论文地址:[2303.15904] 无掩码视频实例分割 (arxiv.org)
论文代码:https://github.com/SysCV/MaskFreeVis
目录
一、摘要
二、介绍
三、方法
3.1 时间掩码一致性
3.2 时间KNN-patch Loss
3.3 训练MaskFreeVIS
四. 数据集
五.消融实验
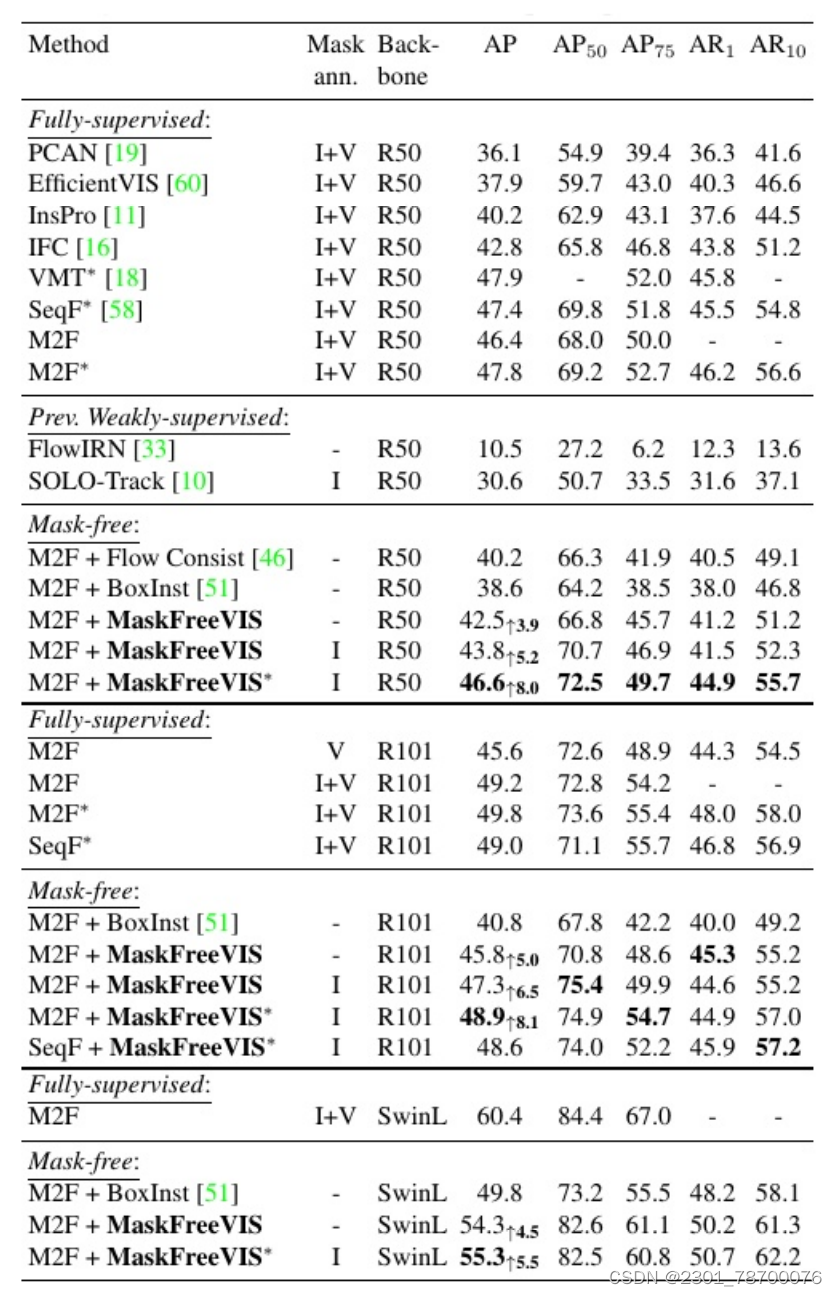
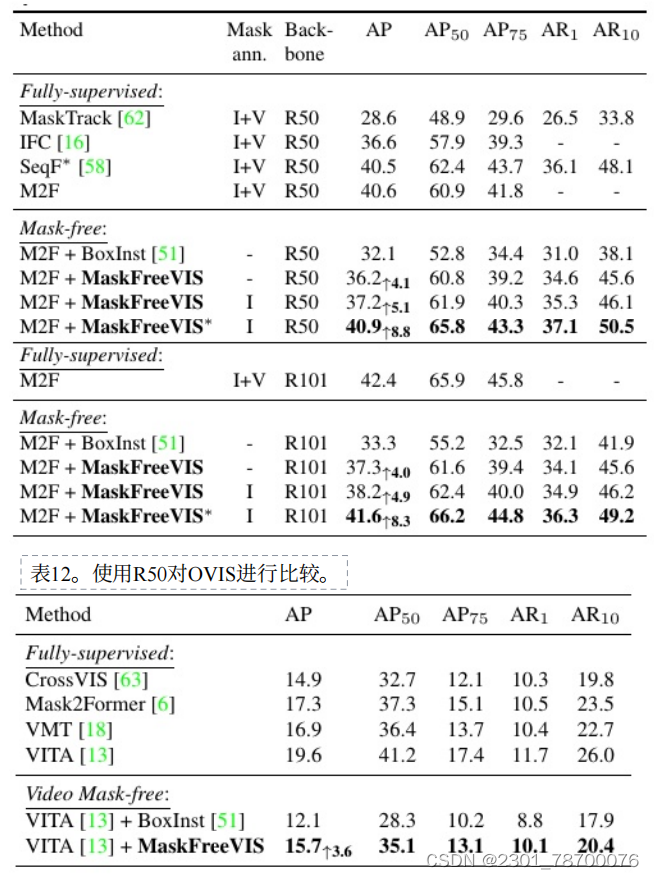
六. 结果
七. 结论
一、摘要
二、介绍
当前问题:
(1)最先进的VIS模型使用来自VIS数据集的完整视频注释进行训练。
视频注释是昂贵的,特别是关于对象掩码标签。即使是粗糙的基于多边形的掩膜标注,也⽐标注视频边界框慢好⼏倍。昂贵的掩码注释使得现有的VIS基准难以扩展,从⽽限制了覆盖的对象类别的数量。
(2)弱监督的单图像⽅法在学习掩膜预测时没有利⽤时间线索,导致直接应⽤于视频时精度较低。
所做工作:
(1)通过研究⽆掩码设置下的弱监督VIS问题,重新审视了完全掩码注释的必要性。
(2)利⽤时间掩码⼀致性约束(不同帧中对应于相同基础对象的区域应该具有相同的掩码标签)来进⾏VIS的⽆掩模学习。
具体贡献:
(1)为了利⽤时间信息,开发了⼀种新的⽆参数时间KNN-patchLoss,它利⽤⽆监督的⼀对kpatch对应来利⽤时间掩模⼀致性。
(2)基于TK-Loss,开发了MaskFreeVIS⽅法,可以在没有任何掩码注释的情况下训练现有的最先进的VIS模型。
(3)MaskFreeVIS是第⼀个获得⾼性能分割结果的⽆掩模VIS⽅法。MaskFreeVIS在不使⽤视频或注释的情况下,在具有挑战性的YTVIS2019基准上实现了42.5%的AP。我们的⽅法进⼀步扩展到更⼤的主⼲⽹,在没有视频掩码注释的情况下,在swing-l主⼲⽹上实现了55.3%的掩码AP。
三、方法
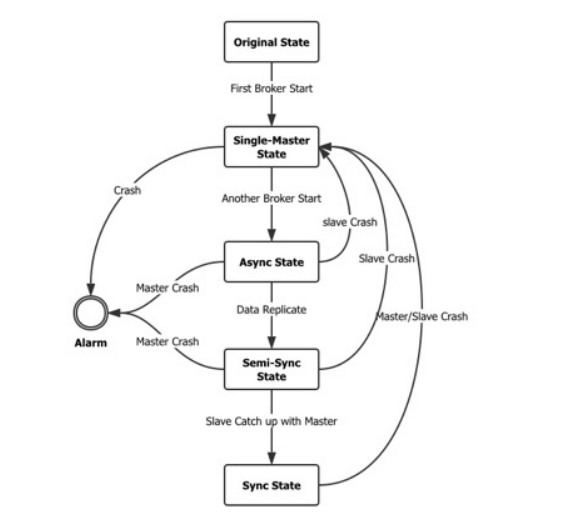
3.1 时间掩码一致性
视频描述了场景的连续变化。物体和背景移动、变形、被遮挡,经历光照变化、运动模糊和噪声,从⽽导致⼀系列通过逐渐变换⽽密切相关的不同图像。
场景中的⼀个⼩区域要么属于⼀个物体,要么属于背景。该区域投影对应的像素在每一帧中应该具有相同的掩膜预测,因为它们属于相同的底层物理对象或背景区域。然⽽,视频中的动态变化导致了实质性的外观变化,作为⼀种⾃然的数据增强形式。因此,对应于相同基础对象区域的像素在时间变化下应该具有相同的掩膜预测,这⼀事实提供了⼀个强⼤的约束,即时间掩膜⼀致性,可⽤于掩膜监督。
利用时间掩膜一致性约束的困难来自于在视频帧之间建立可靠对应的关系。
3.2 时间KNN-patch Loss
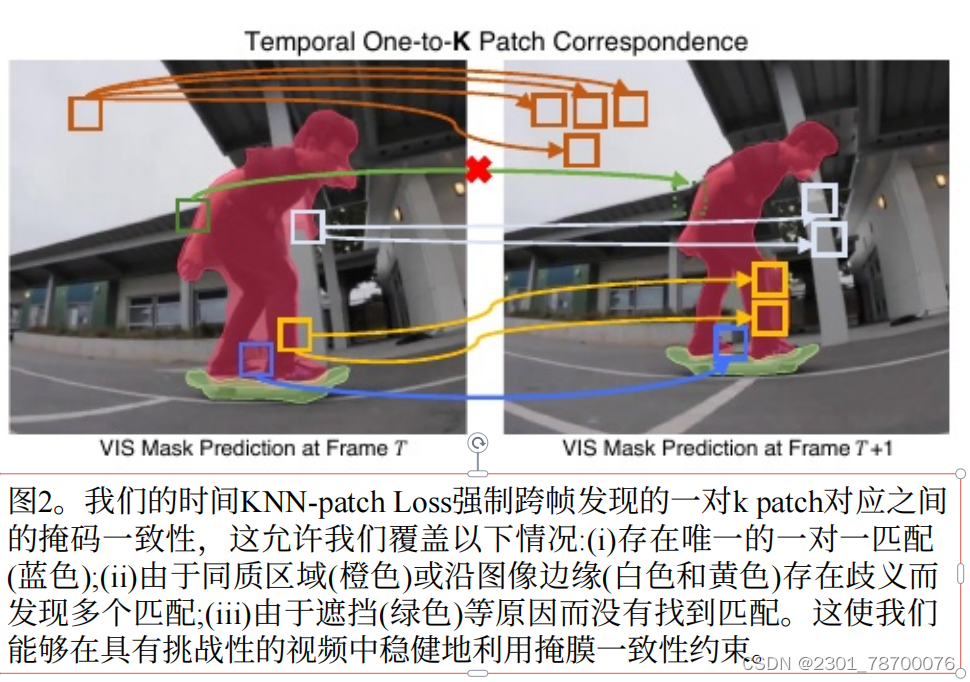
时间KNN-patchLoss(TK-Loss)是基于⼀种简单⽽灵活的跨帧对应估计。建⽴了1-k对应关系。这包括传统的⼀对⼀对应(K=1),其中存在⼀个独特的定义良好的匹配。然⽽,这也允许我们在遮挡情况下处理不存在对应关系(K=0)的情况,在同⽣区域情况下处理⼀对多(K≥2)的情况。在发现多个匹配的情况下,由于它们的外观相似,这些最常属于相同的底层对象或背景。通过更密集的监督,这进⼀步有利于我们的mask⼀致性⽬标。⽅法如图,包含四个主要步骤。
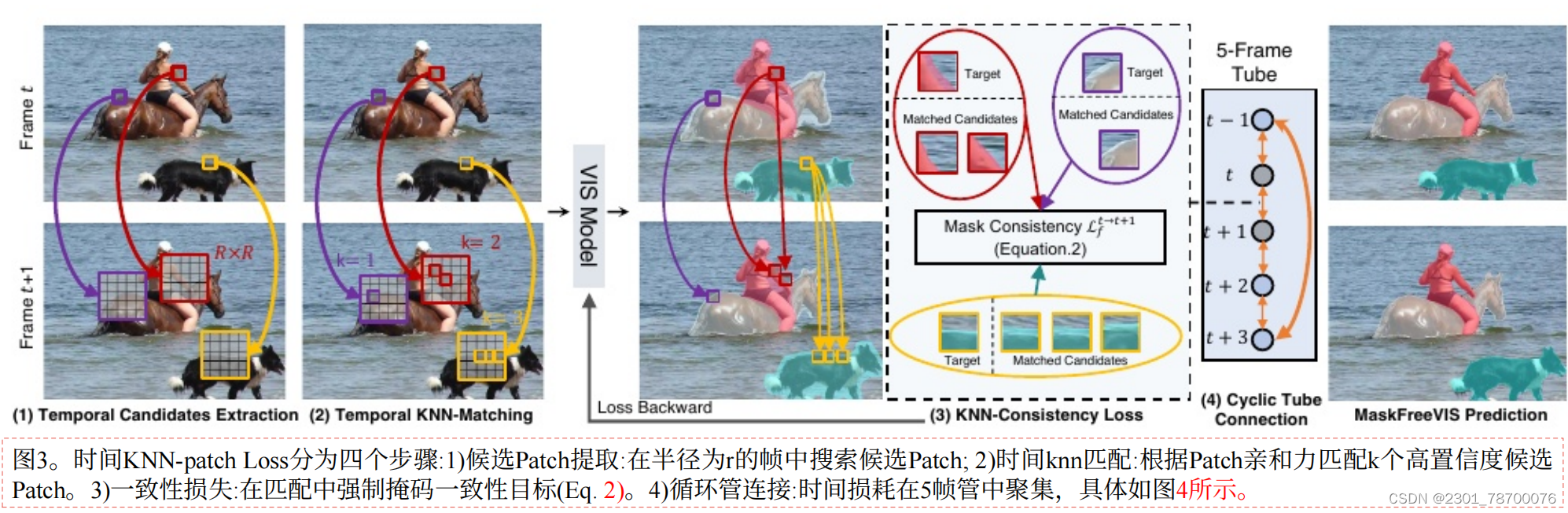
(1)候选Patch提取
(2)时间knn匹配
通过简单的距离计算对候选补丁进⾏匹配,L2norm是最有效的补丁匹配指标。我们选择了patch距离最⼩的前K个匹配dt→tp→p。 最后,通过强制执⾏⼀个最⼤的patch距离D作为dt→tp→p来去除低置信度的匹配 对于每个位置p,从集合Spt→t→p→i}i进⾏匹配。

(3)一致性损失
设Mpt∈[0,1]表⽰⼀个对象的预测⼆进制实例掩码,在帧t中的位置p处求值。为了确保时间掩码⼀致性约束,对Spt→t}中⼀个时空点(p,t)与其估计的对应点之间的掩码预测不⼀致进⾏惩罚。
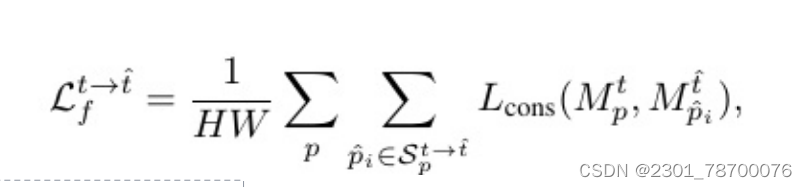
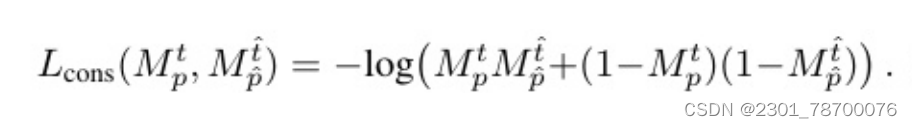
(4)循环管连接
以循环的⽅式计算整个管的时间损失。起始帧连接到结束帧,这在时间上最遥远的两个帧之间引⼊了直接的⻓期掩码⼀致性。全管时间TK-Loss由式给出
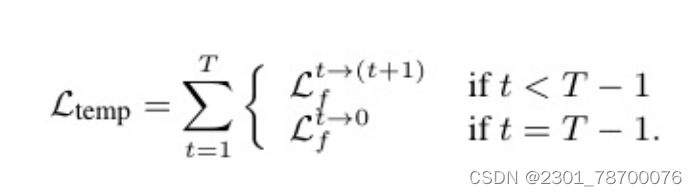
3.3 训练MaskFreeVIS
(1)联合时空正则化
为了训练MaskFreeVIS,除了⽤于时间掩码⼀致性的temporal-poralKNN-patchLoss外,我们还利⽤现有的空间弱分割损失来联合强制帧内⼀致性。 为了探索来⾃图像边界框和像素颜⾊的空间弱监督信号,我们利⽤具有代表性的Box投影损失Lproj和成对损失Lpair来代替监督掩码学习损失。投影损失Lproj强制对象掩模在图像的~x轴和~y轴上的投影p0与它的地真盒掩模⼀致。对于具有T帧的时间管,我们同时优化管as的所有预测帧掩模
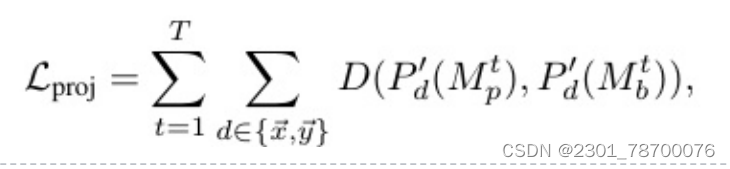
D为骰⼦损失,p0为x/y轴⽅向的投影函数,Mpt和Mbt分别为第t帧下预测的实例掩码及其GT掩码。为清晰起⻅,这⾥省略了对象实例索引。另⼀⽅⾯,成对损失Lpair限制了单帧的空间相邻像素。对于具有颜⾊相似性>σ像素的位置p0i和p0j像素,强制其预测的掩膜标签⼀致,如下式:
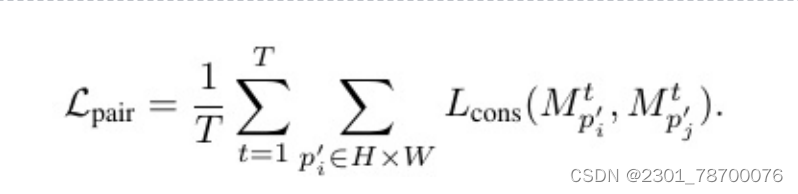
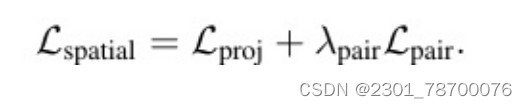

(2)基于transformer的方法的集成
现有的关于无监督分割损失的⼯作与单阶段或两阶段检测器相耦合,并且仅解决单幅图像的情况。然⽽,最先进的VIS⽅法是基于变压器的。这些⼯作通过集合预测进⾏对象检测,其中在评估损失时,预测的实例掩码需要与掩码标注匹配。为了将⽆遮罩VIS训练与变压器相结合,⼀个关键的修改是在实例序列匹配步骤中。
作为初步尝试,⾸先从估计的实例掩码中产⽣边界框预测。然后,我们使⽤VIS⽅法中使⽤的顺序匹配成本函数。为了计算整个序列的匹配代价,在帧间平均每个单独的边界框的L1损失和⼴义IoU损失。然⽽,我们观察到帧平均的匹配结果很容易受到单个离群帧的影响,特别是在弱分割设置下,导致训练期间的不稳定和性能下降。 时空盒掩码匹配没有使⽤前述的帧级匹配,⽽是凭经 验找到了时空盒-掩码匹配,以在弱分割设置下产⽣实质性的改进。我们⾸先将每个预测实例掩码转换为边界框掩码,并将ground-truth盒转换为盒掩码。然后,我们分别从ground-truth盒掩码序列和预测盒掩码序列中随机采样等量的点。与Mask2Former不同,我们 只采⽤骰⼦IoU损失来计算序列匹配成本。交叉熵累积了每个像素的误差,导致⼤⼩物体之间的 值不平衡。相⽐之下,IoU损失是标准化的每个对象,导致⼀个平衡的度量。在消融实验中,研究了⽆掩模 VIS设置下不同的实例序列匹配策略。
(3)基于图像的MaskFreeVIS预训练
⼤多数VIS模型都是从COCO实例分割数据集上预训练的模型初始化的。为了完全消除掩模监督,我们仅使⽤无监督在COCO上预训练MaskFreeVIS。我们在单帧上采⽤空间⼀致性损失来代替Mask2Former中原始的GT掩码损失,同时基于相同的图像COCO培训设置。因此,我们在实验中提供了两种训练设置,⼀种是在训练过程中同时去除图像和视频蒙版,另⼀种是采⽤COCO蒙版注释预训练的权值。在这两种情况下,都没有使⽤视频掩模注释。
四. 数据集
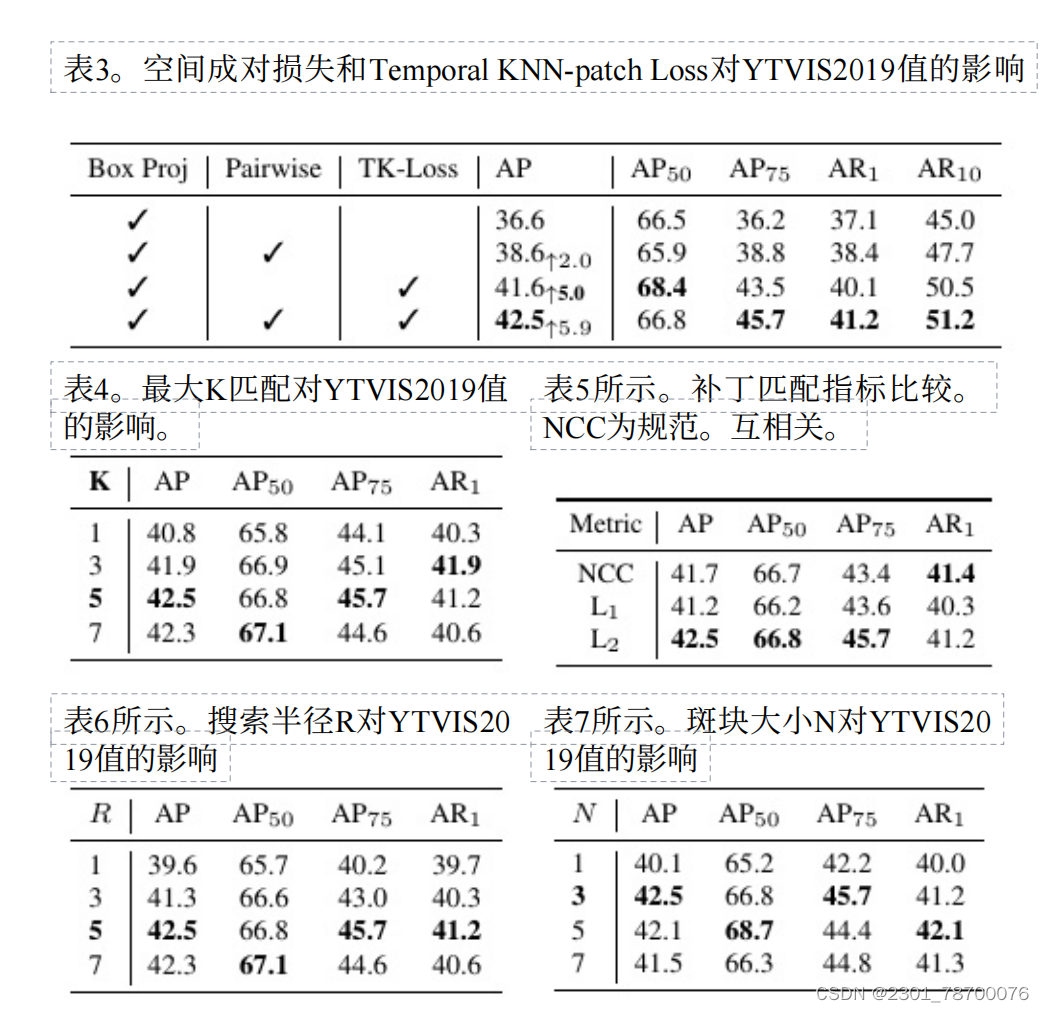
五.消融实验
六. 结果