1. 什么是RabbitMQ
RabbitMQ是使用Erlang语言开发的,基于AMQP高级消息队列的开源消息中间件
Erlang语言主要用于开发并发和分布式系统,在电信领域得到广泛应用
2.什么是消息中间件
消息中间件是在分布式系统中传递消息的软件服务。它允许不同的系统组件之间通过消息进行通信,而无需直接连接到彼此。消息中间件通常用于解耦系统的各个部分,提高系统的可扩展性、灵活性和可维护性。
2. 消息中间件解决了什么问题
2.1 异步处理
在业务没有上下文依赖的前提下,将串行的业务执行流程优化成并行的方式,从而减少服务响应的时间。
例如:在用户注册成功后,需要给用户发送短信和邮箱注册成功的通知,在此场景中,发送邮箱和短信通知不是必须要给客户端响应成功后通知,因此两者可以和注册的业务逻辑优化成并行。也就是在用户注册信息成功持久化到数据库后,直接给客户端响应注册成功,而邮箱和短信可以通过异步执行的方式,减少服务整体响应时间,减少用户的等待时长。
2.2 服务解耦
将耦合的接口,通过消息中间件解耦,减少一个接口定义发生变化,导致其他调用方都需要修改的情况。
例如:用户购买商品,调用下订单服务,再调用发货服务,如果发货服务需要进行升级,发货服务接口参数改变了,那么所有使用了发货接口的服务,全部需要配合修改参数;如果使用了消息中间件,将用户下单的信息发布到消息中间件中,发货接口只需要订阅消息中间件的订单消息,当有新的订单时,再发货,无论发货接口的参数定义如何变化,都不会影响上游的接口功能
2.2 流量削峰
将集中在某一段时间的流量,存储在一个池子里(消息中间件的队列中),然后根据服务器的消费能力进行处理,而不是在流量高峰期,将所有的流量全部处理完毕。
例如:秒杀活动,瞬间流量会非常大,如果服务器直接去处理这么大流量的请求,很容易导致整个应用崩溃;通过消息队列,将流量先暂存到队列中,然后有服务器慢慢的消化,通过拉长时间,减小服务器的压力
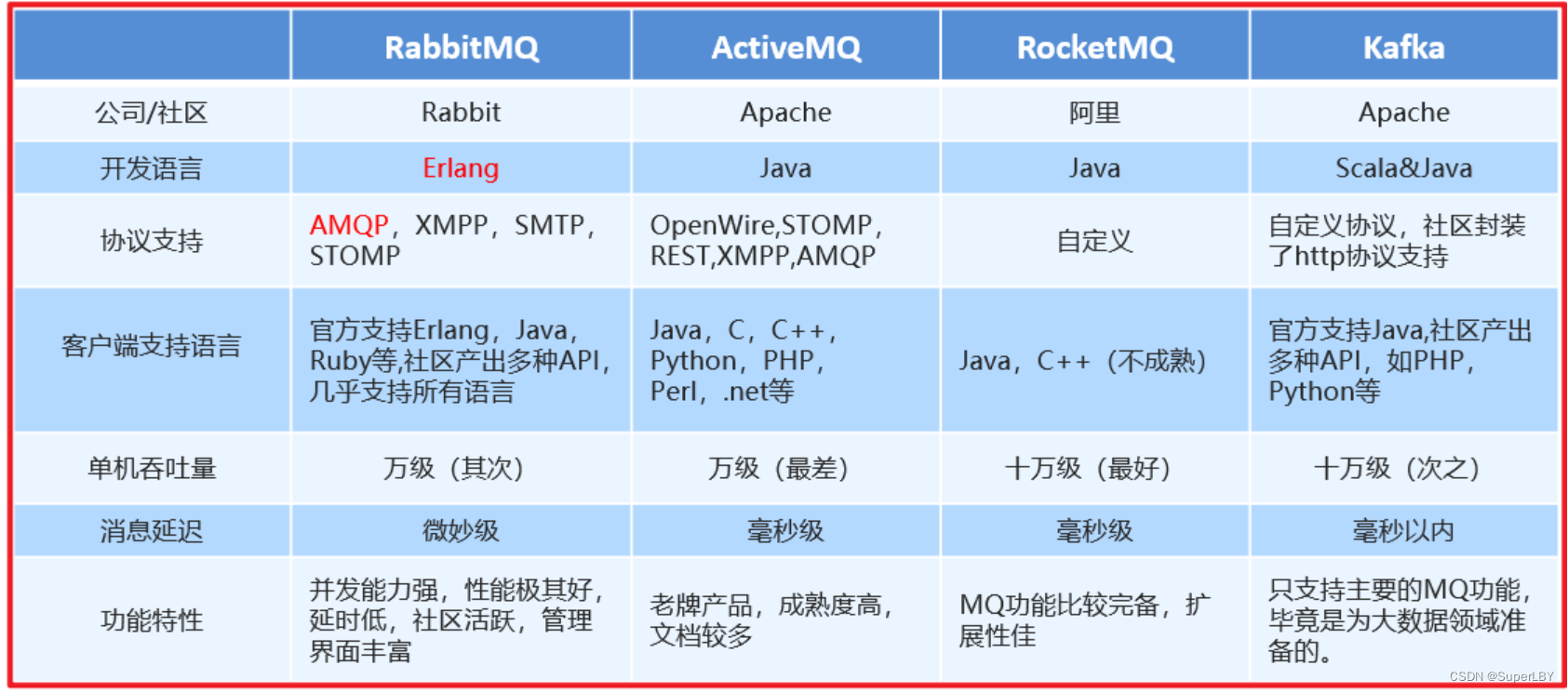
常见消息队列产品
3.AMQP和JMS的区别
- AMQP是一种消息队列链接协议,AMQP不从API层进行限定,而是直接定义网络交换数据格式, 不规定实现方式,因此是跨语言的,而且消息模式更加丰富
常见支持AMQP的消息中间件:RabbitMQ、ActiveMQ、RocketMQ也支持
- JMS是一套java的api规范,用于在分布式系统中发送消息,进行异步通信,具体的实现由各大消息中间件厂商提供。有两种消息模式(点对点和分布订阅模式)
许多常见的消息中间件都实现了JMS
4.RabbitMQ都有哪些消息模式
4.1简单模式
单一生产者将消息发送到队列,单一消费者从队列中接收消息。
适用于基本的点对点通信。
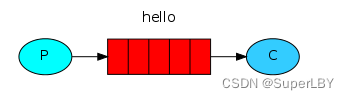
4.2 工作队列模式
也是点对点的模式:一个生产者,可以对应多个消费者,但是只有一个消费者可以获得消息
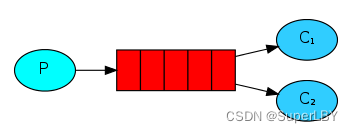
4.3 发布/订阅模式
生产者将消息发布到交换机(Exchange),多个队列通过绑定到该交换机来接收消息。
消息会被广播给所有与交换机绑定的队列。
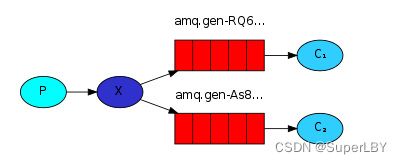
相关场景:邮件群发,群聊天,广播(广告)
4.4 路由模式
队列和交换机绑定以及生产者向交换机发送消息时,都需要指定一个路由key,路由key相同,消息才会成功投递到对应路由key的队列
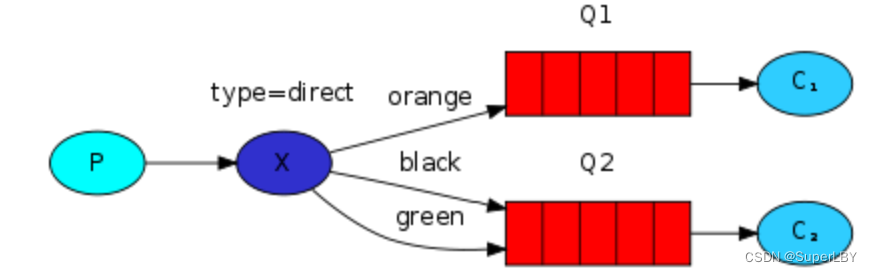
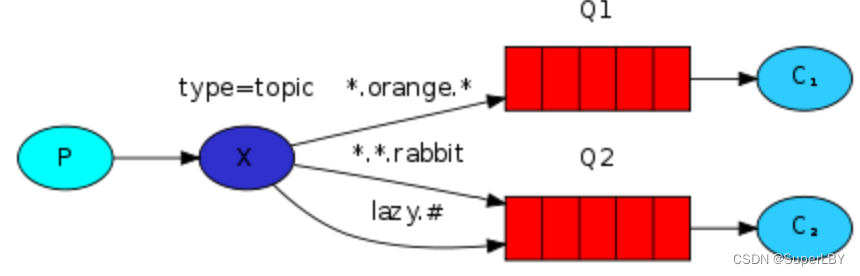
4.5 Topic(主题)模式
Topic模式在路由模式的基础上更进一步,实现通配符进行模糊匹配的机制
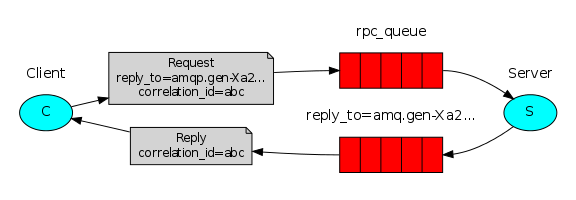
4.6 RPC模式
- 服务端创建RPC队列,等待客户端的请求
- 客户端发送请求时,需要携带一个接受服务端响应结果的队列,以及一个correlation_id
因为所有响应消息都通过一个队列接收,所以通过绑定一个唯一标识correlation_id来分辨响应消息对应的请求。
- 服务端将响应的消息,放到服务端传过来的响应队列
- 客户端会一直监听自己的响应队列,等待服务端的响应
- 客户端收到自己响应队列的服务端响应结果后,判断标识correlation_id是否和自己发出请求时携带的标识一致,一致代表结果是自己请求的结果,不是丢掉
RPC服务器可能会在向我们发送答案后,在发送请求确认消息之前死亡,重启的RPC服务会重新处理客户端的这个请求,直接丢弃可以防止重复响应
5. 交换机有哪些类型
- Fanout:广播,将消息交给所有绑定到交换机的队列
- Direct:定向,把消息交给符合指定routing key 的队列
- Topic:通配符,把消息交给符合routing pattern(路由模式) 的队列
6. 交换机的结构是什么样的
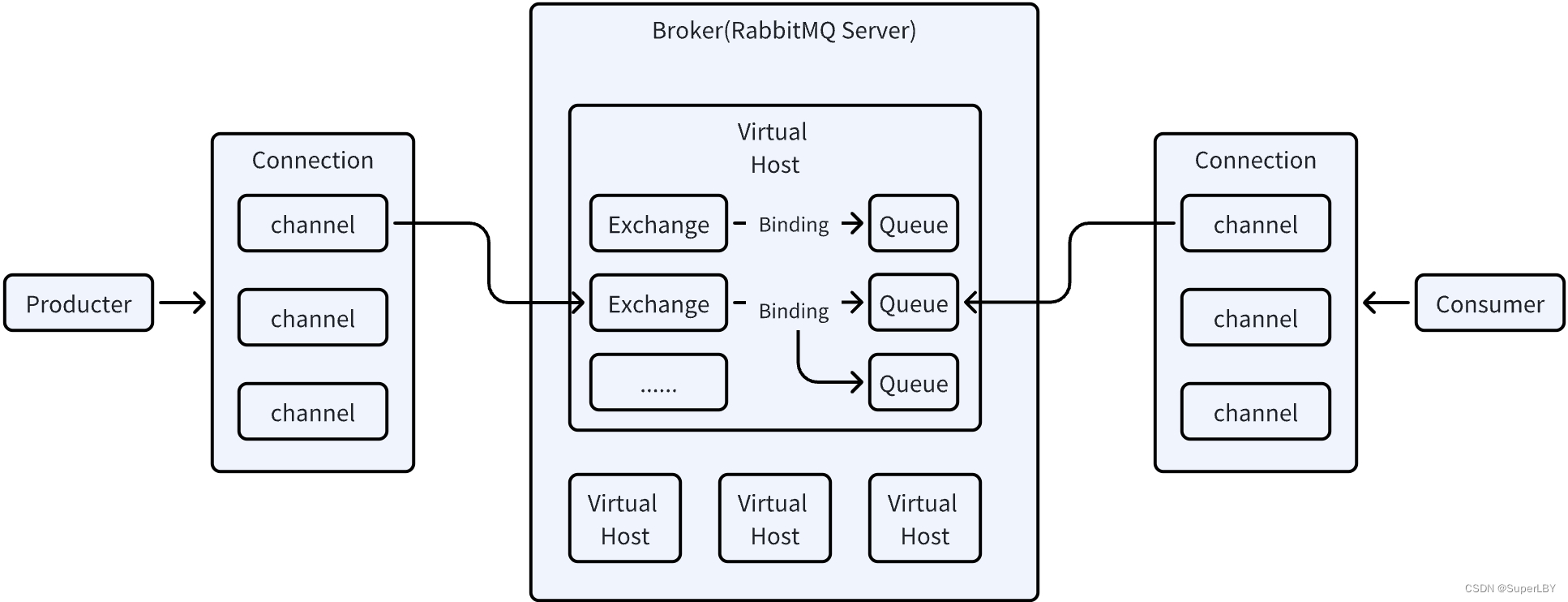
- Producter:生产者,是消息的发送放,将消息发送给Exchange交换器
- Consumer:消费者,是消息的接收方,从消息队列中获取消息,并处理消费
- Broker:接收和分发消息的应用,RabbitMQ Server就是Message Broker
- Virtual Host:当多个不同的用户使用同一个RabbitMQ Server时,可以划分出多个Virtual Host,每个用户在自己的Virtual Host中创建Exchange/Queue等
- Exchange:交换器,根据分发规则,匹配RoutingKey路由键,将消息分发到Queue队列中
- Queue:消息队列,存储消息的容器,消息最终会被送到这里,等待consumer取走
- Binding:Exchange和Queue之间的虚拟连接,binding 中可以包含 routing key,Binding 信息被保存到 exchange 中的查询表中,用于 message 的分发依据
- Connection:publisher/consumer 和 broker 之间的 TCP 连接
- Channel 是在 connection 内部建立的逻辑连接,如果每一次访问 RabbitMQ 都建立一个 Connection,建立 TCP Connection的开销将是巨大的,效率也较低。
7. 如何保证消息成功投递
RabbitMQ在生产者投递消息是有两个过程可能导致消息丢失,分别是消息发送到交换机,和消息从交换机到对列的过程;针对到交换机的过程使用Publisher Confirm,针对交换机到对列使用Publisher Returns。
7.1 Publisher Confirm
消息成功到达交换机,RabbitMQ会给生产者发送ACK确认信号,如果发生交换机不存在,或者路由键不匹配导致消息无法被处理,RabbitMQ会给生产者发送NACK否认信号
7.2 Publisher Returns
如果消息成功路由到消息队列,不会返回消息,否则会将无法路由的消息发送给生产者
RabbitMQ通过以上两种确认回调监听的方式,用于消息无法正常投递到交换机或消息队列时通知给生产者,再投递失败后,我们可以通过重试的方式保证消息一定发送成功
7.3 案例代码
- 引入依赖
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>
- 代码
import org.springframework.amqp.core.*;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import java.nio.charset.StandardCharsets;
public class RabbitMQSendMsgExample {
@Autowired
private RabbitTemplate rabbitTemplate;
public void sendMsg() {
/**
* Publisher Confirm确认模式回调
* 确认模式开启:ConnectionFactory中开启publisher-confirms="true"
*/
rabbitTemplate.setConfirmCallback((correlationData, ack, cause) -> {
if (ack) {
//接收成功
System.out.println("接收成功消息" + cause);
} else {
//接收失败
System.out.println("接收失败消息" + cause);
//做一些处理,让消息再次发送。
}
});
/**
* Publisher Returns回退模式回调
* 开启回退模式:publisher-returns="true"
*/
rabbitTemplate.setMandatory(true);
rabbitTemplate.setReturnCallback(new RabbitTemplate.ReturnCallback() {
/**
* @param message 消息对象
* @param replyCode 错误码
* @param replyText 错误信息
* @param exchange 交换机
* @param routingKey 路由键
*/
@Override
public void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) {
System.out.println("return 执行了....");
System.out.println(message);
System.out.println(replyCode);
System.out.println(replyText);
System.out.println(exchange);
System.out.println(routingKey);
//处理
}
});
Message message = MessageBuilder.withBody("消息".getBytes(StandardCharsets.UTF_8))
.setDeliveryMode(MessageDeliveryMode.PERSISTENT).build();
//3. 发送消息
rabbitTemplate.convertAndSend("RabbitMQ_Message", "routingKey", message);
}
8. 如何保证消息不丢
消息成功投递到消息队列,并不以为着业务完成,RabbitMQ在接收到消息暂存在内存,如果此时RabbitMQ挂掉了,消息还是会丢失,所以通过持久化机制来保证业务成功执行
8.1 持久化消息队列,交换机
持久化后的交换机和消息队列,在RabbitMQ重启后会保留,保证队列和交换机的数据不丢失
@Bean
public Queue TestQueue() {
//第二个参数durable:是否持久化,默认是false
return new Queue("queueName", true, true, false);
}
@Bean
public DirectExchange mainExchange() {
//第二个参数durable:是否持久化,默认是false
return new DirectExchange("exchangeNamw", true, false);
}
8.2 持久化消息
在发布消息时,可以通过设置消息的 deliveryMode 属性为 2 来将其标记为持久化,服务器重启后可以确保消息不丢失,不过设置消息的持久化会增加磁盘的IO开销
Message message = MessageBuilder.withBody("消息".getBytes(StandardCharsets.UTF_8))
.setDeliveryMode(MessageDeliveryMode.PERSISTENT).build();
//3. 发送消息
rabbitTemplate.convertAndSend("RabbitMQ_Message", "routingKey", message);
8.3 消息确认
有了持久化之后,如何保证消息被消费者成功消费
消费者再成功处理消息之后,可以向RabbitMQ发送ACK回执,RabbitMQ收到ACK回执后删除改消息,保证消息不丢失,如果出现异常,就会返回NACK回执,MQ就会重新投递一次消息,如果消费者一直没有返回任何回执消息,MQ也会尝试重新投递一次消息。
ACK表示消费和收到消息后确认的方式,有两种确认方式,分别是自动确认(默认)和手动确认
- 自动确认:消息一旦被消费者接收到,就会自动确认,并且将消息从消息队列移除,但是在实际的业务当中,可能消息接收到了,但是业务处理出现异常了,那改消息就相当于丢失了
- 手动确认:需要在业务成功处理后,调用channel.basicAck(),手动签收,如果出现异常,则在catch中调用 basicNack,拒绝消息,让MQ重新发送消息。
8.4 结合本地消息表
虽然我们经过一些列的持久化,确认机制,但是依然存在消费者确认消息后没来得及使用消息出现宕机的情况,这个消息依然被认为丢失,此时需要在数据库中除了基础的业务表,针对消息队列也需要建立一张表,用来监控消息队列中消息最终的状态,将最终依然失败的消息,通过定时任务隔一段时间将失败的消息重新处理
针对消息队列消息处理情况日志表
CREATE TABLE `broker_message_log` (
`message_id` varchar(255) NOT NULL COMMENT '消息唯一ID',
`message` varchar(4000) NOT NULL COMMENT '消息内容',
`try_count` int(4) DEFAULT '0' COMMENT '重试次数',
`status` varchar(10) DEFAULT '' COMMENT '消息投递状态 0投递中,1投递成功,2投递失败',
`error_message` varchar(4000) NOT NULL COMMENT '失败原因',
`next_retry` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP COMMENT '下一次重试时间',
`create_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
`update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`message_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- 将消息信息存储在数据库中,初始状态0投递中
- 在所有业务全部成功处理后,将状态设置为1投递成功,中间出现的任何异常都记录2投递失败,同时记录回调或者手动ACK将失败信息
- 创建定时任务,根据业务需要拉取状态为2失败的消息,进行最大努力重试,重试超过一定次数还是失败,进行人工排查
9. RabbitMQ如何实现消费端限流
消费端限流是保护消费者所在服务器的手段,当流量达到高峰时,MQ的消费者如果不加限制的进行消费,服务器肯定容易挂掉,甚至重启之后依然无法解决。RabbitMQ可以通过basicQos方式,配置MQ服务器一次性传递给消费者的最大消息数量,当达到这个数量后,RabbitMQ不再推送新的消息给消费者,实现消费端限流。
- 实现这个功能需要关闭自动提交
channel.basicConsume(queueName, false, consumer);
- 配置限流
// 服务器可以将1条消息预先发送给消费者,而不需要等到消费者确认已经处理完先前的消息。
channel.basicQos(1);
10. RabbitMQ消息存活时间(TTL)了解么
当消息到达存活时间后,还没有被消费,会被自动清除。RabbitMQ可以对消息设置过期时间,也可以对整个队列(Queue)设置过期时间。
11. 死信队列
更新中~~~~~~