目录
- 全文检索 ------ 反向索引库 与 Lucene
- SQL模糊查询的问题
- 反向索引库
- 反向索引库的查询
- Lucene(全文检索技术)
- Lucene能做什么
- Lucene存在的问题
- Solr 和 Elasticsearch 与 Lucene 的关系
全文检索 ------ 反向索引库 与 Lucene
MySQL一些索引词汇解释
SQL模糊查询的问题
如这条 like 模糊查询的 sql
select * from 表 where description like "%疯狂%"
这种 like 的模糊查询,也没办法通过索引查询。
SQL模糊查询(like)只能逐个、逐个地搜索。比如要查询 description 列是否包含了 “ 疯狂 ” 关键字。当字符串内容较多时,本身就需要花费较多的时间来逐个匹配。
如图:
用like 模糊查询 “疯狂” 两字,需要对每一行的数据都进行两个字符两个字符逐个匹配,如下图,表示对这一行数据的逐个匹配的过程。

当处理100条记录时,模糊查询的时间开销就是单条记录的处理时间 再乘以100;
当处理千万条记录时,模糊查询的时间开销就是单条记录的处理时间 再乘以千万。
关于使用模糊查询 like 是否会导致索引失效的问题:
用like做查询时,通配符% 放在字段值后面(样子为—>xxx%),进行前缀查询,索引就能使用,
前缀查询的样子abc%,就可以拿a、b、c先去索引树进行匹配,所以索引就可以使用。
如果把通配符%放在字段值最前面来进行后缀查询(样子为—>%xxx),那么索引就会失效。
比如后缀查询的样子是 【%abc】,我们根本不知道%是什么值,也就没办法在索引树进行比对,所以索引就会失效
反向索引库
为了解决 like 模糊查询性能不好的问题,Lucene 做出了一个革命性的创新:先建立反向索引库,再通过反向索引库进行检索。
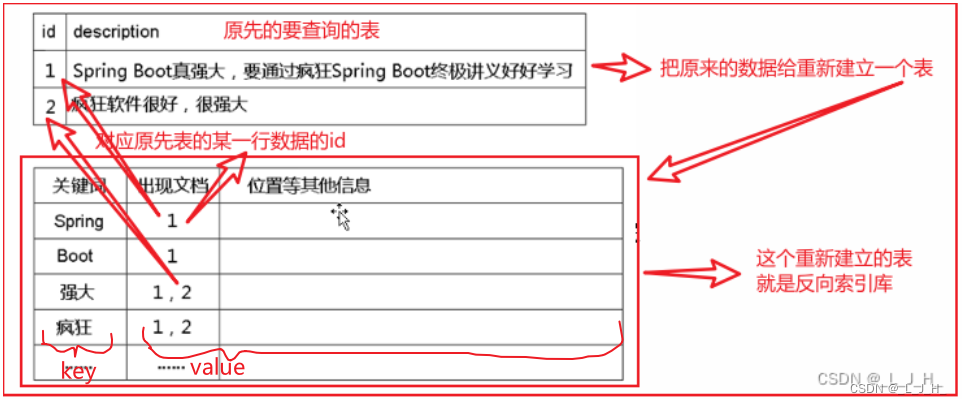
反向索引库: 需要先对目标内容进行分词,然后以【分好的关键词】为 key 建立索引库,value 保存了该key出现在哪些文档中、出现在文档中哪些位置等信息。
解释如图:
原先有这么一张表,这个表里面有一些数据,然后通过分关键词来建立一个索引库。
如图:
“spring” 这个关键词,存在旧表中 id=1 的那一行数据里面,那么在新建立的索引库里面对该关键字给标识上 1;
“强大” 这个关键词,在旧表 id =1 和 id=2 那两行数据里面都存在,那么在新建立的索引库里面也标识了该id,标识了 1,2;
如果我们要全文检索 “强大” 这个词,那么就会直接去旧表查id=1 和 id=2 这两行数据。
而不用对整张表的每一行数据都查一次。
相当于把 like 的查询策略给去掉了。
对反向索引库的查询,立即就变成了原来的 = 查询,相当于如下条件:
“where 关键词列 = 要查询的关键词 ” 查询,而且这关键词列在反向索引库肯定是有索引的(比如btree索引),
这意味着在反向索引库中对该关键词列(就是上图中的key)的检索完全不需要整个表扫描。
反向索引库的查询
对 “关键词”列 执行查询有两个特征:
- 不需要使用LIKE模糊查询,性能很好。
- "关键词"列本身带有聚簇索引,性能很好。
通过“关键字”列中可以很迅速地找到“疯狂”关键字,一旦找到“疯狂”关键字之后,接下来就可通过它对应的value发现,该关键字出现了1、2两个文档中,还可以发现该关键字在1、2两个文档中的位置……等更多详细信息。
不管哪一种语言,它能支持的“词”是有限的,以英语为例,大部分母语为英语的大学生词汇量大约在3万左右;
类似的,中文的汉字、单词也是有限的。
不管目标文档是百万条也好,是百亿条也好,反向索引库的关键字并不会显著增加,
因此对“关键词”列的检索性能总是有保证的。
Lucene(全文检索技术)
Lucene 利用了反向索引库的特征,从而为全文检索提供了性能保证。
Lucene 是目前世界上最流行的全文检索框架。
Lucene 解决了传统SQL查询搞不定的情况,或者用SQL语句能够搞定查询,但要用到很多LIKE……OR时,查询就会很慢。此时就要用到 Lucene 全文检索技术。
Lucene能做什么
Lucene能开发搜索引擎吗?
实际上这并非不可能,当然单独的Lucene可能做不到,一个互联网搜索引擎至少需要解决以下三个核心问题:
- 全文检索。
- 海量信息的自动搜索,需要用到网络爬虫从互联网上爬取信息。
- 海量信息的分布式存储、管理,例如 Cassandra、MongoDB 等
单独的 Lucene 通常用于实现单个的站内搜索功能,只检索本应用内的信息。
Lucene存在的问题
Lucene本身的API比较难用,Lucene框架的开发者应该不是Java开发者,因此他设计的Lucene API比较晦涩,难用。
最大的问题:Luence 只是一个 Java 框架,因此只有 Java 程序员才能使用 Lucene 为项目添加全文检索功能。此时就需要一个跨平台、跨语言的接口。
Solr 和 Elasticsearch 与 Lucene 的关系
Solr、Elasticsearch 等技术对 Lucene 进行了包装,包装之后的 Solr、Elasticsearch 不再是简单的框架,更像一个搜索引擎的服务器。
虽然 Solr、Elasticsearch 底层都是基于 Lucene,但它们自己提供了对 Lucene 索引库的操作、管理,开发者不再需要直接面向 Lucene API 编程,而是面向 Solr、Elasticsearch 所提供 RESTful 接口(跨平台、跨语言)来编程,
这意味着开发者不管使用哪种语言,甚至不管他会不会编程,只要他会用工具发送请求(比如 Postman、curl 等),那就能调用 Solr、Elasticsearch 的 RESTful 接口来操作索引库,包括创建索引库、添加、删除文档、执行全文检索……等一切功能。
优势:降低开发者的要求(使用起来更方便)、没有开发语言的限制。