500行代码构建对话搜索引擎,贾扬清被内涵的Lepton Search真开源了

来了,贾扬清承诺的 Lepton Search 开源代码来了。前天,贾扬清在 Twitter 上公布了 Lepton Search 的开源项目链接,并表示任何人、任何公司都可以自由使用开源代码。也就是说,你也可以用不到 500 行 Python 代码构建自己的对话搜索引擎了。今天,Lepton Search 又登上了 GitHub trending 榜单。此外已经有人将这个开源项目用来构建自己的 Web 应用程序了,并表示质量非常高,与 AI 驱动的搜索引擎 Perplexity 不相上下。
基于量子辅助深度学习的逆向分子设计

康奈尔大学Fengqi You教授团队,通过结合量子计算(QC)与生成式AI的优势,提出了一个新颖的逆向分子设计框架。该框架利用QC辅助的深度学习模型来学习和模拟化学空间,从而预测并生成具有特定化学性质的分子结构。生成式AI在此过程中起着核心作用,它能够从大量的分子数据中学习潜在的结构-性质关系,并生成新的分子候选物,这些分子不仅符合预设的性质,还考虑到合成的可行性。量子计算的加入则为这一过程提供了高效的计算能力和优化算法,克服了传统计算机在处理大规模化学系统时的性能瓶颈。通过这种量子-经典混合计算框架,研究人员能够在复杂的化学空间中进行高效、有效的分子设计,为新分子的发现和材料科学的进步开辟了新途径。
百川智能上新超千亿大模型Baichuan 3,冲榜成绩:若干中文任务超车GPT-4

走月更路线的百川智能,在年前猛地加速,变成了半月更:发布了超千亿参数的最新版本大模型Baichuan 3,是百川智能基础模型第三代——就在20天前,这家由王小川创办的大模型公司,刚刚发布过角色大模型Baichuan-NPC。更具标志性的是,百川智能这次模型更新,重点展示了模型在医疗场景的能力。
Meta官方的Prompt工程指南:Llama 2这样用更高效

随着大型语言模型(LLM)技术日渐成熟,提示工程(Prompt Engineering)变得越来越重要。一些研究机构发布了 LLM 提示工程指南,包括微软、OpenAI 等等。最近,Llama 系列开源模型的提出者 Meta 也针对 Llama 2 发布了一份交互式提示工程指南,涵盖了 Llama 2 的快速工程和最佳实践。
AI也造代码屎山!研究发现GitHub Copilot代码可维护性差,偏爱“无脑重写”而非重构复用已有代码
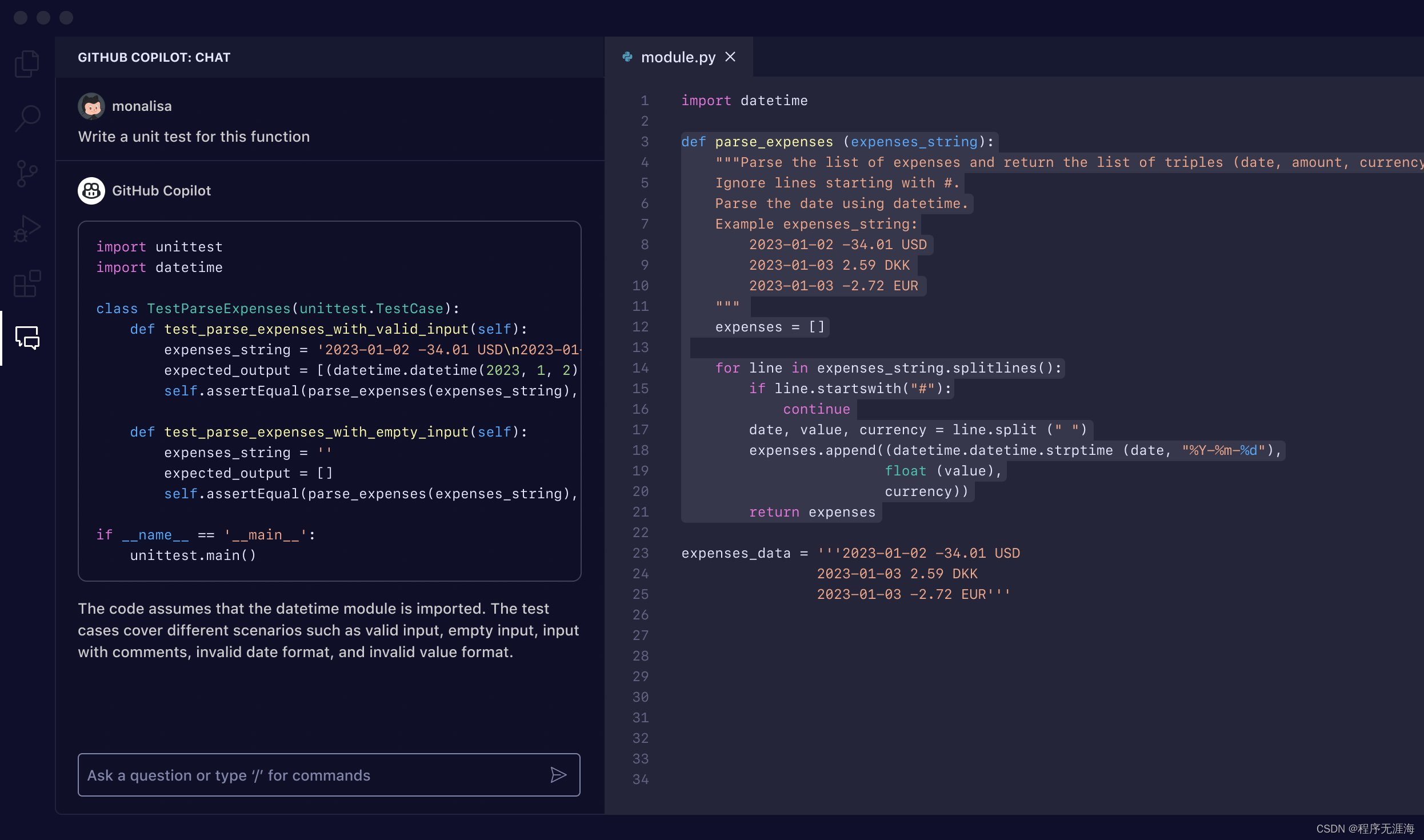
AI帮忙写代码程序员用了都说好,但代码质量真的靠谱吗?结果或许令你大跌眼镜。一家名为GitClear的公司分析了近四年超过1.5亿行代码后发现,随着GitHub Copilot工具的加入,代码流失率(即代码写入后不久又被返工修改、删除的情况)出现了显著上升:2023年为7.1%,而2020年时仅为3.3%,翻了一番。
OpenAI 董事会主席 Bret Taylor 的 AI 公司估值 10 亿美元!红杉美国领投,专注企业解决方案

Bret Taylor,前 Salesforce 联合 CEO,他曾创立了一家开发了基于云的文字处理器和电子表格应用 Quip 的软件公司,2016 年以约 7.5亿 美元的价格出售给了 Salesforce。去年,Taylor 加入了 OpenAI 董事会,担任董事长,并在与 ChatGPT 制造商前董事会的一项协议中,帮助重新任命了被罢免的 CEO Sam Altman。外媒预计 Taylor 的角色是临时性的,以便他能够回到自己的公司。这家公司名为 Sierra 的 AI 初创公司,由 Bret Taylor 和前谷歌高管,曾领导谷歌 AR/VR 工作的 Clay Bavor 共同创立,正进行一轮新的融资活动。
从零手搓MoE大模型,大神级教程来了
 https://huggingface.co/blog/AviSoori1x/makemoe-from-scratch
https://huggingface.co/blog/AviSoori1x/makemoe-from-scratch
传说中GPT-4的“致胜法宝”——MoE(混合专家)架构,自己也能手搓了!Hugging Face上有一位机器学习大神,分享了如何从头开始建立一套完整的MoE系统。这个项目被作者叫做MakeMoE,详细讲述了从注意力构建到形成完整MoE模型的过程。作者介绍,MakeMoE是受到OpenAI创始成员Andrej Karpathy的makemore启发并以之为基础编写的。makemore是一个针对自然语言处理和机器学习的教学项目,意在帮助学习者理解并实现一些基本模型。同样,MakeMoE也是在一步步的搭建过程中,帮助学习者更深刻地理解混合专家模型。
elvis:多模态大型语言模型的进展
elvis:最近几周,我们看到了多模态大型语言模型(MM-LLMs)研究论文的激增。
在这些出版物中,有一项很好的综合调查,总结了26种现有的MM-LLMs。
它还包括增强这些模型的训练配方、洞察力和一些有前途的研究方向。
能够轻松调整和增强这些系统真是不可思议。这也要感谢最近围绕MM-LLMs的开源工作,包括数据集、基准测试和模型。
Jeremy Howard 分享《CUDA-MODE 讲座3:CUDA入门》:面向所有Python背景的人的CUDA入门
CUDA-MODE 讲座3:CUDA入门
视频:https://youtu.be/6E7K4SGlXas?si=x1pCOaGdRZrvDMqw
笔记本:https://github.com/cuda-mode/lecture2/blob/main/lecture3/pmpp.ipynb
🏎️面向所有Python背景的人的CUDA入门!
@jeremyphoward 首先在Python中构建内核(使用blockIdx和threadIdx) -> 然后将它们转换为CUDA C。
如何从头开始构建大型语言模型
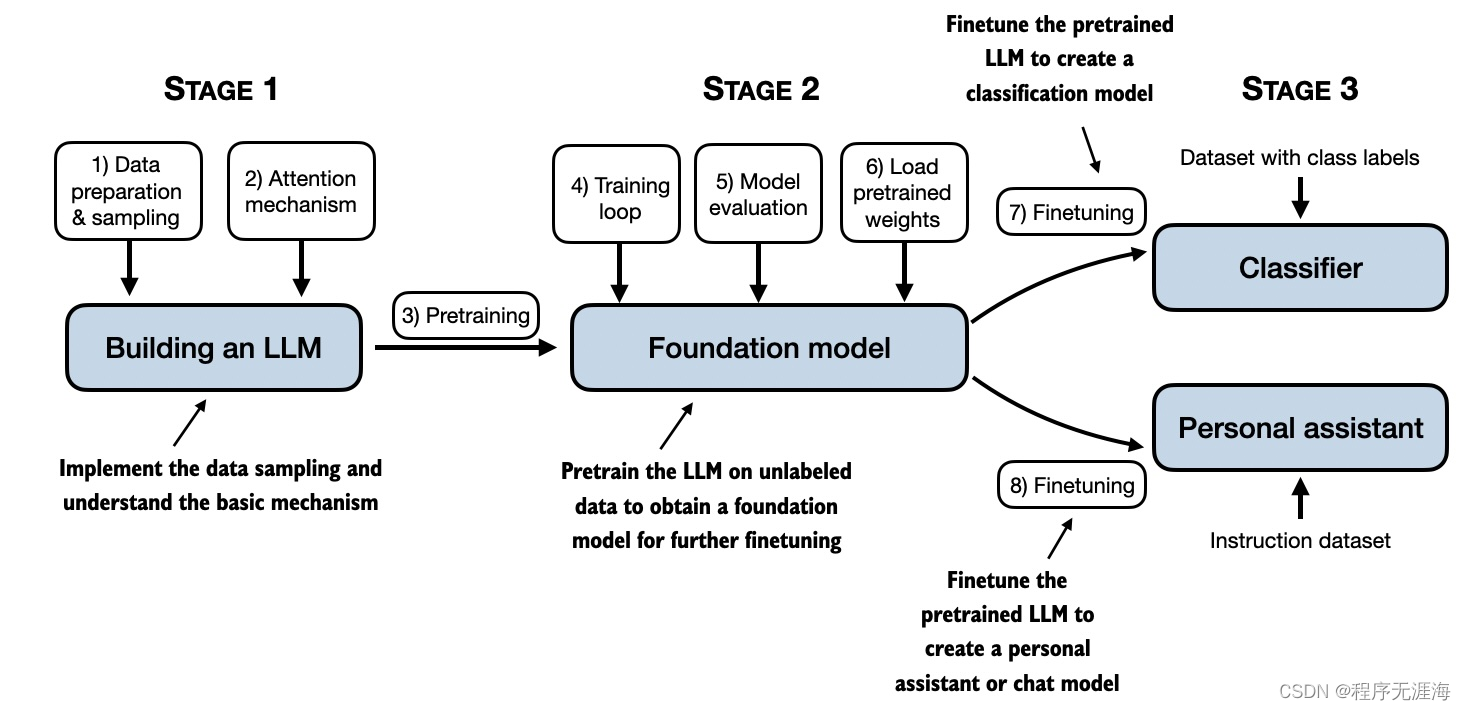
在如何从头开始构建大型语言模型的书中,读者将了解如何从内到外 构建 LLMs 的工作。作者将指导用户逐步创建自己的LLM阶段,用清晰的文本、图表和示例解释每个阶段。GitHub 中作者公开啦相关代码,同时也可以进行学习,感兴趣细节的朋友们可以读一读。
The Future of Prosumer: The Rise of “AI Native” Workflows
文章概述了基于人工智能原生工作流的未来展望。在这一领域,人工智能为创始人提供了完全重塑工作流程的机会,预示着全新一代完全基于人工智能的公司的诞生。这些公司将以现有技术为起点,围绕人工智能独特的生成、编辑和组合能力构建新产品。文章强调,人工智能原生平台将提升用户与软件的交互方式,使用户能够将低技能任务委托给人工智能助手,专注于更高层次的思考。同时,人工智能还将帮助用户解锁全新的技术和审美技能,缩小创造力与技艺之间的差距,让每个人都能成为新一代的“专业用户”。
2023年大语言模型融合技术调研与实践指南
本文探讨了大语言模型融合技术,介绍了五种融合算法:任务向量模型编辑(EMTA)、球面线性插值(SLERP)、修整选举合并(TIES)、剪枝缩放(DARE)和直通(Passthrough)。这些技术允许在不重新训练或使用GPU的情况下,通过合并不同模型的参数来增强模型能力。文章通过mergekit工具包展示了如何实现这些算法,并提供了配置示例。特别提到了使用SLERP方法创建的Marcoro14-7B-slerp模型,在Open LLM排行榜上表现优异。这些方法为未来语言模型的能力模块化组装提供了新途径。
PAI-ChatLearn :灵活易用、大规模 RLHF 高效训练框架(阿里云最新实践)
PAI-ChatLearn 是阿里云PAI团队开发的大规模RLHF(基于人类反馈的强化学习)训练框架,专为大模型设计,支持SFT(有监督指令微调)、RM(奖励模型)和RLHF全流程训练。该框架采用灵活的并行策略,包括数据并行、模型并行和任务并行,以适应不同规模的模型训练需求。PAI-ChatLearn 提供了高效的参数同步机制和环境隔离,支持不同后端的推理和训练,简化了模型封装和开发流程。在实际应用中,PAI-ChatLearn 已成功支持175B+175B规模的模型训练,并在性能上优于业界框架,有助于用户专注于模型效果的优化。






![uniapp对接微信APP支付返回requestPayment:fail [payment微信:-1]General errors错误-全网总结详解](https://img-blog.csdnimg.cn/742bc7da3e274776bc2280299e3701aa.png)