大家好,我是八块腹肌的小胖,
下面将围绕微博“中国文化”以数据分析、数据处理、建模及可视化等操作
目录
1、数据获取
2、数据处理
3、词频统计及词云展示
4、文本聚类分析
5、文本情感倾向性分析
6、情感倾向演化分析
7、总结
1、数据获取
本任务以新浪微博为目标网站,爬取“中国文化”为主题的微博数据进行数据预处理、数据可视化等操作。
目标网站如图1所示:
图1 微博网站及分析
通过分析微博网站,使用爬虫获取代码,爬虫核心伪代码如下:
-
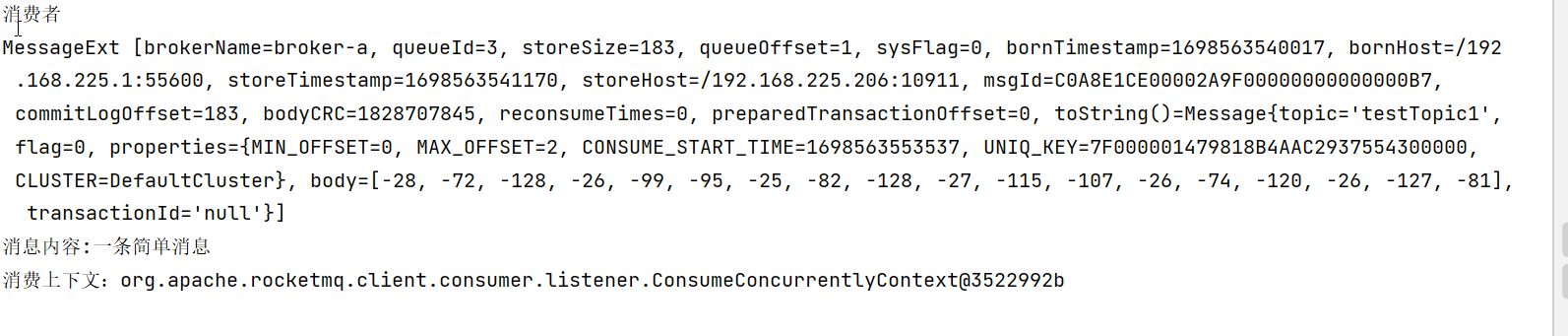
这段代码咱们开始处理微博数据了。这次的目标是搞清楚微博里的各种信息,包括内容、创建时间、作者、还有转发、评论、点赞这些数字。
首先呢,咱们用jsonpath这个工具从一大堆微博数据里挑出来微博的文本内容,这就是咱们要分析的主角。但这些文本里可能夹杂了一些HTML标签,看着碍眼,所以用了正则表达式把这些标签统统清除掉,让文本干净整洁。
然后,咱们也顺便把微博的发布时间、发布者、微博ID这些信息给捞出来,这都是分析的重要信息。特别的是,如果发现了有微博是长文,咱们就得用特殊的方式去获取全文,确保分析的内容不遗漏。
紧接着,转发数、评论数、点赞数这些“数字见证”,也统统不放过,这些可是衡量微博火不火的重要标尺。
最后,把这些信息整理好,打包进一个DataFrame里,这样数据就既清晰又方便后续的分析了。打印出一些列表的长度,就是为了检查一下咱们收集的信息完整不完整,防止哪里出了差错。
整个过程就像是咱们对微博数据进行了一次大扫除,把需要的信息都收集齐全,准备好了接下来的分析步骤。这样一来,不管咱们想研究微博的哪方面信息,手头上都有足够的材料了。
1. # 微博内容
2. text_list = jsonpath(cards, '$..mblog.text')
3. # 微博内容-正则表达式数据清洗
4. dr = re.compile(r'<[^>]+>', re.S)
5. text2_list = []
6. print('text_list is:')
7. # print(text_list)
8. if not text_list: # 如果未获取到微博内容,进入下一轮循环
9. continue
10. if type(text_list) == list and len(text_list) > 0:
11. for text in text_list:
12. text2 = dr.sub('', text) # 正则表达式提取微博内容
13. # print(text2)
14. text2_list.append(text2)
15. # 微博创建时间
16. time_list = jsonpath(cards, '$..mblog.created_at')
17. time_list = [trans_time(v_str=i) for i in time_list]
18. # 微博作者
19. author_list = jsonpath(cards, '$..mblog.user.screen_name')
20. # 微博id
21. id_list = jsonpath(cards, '$..mblog.id')
22. # 判断是否存在全文
23. isLongText_list = jsonpath(cards, '$..mblog.isLongText')
24. idx = 0
25. for i in isLongText_list:
26. if i == True:
27. long_text = getLongText(v_id=id_list[idx])
28. text2_list[idx] = long_text
29. idx += 1
30. # 转发数
31. reposts_count_list = jsonpath(cards, '$..mblog.reposts_count')
32. # 评论数
33. comments_count_list = jsonpath(cards, '$..mblog.comments_count')
34. # 点赞数
35. attitudes_count_list = jsonpath(cards, '$..mblog.attitudes_count')
36. # 把列表数据保存成DataFrame数据
37. print('id_list:', len(id_list))
38. print(len(time_list))
39. print('region_name_list:', len(region_name_list))
40. print(len(status_city_list))
41. print(len(status_province_list))
42. print(len(status_country_list))
获取的爬虫数据如图2所示:
图2微博数据
2、数据处理
咱们这一步呢,是要把数据梳理得整整齐齐的,好比给数据做个美容。首先,咱们决定了要关注哪几个方面的信息:发布者的名字、发布时间、文本内容、转发数、评论数、点赞数和位置信息。这些都是分析微博活动时不可或缺的。
接下来,咱们对日期格式做了标准化处理,确保所有的日期都是按照年-月-日 时:分:秒这样的格式来的,这样看起来既整洁又方便后续的分析。
然后,文本内容里有些杂七杂八的东西需要清理掉,比如那些乱七八糟的标签啊、特殊字符啊,甚至是一些广告内容,都得用字符串替换的方法把它们给去掉,让文本内容清清爽爽。
咱们还考虑到了数据里可能会有一些空白的地方,这些地方咱们就统一填上"N/A",意思就是这里啥也没有,但是也不能空着,得有个标记。
做完这一切,咱们就可以看看咱们的数据变成啥样了。打印出来一看,所有的信息都按部就班,整整齐齐的,这下子,无论是要做分析还是画图,手里的数据都是清清楚楚,明明白白的了。这就像是给数据穿上了新衣服,既美观又实用。
1. # 数据清洗和预处理
2. # 列:screen_name, created_at, text, reposts_count, comments_count, attitudes_count, location
3. selected_columns = ['screen_name', 'created_at', 'text', 'reposts_count', 'comments_count', 'attitudes_count', 'location']
4. data = data[selected_columns]
5.
6. # 处理日期格式
7. data['created_at'] = pd.to_datetime(data['created_at'], format='%Y-%m-%d %H:%M:%S')
8.
9. # 去除文本中的特殊字符或标签
10. data['text'] = data['text'].str.replace(r'#', '')
11. data['text'] = data['text'].str.replace(r'【', '')
12. data['text'] = data['text'].str.replace(r'】', '')
13. data['text'] = data['text'].str.replace(r'不得鸟的微博视频', '')
14.
15. # 填充缺失值(如果有)
16. data = data.fillna('N/A')
17.
18. # 查看预处理后的数据
19. print(data)
“数据处理”代码输出如图3所示:
图3数据处理
3、词频统计及词云展示
咱们这一步就是要搞清楚咱们数据里面都聊了啥,用的哪些词特别多。
首先,得用jieba来分词,就是把句子切成词儿。把咱们数据里的文本内容拿出来,一条条地切,切完了汇总到一起。
然后,你知道有些词儿咱其实不太需要,比如“的”、“是”这种,这就需要用到停用词表了。
停用词表里的词儿,咱们在分词结果里看到了就直接忽略它。这个停用词表是个文件,咱们打开它,把里面的词读出来,存起来,准备用。
接下来,咱们要把切出来的词里面,不在停用词表里的筛出来,这样剩下的就都是咱们要的了。
这些词儿,咱们来数数谁出现得多,谁出现得少,就是词频统计。
统计完了,咱们就挑出来出现次数最多的前十个词,看看都是些啥,打印出来给自己看看。
最后,用这些词儿画个词云图。词云图就是把这些词以不同的大小显示出来,谁大谁就是出现次数多的。
这样一看,就一目了然了,知道咱们数据里面热点话题都有啥。
画完了直接显示出来,这图挺好看的,也挺有用的,一眼能看出来重点词汇。
1. # 词频统计及词云显示
2. # 分词
3. import pandas as pd
4. import jieba
5. from collections import Counter
6. from wordcloud import WordCloud
7. import matplotlib.pyplot as plt
8. # 分词
9. seg_list = []
10. for text in data['text']:
11. seg_list.extend(jieba.cut(text))
12.
13. # 加载停用词表
14. stopwords = set()
15. with open('stop_words.txt', 'r', encoding='utf-8') as f:
16. for line in f:
17. stopwords.add(line.strip())
18.
19. # 过滤停用词
20. seg_list_filtered = [word for word in seg_list if word not in stopwords]
21.
22. # 统计词频
23. word_counts = Counter(seg_list_filtered)
24.
25. # 获取词频最高的前N个词
26. top_n = 10
27. top_words = word_counts.most_common(top_n)
28.
29. # 打印词频最高的词
30. for word, count in top_words:
31. print(f'{word}: {count}')
32.
33. # 生成词云
34. wordcloud = WordCloud(font_path='SimHei.ttf', background_color='white').generate(' '.join(seg_list_filtered))
35.
36. # 显示词云
37. plt.imshow(wordcloud, interpolation='bilinear')
38. plt.axis('off')
39. plt.show()

4、文本聚类分析
下面聚类的代码,咱们是要搞点更高级的,不光是看看热词,还要把这些文本内容分个类,看看都有哪些不同的主题或者类型在里面。
首先,还是老规矩,先把数据读进来,用Pandas从一个叫data.csv的文件里读数据。然后,还是得清理一下文本,把一些乱七八糟的特殊字符或者不需要的标签给去掉。
接着,分词。这次咱们分完词后,每个词之间加个空格,因为接下来要用TF-IDF(词频-逆文档频率)来向量化文本,这个操作是把文本转换成数学上的向量,为的是让计算机能理解和处理。
咱们用TF-IDF把文本向量化之后,文本就变成了一堆数字表示的向量,接下来就可以用KMeans这个算法来聚类了。意思就是,咱们想把这些文本按内容或风格自动分成几堆,这里咱们定了3堆。
聚类完了,为了让咱们肉眼能看出来效果,用到了SVD(奇异值分解)进行降维,就是把那些高维的数据压缩到2维空间里,这样就能在图上画出来了。
然后,咱们就可以画图看看了,用不同颜色表示不同的类,把这些点画到图上,通过颜色就能看出来哪些文本是被分到一组的。
这还不够,咱们还得知道每组里面都是些啥内容,所以要找出每个聚类(也就是每堆)的关键词。这里就是计算每个聚类里面哪些词最能代表这个聚类,然后挑出来权重最高的前10个词。
最后,把这些关键词打印出来,每个聚类的关键词都列一列,这样一看,就知道每个聚类大概是啥主题的了。还把每个聚类里面的文本也打印出来,这样咱们就能具体看看分得对不对,有没有啥意外的发现。
画完图,标上轴名,给图个标题,这图就完整了,展示的是咱们的聚类结果。看完这个,就能对咱们数据里的文本有个更深入的了解了。
1. import pandas as pd
2. import jieba
3. from sklearn.feature_extraction.text import TfidfVectorizer
4. from sklearn.cluster import KMeans
5. from sklearn.decomposition import TruncatedSVD
6. import matplotlib.pyplot as plt
7. from scipy.sparse import csr_matrix
8.
9. # 读取数据文件
10. data = pd.read_csv('data.csv')
11.
12. # 去除文本中的特殊字符或标签
13. data['text'] = data['text'].str.replace(r'#', '')
14. data['text'] = data['text'].str.replace(r'【', '')
15. data['text'] = data['text'].str.replace(r'】', '')
16. data['text'] = data['text'].str.replace(r'不得鸟的微博视频', '')
17.
18. # 分词
19. seg_list = []
20. for text in data['text']:
21. seg_list.append(' '.join(jieba.cut(str(text))))
22.
23. # 使用TF-IDF向量化文本
24. vectorizer = TfidfVectorizer()
25. X = vectorizer.fit_transform(seg_list)
26.
27. # 转换为稀疏矩阵
28. X_sparse = csr_matrix(X)
29.
30. # 使用KMeans聚类
31. k = 3 # 聚类数量
32. kmeans = KMeans(n_clusters=k, random_state=42)
33. kmeans.fit(X_sparse)
34.
35. # 使用SVD进行降维
36. svd = TruncatedSVD(n_components=2)
37. X_svd = svd.fit_transform(X_sparse)
38.
39. # 绘制聚类结果
40. colors = ['red', 'blue', 'green']
41. labels = kmeans.labels_
42. for i in range(len(X_svd)):
43. plt.scatter(X_svd[i, 0], X_svd[i, 1], color=colors[labels[i]])
44.
45. # 获取聚类关键词
46. terms = vectorizer.get_feature_names()
47.
48. # 显示类别关键词
49. for cluster_id in range(k):
50. cluster_terms = []
51. cluster_indices = labels == cluster_id
52. cluster_text = data.loc[cluster_indices, 'text']
53. cluster_vector = X[cluster_indices]
54.
55. # 计算每个类别的关键词权重总和
56. cluster_weights = cluster_vector.sum(axis=0).A1
57. sorted_indices = cluster_weights.argsort()[::-1]
58.
59. # 获取权重排名前10的关键词
60. for term_index in sorted_indices[:10]:
61. cluster_terms.append(terms[term_index])
62.
63. print(f"Cluster {cluster_id + 1} Keywords: {' '.join(cluster_terms)}")
64. print(f"Cluster {cluster_id + 1} Texts:")
65. print(cluster_text)
66. print()
67.
68. plt.xlabel('Component 1')
69. plt.ylabel('Component 2')
70. plt.title('KMeans Clustering')
71. plt.show()
文本聚类最终展示的聚类前10个关键词如下所示,完整结果及聚类输出如图5所示:
Cluster 1 Keywords: 京剧 国粹 表演 中国 戏曲 艺术 文明 视频 变脸 传统
Cluster 2 Keywords: 中国 文化 历史 美食 传统 传统节日 视频 微博 我们 六级
Cluster 3 Keywords: 街头 联动 外国 上海 时代广场 疯狂 上分 文化 我们 中国

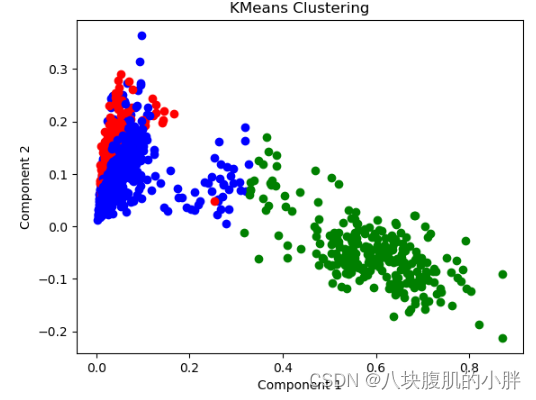
图5 聚类结果
5、文本情感倾向性分析
咱们这回的任务是要看看咱们数据里面的文本,大家是个啥心情,是不是开心,还是有点小郁闷。用的是情感分析,这玩意儿可以算出一句话是正面的、负面的还是说不上好坏中性的。
先来,对每条文本用SnowNLP这个工具跑一遍,这个东西能给咱们一个情感倾向性得分,分数高的话,说明这话挺乐观的,分数低就可能有点悲观。
得到所有文本的情感得分后,咱们分三类,负面、中性、正面。规则是这样的,得分低于0.3的咱们认为是负面的,0.3到0.7之间的算中性,高于0.7的就是正面了。然后数一数每类有多少条。
下一步,咱们要把这个结果做成一个饼图,一眼就能看出来哪种情绪的文本多。为了好看点,还得挑挑颜色,用的是sns(Seaborn库)的色板,选了个pastel(粉彩)风格的前三种颜色。
画饼图时,标上每种情绪的标签,加上每部分占的比例,然后从90度开始画,这样看起来舒服。
因为咱们要显示中文,所以还得设置下字体,确保中文不会乱码。设置完后,把所有文本的字体都调整成咱们设置的那个。
给图加个标题,叫“情感分析结果”,别忘了也要设置成中文显示。最后,为了饼图看起来是个正圆,调一调轴的比例。
做完这些,跑一下,饼图就出来啦。这样一看,咱们就清楚了,在咱们的数据里,人们大多是啥心情,乐观的、悲观的还是说不上来的,心里有数了。
1. # 对每条文本进行情感分析并计算情感倾向性得分
2. sentiments = []
3. for text in data['text']:
4. s = SnowNLP(str(text))
5. sentiment_score = s.sentiments
6. sentiments.append(sentiment_score)
7.
8. # 情感类别定义
9. labels = ['负面', '中性', '正面']
10.
11. # 统计情感类别的数量
12. sentiment_counts = [0, 0, 0]
13. for sentiment in sentiments:
14. if sentiment < 0.3:
15. sentiment_counts[0] += 1
16. elif sentiment >= 0.3 and sentiment < 0.7:
17. sentiment_counts[1] += 1
18. else:
19. sentiment_counts[2] += 1
20.
21. # 创建情感分析饼图
22. plt.figure(figsize=(6, 6))
23.
24. # 设置颜色
25. colors = sns.color_palette('pastel')[0:3]
26.
27. # 绘制饼图
28. plt.pie(sentiment_counts, labels=labels, colors=colors, autopct='%1.1f%%', startangle=90)
29.
30. # 设置中文显示
31. font = FontProperties(fname='SimHei.ttf', size=12)
32. for text in plt.gca().texts:
33. text.set_fontproperties(font)
34.
35. # 添加标题
36. plt.title('情感分析结果', fontproperties=font)
37.
38. # 调整饼图为正圆
39. plt.axis('equal')
40.
41. # 显示饼图
42. plt.show()
代码运行后的到的情感分析饼状图如图6所示:

图6 情感分析
6、情感倾向演化分析
咱们这回的动作是,要看看随着时间变化,人们的情绪变化怎么样。就像看天气预报一样,不过咱们预报的是情绪。
首先,把刚才算出来的每条文本的情感得分,直接加到数据里去,这样每条数据都有个情感分数了。
接下来,咱们要按日期来一次大聚合,把同一天的情感得分平均一下,看看这一天的整体情绪怎么样。这样咱们就能得到每一天的平均情感得分了。
然后,咱们开始画图,这次画的是折线图,一看就知道每天情绪怎么变的。图的大小定为12x6,这样显示的信息多一些,看起来也舒服。
为了让图好看,咱们选了个色板,"husl",颜色鲜艳一点,把折线图画出来,用的是色板的第一个颜色。
标题、标签都设置好,用中文显示,并且字号也调了一下,让它更清晰易读。日期标签旋转了45度,这样不管日期多密集,每个标签都能看得清。
加了个图例,也是用中文显示。然后,为了让图看起来更有条理,加了横向的网格线,线条是虚线,透明度调低一些,不那么扎眼。
最后,调整了一下图形的边距,让整个图看起来更紧凑,信息显示得更完整。
一切设置好后,展示图形,这下咱们就能看到,随着时间的推移,整体的情绪是怎么变化的了。这可比单纯看数字有意思多了,一目了然,一折线图看天下情绪!
1. # 添加情感得分列
2. data['sentiment_score'] = sentiments
3.
4. # 按日期分组并计算每天的情感得分的平均值
5. sentiment_by_date = data.groupby(data['created_at'].dt.date)['sentiment_score'].mean()
6.
7. # 创建图形
8. plt.figure(figsize=(12, 6))
9.
10. # 设置颜色
11. colors = sns.color_palette("husl")
12.
13. # 绘制情感得分随时间变化的折线图,并设置颜色
14. sentiment_by_date.plot(kind='line', linewidth=2, color=colors[0])
15.
16. # 设置标题、标签和图例
17. plt.title('情感分数随时间变化', fontproperties=myfont, fontsize=16)
18. plt.xlabel('日期', fontproperties=myfont, fontsize=12)
19. plt.ylabel('情感分数', fontproperties=myfont, fontsize=12)
20. plt.xticks(rotation=45)
21. plt.legend(prop=myfont)
22.
23. # 设置网格线
24. plt.grid(axis='y', linestyle='--', alpha=0.5)
25.
26. # 调整图像边距
27. plt.tight_layout()
28.
29. # 显示图形
30. plt.show()
情感演化如图7所示:
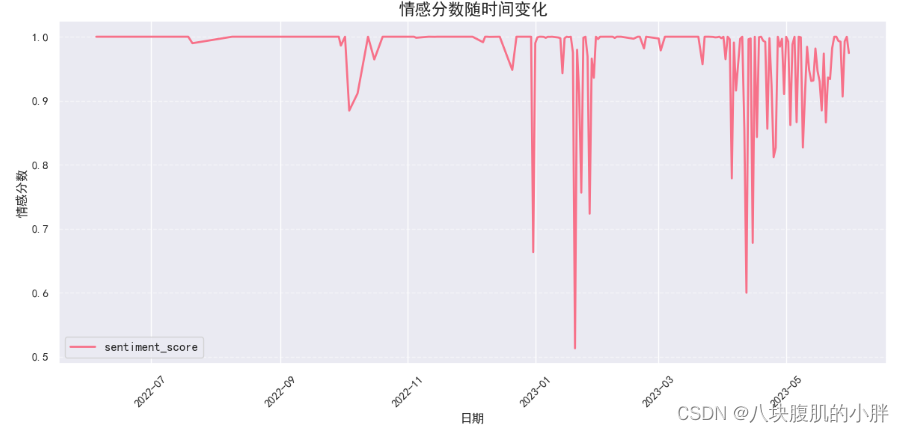
图7 情感演化
由图7可知,2023年1月网民情绪波动较大,分析与中国传统节日“春节”有关,且整体情绪处于中性和积极分值中;2023年4月至2023年6月期间,网民整齐情绪波动较大,分析其可能与4月的清明节、5月劳动节及6月的端午节有关。
7、总结
本次任务以“中国文化”为主题,首先通过爬虫对微博数据进行爬取,并对获取的数据进行预处理等操作。通过对微博数据进行词频统计,可以发现在关于中国文化的讨论中,最常出现的词是"中国",出现了4112次,紧随其后的是"文化",出现了2986次。此外,历史、传统和美食也是热门关键词,分别出现了1036次、1021次和645次。这反映了人们对中国文化的关注和兴趣。
使用kmeans算法进行文本聚类,将微博文本分为了三类。第一类聚焦于中国传统艺术,如京剧、国粹和戏曲,体现了中国丰富的艺术表演传统。第二类聚集了与中国文化、历史和传统节日有关的关键词,同时也涉及到微博和视频的讨论。第三类则关注街头文化、外国影响和中国城市的繁华景象。
情感分析的结果显示,人们对中国文化的态度整体上积极,积极情感得分为91.2%,消极情感得分为4.1%,中性情感得分为4.7%。这说明大多数人在微博上表达对中国文化的喜爱和肯定。
在情感演化的分析中,选取了时间范围从2022年6月到2023年6月。2023年1月,人们的情绪波动较大,可能与中国传统节日"春节"有关,整体情绪处于中性和积极分值中。而在2023年4月至6月期间,情绪波动再次增大,推测可能与清明节、劳动节和端午节等传统节日有关。
基于微博爬取的"中国文化"分析表明人们对中国文化表达了浓厚的兴趣和积极的态度。通过文本聚类和情感分析,我们深入了解了人们对中国文化的关注焦点和情感变化。这些结果有助于我们更好地理解和推动中国文化的传播与发展。