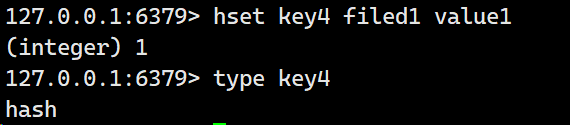
使用postman进行测试
如下图所示:

需要进行验证,请选择Authorization中的basic auth,填写账号以及密码。
添加ik中文分词
安装 IK 分词器插件:
下载 IK 分词器插件,可以从 GitHub 上的
elasticsearch-analysis-ik
页面下载最好下载与ES版本相同的IK版本文件。
将下载的插件解压缩到 Elasticsearch 的插件目录中。(插件目录在ES的根目录下的plugins)
创建索引并指定 IK 分词器:
在创建索引时,使用自定义的分词器配置来指定字段的分词器为 IK 分词器。
具体步骤如下:

ps: plugins下面只存放插件,而压缩包必须删除掉,千万不要也放在下面!!!!切记。
创建索引格式演示:
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"ik_analyzer": {
"type": "custom",
"tokenizer": "ik_max_word",
"filter": ["synonym_filter", "stop_filter"]
}
},
"filter": {
"synonym_filter": {
"type": "synonym",
"synonyms_path": "analysis/synonyms.txt"
},
"stop_filter": {
"type": "stop",
"stopwords_path": "analysis/stop.txt"
}
}
}
},
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_analyzer"
}
}
}
}
说明:
设置了一个自定义的解析器analyzer
定义名称为ik_analyzer(可根据自己喜好修改名称)
定义它的类型为custom自定义类型
采用的分词tokenizer为ik_max_word
定义了同义词和停用词过滤filter为synonym_filter、stop_filter
设置过滤filter
分别命名为synonym_filter和stop_filter(名字自己取),上边引用的filter就是对应的这个名字(不要写错)
定义了type类型分别是synonym(同义词)、stop(停用词)
synonyms_path和stopwords_path分别是同义词和停用词文件位置,文件路径为ES根目录下的config中创建analysis/synonyms.txt和analysis/stop.txt;(文件夹analysis和文件XXX.txt可自己定义,主要是放在config下边)
二、 以上mappings中说明:
定义属性properties为content(这个就是我们要进行分词的字段名)
定义content字段类型为type:text
字段content采用的解析方式analyzer为上边settings中定义的ik_analyzer