阅读建议
仔细阅读书[1]对应的序列标注章节,理解该方法面向的问题以及相关背景,然后理解基础的概念。
引言
威胁情报挖掘的相关论文中,均涉及到两部分任务:命名实体识别(Named Entity Recognition,NER)和关系抽取,大多数网安实现NER的方法,采用比较多的方法包含:BiLstm+CRF或者Bert+CRF。
其中条件随机场(conditional random fields, CRF),这个模型算是多次遇到了。经过了长期的学习之后,对该部分模型也算是有了较为深入的理解,虽然还没有达到能立马应用的效果,但基本上了解了比较关键的点。
在学习这个模型的过程中,一开始直接搜索相关的方法介绍的时候,经常会遇到上来就介绍模型算法公式这种的,或者说是不通过公式的,就从大致原理介绍的,这些介绍的形式都不怎么适合我这种非专业自然语言处理的人。
实际上,个人认为,从问题的角度来出发,思考清楚他是为了解决什么问题,穿插着一些关键的公式、算法,最后还能融合一些代码实现用于后续的使用过程。
不准备完全通过数学的角度来理解这个方法,而是从应用的角度,明白较为关键的参数。
所解决的问题 - 序列标注
在各种论文中看到使用CRF是进行NER的时候,实际上他解决的是类似词性标注(Part of Speech tagging)一样的序列标注问题,这类问题是指输入一个 X X X向量,对应输出一个 Y Y Y向量,通常情况下他们的向量长度是一样的。
在《自然语言处理综论》课程中[1]提供的PDF文档中,介绍序列标注的章节(第8章)中,针对该问题介绍了两种方法隐马尔可夫模型和条件随机场模型。在之前中,已经通过该文档学习了HMM模型。
词性标注
举例来说,对一句话中各个词汇的词性进行标注,例如I am Ac.这个输入就将对应三个输出,分别说明这个词汇是什么类型,名词、动词这种。相应的,输出的标签也就是这些内容,如下图所示:
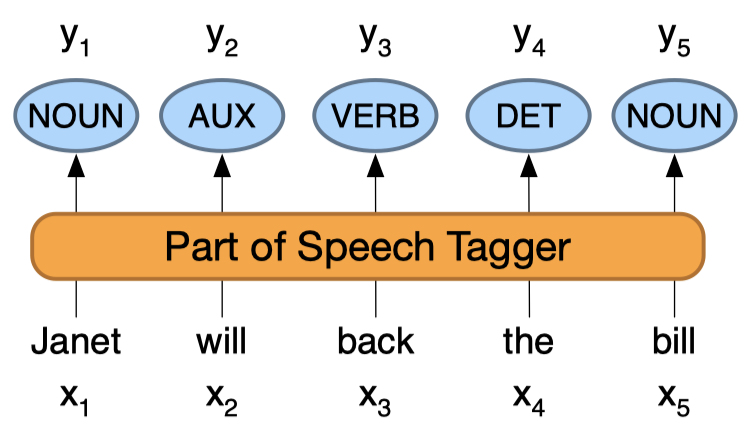
NER
再进一步,进行NER任务,此时在进行标注的时候,其输出的标签是就是某种实体的标志,如下图所示:

上述表格中列举了三种标记方式:IO、BIO、BIOES,O指代非命名实体,在某种实体(person、location)前加上B或者E便是BIO这种。
针对这种方法,可以针对每个数据训练一个分类器,然后进行分类(对连续照片进行分类的问题,这也是很多博客都进行距离的一个方法),但这种方法他们的缺点就是没有考虑上下文的关联,比如说我上一个照片是什么样子。
模型理解
模型差异 - 生成模型与判别模型
在解决词性标注的问题中,有两种模型:HMM和CRF,而他们分别对应了生成模型和判别模型,这里的分别就是说明了他们针对概率模型不同的处理方式,特别是为了求解 P ( C / X ) P(C/X) P(C/X)[3][5],不过我对这部分问题依然还是不够深入理解。在[1]中在介绍逻辑回归模型的时候,说明了两种模型的对比,重点就是他们去进行分类任务的时候,他们是怎么入手概率。
当然,在介绍CRF的文章中,都绕不过经典的文章[4],这篇文章中有一个比较主观的图:
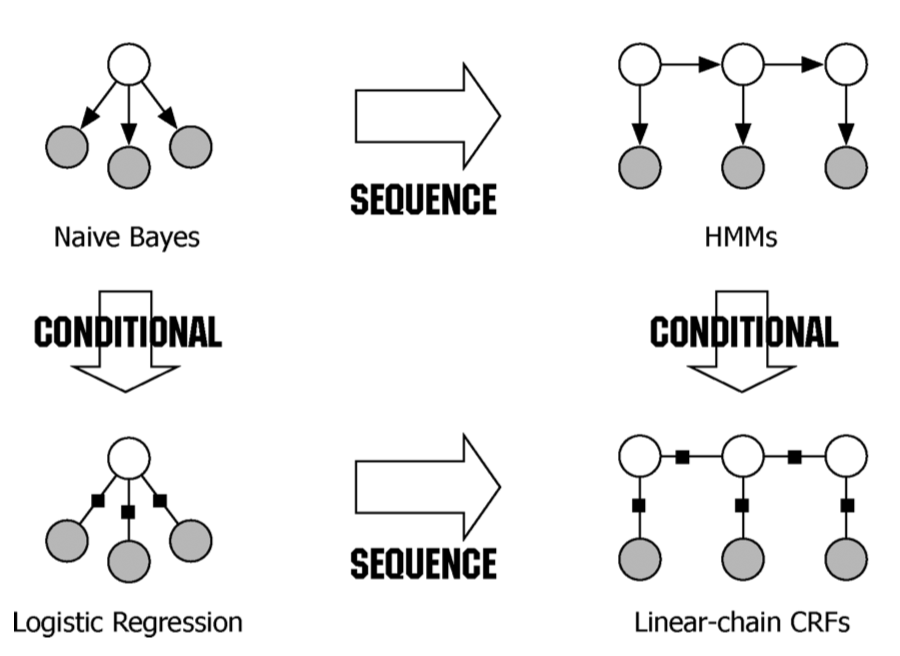
在介绍了生成模型与判别模型时,便采用了朴素贝叶斯和逻辑回归两种方法进行对比,然后分别对他们进行序列化的扩展,也就形成了后续的这种模型。
实际上,在书[1]中,从HMM拓展到CRF的时候,也简单说明了HMM的缺陷和CRF的优势,他描述的角度是从增加这个特征的角度,不容易重新构造条件概率来说明。
所以在学习CRF的时候,能够发现他的公式跟逻辑回归很像。在图中也直接说明了线性链式CRF,平时这种也属于用的比较多的。在这里就不对HMM进行具体介绍了,但是如果能够回想起当时学习的转移概率和发射概率这些名词,对理解CRF能够有一定的帮助。
CRF模型概述
那么结合发射概率和转移概率这些概念,以及CRF所做的假设,或者说其模型公式中的相关限制,依然利用词性标注这个问题来解释:
每个单词的词性,他不仅仅和当前的单词有关,他还和前一个单词的词性有关。
注意,他是和上一个单词的词性有关。所以建模的时候要干的事情到底是什么?也就是同时考虑当前单词的属性,同时也要考虑上一个标注结果从而输出一个序列解决。
相应的,特征函数的写法也就是 f ( X , i , l i − 1 , l i ) f(X, i, l_{i-1}, l_{i}) f(X,i,li−1,li), i i i指代当前处理单词的位置, l l l指标记结果。关于特征函数,这里不在赘述,实际上就是根据单词或者句子的位置等进行的一些定义,特征函数的输出为0或者1。
而CRF的模型就是一个输出标记序列y概率的概率模型[1]:

其中 w k w_k wk是每个特征函数的权值。对于每条句子,他可能会有非常多的标注结果,公式分母是一个归一化的结果,要干的事情就是求解参数,令正确的序列结果最大。文章[6]中比较形象的描述了这个事情:
上面所说的动词后面还是动词就是一个特征函数,我们可以定义一个特征函数集合,用这个特征函数集合来为一个标注序列打分,并据此选出最靠谱的标注序列。也就是说,每一个特征函数都可以用来为一个标注序列评分,把集合中所有特征函数对同一个标注序列的评分综合起来,就是这个标注序列最终的评分值。
定义了这个模型之后,要干的事情:一个方面是求解这个参数,另外一方面,在求解完这些参数之后,还需要利用这个参数来对结果进行预测。所以大部分博文,解释的事情,也就是这两部分。
文章[6]中同时对比了HMM以及逻辑回归,可以作为学习补充,同时也根据《统计学习方法》进行了比较规范的数学介绍。
那么为了训练获取参数,可以采用最大似然估计的方式,求解参数,同时定义相关的损失函数,利用梯度下降的方法来获得参数[5]。
对于具体的训练方式,还需要结合代码来具体学习。
CRF词性标注初步实践
文章[2]中直接利用了CRF的Python库sklearn_crfsuite实现了词性标注这个问题,虽然词性标注的结果准确率为96%。
深度学习方法
在一些论文和github中,利用BiLstm+CRF和BERT+CRF来进行命名实体识别,可以搜到非常多的方法和代码。在最开始的时候,我也是准备从代码的角度来理解这个方法。但是发现还是有些不一样的地方,文章[7]利用Keras作为框架来进行神经网络的编程,例如比较核心代码内容如下:
input_layer = layers.Input(shape=(MAX_SENTENCE,))
model = layers.Embedding(WORD_COUNT, DENSE_EMBEDDING, embeddings_initializer="uniform", input_length=MAX_SENTENCE)(input_layer)
model = layers.Bidirectional(layers.LSTM(LSTM_UNITS, recurrent_dropout=LSTM_DROPOUT, return_sequences=True))(model)
model = layers.TimeDistributed(layers.Dense(DENSE_UNITS, activation="relu"))(model)
crf_layer = CRF(units=TAG_COUNT)
output_layer = crf_layer(model)
ner_model = Model(input_layer, output_layer)
loss = losses.crf_loss
acc_metric = metrics.crf_accuracy
opt = optimizers.Adam(lr=0.001)
ner_model.compile(optimizer=opt, loss=loss, metrics=[acc_metric]) ner_model.summary()
上述代码估计版本可能有所变化,已经不能运行了。相比于其他博文,例如他使用pytorch框架时,他在介绍的时候还会把CRF的代码给写出来,这部分还会进行具体的训练说明。
!下一步就是学习pytorch的具体写法。
相关阅读
条件随机场(CRF)极简原理与超详细代码解析
这篇文章利用pytorch针对CRF的训练方式和预测方法都进行了讲解,但他的训练方法部分暂时有点不理解,因为他的公式部分分解成为了转移得分和发射得分,虽然我能够理解这个概念,但是感觉跟前面的特征函数部分的概念还是不太一样。所以,可能是这部分的求解方法不太一样。可以结合[6]再看一看。
条件随机场(CRF)
这篇文章从分词的角度对CRF进行了介绍,是最开始阅读的材料。
参考
[1]Speech and Language Processing, (3rd ed. draft)
[2]Conditional Random Fields (CRFs) for POS tagging in NLP
[3]What is the difference between a generative and a discriminative algorithm?
[4]Sutton C, McCallum A. An introduction to conditional random fields[J]. Foundations and Trends® in Machine Learning, 2012, 4(4): 267-373.
[5]Overview of Conditional Random Fields
[6]CRF条件随机场
[7]Building a Named Entity Recognition model using a BiLSTM-CRF network