题目描述
统计一篇文章里不同单词的总数。
输入
有多组数据,每组一行,每组就是一篇小文章。每篇小文章都是由大小写字母和空格组成,没有标点符号,遇到#时表示输入结束。每篇文章的单词数小于1000,每个单词最多由30个字母组成。
输出
每组只输出一个整数,其单独成行,该整数代表一篇文章里不同单词的总数。
样例输入 Copy
you are my friend
#样例输出 Copy
4分析
这道题如果用C语言实现比较困难,我们需要将这串字符串拆分成无数的小字符串,然后存储在一个二维字符数组中,再利用循环去做比较,比较麻烦,于是,我在想能不能用Python来做,在Python中,对字符串的处理有一个split()方法,可以将字符串分割开,并且将分割成的小字符串存放到列表中,这样一来就容易多了,分割完成后,我们可以把这个新生成的列表转换为集合,利用集合的特点-----集合中元素不可重复,这样我们再利用len()函数就可以测量出集合中的元素数,即单词的总数。
程序代码
while True:
str1=input()
if(str1=='#'):
break
else:
str1=str1.split()
set1=set(str1)
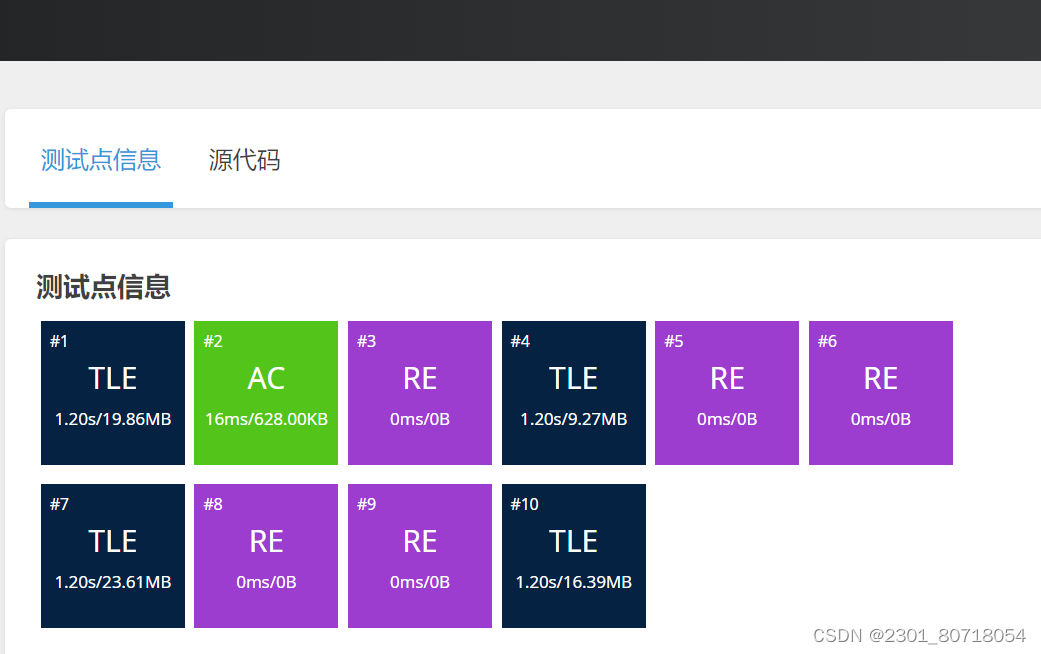
print(len(set1))运行结果

总结
Python作为一门面向对象的语言,具有简单易学的特点,其内置的一些函数可以大大减少问题的复杂度,比如这道统计单词数目题就是一个很好的案例,大家要好好学Python哦,我们一起加油!!!