 What does a data scientist really do?
What does a data scientist really do?
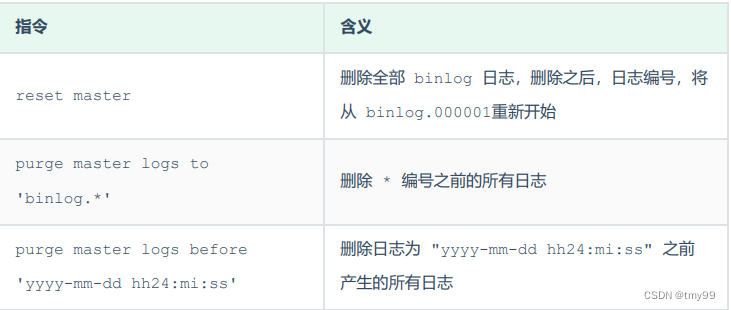
Identifying the pattern in cultural consumption, making fancy graph, engage a dialogue between data and the existing literature, refining hypothesis….(done within one months with three to four online meetings with partners = no more than 35 hours to agree on the main assertions)
| Litteratue review | 60 | 20% |
| Primary definition of the hypothesis | 5 | 2% |
| Getting familiar with the codebook and the survey | 10 | 3% |
| Explore the potential variable of interest | 20 | 7% |
| Rename the variable of interest | 15 | 5% |
| Recode the variable of interest and translate in English | 70 | 23% |
| Non answer cleaning | 5 | 2% |
| Rename the labels (levels) | 10 | 3% |
| Primary analysis of the outputs (inspect the recoded variable and bivariate an) | 20 | 7% |
| Reformulation of some hypothesis | 5 | 2% |
| Plotting the first MCA and analyze them | 15 | 5% |
| Compare model strength and understand the primary outputs | 5 | 2% |
| Refining hypothesis and assertions | 15 | 5% |
| Writing the article | 50 | 16% |
| 305 | 100% |
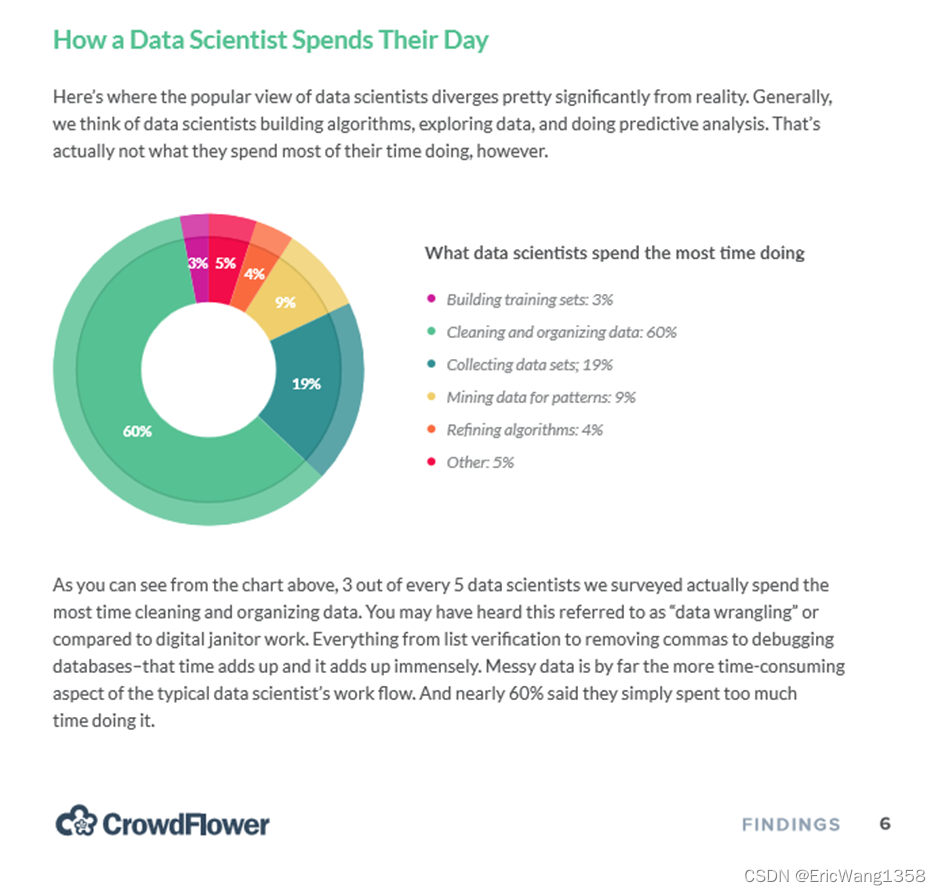
What is “cleaning and organizing data”?
Definition:
- Cleaning and organizing data refer to the process of preparing raw data for analysis by identifying and correcting errors, inconsistencies, and inaccuracies, and structuring it in a way that facilitates effective analysis.
Steps Involved:
- Data Cleaning:
- Handling missing values.
- Removing duplicates.
- Correcting errors and inconsistencies.
- Data Organization:
- Structuring data in a readable format.
- Categorizing and labeling data.
- Creating meaningful variables.
Removing Duplicates:
# Removing duplicate rows
unique_data <- unique(raw_data)
Correcting Errors and Inconsistencies
# Replacing incorrect values
corrected_data <- replace(raw_data, incorrect_condition, replacement_value)
Structuring Data:
# Creating a data frame
structured_data <- data.frame(variable1 = vector1, variable2 = vector2, ...)
Categorizing and Labeling Data:
# Creating factors for categorical variables
categorized_data <- factor(raw_data$variable, levels = c("Category1", "Category2", ...))
Creating Meaningful Variables:
# Creating a new variable based on existing ones
raw_data$new_variable <- raw_data$variable1 + raw_data$variable2
Common issue with online survey
Data not writen in the good format: the typical issue with year of birth
家庭状况与教育经历
47、您的出生年份是?(请填写整数,例如:1984) (填空题 *必答)
________________________
Section Familial Situation and Education background
47. Which year are you born (Please write number such as 1984)
In the raw data, we have 2 people born in 1898 = 120 years old
Given the average age of the population they are likely to be born in 1998
25 respondents answered using the format Year/Month/Birth
Ex: 19940105
2 respondents answered using very original format
Ex: 930524 / 197674
1 respondent just answer 1
How to clean efficiently with R?
tidyR
= it is a very important package to transform a long table from a wide table
Will not be covered, but basic operation using tidyr are explained in this website: https://mgimond.github.io/ES218/Week03b.html
dplyr
dplyr is a very important package that enables you to select specific variable and data, and to transform them
dplyr Package in R:
-
Selection of Specific Variables:
select()function: It allows you to choose specific columns (variables) from a data frame.# Example: Selecting columns "variable1" and "variable2" selected_data <- select(your_data_frame, variable1, variable2)
-
Filtering Data:
filter()function: Enables you to subset your data based on specific conditions-
# Example: Filtering data where "variable1" is greater than 10 filtered_data <- filter(your_data_frame, variable1 > 10)
-
Transformation (Mutating) Data:
mutate()function: Allows you to create new variables or modify existing ones.-
# Example: Creating a new variable "new_variable" as a transformation of existing variables mutated_data <- mutate(your_data_frame, new_variable = variable1 + variable2)
-
Arranging Data:
arrange()function: Sorts rows based on specified variables.-
# Example: Sorting data based on "variable1" in ascending order sorted_data <- arrange(your_data_frame, variable1)
-
Summarizing Data:
summarize()function: Aggregates data, often used with functions likemean,sum, etc.-
# Example: Calculating the mean of "variable1" summary_stats <- summarize(your_data_frame, mean_variable1 = mean(variable1))
The magrittr package
The magrittr package offers a set of operators which make your code more readable by:
structuring sequences of data operations left-to-right, avoiding nested function calls, minimizing the need for local variables and function definitions, and making it easy to add steps anywhere in the sequence of operations.
The operators pipe their left-hand side values forward into expressions that appear on the right-hand side, i.e. one can replace f(x) with x %>% f(), where %>% is the (main) pipe-operator.
https://magrittr.tidyverse.org/