1. 使用LSTM模型进行乘客的数目预测
- 数据集 international-airline-passengers.csv
- (可以不在意精度和loss)
import pandas as pd
import numpy as np
filename = r'C:\Users\15002\Desktop\data1\international-airline-passengers.csv'
data = pd.read_csv(filename)
data.head() # 取前五条数据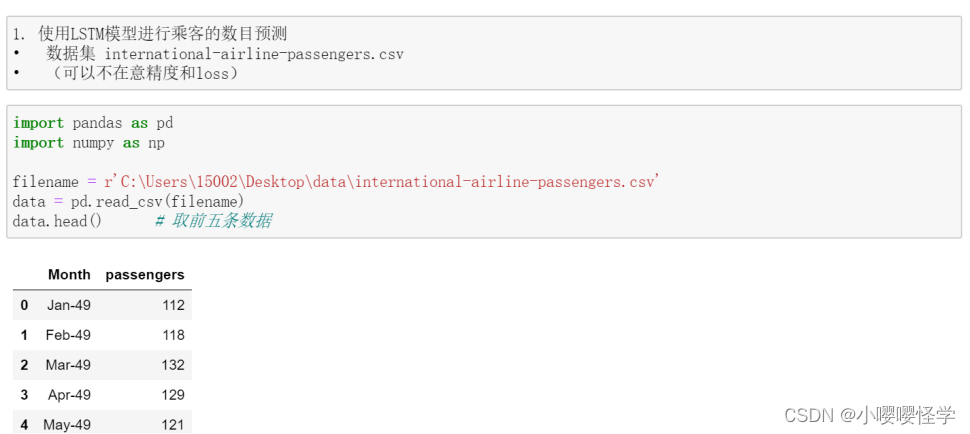
from matplotlib import pyplot as plt
plt.rcParams['axes.unicode_minus']=False # 设置负号正常显示,不然会乱码
temp = data["passengers"]
temp_10days = temp[:1440] # 前10天共有1440个数据点
temp_10days.plot(color='#FFA509')
plt.show()

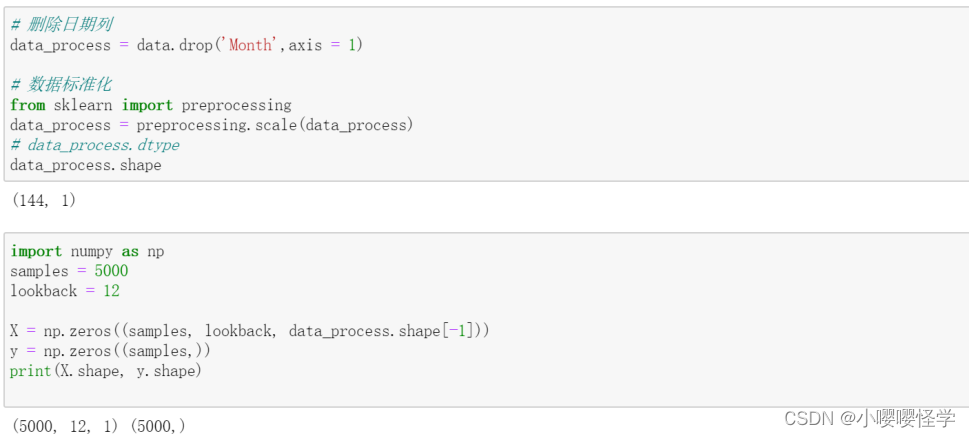
# 删除日期列
data_process = data.drop('Month',axis = 1)
# 数据标准化
from sklearn import preprocessing
data_process = preprocessing.scale(data_process)
# data_process.dtype
data_process.shapeimport numpy as np
samples = 5000
lookback = 12
X = np.zeros((samples, lookback, data_process.shape[-1]))
y = np.zeros((samples,))
print(X.shape, y.shape)
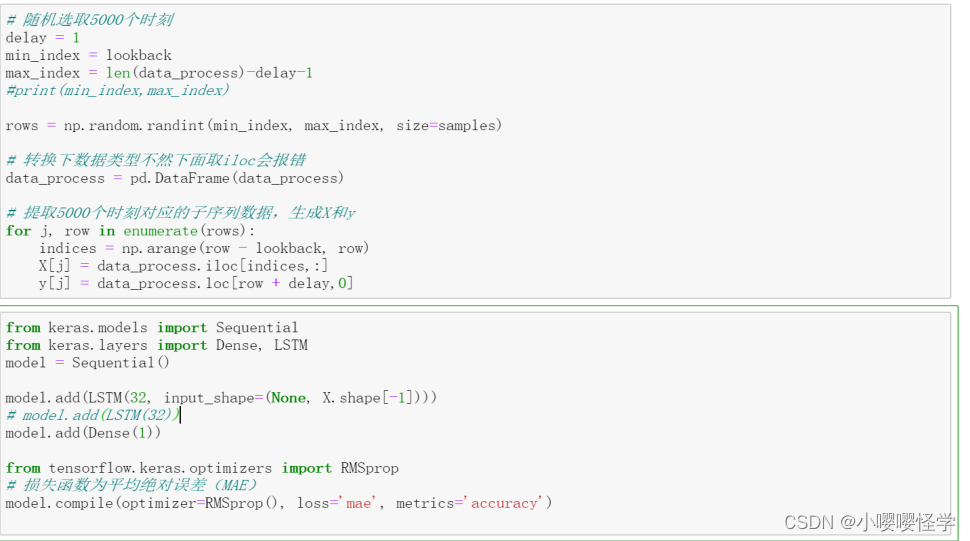
delay = 1
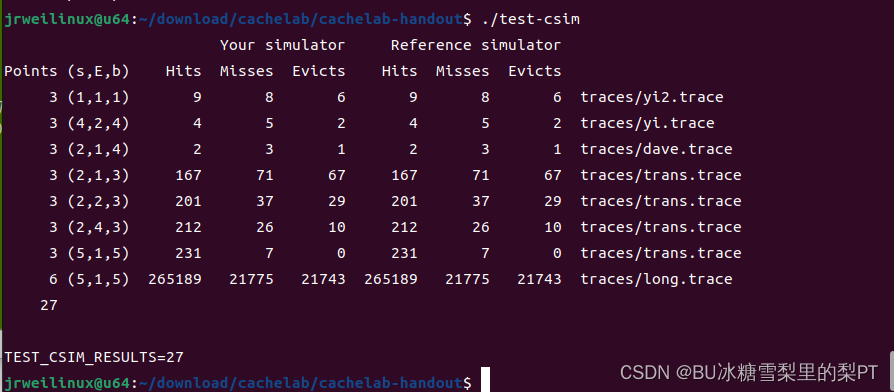
min_index = lookback
max_index = len(data_process)-delay-1
#print(min_index,max_index)
rows = np.random.randint(min_index, max_index, size=samples)
# 转换下数据类型不然下面取iloc会报错
data_process = pd.DataFrame(data_process)
for j, row in enumerate(rows):
indices = np.arange(row - lookback, row)
X[j] = data_process.iloc[indices,:]
y[j] = data_process.loc[row + delay,0] from keras.models import Sequential
from keras.layers import Dense, LSTM
model = Sequential()
model.add(LSTM(32, input_shape=(None, X.shape[-1])))
model.add(Dense(1))
from tensorflow.keras.optimizers import RMSprop
# 损失函数为平均绝对误差(MAE)
model.compile(optimizer=RMSprop(), loss='mae', metrics='accuracy')
model.summary()
history = model.fit(X, y,
epochs=10,
batch_size=128,
verbose=1, # verbose: 0, 1 或 2。日志显示模式。 0 = 安静模式, 1 = 进度条, 2 = 每轮一行。
validation_split=0.2)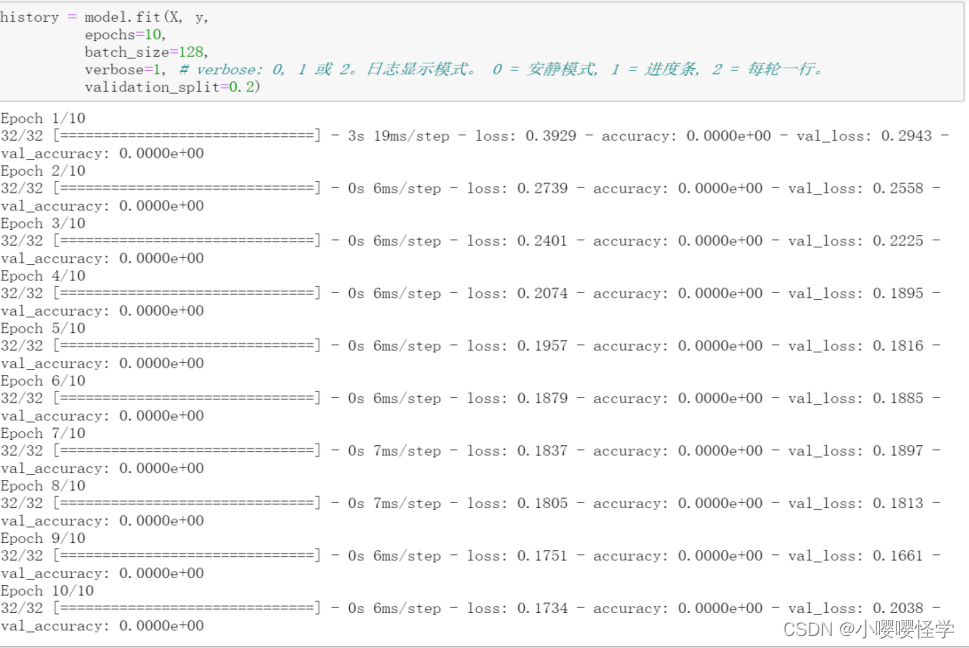
model.save('tempDu.h5')
acc = history.history['accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
val_acc = history.history['val_accuracy']
epochs = range(len(acc))
plt.title('Accuracy and Loss')
plt.plot(epochs, acc, 'red', label='Training accuracy')
plt.plot(epochs, loss, 'blue', label='Training loss')
plt.plot(epochs, val_loss, 'yellow', label='Validation loss')
plt.plot(epochs, val_acc, 'green', label='Validation accuracy')
plt.legend()
plt.show()

时间序列分析的目的是通过找出样本内时间序列的统计特性和发展规律性,构建时间序列模型,进行样本外预测。时序数据特征的方法有四种:基于统计方法的特征提取,基于模型的特征提取,基于变换的特征提取,基于分形理论的特征提取。时序数据分析可分为线性模型和神经网络模型。本次实验运用LSTM模型来进行样本预测。
2. 对文件rest-api-asr_python_audio_16k.m4a进行语音识别
from aip import AipSpeech #导入语音识别包
def get_file_content(file_name):
with open(file_name, 'rb') as fp: # rb 二进制读取模式打开文件
return fp.read()APP_ID = '25751645'
API_KEY = 'OLWQqY1OsYD8Plh1rDXp2Fh5'
SECRET_KEY = 'ZQPC8mrS65GKWbLBAkgF4dEGMgsr5hQ2'
aipSpeech = AipSpeech(APP_ID, API_KEY, SECRET_KEY)# 初始化识别模型
file_name=r'C:\Users\15002\Desktop\data\rest-api-asr_python_audio_16k.m4a' # 语音文件
result = aipSpeech.asr(get_file_content(file_name),
'm4a', # 文件格式,即后缀名,文件后缀 pcm/wav/amr/m4a 格式
16000, # 采样率
{'dev_ip': '1536'})# 1537 表示识别普通话,使用输入法模型。
print (result['result'][0])
语音识别技术通过对数据采样,构建基本框架,特征提取,实现对人类语音中的词汇转化成计算机可输入的序列这一功能。本次实验运用了百度语音开放平台为用户提供免费的语音识别和语音合成服务的工具包:baidu-aip,实现了对语音文件的识别。