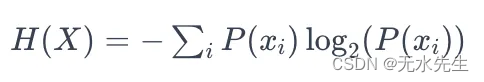基础语法
%% Matlab基本的小常识
% (1)在每一行的语句后面加上分号(一定要是英文的哦;中文的长这个样子;)表示不显示运行结果
a = 3;
a = 5
% (2)多行注释:选中要注释的若干语句,快捷键Ctrl+R
% a = 3;
% a = 5
% (3)取消注释:选中要取消注释的语句,快捷键Ctrl+T
% 我想要取消注释下面这行
% 还有这一行
% clear可以清楚工作区的所有变量
clear
% clc可以清除命令行窗口中的所有文本,让屏幕变得干净
clc
% 所以大家在很多代码开头,都会见到:
clear;clc % 分号也用于区分行。
% 这两条一起使用,起到“初始化”的作用,防止之前的结果对新脚本文件(后缀名是 .m)产生干扰。
%% 基础:matlab中如何提取矩阵中指定位置的元素?
% (1)取指定行和列的一个元素(输出的是一个值)
clc;A=[1 1 4 1/3 3;1 1 4 1/3 3;1/4 1/4 1 1/3 1/2;3 3 3 1 3;1/3 1/3 2 1/3 1];
A
A(2,1)
A(3,2)
% (2)取指定的某一行的全部元素(输出的是一个行向量)
clc;A
A(2,:)
A(5,:)
% (3)取指定的某一列的全部元素(输出的是一个列向量)
clc;A
A(:,1)
A(:,3)
% (4)取指定的某些行的全部元素(输出的是一个矩阵)
clc;A
A([2,5],:) % 只取第二行和第五行(一共2行)
A(2:5,:) % 取第二行到第五行(一共4行)
A(2:2:5,:) % 取第二行和第四行 (从2开始,每次递增2个单位,到5结束)
1:3:10
10:-1:1
A(2:end,:) % 取第二行到最后一行
A(2:end-1,:) % 取第二行到倒数第二行
% (5)取全部元素(按列拼接的,最终输出的是一个列向量)
clc;A
A(:)
判断语句
%% 矩阵与常数的大小判断运算
% 共有三种运算符:大于> ;小于< ;等于 == (一个等号表示赋值;两个等号表示判断)
clc
X = [1 -3 0;0 0 8;4 0 6]
X > 0
X == 4 % 返回一个矩阵
%% 判断语句
% Matlab的判断语句,if所在的行不需要冒号,语句的最后一定要以end结尾 ;中间的语句要注意缩进。
a = input('请输入考试分数:')
if a >= 85
disp('成绩优秀')
elseif a >= 60
disp('成绩合格')
else
disp('成绩挂科')
end
函数与算法
输入输出函数
%% 输出和输入函数(disp 和 input)
% disp函数
% matlab中disp()就是屏幕输出函数,类似于c语言中的printf()函数
disp('我是清风,大家好鸭~~~记得投币关注我哦')
a = [1,2,3] %同一行中间用逗号分隔,也可以不用逗号,直接用空格
a = [1 2 3]
disp(a)
% 注意,disp函数比较特殊,这里可要分号,可不要分号哦
disp(a);
% matlab中两个字符串的合并有两种方法
% (1)strcat(str1,str2……,strn)
strcat('字符串1','字符串2')
% (2)[str 1,str 2,……, str n]或[str1 str2 …… strn]
['字符串1' '字符串2']
['字符串1','字符串2']
% 一个有用的字符串函数:num2str 将数字转换为字符串
c = 100
num2str(c)
disp(['c的取值为' num2str(c)])
disp(strcat('c的取值为', num2str(c)))
% input函数
% 一般我们会将输入的数、向量、矩阵、字符串等赋给一个变量,这里我们赋给A
A = input('请输入A:');
B = input('请输入B:')
% 注意观察工作区,并体会input后面加分号和不加分号的区别
sum函数
%% sum函数
% (1)如果是向量(无论是行向量还是列向量),都是直接求和
E = [1,2,3]
sum(E)
E = [1;2;3]
sum(E)
% (2)如果是矩阵,则需要根据行和列的方向作区分
clc
E = [1,2;3,4;5,6]
% a=sum(x); %按列求和(得到一个行向量)
a = sum(E)
a = sum(E,1)
% a=sum(x,2); %按行求和(得到一个列向量)
a = sum(E,2)
% a=sum(x(:));%对整个矩阵求和
a = sum(sum(E))
a = sum(E(:))
Size函数
%% size函数
clc;
A = [1,2,3;4,5,6]
B = [1,2,3,4,5,6]
size(A)
size(B)
% size(A)函数是用来求矩阵A的大小的,它返回一个行向量,第一个元素是矩阵的行数,第二个元素是矩阵的列数
[r,c] = size(A)
% 将矩阵A的行数返回到第一个变量r,将矩阵的列数返回到第二个变量c
r = size(A,1) %返回行数
c = size(A,2) %返回列数
repmat函数
%% repmat函数
% B = repmat(A,m,n):将矩阵A复制m×n块,即把A作为B的元素,B由m×n个A平铺而成。
A = [1,2,3;4,5,6]
B = repmat(A,2,1)
B = repmat(A,3,2)
矩阵运算
%% Matlab中矩阵的运算
% MATLAB在矩阵的运算中,“*”号和“/”号代表矩阵之间的乘法与除法(A/B = A*inv(B))
A = [1,2;3,4]
B = [1,0;1,1]
A * B
inv(B) % 求B的逆矩阵
B * inv(B)
A * inv(B)
A / B
% 两个形状相同的矩阵对应元素之间的乘除法需要使用“.*”和“./”
A = [1,2;3,4]
B = [1,0;1,1]
A .* B
A ./ B
% 每个元素同时和常数相乘或相除操作都可以使用
A = [1,2;3,4]
A * 2
A .* 2
A / 2
A ./ 2
% 每个元素同时乘方时只能用 .^
A = [1,2;3,4]
A .^ 2
A ^ 2
A * A
求特征值
%% Matlab中求特征值和特征向量
% 在Matlab中,计算矩阵A的特征值和特征向量的函数是eig(A),其中最常用的两个用法:
A = [1 2 3 ;2 2 1;2 0 3]
% (1)E=eig(A):求矩阵A的全部特征值,构成向量E。
E=eig(A)
% (2)[V,D]=eig(A):求矩阵A的全部特征值,构成对角阵D,并求A的特征向量构成V的列向量。(V的每一列都是D中与之相同列的特征值的特征向量)
[V,D]=eig(A)
find函数
%% find函数的基本用法
% 下面例子来自博客:https://www.cnblogs.com/anzhiwu815/p/5907033.html 博客内有更加深入的探究
% find函数,它可以用来返回向量或者矩阵中不为0的元素的位置索引。
clc;X = [1 0 4 -3 0 0 0 8 6]
ind = find(X)
% 其有多种用法,比如返回前2个不为0的元素的位置:
ind = find(X,2)
%上面针对的是向量(一维),若X是一个矩阵(二维,有行和列),索引该如何返回呢?
clc;X = [1 -3 0;0 0 8;4 0 6]
ind = find(X)
% 这是因为在Matlab在存储矩阵时,是一列一列存储的,我们可以做一下验证:
X(4)
% 假如你需要按照行列的信息输出该怎么办呢?
[r,c] = find(X)
[r,c] = find(X,1) %只找第一个非0元素
sort函数
% sort(A)若A是向量不管是列还是行向量,默认都是对A进行升序排列。sort(A)是默认的升序,而sort(A,'descend')是降序排序。
% sort(A)若A是矩阵,默认对A的各列进行升序排列
% sort(A,dim)
% dim=1时等效sort(A)
% dim=2时表示对A中的各行元素升序排列
% A = [2,1,3,8]
% Matlab中给一维向量排序是使用sort函数:sort(A),排序是按升序进行的,其中A为待排序的向量;
% 若欲保留排列前的索引,则可用 [sA,index] = sort(A,'descend') ,排序后,sA是排序好的向量,index是向量sA中对A的索引。
% sA = 8 3 2 1
% index = 4 3 1 2
plot函数
% plot函数用法:
% plot(x1,y1,x2,y2)
% 线方式: - 实线 :点线 -. 虚点线 - - 波折线
% 点方式: . 圆点 +加号 * 星号 x x形 o 小圆
% 颜色: y黄; r红; g绿; b蓝; w白; k黑; m紫; c青
figure函数
figure(1); % 在同一个脚本文件里面,要想画多个图,需要给每个图编号,否则只会显示最后一个图哦~
匿名函数
% 匿名函数的基本用法。
% handle = @(arglist) anonymous_function
% 其中handle为调用匿名函数时使用的名字。
% arglist为匿名函数的输入参数,可以是一个,也可以是多个,用逗号分隔。
% anonymous_function为匿名函数的表达式。
% 举个小例子
% z=@(x,y) x^2+y^2; 等效于z=x^2+y^2(但因为默认识别xy为矩阵所有会报错)
% z(1,2) (x=1,y=2)
% % answer = 5
% fplot函数可用于画出匿名一元函数的图形。
% fplot(f,xinterval) 将匿名函数f在指定区间xinterval绘图。xinterval = [xmin xmax] 表示定义域的范围
f=@(x) k*x+b;
fplot(f,[2.5,7]);
legend('样本数据','拟合函数','location','SouthEast')%根据变量在plot函数中出现的顺序添加备注
rand函数
% (1)randi : 产生均匀分布的随机整数(i = int)
%产生一个1至10之间的随机整数矩阵,大小为2x5;
s1 = randi(10,2,5)
%产生一个-5至5之间的随机整数矩阵,大小为1x10;
s2 = randi([-5,5],1,10)
% (2) rand: 产生0至1之间均匀分布的随机数
%产生一个0至1之间的随机矩阵,大小为1x5;
s3 = rand(1,5)
%产生一个a至b之间的随机矩阵,大小为1x5; % a + (b-a) * rand(1,5); 如:a,b = 2,5
s4= 2 + (5-2) * rand(1,5)
normrnd函数(正态分布)
% (3)normrnd:产生正态分布的随机数
%产生一个均值为0,标准差(方差开根号)为2的正态分布的随机矩阵,大小为3x4;
s5 = normrnd(0,2,3,4)
roundn函数(四舍五入)
% (4)roundn—任意位置四舍五入
% 0个位 1十位 2百位 -1小数点后一位
a = 3.1415
roundn(a,-2) % ans = 3.1400
roundn(a,2) % ans = 0
a =31415
roundn(a,2) % ans = 31400
roundn(5.5,0) %6
roundn(5.5,1) %10
自定义方法(函数)
自定义的函数要单独放在一个m文件中,不可以直接放在主函数里面(和其他大多数语言不同)
图论
% 注意哦,Matlab中的图节点要从1开始编号,所以这里把0全部改为了9
% 编号最好是从1开始连续编号,不要自己随便定义编号
s = [9 9 1 1 2 2 2 7 7 6 6 5 5 4];
t = [1 7 7 2 8 3 5 8 6 8 5 3 4 3];
w = [4 8 3 8 2 7 4 1 6 6 2 14 10 9];
G = graph(s,t,w);
plot(G, 'EdgeLabel', G.Edges.Weight, 'linewidth', 2)
set( gca, 'XTick', [], 'YTick', [] );
[P,d] = shortestpath(G, 9, 4) %注意:该函数matlab2015b之后才有哦
% 在图中高亮我们的最短路径
myplot = plot(G, 'EdgeLabel', G.Edges.Weight, 'linewidth', 2); %首先将图赋给一个变量
highlight(myplot, P, 'EdgeColor', 'r') %对这个变量即我们刚刚绘制的图形进行高亮处理(给边加上r红色)
% 求出任意两点的最短路径矩阵
D = distances(G) %注意:该函数matlab2015b之后才有哦
D(1,2) % 1 -> 2的最短路径
D(9,4) % 9 -> 4的最短路径
% 找出给定范围内的所有点 nearest(G,s,d)
% 返回图形 G 中与节点 s 的距离在 d 之内的所有节点
[nodeIDs,dist] = nearest(G, 2, 10) %注意:该函数matlab2016a之后才有哦
分析
相关性分析(皮尔逊)
统计描述
MIN = min(Test); % 每一列的最小值
MAX = max(Test); % 每一列的最大值
MEAN = mean(Test); % 每一列的均值
MEDIAN = median(Test); %每一列的中位数
SKEWNESS = skewness(Test); %每一列的偏度
KURTOSIS = kurtosis(Test); %每一列的峰度
STD = std(Test); % 每一列的标准差
RESULT = [MIN;MAX;MEAN;MEDIAN;SKEWNESS;KURTOSIS;STD] %将这些统计量放到一个矩阵中表示
计算各列之间的相关系数
% 在计算皮尔逊相关系数之前,一定要做出散点图来看两组变量之间是否有线性关系
% 这里使用Spss比较方便: 图形 - 旧对话框 - 散点图/点图 - 矩阵散点图
R = corrcoef(Test) % correlation coefficient
假设检验
- 普通方法(对临界的P求正态分布函数对应的值)
此处为案例,数据无特定含义
x = -4:0.1:4;
y = tpdf(x,28); %求t分布的概率密度值 28是自由度
figure(1)
plot(x,y,'-')
grid on % 在画出的图上加上网格线
hold on % 保留原来的图,以便继续在上面操作
% matlab可以求出临界值,函数如下(反函数)
tinv(0.975,28) % 2.0484
% 这个函数是累积密度函数cdf的反函数
plot([-2.048,-2.048],[0,tpdf(-2.048,28)],'r-')
plot([2.048,2.048],[0,tpdf(2.048,28)],'r-')
- P值法(推荐)
此处是案例,数据无特定含义
%% 计算p值
x = -4:0.1:4;
y = tpdf(x,28);
figure(2)
plot(x,y,'-')
grid on
hold on
% 画线段的方法
plot([-3.055,-3.055],[0,tpdf(-3.055,28)],'r-')
plot([3.055,3.055],[0,tpdf(3.055,28)],'r-')
disp('该检验值对应的p值为:')
disp((1-tcdf(3.055,28))*2) %双侧检验的p值要乘以2
一步到位的方法
%% 计算各列之间的相关系数以及p值
[R,P] = corrcoef(Test)
% 在EXCEL表格中给数据右上角标上显著性符号吧
P < 0.01 % 标记3颗星的位置
(P < 0.05) .* (P > 0.01) % 标记2颗星的位置
(P < 0.1) .* (P > 0.05) % % 标记1颗星的位置
% 也可以使用Spss操作哦 看我演示
正态分布(使用皮尔逊的前置条件)的检验
%% 正态分布检验
% 正态分布的偏度和峰度
x = normrnd(2,3,100,1); % 生成100*1的随机向量,每个元素是均值为2,标准差为3的正态分布
skewness(x) %偏度
kurtosis(x) %峰度
qqplot(x)
% 检验第一列数据是否为正态分布
[h,p] = jbtest(Test(:,1),0.05)
[h,p] = jbtest(Test(:,1),0.01)
% 用循环检验所有列的数据
n_c = size(Test,2); % number of column 数据的列数
H = zeros(1,6); % 初始化节省时间和消耗
P = zeros(1,6);
for i = 1:n_c
[h,p] = jbtest(Test(:,i),0.05);
H(i)=h;
P(i)=p;
end
disp(H)
disp(P)
% Q-Q图
qqplot(Test(:,1))
相关性分析(斯皮尔曼)
%% 斯皮尔曼相关系数
X = [3 8 4 7 2]' % 一定要是列向量哦,一撇'表示求转置
Y = [5 10 9 10 6]'
% 第一种计算方法
1-6*(1+0.25+0.25+1)/5/24
% 第二种计算方法
coeff = corr(X , Y , 'type' , 'Spearman')
% 等价于:
RX = [2 5 3 4 1]
RY = [1 4.5 3 4.5 2]
R = corrcoef(RX,RY)
% 计算矩阵各列的斯皮尔曼相关系数
R = corr(Test, 'type' , 'Spearman')
% 大样本下的假设检验
% 计算检验值
disp(sqrt(590)*0.0301)
% 计算p值
disp((1-normcdf(0.7311))*2) % normcdf用来计算标准正态分布的累积概率密度函数
% 直接给出相关系数和p值
[R,P]=corr(Test, 'type' , 'Spearman')
回归分析
见Stata代码文件
规划模型
线性规划


%% Matlab求解线性规划
% [x fval] = linprog(c, A, b, Aeq, beq, lb,ub, x0)
% c是目标函数的系数向量,A是不等式约束Ax<=b的系数矩阵,b是不等式约束Ax<=b的常数项
% Aeq是等式约束Aeq x=beq的系数矩阵,beq是等式约束Aeq x=beq的常数项
% lb是X的下限,ub是X的上限,X是向量[x1,x2,...xn]' , 即决策变量。
% 迭代的初始值为x0(一般不用给)
% 更多该函数的用法说明请看讲义
%% 例题1
c = [-5 -4 -6]'; % 加单引号表示转置
% c = [-5 -4 -6]; % 写成行向量也是可以的,不过不推荐,我们按照标准型来写看起来比较正规
A = [1 -1 1;
3 2 4;
3 2 0];
b = [20 42 30]';
lb = [0 0 0]';
[x fval] = linprog(c, A, b, [], [], lb) % ub我们直接不写,则意味着没有上界的约束
% x =
% 0
% 15.0000
% 3.0000
%
% fval =
% -78
%% 例题2
c = [0.04 0.15 0.1 0.125]';
A = [-0.03 -0.3 0 -0.15;
0.14 0 0 0.07];
b = [-32 42]';
Aeq = [0.05 0 0.2 0.1];
beq = 24;
lb = [0 0 0 0]';
[x fval] = linprog(c, A, b, Aeq, beq, lb)
% x =
% 0
% 106.6667
% 120.0000
% 0
%
% fval =
% 28
% 这个题可能有多个解,即有多个x可以使得目标函数的最小值为28(不同的Matlab版本可能得到的x的值不同,但最后的最小值一定是28)
% 例如我们更改一个限定条件:令x1要大于0(注意Matlab中线性规划的标准型要求的不等式约束的符号是小于等于0)
% x1 >0 等价于 -x1 < 0,那么给定 -x1 <= -0.1 (根据实际问题可以给一个略小于0的数-0.1),这样能将小于号转换为小于等于号,满足Matlab的标准型
c = [0.04 0.15 0.1 0.125]';
A = [-0.03 -0.3 0 -0.15;
0.14 0 0 0.07
-1 0 0 0];
b = [-32 42 -0.1]';
Aeq = [0.05 0 0.2 0.1];
beq = 24;
lb = [0 0 0 0]';
[x fval] = linprog(c, A, b, Aeq, beq, lb)
% x =
% 0.1000
% 106.6567
% 119.9750
% 0
%
% fval =
% 28.0000
%% 例题3
c = [-2 -3 5]';
A = [-2 5 -1;
1 3 1];
b = [-10 12];
Aeq = ones(1,3);
beq = 7;
lb = zeros(3,1);
[x fval] = linprog(c, A, b, Aeq, beq, lb)
fval = -fval % 注意这个fval要取负号(原来是求最大值,我们添加负号变成了最小值问题)
% x =
% 6.4286
% 0.5714
% 0
% fval =
% -14.5714
% fval =
% 14.5714
%% 多个解的情况
% 例如 : min z = x1 + x2 s.t. x1 + x2 >= 10
c = [1 1]';
A = [-1 -1];
b = -10;
[x fval] = linprog(c, A, b) % Aeq, beq, lb和ub我们都没写,意味着没有等式约束和上下界约束
% x有多个解时,Matlab会给我们返回其中的一个解
%% 不存在解的情况
% 例如 : min z = x1 + x2 s.t. x1 + x2 = 10 、 x1 + 2*x2 <= 8、 x1 >=0 ,x2 >=0
c = [1 1]';
A = [1 2];
b = 8;
Aeq = [1 1];
beq = 10;
lb = [0 0]';
[x fval] = linprog(c, A, b, Aeq, beq, lb) % Linprog stopped because no point satisfies the constraints.(没有任何一个点满足约束条件)
整数规划(以背包问题为例)

%% 钢管切割问题
%% (1)枚举法找出同一个原材料上所有的切割方法
for i = 0: 2 % 2.9m长的圆钢的数量
for j = 0: 3 % 2.1m长的圆钢的数量
for k = 0:6 % 1m长的圆钢的数量
if 2.9*i+2.1*j+1*k >= 6 && 2.9*i+2.1*j+1*k <= 6.9
disp([i, j, k])
end
end
end
end
% 有同学使用比较老的MATLAB版本,会出现浮点数计算的误差
% 只需要将上面的if这一行进行适当的放缩即可。
% if 2.9*i+2.1*j+1*k >= 6-0.0000001 && 2.9*i+2.1*j+1*k <= 6.9+0.0000001
% 有兴趣的同学可以百度下:浮点数计算误差
%% (2) 线性整数规划问题的求解
c = ones(7,1); % 目标函数的系数矩阵
intcon=[1:7]; % 整数变量的位置(一共7个决策变量,均为整数变量)
A = -[1 2 0 0 0 0 1;
0 0 3 2 1 0 1;
4 1 0 2 4 6 1]; % 线性不等式约束的系数矩阵
b = -[100 100 100]'; % 线性不等式约束的常数项向量
lb = zeros(7,1); % 约束变量的范围下限
[x,fval]=intlinprog(c,intcon,A,b,[],[],lb)
非线性规划(详见课件)


蒙特卡罗思想的运用


%% 使用蒙特卡罗的方法来找初始值(推荐)
clc,clear;
n=1000000; %生成的随机数组数
x1= unifrnd(0,2,n,1); % 生成在[0,2]之间均匀分布的随机数组成的n行1列的向量构成x1
x2 = sqrt(2-x1); % 根据非线性等式约束用x1计算出x2
x3 = sqrt((3-x2)/2); % 根据非线性等式约束用x2计算出x3
fmin=+inf; % 初始化函数f的最小值为正无穷(后续只要找到一个比它小的我们就对其更新)
for i=1:n
x = [x1(i), x2(i), x3(i)]; %构造x向量, 这里千万别写成了:x =[x1, x2, x3]
if (-x(1)^2+x(2)-x(3)^2<=0) & (x(1)+x(2)^2+x(3)^2-20<=0) % 判断是否满足条件
result =sum(x.*x) + 8 ; % 如果满足条件就计算函数值
if result < fmin % 如果这个函数值小于我们之前计算出来的最小值
fmin = result; % 那么就更新这个函数值为新的最小值
x0 = x; % 并且将此时的x1 x2 x3更新为初始值
end
end
end
disp('蒙特卡罗选取的初始值为:'); disp(x0)
lb = [0 0 0]; % 决策变量的下界
[x,fval] = fmincon(@fun2,x0,[],[],[],[],lb,[],@nonlfun2) % 注意 fun2.m文件和nonfun2.m文件都必须在当前文件夹目录下
选址问题

%% 选址问题
clear;clc
format long g %可以将Matlab的计算结果显示为一般的长数字格式(默认会保留四位小数,或使用科学计数法)
% % (1) 系数向量(原来线性规划问题的写法,我们只需要在此基础上改动一点就可以了)
% a=[1.25 8.75 0.5 5.75 3 7.25]; % 工地的横坐标
% b=[1.25 0.75 4.75 5 6.5 7.25]; % 工地的纵坐标
% x = [5 2]; % 料场的横坐标
% y = [1 7]; % 料场的纵坐标
% c = []; % 初始化用来保存工地和料场距离的向量 (这个向量就是我们的系数向量)
% for j =1:2
% for i = 1:6
% c = [c; sqrt( (a(i)-x(j))^2 + (b(i)-y(j))^2)]; % 每循环一次就在c的末尾插入新的元素
% end
% end
% (2) 不等式约束
A =zeros(2,16); % 注意这里要改成16
A(1,1:6) = 1;
A(2,7:12) = 1;
b = [20,20]';
% (3) 等式约束
Aeq = zeros(6,16); % 注意这里要改成16
for i = 1:6
Aeq(i,i) = 1; Aeq(i,i+6) = 1;
end
beq = [3 5 4 7 6 11]'; % 每个工地的日需求量
%(4)上下界
lb = zeros(16,1);
% lb = [zeros(12,1); -inf*ones(4,1)]; 两个新料场坐标的下界可以设为-inf
% 进行求解
% 注意哦,这里我们只尝试了这一个初始值,大家可以试试其他的初始值,有可能能够找到更好的解。
% 未来我会在遗传算法中再来看这个例题。
x0 = [3 5 0 7 0 1 0 0 4 0 6 10 5 1 2 7]; % 用第一问的结果作为初始值
[x,fval] = fmincon(@fun5,x0,A,b,Aeq,beq,lb) % 注意没有非线性约束,所以这里可以用[]替代,或者干脆不写
reshape(x(1:12),6,2) % 将x的前12个元素变为6行2列便于观察(reshape函数是按照列的顺序进行转换的,也就是第一列读完,读第二列,即x1对应x_1,1,x2对应x_2,1)
% 新坐标(5.74,4.99) (7.25,7.25)
% fval =
% 89.9231692432933
% 第一问的fval =
% 135.281541790676
135.281541790676 - 89.9231692432933 % 45.3583725473827