上一篇:
大数据 - Spark系列《一》- 从Hadoop到Spark:大数据计算引擎的演进-CSDN博客
目录
1. 🥙Idea中配置Live Templates来快速生成代码片段
2. 🥙Idea中配置文件模板自定义初始代码
3.🥙设置spark-submit提交程序时不在控制台打印日志信息
1. 🥙Idea中配置Live Templates来快速生成代码片段
下面是如何配置Live Templates来创建Spark对象的示例:
1. 打开IntelliJ IDEA,转到或Settings(Windows/Linux)。
2. 在设置对话框中,选择Editor - Live Templates。
3. 单击右侧的加号图标,选择Live Template。
4. 在弹出的对话框中,输入模板的缩写(Abbreviation)和描述(Description),例如sc2。
5. 在Template Text框中输入模板的文本,例如:
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
新建一个实例

2. 🥙Idea中配置文件模板自定义初始代码
在IntelliJ IDEA中配置每个新生成的文件的代码模板(File Templates)可以让您自定义每个新文件的初始代码。以下是配置步骤:
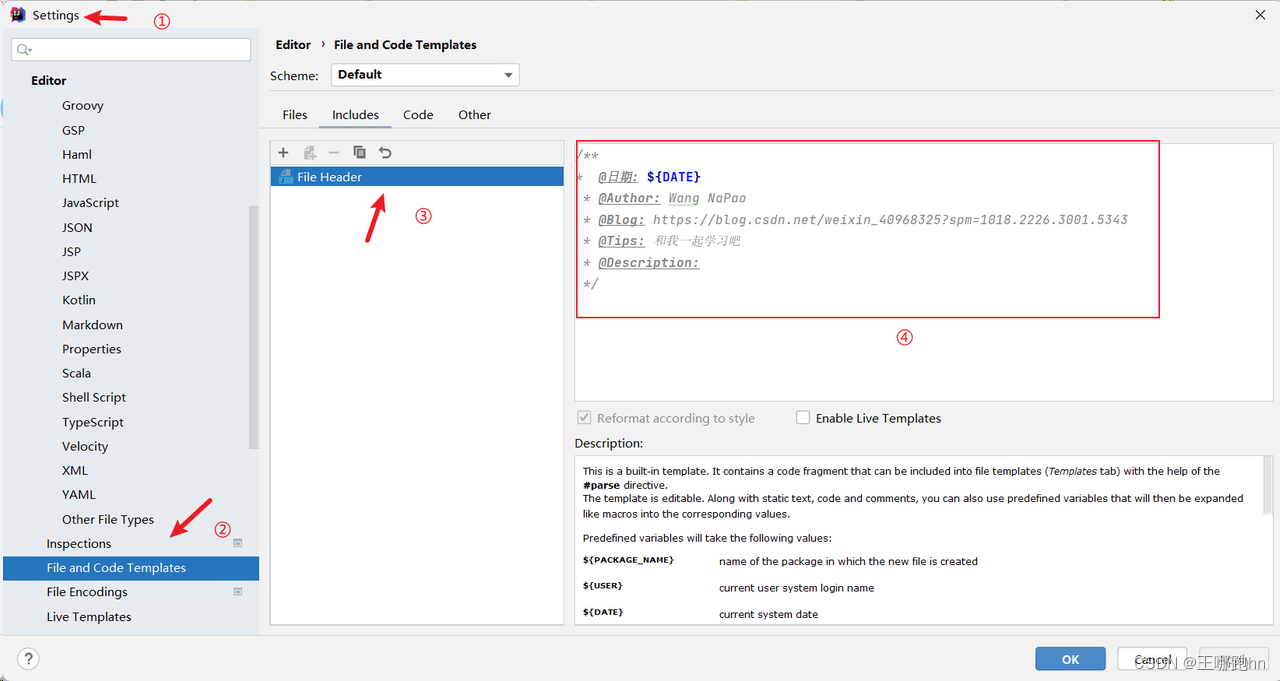
1)打开IntelliJ IDEA,转到Settings(Windows/Linux)。
2)在设置对话框中,选择Editor - File and Code Templates。
3)在顶部选项卡中选择File Templates。
4)在右侧窗格中,您可以看到当前可用的文件模板列表。选择Includes标签页下的File Header。
5)在文本编辑器中,您可以看到文件头部注释的默认模板。在这里,您可以编辑或添加您想要的注释内容。在您的情况下,您可以粘贴您的注释模板,类似于以下内容:
/**
* @日期: 2024/1/31
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description:
*/
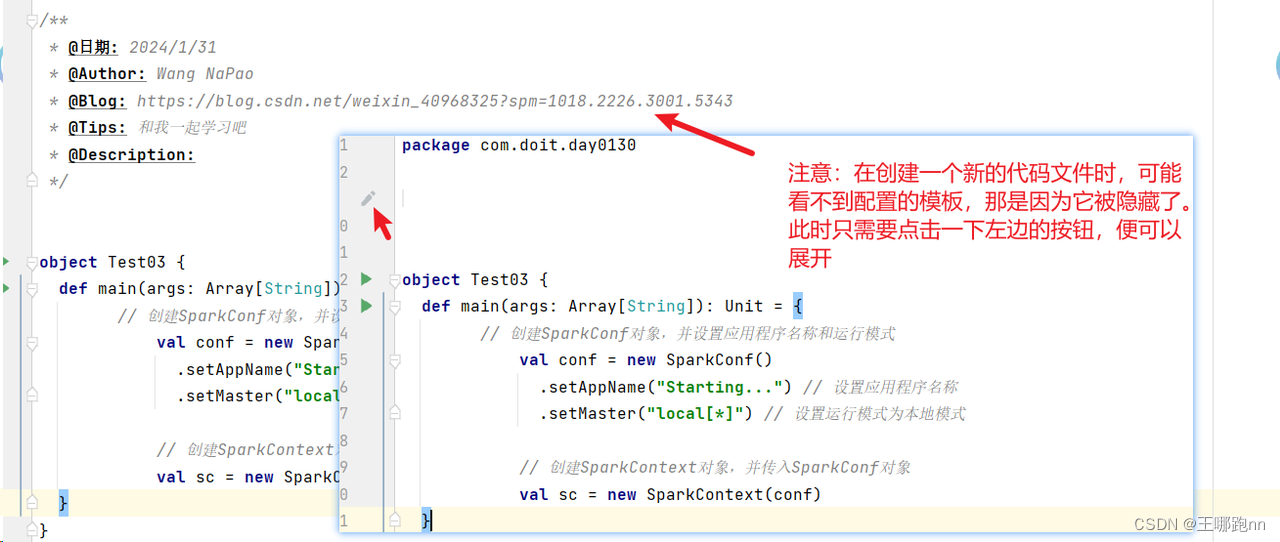
3.🥙设置spark-submit提交程序时不在控制台打印日志信息
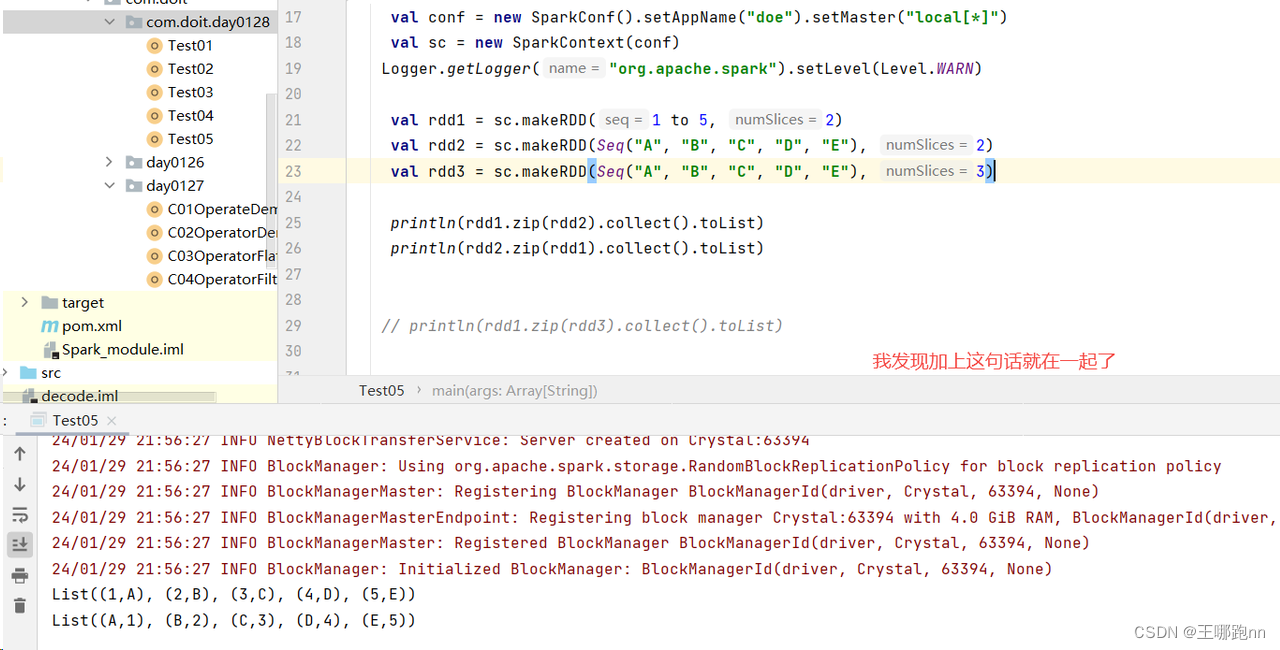
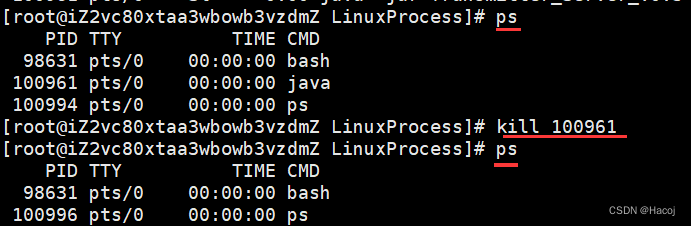
在用spark-submit提交程序时,会打印很多类似图片所示的日志信息,它们会把想要的结果给淹没,所以要想法子去除控制台的日志信息
 解决办法:在程序中设置日志级别。
解决办法:在程序中设置日志级别。
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)关于setLevel()中的参数:
| LogLevel | Level | Use |
| OFF | 2147483647 | 关闭所有日志记录 |
| FATAL | 50000 | 如其翻译,致命的错误 |
| ERROR | 40000 | 错误信息提示,一般需要 Try Catch |
| WARN | 30000 | 潜在错误提示 |
| INFO | 20000 | 正常日志信息 |
| DEBUG | 10000 | 细粒度日志,用于应用调试 |
| TRACE | 5000 | 比调试更细粒度的日志信息 |
| ALL | -2147483648 | 打开所有日志记录 |
测试-
package com.doit.com.doit.day0128
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.log4j.{Level, Logger}
/**
* @日期: 2024/1/29
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 我是技术大牛
* @Description:
*/
object Test05 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("doe").setMaster("local[*]")
val sc = new SparkContext(conf)
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
val rdd1 = sc.makeRDD(1 to 5, 2)
val rdd2 = sc.makeRDD(Seq("A", "B", "C", "D", "E"), 2)
val rdd3 = sc.makeRDD(Seq("A", "B", "C", "D", "E"), 3)
println(rdd1.zip(rdd2).collect().toList)
println(rdd2.zip(rdd1).collect().toList)
// println(rdd1.zip(rdd3).collect().toList)
}
}