论文:MM-LLMs: Recent Advances in MultiModal Large Language Models
论文地址: https://arxiv.org/pdf/2401.13601.pdf


表1:26种主流多模态大型语言模型(MM-LLMs)概要
输入到输出模态(I→O)
- I:图像
- V:视频
- A:音频
- 3D:点云
- T:文本
模态编码器
- -L 代表大型
- -G 代表超大型
- /14 表示14的补丁大小
- @224 表示图像分辨率为224×224
数据集规模
- #.PT 表示多模态预训练(MM PT)期间的数据集规模
- #.IT 表示多模态微调(MM IT)期间的数据集规模
其他信息
- † 包括不对外公开的内部数据。
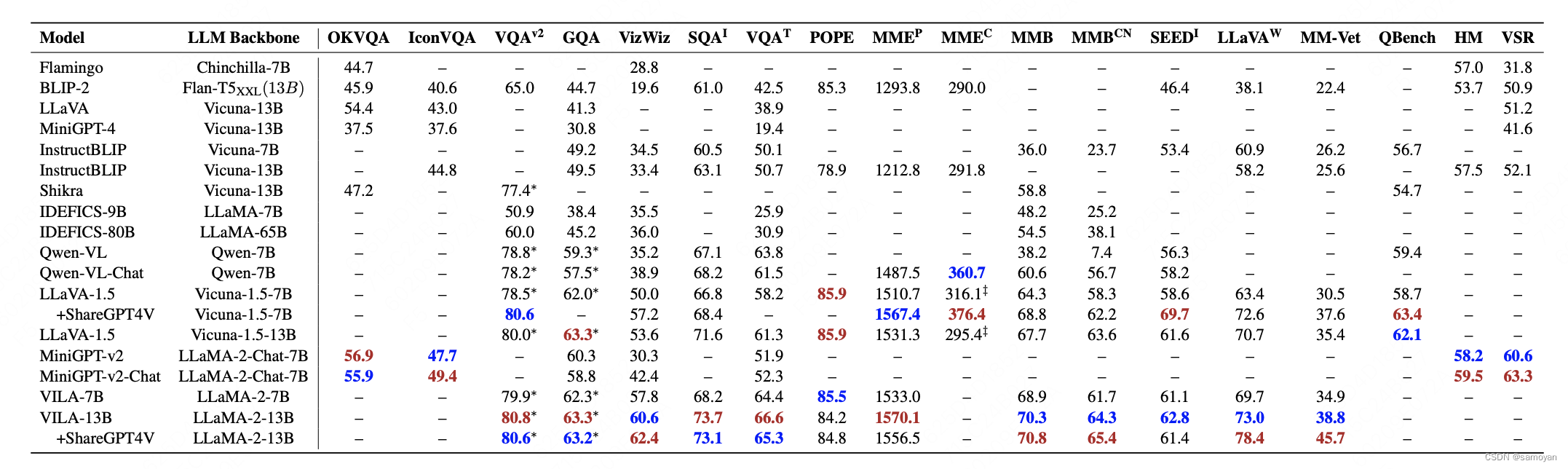
表2:在18个视觉语言基准上主流多模态-大型语言模型(MM-LLMs)的比较
红色表示最高结果,蓝色表示第二高的结果。‡ 表示ShareGPT4V(Chen et al., 2023e)的重新实施测试结果,这些结果在基准测试或原始论文中遗漏。∗表示数据集的训练图像在训练期间被观察到。
(1)Flamingo(Alayrac等人,2022年)代表了一系列视觉语言(VL)模型,这些模型被设计用于处理交错的视觉数据和文本,并生成自由形式的文本作为输出。
(2)BLIP-2(Li等人,2023c)引入了一个更加资源高效的框架,包括轻量级的Q-Former来弥合模态差距,以及利用固定的大型语言模型(LLMs)。通过利用LLMs,BLIP-2可以被引导进行零样本图像到文本的生成,使用自然语言提示。
(3)LLaVA(Liu等人,2023e)率先将图像转换(IT)技术转移到多模态(MM)领域。为了解决数据稀缺问题,LLaVA引入了一个使用ChatGPT/GPT-4创建的新颖的开源多模态指令遵循数据集,以及多模态指令遵循基准LLaVA-Bench。
(4)MiniGPT-4(Zhu等人,2023a)提出了一种简化的方法,其中只训练一个线性层即可将预训练的视觉编码器与LLM对齐。这种高效的方法使得复制GPT-4所展示的能力成为可能。
(5)mPLUG-Owl(Ye等人,2023)提出了一个新颖的多模态大型语言模型(MM-LLMs)的模块化训练框架,融入了视觉上下文。为了评估不同模型在多模态任务中的性能,该框架包括了一个名为OwlEval的指令评估数据集。
(6)X-LLM(Chen等人,2023b)扩展到了包括音频在内的各种模态,并展示了强大的可扩展性。利用Q-Former的语言转移能力,X-LLM在汉藏语系中文的背景下成功应用。
(7)VideoChat(Li等人,2023d)率先提出了一个高效的以聊天为中心的多模态大型语言模型(MM-LLM),用于视频理解对话,为该领域的未来研究树立了标准,并为学术界和工业界提供了协议。
(8)InstructBLIP(Dai等人,2023)基于预训练的BLIP-2模型进行训练,在多模态微调(MM IT)期间只更新Q-Former。通过引入指令感知的视觉特征提取和相应的指令,该模型能够提取灵活多样的特征。
(9)PandaGPT(Su等人,2023)是一个先驱性的通用模型,具有理解和执行6种不同模态指令的能力:文本、图像/视频、音频、热感、深度和惯性测量单元。
(10)PaLIX(Chen等人,2023g)通过混合视觉语言目标和单模态目标(包括前缀完成和遮蔽标记完成)进行训练。这种方法对于下游任务结果和在微调设置中达到帕累托最前沿被证明是有效的。
(11)Video-LLaMA(Zhang等人,2023e)引入了一个多分支的跨模态预训练(PT)框架,使得大型语言模型(LLMs)能够同时处理给定视频的视觉和音频内容,同时与人类进行对话。该框架将视觉与语言以及音频与语言对齐。
(12)Video-ChatGPT(Maaz等人,2023)是一个专为视频对话设计的模型,能够通过整合时空视觉表示来生成关于视频的讨论。
(13) Shikra (Chen et al., 2023d)介绍了一个简单且统一的预训练多模态-大型语言模型(MM-LLM),专为参考对话任务设计,该任务涉及讨论图片中的区域和对象。这个模型展现了值得称赞的泛化能力,有效地处理未见过的设置。
(14) DLP (Jian et al., 2023)提出了P-Former来预测理想的提示符,它在单模态句子的数据集上进行训练。这展示了单模态训练提升多模态学习的可行性。
(15) BuboGPT (Zhao et al., 2023d)是一个通过学习共享的语义空间来构建的模型,用于全面理解多模态内容。它探索了图像、文本和音频等不同模态之间的细粒度关系。
(16) ChatSpot (Zhao et al., 2023b)介绍了一种简单而有效的方法,用于精细调整多模态-大型语言模型(MM-LLM)的精确指引指令,促进细粒度互动。精确指引指令的加入,包括图像和区域级别的指令,增强了多粒度视觉语言(VL)任务描述的整合。
(17) Qwen-VL (Bai et al., 2023b)是一个支持英语和中文的多语言多模态-大型语言模型(MM-LLM)。Qwen-VL在训练阶段还允许输入多个图像,提高了对视觉上下文的理解能力。
(18) NExT-GPT (Wu et al., 2023d)是一个端到端的、通用的任意到任意多模态-大型语言模型(MM-LLM),支持图像、视频、音频和文本的自由输入和输出。它采用了轻量级的对齐策略,在编码阶段利用大型语言模型中心的对齐,在解码阶段利用遵循指令的对齐。
(19) MiniGPT-5 (Zheng et al., 2023b)是一个与生成性vokens的反转集成,并且与稳定扩散集成的多模态-大型语言模型(MM-LLM)。它擅长执行交错的视觉语言(VL)输出,用于多模态生成。在训练阶段加入无分类器指导,提高了生成的质量。
现有多模态-大型语言模型(MM-LLMs)的趋势
(1) 从专注于多模态理解到生成特定模态的演进
并进一步发展成任意到任意模态转换(例如,MiniGPT-4 → MiniGPT-5 → NExT-GPT);
(2) 从多模态预训练(MM PT)到特定任务微调(SFT)再到强化学习人类反馈(RLHF)
训练流程持续精细化,努力更好地与人类意图对齐,并增强模型的对话交互能力(例如,BLIP-2 → InstructBLIP → DRESS);
(3) 拥抱多样化的模态扩展
(例如,BLIP-2 → X-LLM 和 InstructBLIP → X-InstructBLIP);
(4) 吸纳更高质量的训练数据集
(例如,LLaVA → LLaVA1.5);
(5) 采用更高效的模型架构
从BLIP-2和DLP中复杂的Q-和P-Former输入投影模块过渡到VILA中简单而有效的线性投影器。