1.机器学习基础
(1)机器学习概述
机器学习是一种人工智能(AI)的分支,通过使用统计学和计算机科学的技术,使计算机能够从数据中学习并自动改进性能,而无需进行明确的编程。它涉及构建和训练机器学习模型,以便能够对未见过的数据进行预测或做出决策。 机器学习的基本目标是通过从数据中发现模式和规律,自动提取和学习数据中的特征,并用这些特征构建预测模型或分类模型。
(2)数学统计学概念
1、概率论:概率论是研究随机事件发生的概率和统计规律的数学分支。在机器学习中,概率论常用于建模和推断问题。
【1】朴素贝叶斯分类器:朴素贝叶斯分类器是一种基于贝叶斯定理和概率论的经典分类算法。它假设特征之间相互独立,并根据训练数据中各类别特征的概率分布来进行分类。
先引入一个概念:后验概率,是指在观测到一些证据或信息之后,对于某个事件发生的条件概率。也可以说后验概率是在考虑了先验概率以及额外的观测数据后,对于某个事件的概率进行修正或更新得到的结果。
人话解释一下:P(B|A) 是啥?晓得不?
在A发生的情况下B的概率!这玩意就是一个后验概率,栓Q~
热知识哦!学过概率统计的我们都知道~:
1.贝叶斯定理描述了在已知后验概率的情况下如何计算条件概率,可以用于推断未知事件的概率,或者在给定观测数据的情况下更新事件的概率。(类似通过已知的信息推断未知的信息。)
2.贝叶斯定理的数学表达式如下(计算公式,固定的!):
P(A|B) = (P(B|A) * P(A)) / P(B)
【1】P(A|B) 表示在事件 B 发生的条件下事件 A 发生的概率
【2】P(B|A) 表示在事件 A 发生的条件下事件 B 发生的概率
【3】P(A) 和 P(B) 分别表示事件 A 和事件 B 单独发生的概率。
那朴素贝叶斯分类器是啥?
对于一个给定的待分类样本 x,朴素贝叶斯分类器计算出每个类别 c 的后验概率 P(c|x)。根据贝叶斯定理,后验概率可以表示为先验概率 P(c) 与样本 x 属于类别 c 的条件概率 P(x|c) 的乘积,即:
朴素贝叶斯分类器做出了一个“朴素”假设,假设特征之间是独立的。
基于这个该假设,我们可以将条件概率 P(x|c) 可以分解为每个特征的条件概率的乘积:
P(x|c) = P(x₁|c) * P(x₂|c) * ... * P(xₙ|c),其中 x₁, x₂, ..., xₙ 是 x 的特征。
朴素贝叶斯分类器会对每个类别计算后验概率,并选择具有最高后验概率的类别作为预测结果。
那么这玩意怎么用呢?
我们可以假设有一个用于垃圾邮件分类的数据集,这个数据集包含如下特征:邮件主题的关键词、邮件长度、邮件中包含链接的数量。(3个特征)
使用这个数据集训练朴素贝叶斯分类器。假设我们有两个类别:垃圾邮件和非垃圾邮件。(2个类别)我们需要计算在每个类别下各特征的条件概率。
接下来,我们收到一封新的邮件,需要对其进行分类。假设这封邮件的主题包含关键词"优惠"、邮件长度为300字、包含2个链接。我们可以根据训练好的朴素贝叶斯分类器计算出这封邮件在垃圾邮件和非垃圾邮件类别下的条件概率。然后,我们选择概率较大的类别作为预测结果。如果,计算出垃圾邮件类别下的条件概率为0.6,非垃圾邮件类别下的条件概率为0.4,0.6大于0.4,因此我们预测这封邮件为垃圾邮件。
# 准备数据集(示例数据集)
#2个标签,3个特征
messages = [
("垃圾短信", "这是一条垃圾短信", 5, 2),
("垃圾短信", "赚大钱,快来加入我们的网络营销团队", 10, 3),
("非垃圾短信", "这是一条正常的短信", 3, 1),
("非垃圾短信", "明天一起吃饭吗", 4, 0)
]
# 将数据集划分为特征和标签
X = [(message[1], message[2], message[3]) for message in messages]#特征(第二、三、四列)
y = [message[0] for message in messages]#标签(第一列是标签)
# 特征提取
vectorizer = CountVectorizer()
X_text = [text for text, _, _ in X]
X_text = vectorizer.fit_transform(X_text)
X_other = [[length, links] for _, length, links in X]
X = [x_text + x_other for x_text, x_other in zip(X_text.toarray(), X_other)]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
#test_size: 测试集的比例,可以是浮点数(表示比例)或整数(表示样本数量),默认为0.25(即25%),#random_state: 随机数种子,用于控制划分的随机性,如果不设置该参数,每次划分的结果可能会有所不同
# 训练朴素贝叶斯模型
model = MultinomialNB()
model.fit(X_train, y_train)
# 预测并评估模型
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
上面这些代码训练一个朴素贝叶斯分类器,并使用测试数据集评估模型的准确性。首先,代码定义了一个示例数据集messages,它包含了4条短信数据,每条数据有3个特征和1个标签。接下来,将数据集划分为特征X和标签y。特征X由每条短信数据的第二、三、四列组成,标签y由每条短信数据的第一列组成。然后,在特征提取阶段,使用CountVectorizer对短信文本特征进行词频统计,获得词频矩阵X_text。同时也将其他两个特征(即短信长度和链接数量)提取为一个矩阵X_other。接下来,通过遍历X_text和X_other中的每个特征向量,将它们在维度上进行拼接,得到一个新的特征矩阵X。使用train_test_split函数将数据集划分为训练集和测试集,其中测试集占总数据集的20%(我数据集太少了,懒得敲太多玩意就定0.2了,其实正常是0.25)。使用MultinomialNB模型训练朴素贝叶斯分类器,使用训练集的特征和标签调用fit方法。使用测试集的特征调用predict方法进行预测,然后使用accuracy_score函数计算预测结果的准确性,并将结果打印出来。
只是个例子,如果理解有误或者各位觉得哪里需要改进的可以在评论区教学一下,本人新手~
【2】隐马尔可夫模型:隐马尔可夫模型是一种用于建模时序数据的概率图模型。它基于马尔可夫过程假设,通过观测序列和隐藏状态序列之间的概率关系来进行推断和预测。
(1)观测概率(Emission Probability):观测概率描述的是在给定隐藏状态下,观测序列中某个观测值出现的概率。观测概率表示了隐藏状态对观测值的影响程度。
举例:假设我们有一个天气模型,隐藏状态表示天气的状态(晴天、多云、雨天),观测序列表示观测到的天气相关的观测值(温度、湿度、风力等)。观测概率可以表示在特定的天气状态下,观测到某个温度、湿度或风力的概率。
(1)隐藏概率(Hidden Probability):隐藏概率描述的是在给定隐藏状态序列下,从一个隐藏状态转移到另一个隐藏状态的概率。隐藏概率表示了隐藏状态之间的转移规律。
举例:同样在天气模型中,隐藏概率可以表示从一个天气状态转移到另一个天气状态的概率。例如,在晴天的情况下,下一天仍然是晴天的概率较高,而转移到下一天是雨天的概率较低。
观测序列和隐藏状态序列之间的概率关系可以通过两个概率进行描述:转移概率和发射概率。
(1)转移概率(Transition Probability):转移概率描述的是在给定隐藏状态序列下,从一个隐藏状态转移到另一个隐藏状态的概率。
用A表示隐藏状态的集合,a和b表示A中的两个隐藏状态,则转移概率可以表示为
,即从状态a转移到状态b的概率。
(2)发射概率(Emission Probability):发射概率描述的是在给定隐藏状态下,观测序列中某个观测值出现的概率。用B表示观测值的集合,a表示一个隐藏状态,b表示一个观测值,则发射概率可以表示为
,即在状态a下观测到观测值b的概率。
根据这两个概率,可以建立一个隐马尔可夫模型。在模型中,转移概率和发射概率用矩阵形式表示:
-
转移概率矩阵(A):A[i][j]表示从隐藏状态i转移到隐藏状态j的概率。
-
发射概率矩阵(B):B[i][j]表示在隐藏状态i下观测到观测值j的概率。
此外,还有初始概率向量(π)表示隐藏状态序列的初始概率分布,π[i]表示隐藏状态i作为初始状态的概率。
通过转移概率矩阵、发射概率矩阵和初始概率向量,可以计算给定观测序列下,对应的隐藏状态序列的概率。这可以通过前向算法、后向算法、维特比算法等来实现。
(1)前向算法(Forward Algorithm)是用于计算隐马尔可夫模型中给定观测序列的概率的一种动态规划算法。它通过逐步计算每个时间步的前向概率,最终得到整个观测序列的概率。
(2)后向算法(Backward Algorithm)是用于计算隐马尔可夫模型中给定观测序列的概率的另一种动态规划算法。它通过逐步计算每个时间步的后向概率,最终得到整个观测序列的概率。
(3)维特比算法(Viterbi Algorithm)是用于解码隐马尔可夫模型中给定观测序列对应的最可能的隐藏状态序列的一种动态规划算法。它通过逐步计算每个时间步的最大概率路径,最终得到对应于观测序列的最可能的隐藏状态序列。
- 举例:假设有一个语音识别模型,隐藏状态表示不同的单词,观测序列表示录音中的声学特征。我们希望计算给定观测序列的概率以及对应的最可能的单词序列。
- 前向算法:前向算法可以计算给定观测序列的概率,从而确定语音识别模型是否能够准确地识别出该序列。它通过逐步计算每个时间步的前向概率,最终得到整个观测序列的概率。
- 后向算法:后向算法可以计算给定观测序列的概率,从而确定语音识别模型是否能够准确地识别出该序列。它通过逐步计算每个时间步的后向概率,最终得到整个观测序列的概率。
- 维特比算法:维特比算法可以解码给定观测序列对应的最可能的单词序列。它通过逐步计算每个时间步的最大概率路径,最终得到对应于观测序列的最可能的单词序列。例如,对于输入的声学特征序列,维特比算法可以找到最可能对应的单词序列,从而实现语音识别。

import numpy as np
class HMM:
def __init__(self, states, observations, start_prob, transition_prob, emission_prob):
self.states = states
self.observations = observations
self.start_prob = start_prob
self.transition_prob = transition_prob
self.emission_prob = emission_prob
def forward_algorithm(self, observations):
T = len(observations)
N = len(self.states)
# 初始化前向概率矩阵
forward_prob = np.zeros((T, N))
# 初始化初始状态概率
for i in range(N):
forward_prob[0][i] = self.start_prob[i] * self.emission_prob[i][self.observations.index(observations[0])]
# 递归计算前向概率
for t in range(1, T):
for j in range(N):
forward_prob[t][j] = sum(forward_prob[t-1][i] * self.transition_prob[i][j] * self.emission_prob[j][self.observations.index(observations[t])] for i in range(N))
# 返回观测序列的概率
return sum(forward_prob[T-1][i] for i in range(N))
def viterbi_algorithm(self, observations):
T = len(observations)
N = len(self.states)
# 初始化Viterbi矩阵和回溯矩阵
viterbi_prob = np.zeros((T, N))
backtrace = np.zeros((T, N), dtype=int)
# 初始化初始状态概率
for i in range(N):
viterbi_prob[0][i] = self.start_prob[i] * self.emission_prob[i][self.observations.index(observations[0])]
# 递归计算Viterbi概率和回溯
for t in range(1, T):
for j in range(N):
prob = [viterbi_prob[t-1][i] * self.transition_prob[i][j] * self.emission_prob[j][self.observations.index(observations[t])] for i in range(N)]
viterbi_prob[t][j] = max(prob)
backtrace[t][j] = np.argmax(prob)
# 回溯最佳路径
best_path = [0] * T
best_path[T-1] = np.argmax(viterbi_prob[T-1])
for t in range(T-2, -1, -1):
best_path[t] = backtrace[t+1][best_path[t+1]]
# 返回最佳路径和对应的概率
return [self.states[state] for state in best_path], max(viterbi_prob[T-1])
# 测试
states = ['Sunny', 'Rainy']
observations = ['Walk', 'Shop', 'Clean']
start_prob = [0.6, 0.4]
transition_prob = [[0.7, 0.3], [0.4, 0.6]]
emission_prob = [[0.1, 0.4, 0.5], [0.6, 0.3, 0.1]]
hmm = HMM(states, observations, start_prob, transition_prob, emission_prob)
obs = ['Walk', 'Shop', 'Clean']
prob = hmm.forward_algorithm(obs)
print(f"观测序列 {obs} 的概率: {prob}")
obs = ['Walk', 'Clean']
path, prob = hmm.viterbi_algorithm(obs)
print(f"观测序列 {obs} 的最可能路径: {path},概率: {prob}")
上面该代码定义了一个HMM类(隐式马尔可夫模型(Hidden Markov Model, HMM)),其中包括了初始化方法和两种算法:前向算法(forward_algorithm)和维特比算法(viterbi_algorithm)。在初始化方法中,需要传入的参数包括状态集合(states)、观测值集合(observations)、初始状态概率(start_prob)、状态转移概率(transition_prob)和观测值发射概率(emission_prob)。前向算法用于计算给定观测序列的概率。通过递归地计算前向概率矩阵,可以得到给定观测序列的整体概率。维特比算法用于找到给定观测序列的最可能状态路径。通过递归地计算Viterbi矩阵和回溯矩阵,可以找到观测序列最可能的状态路径以及对应的概率。
【3】高斯混合模型(GMM):高斯混合模型是一种概率模型,用于对复杂数据进行建模。它假设数据是由多个高斯分布组合而成的,通过找到最优的高斯分布参数来拟合数据分布。
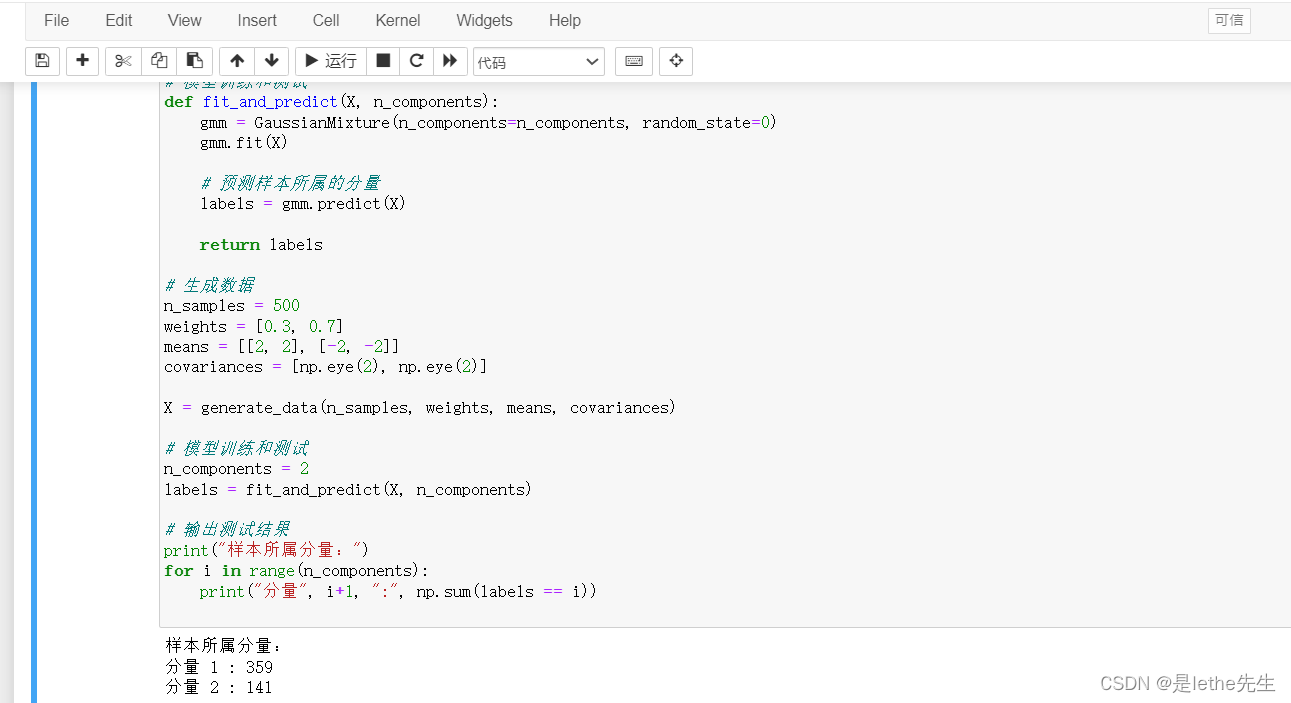
import numpy as np
from sklearn.mixture import GaussianMixture
# 生成高斯混合模型数据
def generate_data(n_samples, weights, means, covariances):
n_components = len(weights)
n_samples_per_component = np.random.multinomial(n_samples, weights)
X = []
for i in range(n_components):
samples = np.random.multivariate_normal(means[i], covariances[i], n_samples_per_component[i])
X.extend(samples)
return np.array(X)
# 模型训练和测试
def fit_and_predict(X, n_components):
gmm = GaussianMixture(n_components=n_components, random_state=0)
gmm.fit(X)
# 预测样本所属的分量
labels = gmm.predict(X)
return labels
# 生成数据
n_samples = 500
weights = [0.3, 0.7]
means = [[2, 2], [-2, -2]]
covariances = [np.eye(2), np.eye(2)]
X = generate_data(n_samples, weights, means, covariances)
# 模型训练和测试
n_components = 2
labels = fit_and_predict(X, n_components)
# 输出测试结果
print("样本所属分量:")
for i in range(n_components):
print("分量", i+1, ":", np.sum(labels == i))
GMM的计算主要涉及两个方面:参数估计和推断。
(1)参数估计:通过最大化似然函数来估计GMM的参数,包括每个高斯分布的均值、协方差和混合系数。常用的方法是使用期望最大化算法(Expectation Maximization,EM算法)来迭代优化参数。
(2)推断:给定已知参数的GMM模型,推断是指根据观测数据推断出最可能的聚类簇和相应的概率。常用的方法是使用后向算法(Backward Algorithm)或维特比算法(Viterbi Algorithm)来计算观测数据在每个高斯分布下的概率,并根据概率来判断数据的聚类簇。
GMM(高斯混合模型(Gaussian Mixture Model,简称GMM))的相关概念如下:
(1)高斯分布(Gaussian Distribution):也称为正态分布,是一种连续型概率分布,通过均值和方差来描述数据的分布情况。高斯分布的概率密度函数(PDF)符合钟形曲线的形状。
对于一维高斯分布:
对于多维高斯分布:
其中:
- x 是观测值(标量或向量)
- mu 是均值向量(标量或向量),表示数据的中心位置
- sigma^2 是方差(标量或协方差矩阵),表示数据的变化程度
- d 是数据的维度
- Cov 是协方差矩阵,用于描述不同维度之间的相关性
- exp() 表示自然指数函数,^ 表示矩阵的转置,^-1 表示矩阵的逆
- sqrt() 表示平方根函数
- det() 表示矩阵的行列式
一维高斯分布的参数是均值 mu 和方差 sigma^2,而多维高斯分布的参数是均值向量 mu 和协方差矩阵 Cov。
(3)混合系数(Mixture Coefficients):表示每个高斯分布对整体混合模型的贡献程度,通常用概率值表示。混合系数之和必须等于1。
设 N 为观测数据点的数量,混合系数的计算公式如下:
混合系数(Mixing Coefficient):
其中,
- pi_k 是第 k 个高斯分量的混合系数
- N_k 是分量 k 中观测数据的数量
- N 是总的观测数据数量
(4)均值(Mean):表示高斯分布的平均值,用于描述数据的中心位置。
高斯分布的平均值(均值)的公式可以表示为:
其中,
- μ 是高斯分布的平均值
- N 是观测数据点的数量
- Σ 表示求和符号
- xi 是观测数据点的值,取自高斯分布的样本集合
(5)协方差(Covariance),就是cov:表示高斯分布的变化程度,用于描述数据的分散情况。协方差矩阵可以表达不同维度之间的相关性。
公式如下:
其中,
- cov(X, Y) 表示 X 和 Y 之间的协方差
- N 是样本的数量
- Σ 表示求和符号
- xi 和 yi 是样本中的第 i 个观测值
- μx 和 μy 分别是 X 和 Y 的平均值
(6)最大似然估计:一种常用的参数估计方法,用于从给定的数据中估计出最合适的模型参数。其基本思想是选择能够使得观测值出现概率最大化的参数值。
给定一组来自总体分布的独立同分布的样本观测值x₁, x₂, ..., xₙ,假设这些观测值服从某个参数为θ的概率分布。似然函数(likelihood function)表示在给定观测数据的情况下,关于参数θ的函数。对于离散型随机变量,似然函数是各个样本观测值出现的概率的乘积。对于连续型随机变量,似然函数是各个样本观测值对应的概率密度函数值的乘积。
似然函数的公式为:
其中,L(θ)为似然函数,f(x; θ)表示样本观测值x在参数θ下的概率密度函数(对于连续型变量)或概率质量函数(对于离散型变量)。为了求解最大似然估计,通常会对似然函数取对数,这样不仅可以化简计算,还可以转为求解最大化对数似然函数的问题:
最大似然估计的目标是找到使得log L(θ)最大化的参数θ值。通常使用优化算法(如梯度下降法、牛顿法等)来估计最大似然估计值。
【4】概率图模型PGM:概率图模型是用于表示随机变量之间依赖关系的图结构。例如,贝叶斯网络和马尔可夫随机场就是常用的概率图模型,它们可以通过概率推断来解决建模和推断问题。主要分为两种类型:贝叶斯网络(Bayesian Networks)和马尔科夫随机场(Markov Random Fields)。
一些概念和术语相关如下:
(1)节点(Node):图中的一个圆圈,表示一个随机变量。
(2)边(Edge):图中的一条线,连接两个节点。有向边表示依赖关系,无向边表示相关关系。
(3)有向图(Directed Graph):节点之间通过有向边表示的依赖关系的图。
(4)无向图(Undirected Graph):节点之间通过无向边表示的相关关系的图。
(5)条件独立性(Conditional Independence):在概率图模型中,节点之间的依赖关系可以通过条件独立性来判断。如果给定一些节点的取值,其他节点的取值与这些节点的取值是独立的,那么这些节点之间是条件独立的。
(6)贝叶斯网络(Bayesian Networks):又称为有向无环图模型(Directed Acyclic Graph,简称DAG),是一种有向图模型。它通过节点和有向边来表示变量之间的依赖关系,节点表示随机变量,边表示变量之间的直接依赖关系。
假设有以下几个随机变量:
1. 学生的智力水平(Intelligence)
2. 学生的SAT成绩(SAT)
3. 学生的推荐信质量(Letter)
4. 学生的大学录取情况(Admission)
5. 学生的课程选择(Course)
在这个例子中,我们可以构建一个有向无环图模型来描述这些变量之间的依赖关系。图中的节点表示随机变量,有向边表示变量之间的依赖关系。
具体的依赖关系如下:
1、学生的智力水平(Intelligence)对学生的SAT成绩(SAT)有影响。
2、学生的推荐信质量(Letter)对学生的大学录取情况(Admission)有影响。
3、学生的智力水平(Intelligence)和SAT成绩(SAT)对学生的大学录取情况(Admission)有影响。
4、学生的大学录取情况(Admission)对学生的课程选择(Course)有影响。
该有向无环图模型可以如下所示:
Intelligence ---> SAT ---> Admission ---> Course
|
└--- Letter
在这个模型中,每个节点之间的关系可以通过概率分布来表示,例如:
1、P(Intelligence)
2、P(SAT | Intelligence)
3、P(Admission | Intelligence, SAT)
4、P(Course | Admission)
(7)马尔科夫随机场(Markov Random Fields):又称为无向图模型,是一种无向图模型。它通过节点和无向边来表示变量之间的相关关系,节点表示随机变量,边表示变量之间的直接相关关系。
假设有以下几个节点表示社交网络中的用户:
1. 用户A
2. 用户B
3. 用户C
4. 用户D
在这个例子中,我们可以构建一个无向图模型来表示用户之间的好友关系。图中的节点表示用户,边表示用户之间的好友关系。
具体的好友关系如下:
1、用户A和用户B是好友。
2、用户A和用户C是好友。
3、用户C和用户D是好友。
该无向图模型可以如下所示:
A
/ \
B C---D
在这个模型中,每个节点代表一个用户,边表示两个用户之间的好友关系。该无向图模型可以描述用户之间的社交关系,可以用来推断用户之间的相似性、关联度等信息。
【5】概率密度估计:概率密度估计是用于估计观测数据的概率密度函数的方法。常见的方法包括核密度估计和最大似然估计,这些方法可以用于建模数据分布和进行数据预测。
2、统计学:统计学是研究数据收集、分析和解释的科学,对于机器学习来说,统计学可以帮助我们理解数据和模型之间的关系。
3、线性代数:线性代数是研究向量空间和线性变换的数学分支,在机器学习中,线性代数常用于描述和处理高维数据。
4、微积分:微积分是研究变化和极限的数学分支,机器学习中的许多模型和算法都建立在微积分的基础上,例如梯度下降算法。
5、优化理论:优化理论是研究如何在给定约束条件下寻找最优解的数学分支,机器学习中许多问题都可以被视为优化问题,例如参数优化、模型选择等。
6、矩阵分解:矩阵分解是将一个矩阵分解为若干个子矩阵的过程,机器学习中的降维技术和推荐系统常常使用矩阵分解。常见的矩阵分解方法包括奇异值分解(Singular Value Decomposition,SVD)、QR分解、LU分解等。
(1)SVD:矩阵分解常用于降维、矩阵近似表示、推荐系统等领域。SVD分解是其中最常用的分解方法之一。
它将一个矩阵分解为三个矩阵的乘积,即:
其中,A是一个m×n的实数矩阵,U是一个m×m的正交矩阵,Σ是一个m×n的对角矩阵,V是一个n×n的正交矩阵的转置。正交矩阵是满足U^T * U = I和V^T * V = I的矩阵,其中I是单位矩阵。
相关概念:
【1】奇异值(Singular Values):Σ矩阵的对角线上的元素称为奇异值,按照从大到小排列。奇异值代表了原始矩阵A在每个特征向量方向上的重要性。
【2】左奇异向量(Left Singular Vectors):U矩阵的列向量称为左奇异向量,对应于原始矩阵A的特征向量。
【3】右奇异向量(Right Singular Vectors):V矩阵的列向量称为右奇异向量,对应于原始矩阵A的转置矩阵的特征向量。
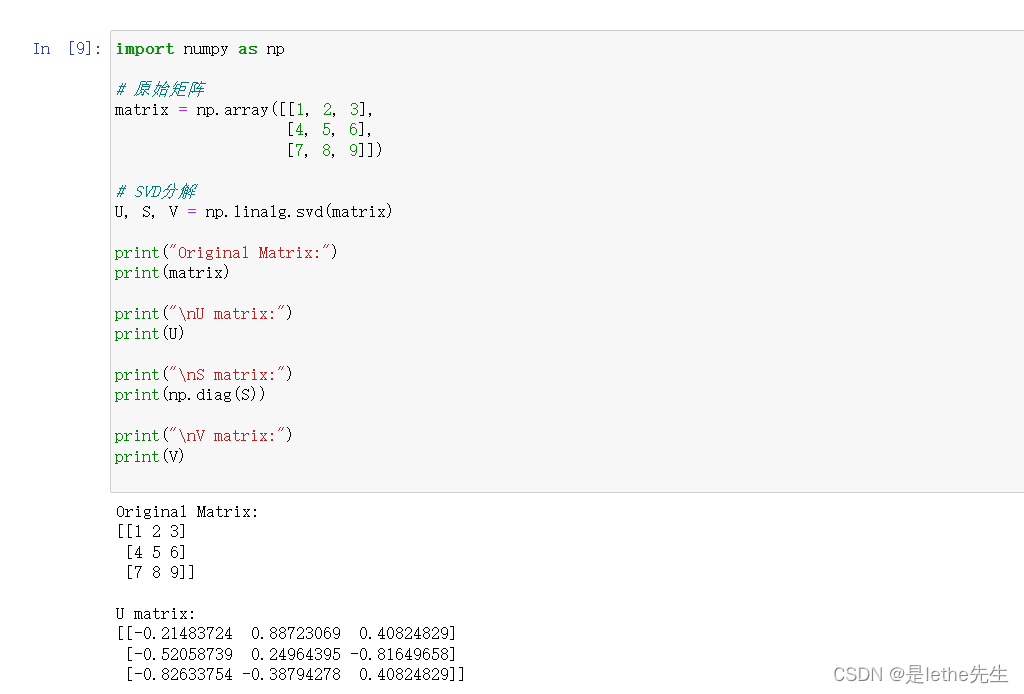
代码举例,下面代码首先定义了一个3x3的原始矩阵matrix,然后使用NumPy库的linalg.svd函数进行SVD分解。该函数会返回三个矩阵:U矩阵、S矩阵和V矩阵。其中,U矩阵包含了原始矩阵的左奇异向量,S矩阵是一个对角矩阵,包含了原始矩阵的奇异值,V矩阵是原始矩阵的右奇异向量的转置。
import numpy as np
# 原始矩阵
matrix = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
# SVD分解
U, S, V = np.linalg.svd(matrix)
print("Original Matrix:")
print(matrix)
print("\nU matrix:")
print(U)
print("\nS matrix:")
print(np.diag(S))
print("\nV matrix:")
print(V)
 (2)QR:一种常用的矩阵分解方法,它将一个矩阵分解为两个矩阵的乘积。
(2)QR:一种常用的矩阵分解方法,它将一个矩阵分解为两个矩阵的乘积。
即:
其中,A是一个m×n的实数矩阵,Q是一个m×m的正交矩阵,R是一个m×n的上三角矩阵。
相关概念、术语:
【1】正交矩阵(Orthogonal Matrix):Q是一个正交矩阵,满足,即它的转置和逆矩阵相等。正交矩阵具有特殊的性质,其列向量互相正交且模长为1。
【2】实数矩阵:由实数构成的矩阵。
下面是一些与实数矩阵相关的基本概念:
-
维度(Dimension):矩阵的维度是指矩阵的行数和列数。例如,一个m×n的矩阵有m行和n列,维度为m×n。
-
元素(Element):实数矩阵中的每个数都是矩阵的一个元素。可以用A_ij表示矩阵A中第i行第j列的元素。
-
行(Row):实数矩阵中的水平排列的元素组成的序列,可以用A_i表示矩阵A中的第i行。
-
列(Column):实数矩阵中的垂直排列的元素组成的序列,可以用A^j表示矩阵A中的第j列。
-
零矩阵(Zero Matrix):所有元素都是零的矩阵,用0表示。
-
对角矩阵(Diagonal Matrix):所有非对角线上的元素都是零的矩阵。对于一个n×n的对角矩阵D,有D_ij = 0当i ≠ j,否则D_ij = a_i,其中a_i为非零实数。
-
方阵(Square Matrix):行数和列数相等的矩阵。
-
转置矩阵(Transpose Matrix):矩阵的行和列互换得到的新矩阵,记作A^T。
-
逆矩阵(Inverse Matrix):若A是一个方阵且存在一个矩阵B,使得A·B = B·A = I(I为单位矩阵),则B称为A的逆矩阵,记作A^-1。
-
行列式(Determinant):矩阵的一种特征值,表示线性变换对面积/体积的伸缩倍数。
-
幂(Power):矩阵的自乘,A^n表示A连乘n次。
-
迹(Trace):方阵对角线上元素的和。
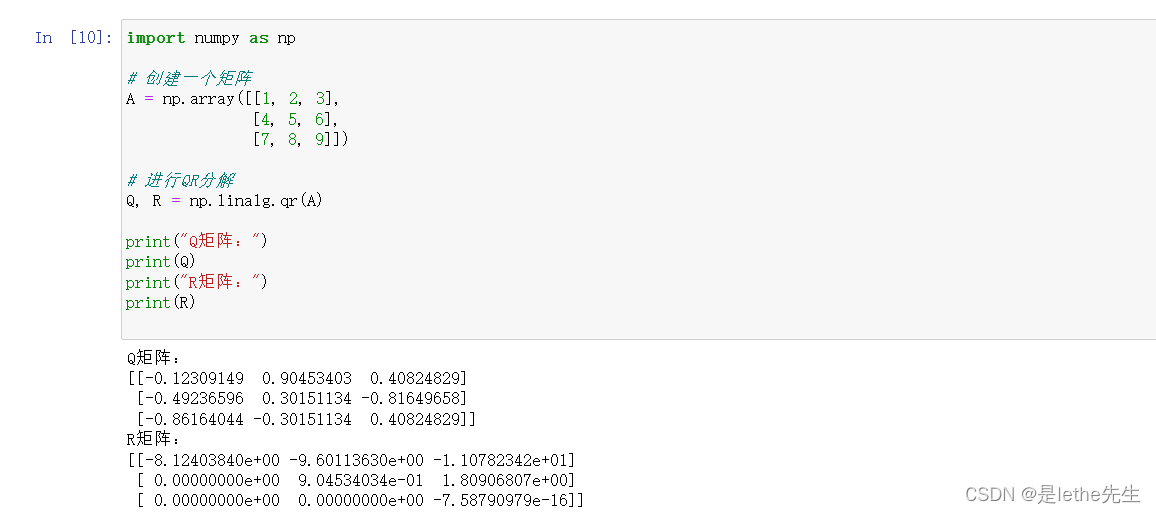
代码举例:
import numpy as np
# 创建一个矩阵
A = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
# 进行QR分解
Q, R = np.linalg.qr(A)
print("Q矩阵:")
print(Q)
print("R矩阵:")
print(R)(3)LU:LU分解是将一个矩阵分解为一个下三角矩阵和一个上三角矩阵的乘积。主要思想是通过高斯消元法来将矩阵A转化为上三角形式,然后将消元得到的乘积因子存储在L中。
高斯消元:一种用于求解线性方程组的数值方法。它通过一系列的行变换将线性方程组转化为一个上三角矩阵,从而可以直接求解出未知数的值。
核心思想:通过对线性方程组的系数矩阵进行一系列行变换,将其转化为一个上三角矩阵。这样得到的上三角矩阵可以通过回代法直接求解出未知数的值。行变换的基本操作包括:交换两行、用一个非零常数乘以某行、将某行的倍数加到另一行上。
高斯消元法2步(举例):
- 假设有一个包含n个未知数和n个线性方程的线性方程组。我们可以将其写成增广矩阵的形式[A|B],其中A是系数矩阵,B是常数向量
第一步: 将系数矩阵A化为上三角矩阵。
- 对于第一列(即第一个未知数所在的列),找到非零元素所在的行,将该行交换到第一行。
- 将第一行的倍数加到后面的每一行上,使得第一列的元素变为0。
- 重复上述步骤,在第二列、第三列等依次对应的未知数上进行操作,直到将整个矩阵A化为上三角形式。
第二步: 回代求解未知数的值。
- 从最后一行开始,由最后一行的系数推导出倒数第二行的未知数值。
- 再由倒数第二行的系数推导出倒数第三行的未知数值,以此类推,直到求解出第一个未知数的值。
使用高斯消元法求解线性方程组可以得到唯一解(如果存在)或者零解(如果方程组不可解)
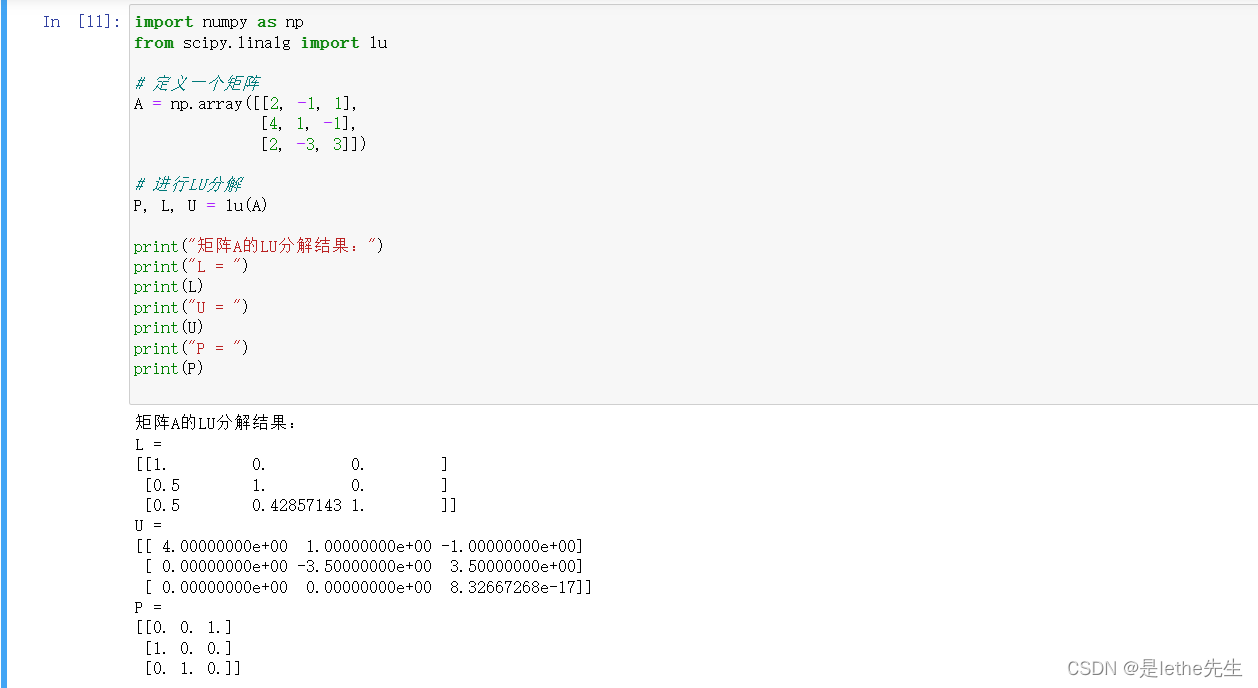
代码举例(LU):
import numpy as np
from scipy.linalg import lu
# 定义一个矩阵
A = np.array([[2, -1, 1],
[4, 1, -1],
[2, -3, 3]])
# 进行LU分解
P, L, U = lu(A)
print("矩阵A的LU分解结果:")
print("L = ")
print(L)
print("U = ")
print(U)
print("P = ")
print(P)
7、维度灾难:维度灾难是指当数据处于高维空间时,由于样本稀疏性等原因,导致机器学习算法性能下降的现象。
8、交叉验证:交叉验证是一种评估模型性能的方法,通过将数据集划分为训练集和测试集,并多次重复训练和测试过程,可以避免过拟合和欠拟合问题。交叉验证的目的是在有限的数据集上尽可能地充分利用数据来评估模型的性能。
常用的交叉验证方法包括k折交叉验证和留一交叉验证。在k折交叉验证中,将数据集划分为k个子集,每次用k-1个子集作为训练集,剩下的一个子集作为测试集。依次对每个子集进行训练和测试,最后将结果进行平均得到最终的评估结果。懒得整理了,先看完深度学习再整这里~
(3)模型基础技术名词
机器学习模型可以分为监督学习、无监督学习和强化学习三大类。
【1】监督学习:通过使用带有标签的训练数据,监督学习的目标是构建一个模型来预测或分类未知的数据。它包括分类问题(预测离散标签)和回归问题(预测连续值)。
【2】无监督学习:无监督学习的目标是从未标记的数据中发现隐藏的结构和模式。它包括聚类(将相似的数据分组)和降维(减少数据的维度)等技术。
【3】强化学习:强化学习通过将智能体暴露在与其环境的交互中,使其能够通过试错的方式学习并改进自己的行为。智能体通过奖励和惩罚来判断其行为是否正确,并优化其策略以获得最大奖励。
其他相关含义:
【1】逻辑回归(Logistic Regression):一种用于分类问题的线性模型,通过将输入特征与权重相乘并进行激活函数处理得出输出。
【2】支持向量机(Support Vector Machine):一种用于分类和回归问题的监督学习方法,通过将数据映射到高维空间中,找到一个超平面来最大化分类边界。
【3】决策树(Decision Tree):一种树状模型,通过对输入数据按照特征值进行分割,以决策树的形式表示规则。
【4】随机森林(Random Forest):一种集成学习方法,通过同时训练多个决策树来减少过拟合。
【5】朴素贝叶斯(Naive Bayes):一种基于贝叶斯定理的概率分类算法,通过假设特征之间相互独立来进行分类。
【6】K近邻(K-Nearest Neighbors):一种基于实例的学习方法,通过比较新样本与训练集中最近的K个样本的标签来进行分类。
【7】线性回归(Linear Regression):一种用于回归问题的线性模型,通过拟合一条直线或平面来预测连续值输出。
【8】主成分分析(Principal Component Analysis):一种降维技术,通过线性变换将高维数据映射到低维空间中,保留最大方差的主成分。
【9】神经网络(Neural Network):一种模仿人脑神经网络结构的机器学习模型,通过多层神经元之间的连接来进行学习和预测。
【10】梯度下降(Gradient Descent):一种优化算法,通过迭代调整模型参数,使损失函数最小化。




![[C#][opencvsharp]opencvsharp sift和surf特征点匹配](https://img-blog.csdnimg.cn/direct/37c3f9c3b367492d947ce0f074544a44.jpeg)


