从这节开始涉及进程间的通信,本节是管道。
管道是一种两个进程间进行单向通信的机制。因为管道传递数据的单向性,管道又称之为半双工管道。。管道的这一特点决定了其使用的局限性。
- 数据只能由一个进程刘翔另一个进程;如果要进行全双工通信,需要建立两个管道。
- 管道只能用于父子进程或者兄弟进程间的通信,也就是说管道只能用于具有亲缘关系的进程间的通信,无亲缘关系的进程不能使用管道。
除了以上局限性,管道还有一些不足。例如管道没有名字,管道的缓冲区大小是受限制的,管道所传送的是无格式的字节流。这就要求管道的输入方和输出方事先约定好数据的格式。虽然有这么多不足,但对于一些简单的进程间的通信,管道还是可以胜任的。
使用管道进行通信时,两端的进程向管道读写数据是通过创建管道时,系统设置的文件描述符进行的。因此对于管道两端的进程来说,管道就是一个特殊的文件,这个文件只存在于内存中。在创建 管道时,系统为管道分配一个页面作为数据缓冲区,进行管道通信的两个进程通过读写这个缓冲区来进行通信。
通过管道通信的两个进程,一个进程向管道写数据,另一个从管道的另一端读数据。写入的数据每次都添加在管道缓冲区的末尾,读数据的时候都是从缓冲区的头部读出数据。
管道的创建与读写
管道的创建
Linux下创建管道可以用函数pipe来完成。该函数如果成功调用返回0,并且数组中将包含两个新的文件描述符;如有错误发生,则返回-1.
#include<unistd.h>
int pipe(int fd[2]);管道两端可分别用描述符fd[0]以及fd[1]来描述。需要注意的是,管道两端的任务是固定的,一段只能用来读,用描述符fd[0]表示,称其为管道读端;另一端只能用于写,由描述符fd[1]来表示,称其为管道写端。如果试图从管道写端读数据,或另一种操作都将导致出错。
管道是一种文件,因此对文件操作的I/O函数都可以用于管道,如read,write等。
注意:管道一旦创建成功,就可以作为一般的文件来使用。对一般文件操作的函数也适用于管道。
管道的一般用法是,进程在使用fork函数创建子进程前先创建一个管道,该管道用于在父子进程间的通信,然后创建子进程,之后父进程关闭管道的读端,子进程关闭管道的写端。父进程负责向管道写数据而子进程负责读数据。当然也可以反过来父进程读子进程写。
从管道中读数据
如果某进程要读取管道中的数据,那么该进程应当关闭fd1, 同时向管道写数据的进程应当关闭fd0。 因为管道只能用于具有亲缘关系的进程间的通信,在各进程进行通信时,它们共享文件描
述符。在使用前,应及时地关闭不需要的管道的另一端,以避免意外错误的发生。
进程在管道的读端读数据时,如果管道的写端不存在,则读进程认为已经读到了数据的末尾,读函数返回读出的字节数为0;管道的写端如果存在,且请求读取的字节数大于PIPE_BUF, 则返回管道中现有的所有数据;如果请求的字节数不大于PIPE_BUF,则返回管道中现有的所有数据(此时,管道中数据量小于请求的数据量),或者返回请求的字节数(此时,管道中数据量大于等于请求的数据量)。
注意: PIPE_BUF在include/linux/limits.h中定义,不同的内核版本可能会有所不同。
从管道中写数据
如果某进程希望向管道中写入数据,那么该进程应该关闭fd0文件描述符,同时管道另一端的进程关闭fd1。向管道中写入数据时,Linux不保证写入的原子性(原子性是指操作在任何时候都不能被任何原因所打断,操作要么不做要么就一定完成)。管道缓冲区一有空闲区域, 写进程就会试图向管道写入数据。如果读进程不读走管道缓冲区中的数据,那么写操作将一直被阻塞等待。
在写管道时,如果要求写的字节数小于等于PIPE_BUF,则多个进程对同一管道的写操作不会交错进行。但是,如果有多个进程同时写一个管道,而且某些进程要求写的字节数超过PIPE_BUF所能容纳时,则多个写操作的数据可能会交错。
注意:只有在管道的读端存在时,向管道中写入数据才有意义。否则,向管道中写入数据的进程将收到内核传来的SIGPIPE信号。应用程序可以处理也可以忽略该信号,如果忽略该信号或者捕捉该信号并从其处理程序返回,则write出错,错误码为EPIPE。
示例程序1
演示管道的创建和读写
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<sys/types.h>
#include <sys/wait.h>
#include<unistd.h>
void read_from_pipe(int fd){
char message[100];
read(fd,message,100);
printf("read from pipe:%s",message);
}
void wtire_to_pipe(int fd){
const char *message="hello pipe!\n";
write(fd,message,strlen(message)+1);//加1是确保'\0'也写进去了
}
int main(int argc,char **argv){
int fd[2];
pid_t pid;
int stat_val;
if(pipe(fd)!=0){//必须在fork前创建管道
printf("create pipe failed!\n");
exit(1);
}
pid=fork();
switch (pid)
{
case -1:
printf("fork error!\n");
break;
case 0:
close(fd[1]);//子进程是读数据,所以要关闭fd1
read_from_pipe(fd[0]);
exit(0);
default://default是父进程执行的部分
close(fd[0]);//父进程是写,所以要关闭fd0
wtire_to_pipe(fd[1]);
wait(&stat_val);
break;
}
return 0;
}执行结果:

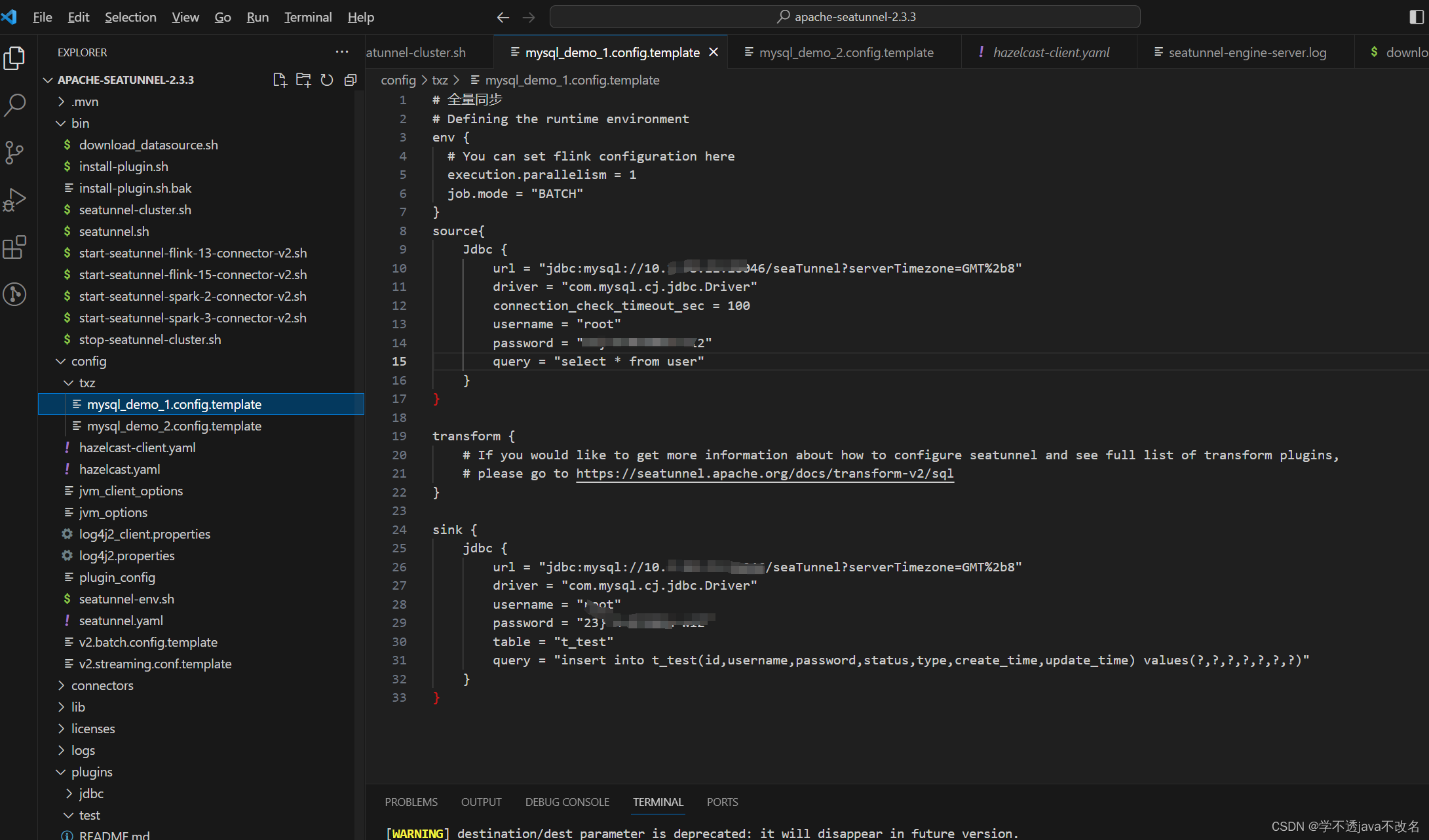
对管道的操作和对一般文件没什么区别。对fork,read,write和wait不了解的可以看我以前的文章。
在管道里,默认read是阻塞的,也就是说如果管道没有数据可读,read函数会一直等待。这样就没有说子进程先执行读父进程再执行写的问题了,因为子进程会一直等到父进程把数据写到管道再读。
示例程序2
管道是半双工的,可以用两个管道来实现全双工通信。
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<sys/types.h>
#include <sys/wait.h>
#include<unistd.h>
void child_rw_pipe(int readfd,int writefd){
const char *message1="from child process!\n";
write(writefd,message1,strlen(message1)+1);
char message2[100];
read(readfd,message2,100);
printf("child process read from pipe:%s",message2);
}
void parent_rw_pipe(int readfd,int writefd){
const char *message1="from parent process!\n";
write(writefd,message1,strlen(message1)+1);
char message2[100];
read(readfd,message2,100);
printf("parent process read from pipe:%s",message2);
}
int main(int argc,char **argv){
int pipe1[2],pipe2[2];
pid_t pid;
int stat_val;
printf("realize full-duplex communication:\n\n");
if(pipe(pipe1)){
printf("pipe1 failed\n");
exit(1);
}
if(pipe(pipe2)){
printf("pipe2 failed\n");
exit(1);
}
pid=fork();
switch (pid)
{
case -1:
printf("fork error!\n");
exit(1);
case 0:
close(pipe1[1]);
close(pipe2[0]);
child_rw_pipe(pipe1[0],pipe2[1]);
exit(0);
default:
close(pipe1[0]);
close(pipe2[1]);
parent_rw_pipe(pipe2[0],pipe1[1]);
wait(&stat_val);
exit(0);
}
}运行结果:
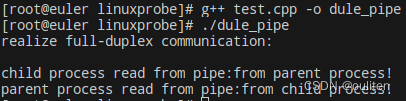
代码就是多了一个管道,和上一个几乎一样。
dup()和dup2()
前面的例子,子进程可以直接共享父进程的文件描述符,但是如果子进程调用exec去执行另外一个应用程序时,就不能再共享了。这种情况可以将子进程中的文件描述符重定向到标准输入,当新执行的程序从标准输入获取数据时实际上是从父进程中获取数据。
这两个函数则是提供了复制文件描述符的功能,在《Linux C编程实战》笔记:一些系统调用-CSDN博客已经介绍过。
具体使用如下所示
//用dup
pid=fork();
if(pid==0){
//关闭子进程标准输出
close(1);
//复制管道写端到标准输出,这样像printf就会输出到管道
dup(fd[1]);
execve("your_process",argv,environ);
}//用dup2的例子
pid=fork();
if(pid==0){
close(1);
dup2(fd[1],1);
execve("your_process",argv,environ);
}管道的应用实例
管道的一种常见的用法,在父进程创建子进程后向子进程传递参数。例如,一个应用软件有一个主进程和很多个不同的子进程。主进程创建子进程后,在子进程调用exec函数执行一个新程序之前,通过管道给即将执行的程序传递命令行参数,子进程根据床来的参数进行初始化或其他操作
示例程序3
首先是子进程之后要执行的代码
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<sys/types.h>
#include <sys/wait.h>
#include<unistd.h>
int main(int argc,char **argv){
int n;
char buffer[1024];
while (1)
{
//从标准输入中读,父进程会修改子进程的标准输入
if((n=read(STDIN_FILENO,buffer,1024))>0){
buffer[n]='\0';
printf("ctrlprocess receive:%s\n",buffer);
if(!strcmp(buffer,"exit"))
exit(0);
if(!strcmp(buffer,"getpid")){
printf("My pid:%d\n",getpid());
sleep(3);
exit(0);
}
}
}
}然后是主进程
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<sys/types.h>
#include <sys/wait.h>
#include<unistd.h>
int main(int argc,char **argv,char **environ){
int fd[2];
pid_t pid;
int stat_val;
if(argc<2){
printf("wrong parameters");
exit(0);
}
if(pipe(fd)){
perror("pipe failed");
exit(1);
}
pid=fork();
switch (pid)
{
case -1:
perror("fork failed!\n");
exit(1);
case 0:
//子进程先关闭自己的标准输入
close(0);
//标准输入重定向到管道的读入端
dup(fd[0]);
execve("ctrlprocess",argv,environ);
exit(0);
default:
//这里是父进程
close(fd[0]);
write(fd[1],argv[1],strlen(argv[1]));
break;
}
wait(&stat_val);
exit(0);
}执行结果:
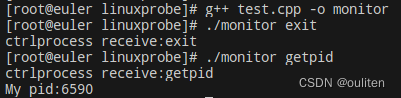
顺带一提,如果直接执行./ctrlprocess 的话,输入getpid或者exit都是进不去if(strcmp...)的,因为这时候的标准输入还是命令行,命令行里输入getpid,实际上读入的是"getpid\n",这会导致strcmp比较不准。而通过父进程的argv参数,这个参数是不会带\n的,写入管道也不会带\n,能确保子进程通过标准输入(也就是管道)读入的是完整的字符串,只需要在最后加\0就行了









![[Grafana]ES数据源Alert告警发送](https://img-blog.csdnimg.cn/direct/ed9b6dd33dcf4a338f57901498de61e9.png)