哈希 = hash = 散列函数(将非常大范围的输入,通过一定的函数,可以转换到小规模的输出)
什么是哈希?
广义上是一种思想,不是一个特定的东西,只要算法设计中使用到了哈希思想,就可以叫做哈希函数。
- 存储地址 = f(关键字)
- 可以直接通过关键字而不是去一次比较,直接获取存储地址。
- 散列技术,其实是将存储位置和关键字之间确立了一种对应关系
f,使得每一个关键字(key)都对应一个存储位置。
查找的时候通过确定的对应关系,找key值的映射f(key)。
这种对应关系f就是散列函数(哈希函数),采用散列技术将记录存在一片连续的存储空间,这个空间就被称为哈希表。
通俗的讲:就是一片连续的存储空间存储了 通过散列函数计算的散列地址,并记录了其映射关系
散列技术,既是一种存储方法,也是一种查找方法。
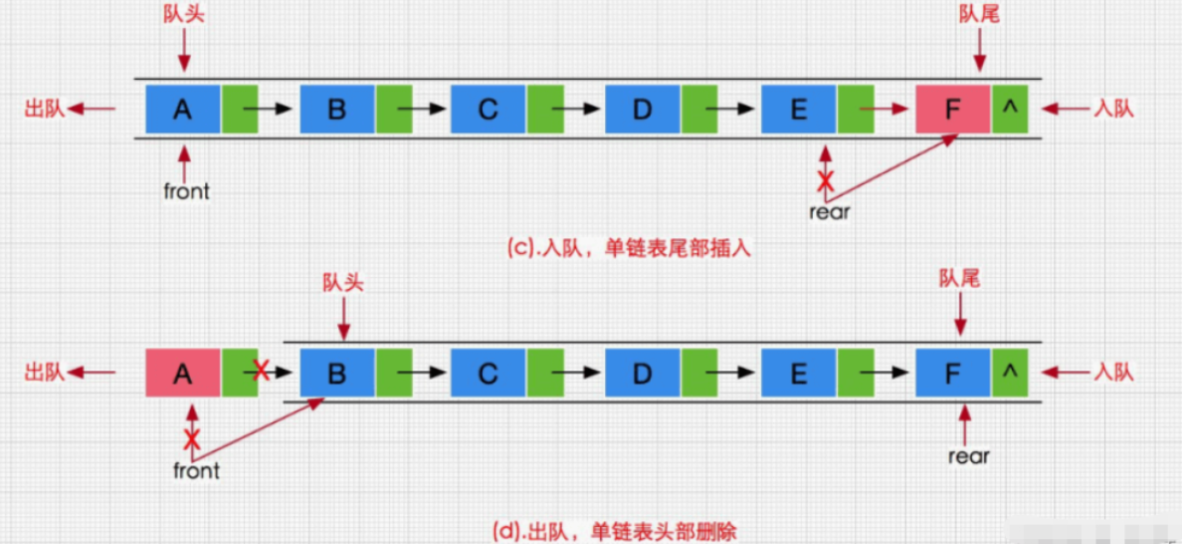
例如:单链表和顺序表,数据和数据之间有没有关系?
单链表各个结点之间:上一个结点存储了下一个结点的地址
顺序表之间:逻辑上相邻,物理上也相邻
哈希表:数据与数据之间没有关系,但是数据本身和最终存储空间有唯一的关系。
存储地址 = f(关键字)
散列函数怎么设计(6种方法)(面试不会考)
直接定址法(线性关系) f(key) = key
使用最多的是:除留取余法
可以穿插使用
哈希冲突怎么解决?(4种方法)(不可避免,尽可能的减少哈希冲突)
公司:以空间换时间。
1.开放定址法
(线性探测):只向后探测 (造成的问题:导致前方有空间大量闲余,后方空间紧张,并且会出现数据堆积)
(平方探测):向前向后探测
.向后探测是否有空心的值
2.拉链法
3.公共溢出法(基本表和溢出表)

其中链式哈希必须 会写
#define HASHSIZE 12
typedef int ELEMTYPE;
typedef struct LNode
{
ELEMTYPE data;
LNode* next;
}LNode,*PLNode;
typedef struct Head
{
struct LNode arr[HASHSIZE]; //指针数组(存放指针的数组)
}Head,*PHead; //直接设计为LNode类型,可以直接访问LNode中的数据

#include "listhash.h"
void Init_listhash(PHead ph)
{
//assert ;
for (int i = 0; i < HASHSIZE; i++)
{
//ph->rr[i].data 不使用
ph->arr[i].next = nullptr;
}
}
bool Insert_hash(PHead ph, int key)
{
int hash = key % HASHSIZE;
//创建新结点
struct LNode* s = (LNode*)malloc(sizeof(LNode)*1);
assert(s != nullptr);
//插入;
s->data = key;
s->next = ph->arr[hash].next;
ph->arr[hash].next = s;
return true;
}
bool Del_hash(PHead ph, int key)
{
int hash = key % HASHSIZE; //得到所在物理下标
LNode* p = &ph->arr[hash]; //p->arr[hash]是变量,p指向该下标的地址空间,该地址空间存的是链表的第一个节点
for (; p->next != nullptr; p = p->next)
{
if (p->next->data == key)
{
LNode* q = p->next;
p->next = q->next;
free(q);
q = nullptr;
return true;
}
}
return false;
}
struct LNode* Search(PHead ph, int key)
{
int hash = key % HASHSIZE; //得到所在物理下标
LNode* p = ph->arr[hash].next; //指针
for (; p != nullptr; p = p->next)
{
if (p->data == key)
{
return p;
}
}
}
void Show_Hash(PHead ph)
{
for (int i = 0; i < HASHSIZE; ++i)
{
printf("%3d ", i);
struct LNode* p = ph->arr[i].next;
for (; p != nullptr; p = p->next)
{
printf("%d ", p->data);
}
printf("\n");
}
}
测试:
int main()
{
Head hd;
Init_listhash(&hd);
Insert_hash(&hd, 48);
Insert_hash(&hd, 12);
Insert_hash(&hd, 37);
Insert_hash(&hd, 25);
Insert_hash(&hd, 15);
Insert_hash(&hd, 16);
Insert_hash(&hd, 29);
Insert_hash(&hd, 67);
Insert_hash(&hd, 56);
Insert_hash(&hd, 34);
Insert_hash(&hd, 22);
Insert_hash(&hd, 47);
Show_Hash(&hd);
Del_hash(&hd, 48);
Show_Hash(&hd);
}
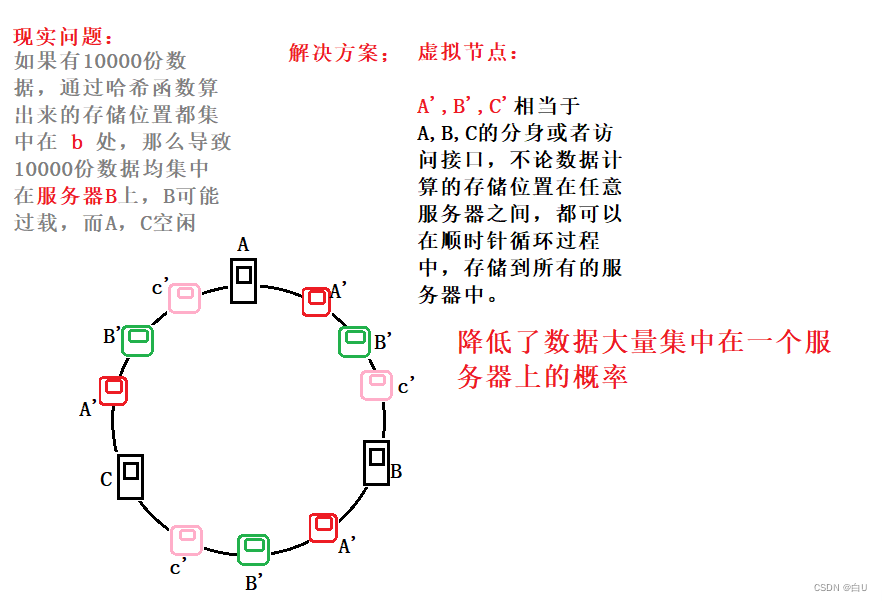
一致性哈希的问题,虚拟节点来解决
普通哈希算法的缺陷:
如果服务器已经不能满足缓存需求,就需要增加服务器数量,假设我们增加了一台缓存服务器,此时如果仍然使用取模,key作为主机数对同一张图片进行缓存,那么这张图片所在的服务器编号必定与原来3台服务器时所在的服务器编号不同,因为除数由3变为了4,最终导致所有缓存的位置都要发生改变,也就是说,当服务器数量发生改变时,所有缓存在一定时间内是失效的,当应用无法从缓存中获取数据时,则会向后端服务器请求数据;同理,假设突然有一台缓存服务器出现了故障,那么我们则需要将故障机器移除,那么缓存服务器数量从3台变为2台,同样会导致大量缓存在同一时间失效,造成了缓存的雪崩,后端服务器将会承受巨大的压力,整个系统很有可能被压垮。为了解决这种情况,就有了一致性哈希算法。
一致哈希的优点:
果简单对服务器数量进行取模,那么当服务器数量发生变化时,会产生缓存的雪崩,从而很有可能导致系统崩溃,而使用一致性哈希算法就可以很好的解决这个问题,因为一致性Hash算法对于节点的增减都只需重定位环空间中的一小部分数据,只有部分缓存会失效,不至于将所有压力都在同一时间集中到后端服务器上,具有较好的容错性和可扩展性。
一致哈希: 一致性哈希算法也是使用取模的方法,但是取模算法是对服务器的数量进行取模,而一致性哈希算法是对 2^32 取模,
具体步骤如下:
- 步骤一:一致性哈希算法将整个哈希值空间按照顺时针方向组织成一个虚拟的圆环,称为 Hash 环;
- 步骤二:接着将各个服务器使用 Hash 函数进行哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,从而确定每台机器在哈希环上的位置
- 步骤三:最后使用算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针寻找,第一台遇到的服务器就是其应该定位到的服务器
我们认为在圆圈上存在2^32
个点每个点对应一个值,所以取模的时候即2^32即可
哈希算法将图片映射在哈希环上:hash(图片名称) % 2^32,假设我们有1个数据,映射后的示意图如下:

因此如上图,当一个服务器出现故障,不会影响到其他的服务器。
一致哈希和虚拟节点配合使用。解决了数据大量集中在一个服务器的可能性。