文章目录
- 1. DQL定义
- 2. 基础查询
- 3. 条件查询(WHERE)
- 4. 分组查询(GROUP BY)
- 5. 过滤分组(HAVING)
- 6. 排序(ORDER BY)
- 7. 限制查询结果的条数(LIMIT)
- 8. 多表查询
- 8.1 多表关系
- 8.1.1 一对多
- 8.1.2 多对多
- 8.1.3 一对一
- 8.2 连接
- 8.2.1 交叉连接(CROSS JOIN)
- 8.2.2 内连接(INNER JOIN)
- 8.2.3 外连接(OUTER JOIN)
- 8.2.3.1 左外连接(LEFT OUTER JOIN)
- 8.2.3.2 右外连接(RIGHT OUTER JOIN)
- 8.2.4 自连接
- 8.2.5 联合查询(UNION)
- 8.3 子查询
- 8.3.1 标量子查询
- 8.3.2 列子查询
- 8.3.3 行子查询
- 8.3.4 表子查询
- 8.4 探讨表连接与子查询
1. DQL定义
-
DQL(Data Query Language):数据查询语言,用来查询表中的记录,主要包含 SELECT 命令,来查询表中的数据。
-
DQL完整语法:
SELECT DISTINCT <select_list> #去重 FROM <left_table><join_type> JOIN <right_table> #表连接 ON <join_condition> #连接条件 WHERE <where_condition> #条件查询 GROUP BY <group_by_list> #分组 HAVING <having_condition> #对分组后的结果进行聚合筛选 ORDER BY <order_by_condition> #排序 LIMIT <limit_number> #行数限制 -
DQL语句执行顺序:

但是在实际应用中,数据库不一定会按照 JOIN、 WHERE、 GROUP BY 的顺序来执行查询。因为它们会进行一系列优化,在不改变查询结果的前提下,把执行顺序打乱,从而让查询执行得更快。
2. 基础查询
-
查询多个字段:
select 字段1, 字段2, 字段3 from 表名; -
查询所有字段:
select * from 表名; -
设置别名:
select 字段1 [ as 别名1 ] , 字段2 [ as 别名2 ] from 表名;表别名只在执行查询时使用,并不在返回结果中显示。而字段定义别名之后,会返回给客户端显示,显示的字段为字段的别名。
-
去除重复记录:
select distinct 字段列表 from 表名;使用DISTINCT关键字的注意事项:
-
DISTINCT 关键字只能在 SELECT 语句中使用。
-
在对一个或多个字段去重时,DISTINCT 关键字必须在所有字段的最前面。
-
如果 DISTINCT 关键字后有多个字段,则会对多个字段进行组合去重,也就是说,只有多个字段组合起来完全是一样的情况下才会被去重。
-
因为 DISTINCT 只能返回它的目标字段,而无法返回其它字段,所以在实际情况中,我们经常使用 DISTINCT 关键字来返回不重复字段的条数。
SELECT COUNT(DISTINCT name,age) FROM student;
-
3. 条件查询(WHERE)
-
在 MySQL 中,如果需要有条件的从数据表中查询数据,可以使用 WHERE 关键字来指定查询条件。
WHERE 查询条件 -
查询条件可以是:
- 带比较运算符和逻辑运算符的查询条件
- 带 BETWEEN AND 关键字的查询条件
- 带 IS NULL 关键字的查询条件
- 带 IN 关键字的查询条件
- 带 LIKE 关键字的查询条件
比较运算符 功能 > 大于 >= 大于等于 < 小于 <= 小于等于 = 等于 <> 或 != 不等于 between … and … 在某个范围之内(含最小、最大值) in(…) 在in之后的列表中的值,多选一 like 占位符 模糊匹配(_匹配单个字符, %匹配任意个字符) is null 是null
| 逻辑运算符 | 功能 |
|---|---|
| and 或 && | 并且 (多个条件同时成立) |
| or 或 || | 或者 (多个条件任意一个成立) |
| not 或 ! | 非 , 不是 |
-
模糊匹配查询(like 占位符)的注意事项:
-
默认情况下,LIKE 关键字匹配字符的时候是不区分大小写的。如果需要区分大小写,可以加入 BINARY 关键字。
SELECT name FROM tb_students_info WHERE name LIKE BINARY 't%'; -
“%”通配符可以到匹配任意字符,但是不能匹配 NULL。也就是说 “%”匹配不到 tb_students_info 数据表中值为 NULL 的记录。
-
-
范围查询(between and)的注意事项:
- 在 MySQL 中,BETWEEN AND 能匹配指定范围内的所有值,包括起始值和终止值。
- 起始值和终止值的顺序不能颠倒。
-
空值查询(is null)的注意事项:
- IS NULL 是一个整体,不能将 IS 换成“=”。
- 空值不同于 0,也不同于空字符串。
4. 分组查询(GROUP BY)
-
在 MySQL 中,GROUP BY 关键字可以根据一个或多个字段对查询结果进行分组。多个字段分组查询时,会先按照第一个字段进行分组。如果第一个字段中有相同的值,MySQL 才会按照第二个字段进行分组。如果第一个字段中的数据都是唯一的,那么 MySQL 将不再对第二个字段进行分组。
GROUP BY <字段名> -
使用场景:
-
GROUP BY 关键字可以和 GROUP_CONCAT() 函数一起使用。GROUP_CONCAT() 函数会把每个分组的字段值都显示出来。
mysql> SELECT `sex`, GROUP_CONCAT(name) FROM tb_students_info -> GROUP BY sex; +------+----------------------------+ | sex | GROUP_CONCAT(name) | +------+----------------------------+ | 女 | Henry,Jim,John,Thomas,Tom | | 男 | Dany,Green,Jane,Lily,Susan | +------+----------------------------+ 2 rows in set (0.00 sec) -
在数据统计时,GROUP BY 关键字经常和聚合函数一起使用。
mysql> SELECT sex,COUNT(sex) FROM tb_students_info -> GROUP BY sex; +------+------------+ | sex | COUNT(sex) | +------+------------+ | 女 | 5 | | 男 | 5 | +------+------------+ 2 rows in set (0.00 sec) -
WITH POLLUP 关键字用来在所有记录的最后加上一条记录,这条记录是上面所有记录的总和,即统计记录数量。
mysql> SELECT sex,GROUP_CONCAT(name) FROM tb_students_info ->GROUP BY sex WITH ROLLUP; +------+------------------------------------------------------+ | sex | GROUP_CONCAT(name) | +------+------------------------------------------------------+ | 女 | Henry,Jim,John,Thomas,Tom | | 男 | Dany,Green,Jane,Lily,Susan | | NULL | Henry,Jim,John,Thomas,Tom,Dany,Green,Jane,Lily,Susan | +------+------------------------------------------------------+ 3 rows in set (0.00 sec)
-
5. 过滤分组(HAVING)
-
在 MySQL 中,可以使用 HAVING 关键字对分组后的数据进行过滤。
HAVING <查询条件> -
HAVING 关键字和 WHERE 关键字都可以用来过滤数据,且 HAVING 支持 WHERE 关键字中所有的操作符和语法。
-
但是 WHERE 和 HAVING 关键字也存在以下几点差异:
- 一般情况下,WHERE 用于过滤数据行,而 HAVING 用于过滤分组。
- WHERE 查询条件中不可以使用聚合函数,而 HAVING 查询条件中可以使用聚合函数。
- WHERE 在数据分组前进行过滤,而 HAVING 在数据分组后进行过滤 。
- 执行顺序: where > 聚合函数 > having 。
6. 排序(ORDER BY)
-
MySQL 提供了 ORDER BY 关键字来对查询结果进行排序。
ORDER BY <字段名> [ASC|DESC] -
注意事项:
- 当排序的字段中存在空值时,ORDER BY 会将该空值作为最小值来对待。
- ORDER BY 指定多个字段进行排序时,MySQL 会按照字段的顺序从左到右依次进行排序。
7. 限制查询结果的条数(LIMIT)
-
LIMIT 是 MySQL 中的一个特殊关键字,用于指定查询结果从哪条记录开始显示,一共显示多少条记录。
LIMIT 初始位置,记录数 LIMIT 记录数 OFFSET 初始位置 -
注意事项:
- LIMIT 后的两个参数必须都是正整数。
- “LIMIT n”与“LIMIT 0,n”返回结果相同。
- 如果是分页查询,起始索引 = (查询页码 - 1) 每页显示记录数*。
8. 多表查询
- 在关系型数据库中,表与表之间是有联系的,所以在实际应用中,经常使用多表查询。多表查询就是同时查询两个或两个以上的表。
8.1 多表关系
- 项目开发中,在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,基本上分为三种: 一对多(多对一)、多对多、一对一 。
8.1.1 一对多
案例: 部门 与 员工的关系
关系: 一个部门对应多个员工,一个员工对应一个部门
实现: 在多的一方建立外键,指向一的一方的主键

8.1.2 多对多
案例: 学生 与 课程的关系
关系: 一个学生可以选修多门课程,一门课程也可以供多个学生选择
实现: 建立第三张中间表,中间表至少包含两个外键,分别关联两方主键

8.1.3 一对一
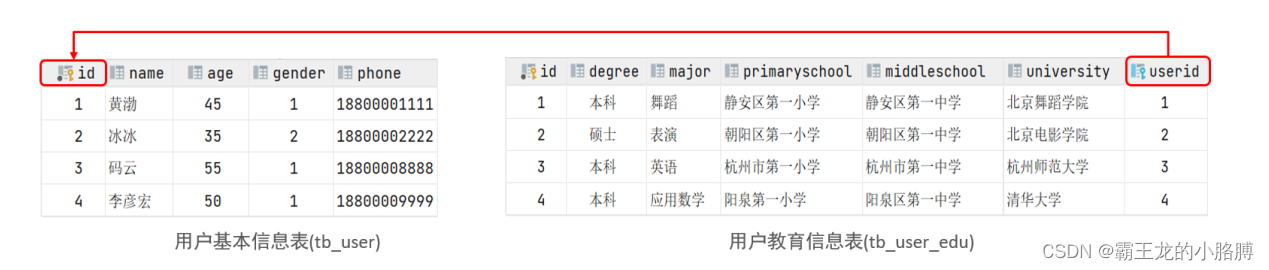
案例: 用户 与 用户详情的关系
关系: 一对一关系,多用于单表拆分,将一张表的基础字段放在一张表中,其他详情字段放在另一张表中,以提升操作效率
实现: 在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE)
8.2 连接
- 在 MySQL 中,连接查询主要有交叉连接、内连接、外连接、自连接。
8.2.1 交叉连接(CROSS JOIN)
-
定义:交叉连接(CROSS JOIN)一般用来返回连接表的笛卡尔积。
-
语法:
# SELECT <字段名> FROM <表1> CROSS JOIN <表2> [WHERE子句] # SELECT <字段名> FROM <表1>, <表2> [WHERE子句] SELECT * FROM tb_course CROSS JOIN tb_students_info WHERE tb_students_info.course_id = tb_course.id; -
注意事项:
- 如果在交叉连接时使用 WHERE 子句,MySQL 会先生成两个表的笛卡尔积,然后再选择满足 WHERE 条件的记录。因此,表的数量较多时,交叉连接会非常非常慢。一般情况下不建议使用交叉连接。
- 在 MySQL 中,多表查询一般使用内连接和外连接,它们的效率要高于交叉连接。
8.2.2 内连接(INNER JOIN)
-
定义:内连接(INNER JOIN)主要通过设置连接条件的方式,来移除查询结果中某些数据行的交叉连接。简单来说,就是利用条件表达式来消除交叉连接的某些数据行。内连接使用 INNER JOIN 关键字连接两张表,并使用 ON 子句来设置连接条件。
-
语法:
# SELECT <字段名> FROM <表1> INNER JOIN <表2> [ON子句] SELECT s.name,c.course_name FROM tb_students_info s INNER JOIN tb_course c ON s.course_id = c.id; -
注意事项:
- 如果没有连接条件,INNER JOIN 和 CROSS JOIN 在语法上是等同的,两者可以互换。
8.2.3 外连接(OUTER JOIN)
-
内连接的查询结果都是符合连接条件的记录,而外连接会先将连接的表分为基表和参考表,再以基表为依据返回满足和不满足条件的记录。外连接可以分为左外连接和右外连接,下面根据实例分别介绍左外连接和右外连接。
-
注意事项:
- 多个表左/右连接时,在 ON 子句后连续使用 LEFT/RIGHT OUTER JOIN 或 LEFT/RIGHT JOIN 即可。
- 使用外连接查询时,一定要分清需要查询的结果,是需要显示左表的全部记录还是右表的全部记录,然后选择相应的左连接和右连接。
8.2.3.1 左外连接(LEFT OUTER JOIN)
-
定义:左外连接又称为左连接,使用 LEFT OUTER JOIN 关键字连接两个表,并使用 ON 子句来设置连接条件。
-
语法:下述语法中,“表1”为基表,“表2”为参考表。左连接查询时,可以查询出“表1”中的所有记录和“表2”中匹配连接条件的记录。如果“表1”的某行在“表2”中没有匹配行,那么在返回结果中,“表2”的字段值均为空值(NULL)。
SELECT <字段名> FROM <表1> LEFT OUTER JOIN <表2> <ON子句> -
案例:
mysql> SELECT * FROM tb_course; +----+-------------+ | id | course_name | +----+-------------+ | 1 | Java | | 2 | MySQL | | 3 | Python | | 4 | Go | | 5 | C++ | | 6 | HTML | +----+-------------+ 6 rows in set (0.00 sec) mysql> SELECT * FROM tb_students_info; +----+--------+------+------+--------+-----------+ | id | name | age | sex | height | course_id | +----+--------+------+------+--------+-----------+ | 1 | Dany | 25 | 男 | 160 | 1 | | 2 | Green | 23 | 男 | 158 | 2 | | 3 | Henry | 23 | 女 | 185 | 1 | | 4 | Jane | 22 | 男 | 162 | 3 | | 5 | Jim | 24 | 女 | 175 | 2 | | 6 | John | 21 | 女 | 172 | 4 | | 7 | Lily | 22 | 男 | 165 | 4 | | 8 | Susan | 23 | 男 | 170 | 5 | | 9 | Thomas | 22 | 女 | 178 | 5 | | 10 | Tom | 23 | 女 | 165 | 5 | | 11 | LiMing | 22 | 男 | 180 | 7 | +----+--------+------+------+--------+-----------+ 11 rows in set (0.00 sec)mysql> SELECT s.name,c.course_name FROM tb_students_info s LEFT OUTER JOIN tb_course c -> ON s.`course_id`=c.`id`; +--------+-------------+ | name | course_name | +--------+-------------+ | Dany | Java | | Henry | Java | | NULL | Java | | Green | MySQL | | Jim | MySQL | | Jane | Python | | John | Go | | Lily | Go | | Susan | C++ | | Thomas | C++ | | Tom | C++ | | LiMing | NULL | +--------+-------------+ 12 rows in set (0.00 sec)
8.2.3.2 右外连接(RIGHT OUTER JOIN)
-
定义:右外连接又称为右连接,右连接是左连接的反向连接。使用 RIGHT OUTER JOIN 关键字连接两个表,并使用 ON 子句来设置连接条件。
-
语法:与左连接相反,右连接以“表2”为基表,“表1”为参考表。右连接查询时,可以查询出“表2”中的所有记录和“表1”中匹配连接条件的记录。如果“表2”的某行在“表1”中没有匹配行,那么在返回结果中,“表1”的字段值均为空值(NULL)。
SELECT <字段名> FROM <表1> RIGHT OUTER JOIN <表2> <ON子句> -
案例:
mysql> SELECT s.name,c.course_name FROM tb_students_info s RIGHT OUTER JOIN tb_course c -> ON s.`course_id`=c.`id`; +--------+-------------+ | name | course_name | +--------+-------------+ | Dany | Java | | Green | MySQL | | Henry | Java | | Jane | Python | | Jim | MySQL | | John | Go | | Lily | Go | | Susan | C++ | | Thomas | C++ | | Tom | C++ | | NULL | HTML | +--------+-------------+ 11 rows in set (0.00 sec)
8.2.4 自连接
-
自连接查询,顾名思义,就是自己连接自己,也就是把一张表连接查询多次。而对于自连接查询,可以是内连接查询,也可以是外连接查询 。
-
语法:
# SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件 ... ; select a.name '员工', b.name '领导' from emp a left join emp b on a.managerid =b.id;
8.2.5 联合查询(UNION)
-
对于union查询,就是把多次查询的结果合并起来,形成一个新的查询结果集。
-
语法:
SELECT 字段列表 FROM 表A UNION [ ALL ] SELECT 字段列表 FROM 表B ; -
注意事项:
-
对于联合查询的多张表的列数必须保持一致,字段类型也需要保持一致。
-
union all 会将全部的数据直接合并在一起,union 会对合并之后的数据去重。
-
8.3 子查询
-
子查询是 MySQL 中比较常用的查询方法,通过子查询可以实现多表查询。子查询指将一个查询语句嵌套在另一个查询语句中。子查询可以在 SELECT、UPDATE 和 DELETE 语句中使用,而且可以进行多层嵌套。在实际开发时,子查询经常出现在 WHERE 子句中。
-
语法:其中,操作符可以是比较运算符和 IN、NOT IN、EXISTS、NOT EXISTS 等关键字。
WHERE <表达式> <操作符> (子查询) -
注意事项:
- 在 SELECT 语句中,子查询可以被嵌套在 SELECT 语句的列、表和查询条件中,即 SELECT 子句,FROM 子句、WHERE 子句、GROUP BY 子句和 HAVING 子句。
8.3.1 标量子查询
-
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。
-
常用的操作符:= <> > >= < <=
select * from emp where dept_id = (select id from dept where name = '销售部');
select * from emp where entrydate > (select entrydate from emp where name = '方东白');
8.3.2 列子查询
-
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。
-
常用的操作符:IN 、NOT IN 、 ANY 、SOME 、 ALL
操作符 描述 IN 在指定的集合范围之内,多选一 NOT IN 不在指定的集合范围之内 ANY 子查询返回列表中,有任意一个满足即可 SOME 与ANY等同,使用SOME的地方都可以使用ANY ALL 子查询返回列表的所有值都必须满足 select * from emp where dept_id in (select id from dept where name = '销售部' or name = '市场部'); select * from emp where salary > all ( select salary from emp where dept_id =(select id from dept where name = '财务部') );
8.3.3 行子查询
-
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
-
常用的操作符:= 、<> 、IN 、NOT IN
select * from emp where (salary,managerid) = (select salary, managerid from emp where name = '张无忌');
8.3.4 表子查询
-
子查询返回的结果是多行多列,这种子查询称为表子查询。
-
常用的操作符:IN
select * from emp where (job,salary) in ( select job, salary from emp where name ='鹿杖客' or name = '宋远桥' );
8.4 探讨表连接与子查询
- 子查询的功能也可以通过表连接完成,但是子查询会使 SQL 语句更容易阅读和编写。
- 一般来说,表连接(内连接和外连接等)都可以用子查询替换,但反过来却不一定,有的子查询不能用表连接来替换。
- 子查询比较灵活、方便、形式多样,适合作为查询的筛选条件,而表连接更适合于查看连接表的数据。
- 一般情况下,子查询会产生笛卡儿积,表连接的效率要高于子查询。因此在编写 SQL 语句时应尽量使用连接查询。