1.前言
在应用程序中会有大量的对变量的操作,在一般情况下不会导致问题,但在多线程操作共享变量时,不当的操作会产生大量的冗余操作,造成性能的浪费。这篇文章主要从编码方式与逻辑策略对变量从CPU寄存器,CPU缓存,直至内存,描述变量的生命周期,性能瓶颈与解决方式。
2.基本原理
2.1 硬件架构
在CPU需要对数据进行操作时,会按照以下顺序对数据进行获取,若未获取到则继续向下一级获取,直至内存中命中。
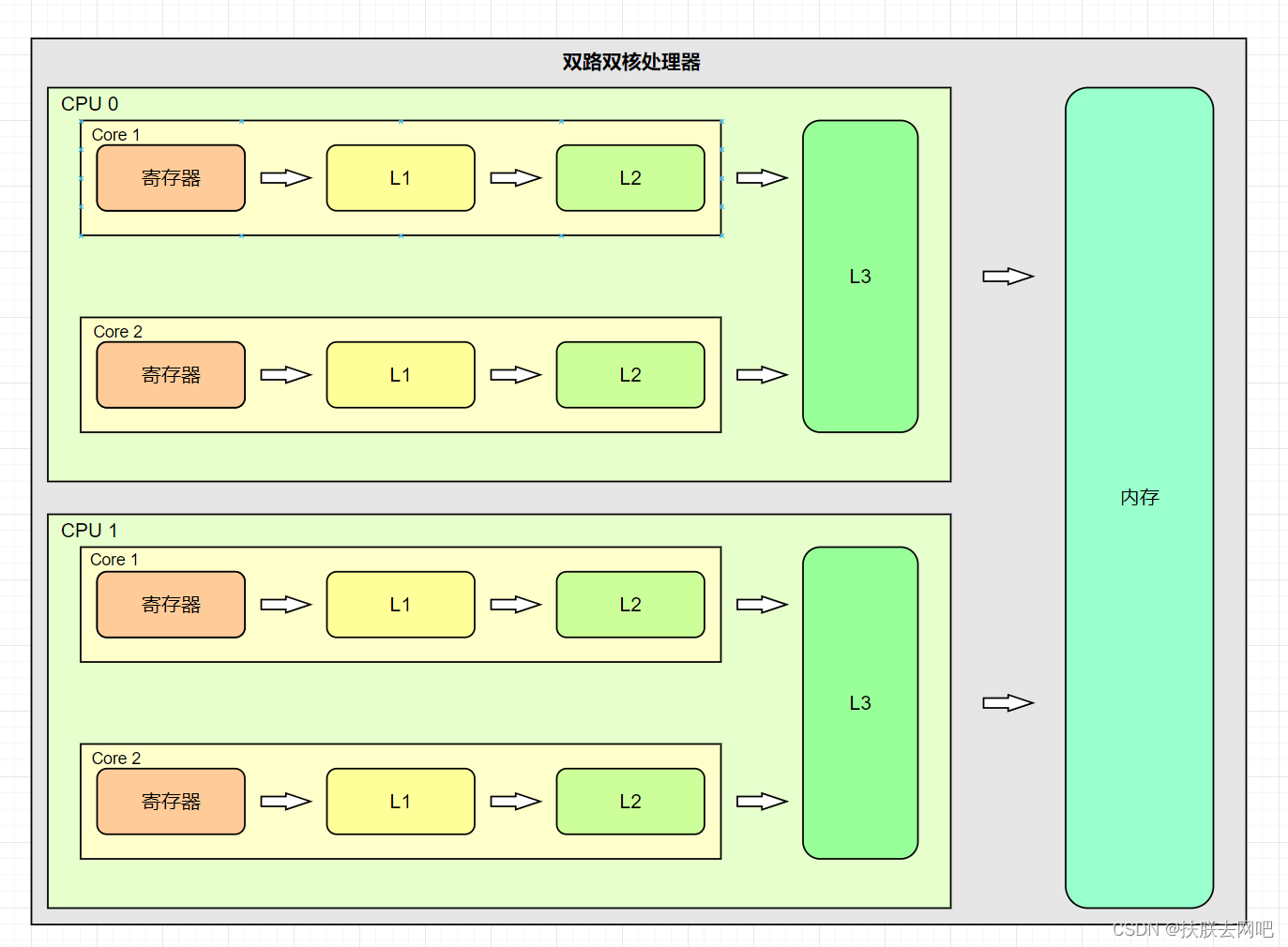
在上面是普通的双路(安装了两颗CPU)双核CPU,也有不带L3的CPU。一般情况下CPU数据读取是按照上述过程执行。可以看出L1,L2是核内共享,L3为CPU内多核共享,而内存为多CPU共享,寄存器会优先去L1查找,再去L2,L3,内存中查找。
注意:L1分为数据L1和指令L1两部分
2.2 存储层次
这里引用一张《深入理解计算机系统》中的图
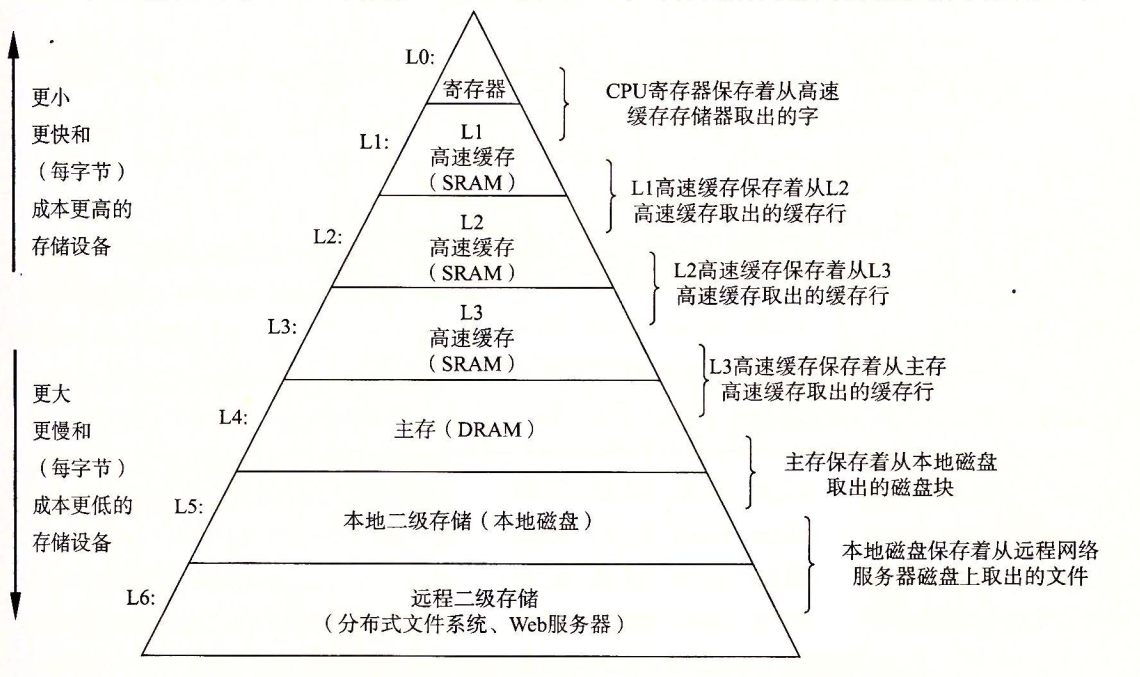
里面完整描述了各部件与速度的关系,各部件获取数据的速度大约在:
| 部件 | 时钟周期 |
| L1 | 2-4 |
| L2 | 10-20 |
| L3 | 20-60 |
| 内存 | 200-300 |
时钟周期:时钟周期是CPU主频的倒数,比如2GHz主频的CPU,一个时钟周期是0.5ns,也就是说,主频越高,时钟周期越小。
2.3 实际参数
以下是一个6核12线程i7-10750H CPU的参数。
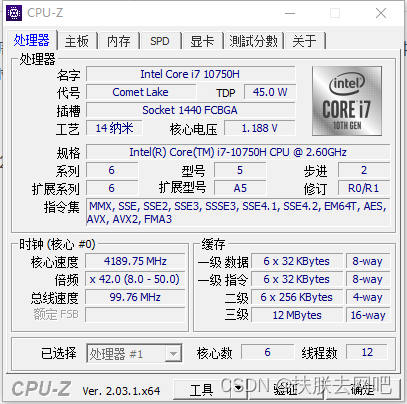
缓存大小:
在上面的结构中,可以看到,6个核心中,每个核心有32K的数据L1,32K的指令L1,还有256K的L2,12M的L3。在上面可以看到,L1和L2前面分别跟了‘6 X’,而L3没有,表名L3位CPU共享三级缓存。
缓存路数:
可以看到缓存后有个8-way,4-way,16-way这种,缓存路数用来将缓存行打包标记,用于快速查找数据。比如L1的数据缓存有32K,每个缓存行有64B,那么这个L1的数据缓存中就有32*1024/64=512个缓存行,而这的8-way代表将每8个缓存行打包为512/8=64标记。
2.4 缓存行
缓存行是CPU重很重要的一个结构,在CPU读取数据A时,后面可能再次访问到,并且可能会访问到相邻的数据B,所以为了读取效率,应用到了缓存行的概念,CPU会在读取数据时,将命中对象相邻的区域也读取到缓存行中,这个区域也就是缓存行的大小一般是64Byte。
| ....... | 1(byte) | 1(byte) | 1(byte) | 1(byte) | 1(byte) | 1(byte) | 1(byte) | 1(byte) | ........ |
3.性能瓶颈
3.1 缓存命中
3.1.1 数据缓存命中
当对一个数组进行遍历的时候,如果在使用到缓存的时候
CPU缓存与性能优化 | 码农家园 (codenong.com)
3.1.2 指令缓存命中
3.1.3 多核CPU下缓存命中
3.2 伪缓存行
在
解决方式:缓存行填充







![[RoarCTF 2019]Online Proxy(x-forwarded-for盲注)](https://img-blog.csdnimg.cn/6723c9beff2c48398cedca1fad58701c.png)
