在上一篇文章中,我们成功验证了Intel Threading Building Blocks (TBB) 与 OpenMP 在多线程并行处理方面的加速潜力。为了更深入地理解这些技术在实际应用场景中的效能提升,接下来我们将目光转向目标开发板环境,进一步探究这两种框架在嵌入式系统上的实际加速效果。
一、OPENMP加速效果测试
在探讨OPENMP对性能提升的影响时,我们首先遇到了一个有趣的插曲。通常情况下,OpenMP作为一项编译器层面的支持特性,只需在编译阶段通过简单的命令行标志即可启用,例如在使用make构建时追加-fopenmp参数,或在CMake项目中配置如set(CMAKE_CXX_FLAGS “-fopenmp”),即可轻松为项目开启并行处理能力。
然而,在针对RV1106平台的交叉编译环境中,我们发现原生的交叉编译工具链并不支持OpenMP功能。通过执行arm-rockchip830-linux-uclibcgnueabihf-gcc -v来查看编译器详细信息时,注意到其构建选项中包含了–disable-libgomp,这意味着该编译器在构建之初就已排除了对OpenMP库的支持。这可能是因为RV1106芯片本身为单核架构,考虑到硬件资源有限,制造商在设计工具链时并未考虑多线程并行处理的需求。

尽管如此,面对手头仅有的嵌入式开发环境限制,我们并未止步于此。经过深入研究和探索,最终成功实现了对该交叉编译器OpenMP支持的集成。虽然整个过程尚未完全优化与标准化,此处暂且略过具体实现细节,我们将简要概述如何使编译器支持OpenMP以及随后进行的测试效果评估。
交叉编译器不支持的临时解决办法:
1、从源码编译openmp:
官网介绍:https://www.openmp.org/specifications/
下载地址:https://github.com/OpenMP/sources
编译过程比较简单:在源码中将makefile的configure 后面指定当前的编译工具链路径和生产路径。
all:
mkdir src/libgomp/build ; \
cd src/libgomp/build && \
../configure --host=arm-rockchip830-linux-uclibcgnueabihf && \
$(MAKE)
2、编译好的libgomp放入工具链
我生成的libgomp 路径在 libgomp-master\src\libgomp\build.libs 下面,将其中的
libgomp.so libgomp.so.1 libgomp.so.1.0.0 以及上一级目录的libgomp.spec 一共四个文件拷贝到工具链的以下两个路径:
/arm-rockchip830-linux-uclibcgnueabihf/arm-rockchip830-linux-uclibcgnueabihf/lib/lib
/arm-rockchip830-linux-uclibcgnueabihf/arm-rockchip830-linux-uclibcgnueabihf/sysroot/lib/
编译测试:
在编译过程中,直接加入-fopenmp指令:
arm-rockchip830-linux-uclibcgnueabihf-g++ OptCvTestWin.cpp -o test -fopenmp
即可生成可执行文件。
此处不用cmake编译,因为写好的cmakelist中配置的-fopenmp不生效。
加速效果:
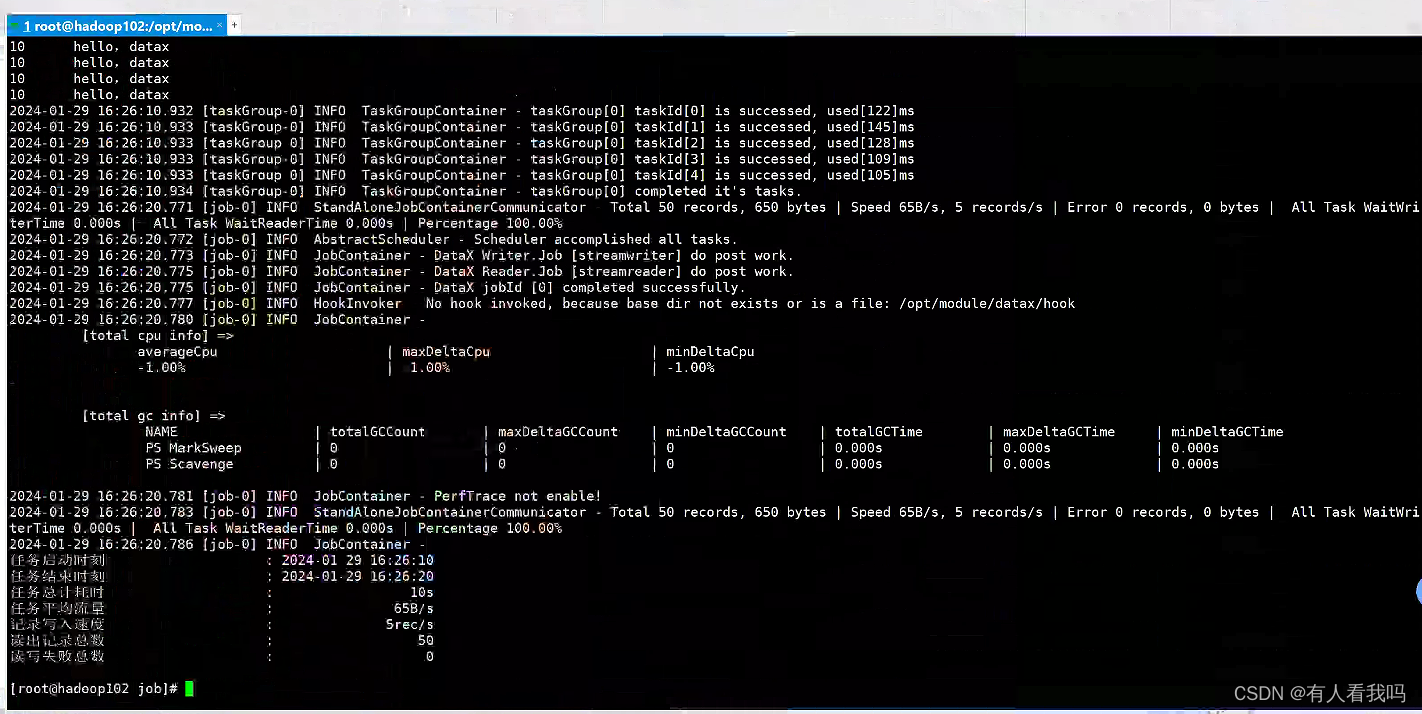
# ./test
cv F1 Time = 79 rslt 3.20518e+10
cv F2 Time = 153 rslt 3.20518e+10
cv F1 Time = 91 rslt 2.99779e+10
cv F2 Time = 166 rslt 2.99779e+10
cv F1 Time = 76 rslt 2.93042e+10
cv F2 Time = 166 rslt 2.93042e+10
cv F1 Time = 75 rslt 3.1813e+10
cv F2 Time = 158 rslt 3.1813e+10
cv F1 Time = 75 rslt 3.18925e+10
cv F2 Time = 177 rslt 3.18925e+10
cv F1 Time = 81 rslt 3.07783e+10
cv F2 Time = 158 rslt 3.07783e+10
cv F1 Time = 90 rslt 3.05833e+10
cv F2 Time = 156 rslt 3.05833e+10
cv F1 Time = 76 rslt 2.83669e+10
cv F2 Time = 158 rslt 2.83669e+10
cv F1 Time = 91 rslt 3.42625e+10
cv F2 Time = 170 rslt 3.42625e+10
cv F1 Time = 75 rslt 3.44049e+10
cv F2 Time = 163 rslt 3.44049e+10
对比了多线程方案F1与常规单线程方案F2的执行速度(单位ms)。实验发现,随着OpenMP线程数从2增至10,F1的加速效果逐步提升;但超过10个线程后,加速收益不再明显增加。这表明存在一个最优线程数阈值,在该范围内使用OpenMP能有效提高程序性能。
测试的代码放出来:
整体上跑10遍观察效果,选取其中一部分数据打印看结果是否一致。
#include <fstream>
#include <iostream>
#include <vector>
//#include <opencv2/opencv.hpp>
//#include "libgomp.h"
#include <future>
#include <thread>
//#include <tbb/parallel_for.h>
//#include <tbb/blocked_range.h>
#include <chrono>
//using namespace cv;
using namespace std;
typedef std::chrono::system_clock::time_point SYS_TIME;
SYS_TIME getClock()
{
return std::chrono::system_clock::now();
}
double getMsTime(SYS_TIME start, SYS_TIME end)
{
return std::chrono::duration_cast<std::chrono::milliseconds>(end-start).count();
}
int main()
{for (int j =0; j <10; j++)
{
const int iCnt = 1000000;
std::vector<float> data1(iCnt);
std::vector<float> data2(iCnt);
for (float i = 0; i < iCnt; ++i) {
data1[i] = rand(); // 假设填充了随机整数
data2[i] = data1[i];
}
float fv1=0;
SYS_TIME start = getClock();
#pragma omp parallel num_threads(4)
{
#pragma omp for
for(int i = 0; i < iCnt; i++)
{
data1[i]+=i;
if(i>iCnt/3&&i<iCnt/3+30)
fv1+=data1[i];
}
}
cout << " cv F1 Time = " << getMsTime(start, getClock()) <<" rslt "<< fv1 << endl;
float fv2=0;
SYS_TIME start2 = getClock();
{
for (float i = 0; i < iCnt; i++)
{
data2[i]+=i;
if(i>iCnt/3&&i<iCnt/3+30)
fv2+=data2[i];
}
}
cout << " cv F2 Time = " << getMsTime(start2, getClock()) <<" rslt "<< fv2 << endl;
} return 0;
}
后记:
在本阶段的技术探索中,我们遇到了CMakeLists.txt中设置的OpenMP编译选项未能生效的问题。尽管GPT暂时无法给出具体原因,但当前的重点已转向验证OpenMP的实际加速效果,并发现尽管其在基准测试中表现出显著优势,但在实际业务工程应用时却遭遇了挑战。由于现有工程完全依赖于由CMake构建的Makefile体系,直接修改Makefile以整合OpenMP支持无疑会增加额外的工作量。

1、一种解决方案是联系RK(瑞芯微)厂家,请求提供一个内建OpenMP支持的交叉编译器版本,或者自行构建这样一个工具链。然而,鉴于目前的知识储备尚不足以完成这一任务,该方案暂时尚未实施
2、另个一个可行的方案是,将预先编译好的libgomp库作为静态或动态链接库与可执行文件进行链接。这种方法虽然理论上可行,但在调用OpenMP接口和管理库依赖方面可能会遇到复杂性问题,需要进一步技术评估。
接下来的步骤,我们将把注意力转向Intel Threading Building Blocks (TBB) 并行编程库,计划对其进行编译和测试验证,以对比分析其对项目性能提升的效果。


![[嵌入式系统-7]:龙芯1B 开发学习套件 -4- LoongIDE 集成开发工具的使用-创建应用程序工程、编译、下载、调试](https://img-blog.csdnimg.cn/direct/d0b1f2488ef848809938af3c2cb4b36a.png)