密钥,因此无法迁移。还是有?事实证明,在向记录添加/从记录中删除属性时,您有两个选项:
- 在运行时处理更改–例如,添加具有默认值的列
- 遵循以下三步模式:
1 开始使用新的“属性”写入新记录
2 使用新的“属性”将现有记录更新为所需值(您可以扫描表中的所有记录并更新它们)
3 开始在代码中使用新的“属性”
您可以将三步模式推广到其他类型的更改,如删除属性。
有了所有可用的工具,Postgres的迁移更容易。
如果您在更复杂的项目中工作,而性能差或停机时间确实不是一种选择,那么您可能会手动编写大部分迁移代码。对于这种情况,Postgres和DynamoDB之间没有太大的区别。
Queries
事实上,我们已经谈到了这个话题。我们甚至查看了示例查询。尽管如此,让我们更深入地挖掘。
任何不习惯DynamoDB的人都会说,由于查询数据的能力非常有限,使用它没有意义。的确,查询在DynamoDB中的灵活性要低得多。人们普遍认为,在使用SQL数据库时,可以使用所需的任意列集查询任何数据。理论上是这样的。换句话说,只有当您的数据库足够小,可以放入服务器的内存时,这才是正确的。
一旦您有了更严重的数据量,查询往往会变慢,这反过来又会减慢应用程序的速度。迟早,你需要开始考虑指数。要进行快速查询,您需要添加索引并仅按索引列进行查询。您还将意识到,如果不限制返回记录的数量,您将无法进行查询。无限制的查询很容易导致系统瘫痪。这是因为你根本不知道他们会返回多少数据。您的数据库可能需要从磁盘读取10亿行,这需要时间。
那我们该何去何从呢?DynamoDB的构建方式迫使您提前考虑这些问题。
在设计数据模型时,您需要:
- 使用HASH键对数据进行分区
- 使用RANGE键对数据进行排序
然后,您只能通过HASH和RANGE键或预定义的索引进行查询,这些索引有自己的HASH和RANGE键。单个查询返回的数据量也有限制。所以你不得不使用分页。
所有这些限制在一开始可能听起来很可怕,让人不知所措。一旦你习惯了它们,你就会意识到它们的存在是有原因的。让我们来看看示例查询。。。
With DynamoDB:
import boto3
from boto3.dynamodb.conditions import Key
owner = "john@doe.com"
dynamodb = boto3.resource("dynamodb")
table = dynamodb.Table("tasks-api")
last_key = None
query_kwargs = {
"IndexName": "GS1",
"KeyConditionExpression": Key("PK").eq(f"#TASK#{owner}"),
}
tasks = []
while True:
if last_key is not None:
query_kwargs["ExclusiveStartKey"] = last_key
response = table.query(**query_kwargs)
tasks.extend(response["Items"])
last_key = response.get("LastEvaluatedKey")
if last_key is None:
break
print(tasks)
使用Postgres+SQLAlchemy(分页查询):
from models import Session, Task
tasks = []
last_evaluated_id = -1
session = Session()
while True:
query = session.query(Task).filter(Task.id > last_evaluated_id).order_by(Task.id).limit(10)
tasks.extend(query.all())
last_evaluated_id = tasks[-1].id
if len(tasks) < 10:
break
print(tasks)
正如您所看到的,DynamoDB和Postgres分页查询在代码复杂度上没有太大区别。
DynamoDB还有其他查询限制:
- 我们必须始终至少提供HASH密钥
- 我们只能通过HASH和RANGE键或预定义索引进行查询
- 返回的记录按RANGE键排序。您只能在升序和降序之间进行选择
我们知道,在当前的表设计中,我们只能支持两个查询:
- 按所有者列出(您已在上面看到)
- 按所有者和任务ID获取(您可以在下面看到)
import boto3
from boto3.dynamodb.conditions import Key
owner = "john@doe.com"
task_id = "7b0f4bc8-4751-41f1-b3b1-23a935d81cd6"
dynamodb = boto3.resource("dynamodb", endpoint_url="http://localhost:9999")
table = dynamodb.Table("tasks-api")
query_kwargs = {
"KeyConditionExpression": Key("PK").eq(f"#TASK#{owner}") & Key("SK").eq(f"#TASK#{task_id}"),
}
task = response = table.query(**query_kwargs)["Items"][0]
print(task)
例如,我们不能按状态进行查询。但我们可以用Postgres做到这一点:
from models import Session, Task
tasks = []
last_evaluated_id = -1
session = Session()
while True:
query = session.query(Task).filter(Task.status == "OPEN").filter(Task.id > last_evaluated_id).order_by(Task.id).limit(10)
tasks.extend(query.all())
last_evaluated_id = tasks[-1].id
if len(tasks) < 10:
break
print(tasks)
别担心,我们仍然可以在DynamoDB中支持这样的查询。我们只需要添加即可使用全局二级索引(GSI)。我们可以创建一个名为GS1的具有单个GSI的表,如下所示:
import boto3
client = boto3.client("dynamodb", endpoint_url="http://localhost:9999")
client.create_table(
TableName="tasks-api",
KeySchema=[
{"AttributeName": "PK", "KeyType": "HASH"},
{"AttributeName": "SK", "KeyType": "RANGE"},
],
AttributeDefinitions=[
{"AttributeName": "PK", "AttributeType": "S"},
{"AttributeName": "SK", "AttributeType": "S"},
{"AttributeName": "GS1PK", "AttributeType": "S"},
{"AttributeName": "GS1SK", "AttributeType": "S"},
],
GlobalSecondaryIndexes=[
{
"IndexName": "GS1",
"KeySchema": [
{"AttributeName": "GS1PK", "KeyType": "HASH"},
{"AttributeName": "GS1SK", "KeyType": "RANGE"},
],
"Projection": {"ProjectionType": "ALL"},
},
],
BillingMode="PAY_PER_REQUEST",
)
就像表格一样,GSI有自己的HASH和RANGE键。然后,我们可以按如下状态进行查询:
import boto3
from boto3.dynamodb.conditions import Key
status = "OPEN"
dynamodb = boto3.resource("dynamodb", endpoint_url="http://localhost:9999")
table = dynamodb.Table("tasks-api")
last_key = None
query_kwargs = {
"KeyConditionExpression": Key("GS1PK").eq(f"#TASK#{status}"),
"IndexName": "GS1",
}
tasks = []
while True:
if last_key is not None:
query_kwargs["ExclusiveStartKey"] = last_key
response = table.query(**query_kwargs)
tasks.extend(response["Items"])
last_key = response.get("LastEvaluatedKey")
if last_key is None:
break
print(tasks)
正如您所看到的,您需要显式定义查询时要使用的索引。另一方面,Postgres自己做到了这一点。再一次,如果您比较查询,您会发现它们毕竟没有那么大的不同。
只要您使用的是精确的查询(=,!=,>,<,…),Postgres和DynamoDB之间就没有太大区别。使用DynamoDB,您无法进行LIKE、IN等查询或全文搜索。要支持这样的功能,您需要将其与Elasticsearch或类似功能配对。
您可以在此处看到HASH/RANGE键支持的条件的完整列表。
简而言之,当用作应用程序数据库时,这两个数据库都应该支持您的需求。如果你想进行更复杂的查询(例如,报告、分析等),你要么需要使用Postgres,要么将DynamoDB与其他一些服务配对,如Elasticsearch、Athena或Redshift等。
Performance
性能总是一个棘手的话题。进入“意见”领域是很容易的。我会尽量避免的。如果你在网上搜索,你会发现有人赞扬DynamoDB,诋毁Postgres,反之亦然。事实是,在大多数情况下,你会看到以下缺陷之一:
- DynamoDB被用作关系数据库——多个表,没有单表设计
- Postgres的索引/分区很差
- 扫描与DynamoDB一起使用
- Postgres被非索引列或无限制查询
这些年来,我在各种生产环境中都使用过这两种方法。我可以告诉你以下几点:如果使用得当,它们都会燃烧得很快。当直接比较时,您可能会注意到它们之间的细微差异,但从应用程序的角度来看,您不会注意到太大的性能差异。当然,在亚马逊/谷歌/奈飞等网站。规模,你会明显地看到一些不同;毕竟,创建DynamoDB是有原因的。
长话短说:对于大多数项目来说,性能不应该是主要的决定因素。至少如果你不是亚马逊/网飞/。。。。相反,把时间花在开发一个高效的数据(访问)模型上,你会没事的。
Backups
备份是一个经常被遗忘的主题。没有备份之前一切都很好。由于我们已经在AWS和DynamoDB中,让我们将AWS RDS上的Postgres与DynamoDB进行比较。
它们都支持按需备份和连续备份。它们都提供时间点恢复,我强烈建议您这样做。我强烈建议您同时使用内置备份。对于时间点恢复,两者的流程基本相同:
- 从给定的时间戳创建一个时间点恢复,这将创建一个新实例(RDS)或一个新表(DynamoDB)
- 将已恢复数据中丢失的数据复制到应用程序实例/表,或将应用程序重新路由到新实例/表
提示:AWS上的备份符合SOC 2等证书。
您可以从DynamoDB和RDS的官方文档中了解更多信息。
Transactions
在我们结束之前,让我们谈一谈事务。事务是一种允许我们将多个操作封装到单个数据库操作中的机制。这有助于确保要么执行所有操作,要么不执行任何操作。例如,通过这种方式,我们可以确保减少库存项目的数量并创建新订单。如果没有交易,我们可能会收到一个没有库存的订单——例如,有人在你之前下了订单。
事务是SQL数据库的“面包和黄油”。另一方面,它们在NoSQL数据库中并不常见。Postgres和DynamoDB都支持事务——要么全部支持,要么什么都不支持。它们在Postgres中可能感觉更惯用,但您也可以在DynamoDB中使用它们。您只需要使用较低级别的Boto3 API。
因此,在这方面,您应该可以使用DynamoDB或Postgres。
您可以从DynamoDB和Postgres的官方文档中了解更多信息。
我应该使用哪一个
所有这些都给你留下了一个问题:我应该使用哪一个?对于大多数情况,您可以使用其中任何一种。尽管如此,还是有一些指导原则可以帮助您进行选择:
- 如果您正在使用Django(或任何其他包含电池的框架),请使用Postgres。这是最简单的方法。如果您尝试使用DynamoDB,那么您只需要与框架作斗争。
- 如果你有一个缺乏经验的团队,去Postgres。这更容易让你的头脑清醒起来,并在以后纠正你的错误。
- 如果您需要在多个AWS区域轻松复制数据,请使用DynamoDB。它就是为这个而建的。
- 如果您的流量非常大,请选择DynamoDB。您可以按要求付款。
- 如果你想无服务器化,那就选择DynamoDB。但在这种情况下,您也需要在Lambda上运行您的应用程序。
- 如果您不在AWS生态系统中,请使用Postgres。DynamoDB与AWS紧密相连。
无论您选择哪种,请记住,拥有一个高效的数据模型比您使用的数据库更重要。DynamoDB会强迫你这么做。Postgres不会。但正如您所看到的,当有效地使用它们时,您最终会得到非常相似的使用模式。
结论
虽然本文涵盖了很多内容,但仍有很多内容需要探索。那么接下来该怎么办呢?你可以用它们两个构建同一个应用程序,以真正掌握它们。我们——惊喜,惊喜!——有两门课程可以帮助你做到这一点:
- Serverless FastAPI course
- Scalable FastAPI course
前者使用DynamoDB,后者使用Postgres。试着用两者构建相同的东西,你会看到它的进展。如果没有别的,我相信一旦完成,你在数据建模方面会做得更好。
您还可以使用本文中的示例:GitHub repository。