目录
ShardingJDBC实战
STANDARD标准分片策略
COMPLEX_INLINE复杂分片策略
CLASS_BASED自定义分片策略
HINT_INLINE强制分片策略
ShardingJDBC实战
上篇已经将需要用到的类、数据库表都准备好了,本篇主要介绍分片配置文件。
STANDARD标准分片策略
如果按照上篇文章所讲,使用INLINE分片算法是不能支持Between查找的,如果使用会报错。
@Test
public void queryCourseRange(){
//select * from course where cid between xxx and xxx
QueryWrapper<Course> wrapper = new QueryWrapper<>();
wrapper.between("cid",957742087095189504L,957742088538030080L);
List<Course> courses = courseMapper.selectList(wrapper);
courses.forEach(course -> System.out.println(course));
}

修改添加以下配置即可支持范围查找
# 允许在inline策略中使用范围查询。
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.props.allow-range-query-with-inline-sharding=true

虽然可以查询出数据,但是走的是全表扫描通过union联表查询。
以上案例使用STANDARD标准分片策略和INLINE分片算法来完成。
COMPLEX_INLINE复杂分片策略
之前只可以根据cid进行分片查询,现在我们通过以下这种分片策略可以实现多字段分片查询。
配置文件如下:
# 指定对应的库
spring.shardingsphere.datasource.names=m0,m1
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/coursedb?serverTimezone=UTC
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=123456
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/coursedb2?serverTimezone=UTC
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123456
# 雪花算法,生成Long类型主键。
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.props.worker.id=1
# 指定分布式主键生成策略
spring.shardingsphere.rules.sharding.tables.course.key-generate-strategy.column=cid
spring.shardingsphere.rules.sharding.tables.course.key-generate-strategy.key-generator-name=alg_snowflake
#-----------------------配置实际分片节点m0,m1
spring.shardingsphere.rules.sharding.tables.course.actual-data-nodes=m$->{0..1}.course_$->{1..2}
#MOD分库策略
spring.shardingsphere.rules.sharding.tables.course.database-strategy.standard.sharding-column=cid
spring.shardingsphere.rules.sharding.tables.course.database-strategy.standard.sharding-algorithm-name=course_db_alg
spring.shardingsphere.rules.sharding.sharding-algorithms.course_db_alg.type=MOD
spring.shardingsphere.rules.sharding.sharding-algorithms.course_db_alg.props.sharding-count=2
#给course表指定分表策略 complex-按多个分片键进行组合分片
spring.shardingsphere.rules.sharding.tables.course.table-strategy.complex.sharding-columns=cid,user_id
spring.shardingsphere.rules.sharding.tables.course.table-strategy.complex.sharding-algorithm-name=course_tbl_alg
# 分表策略-COMPLEX:按多个分片键组合分表
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.type=COMPLEX_INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.props.algorithm-expression=course_$->{(cid+user_id+1)%2+1}配置中说明,通过cid和user_id实现多字段分片,如果存储数据不是按照这种分片策略和算法,那么需要灵活调整,配置文件中的调整为course_$->{(cid+user_id+1)%2+1}
@Test
public void queryCourseComplexSimple(){
QueryWrapper<Course> wrapper = new QueryWrapper<Course>();
// wrapper.orderByDesc("user_id");
wrapper.in("cid",957742087095189504L,957742088538030080L);
// wrapper.between("cid",799020475735871489L,799020475802980353L);
wrapper.eq("user_id",1001L);
List<Course> course = courseMapper.selectList(wrapper);
//select * fro couse where cid in (xxx) and user_id between(8,3)
System.out.println(course);
}执行结果如下:

CLASS_BASED自定义分片策略
如果我们希望在对user_id进行范围查询时,能够提前判断一些不合理的查询条件。而具体的判断规则,比如在对user_id进行between范围查询时,要求查询的下限不能超过查询上限,并且查询的范围必须包括1001L这个值。如果不满足这样的规则,那么就希望这个SQL语句就不要去数据库执行了。因为明显是不可能有数据的,还非要去数据库查一次,明显是浪费性能。那么这种情况就可以通过自定义分片策略来实现相当于快速失败的逻辑。比如像以下这种查询我们就希望快速失败。
@Test
public void queryCourdeComplex(){
QueryWrapper<Course> wrapper = new QueryWrapper<Course>();
wrapper.in("cid",957742087095189504L,957742088538030080L);
wrapper.between("user_id",3L,8L);
// wrapper.between("user_id",3L,3L);
List<Course> course = courseMapper.selectList(wrapper);
//select * fro couse where cid in (xxx) and user_id between(8,3)
System.out.println(course);
}像上述中的user_id范围在3-8,在库中是明显不存在的,因为库中的user_id的值都为1001。
通过自定义来实现快速失败
配置文件
spring.shardingsphere.datasource.names=m0,m1
spring.shardingsphere.datasource.m0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m0.url=jdbc:mysql://localhost:3306/coursedb?serverTimezone=UTC
spring.shardingsphere.datasource.m0.username=root
spring.shardingsphere.datasource.m0.password=123456
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/coursedb2?serverTimezone=UTC
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123456
#------------------------分布式序列算法配置
# 雪花算法,生成Long类型主键。
#spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=COSID_SNOWFLAKE
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.props.worker.id=1
# 指定分布式主键生成策略
spring.shardingsphere.rules.sharding.tables.course.key-generate-strategy.column=cid
spring.shardingsphere.rules.sharding.tables.course.key-generate-strategy.key-generator-name=alg_snowflake
#-----------------------配置实际分片节点m0,m1
spring.shardingsphere.rules.sharding.tables.course.actual-data-nodes=m$->{0..1}.course_$->{1..2}
#MOD分库策略
spring.shardingsphere.rules.sharding.tables.course.database-strategy.standard.sharding-column=cid
spring.shardingsphere.rules.sharding.tables.course.database-strategy.standard.sharding-algorithm-name=course_db_alg
spring.shardingsphere.rules.sharding.sharding-algorithms.course_db_alg.type=MOD
spring.shardingsphere.rules.sharding.sharding-algorithms.course_db_alg.props.sharding-count=2
#给course表指定分表策略 complex-按多个分片键进行组合分片
spring.shardingsphere.rules.sharding.tables.course.table-strategy.complex.sharding-columns=cid,user_id
spring.shardingsphere.rules.sharding.tables.course.table-strategy.complex.sharding-algorithm-name=course_tbl_alg
# 使用CLASS_BASED分片算法- 不用配置SPI扩展文件
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.type=CLASS_BASED
# 指定策略 STANDARD|COMPLEX|HINT
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.props.strategy=COMPLEX
# 指定算法实现类。这个类必须是指定的策略对应的算法接口的实现类。 STANDARD-> StandardShardingAlgorithm;COMPLEX->ComplexKeysShardingAlgorithm;HINT -> HintShardingAlgorithm
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.props.algorithmClassName=com.shardingDemo.algorithm.MyComplexAlgorithm通过这种方式,需要自定义算法来实现,算法如下:
public class MyComplexAlgorithm implements ComplexKeysShardingAlgorithm<Long> {
private static final String SHARING_COLUMNS_KEY = "sharding-columns";
private Properties props;
//保留配置的分片键。在当前算法中其实是没有用的。
private Collection<String> shardingColumns;
@Override
public void init(Properties props) {
this.props = props;
this.shardingColumns = getShardingColumns(props);
}
/**
* 实现自定义分片算法
* @param availableTargetNames 在actual-nodes中配置了的所有数据分片
* @param shardingValue 组合分片键
* @return 目标分片
*/
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<Long> shardingValue) {
//select * from cid where cid in (xxx,xxx,xxx) and user_id between {lowerEndpoint} and {upperEndpoint};
Collection<Long> cidCol = shardingValue.getColumnNameAndShardingValuesMap().get("cid");
Range<Long> userIdRange = shardingValue.getColumnNameAndRangeValuesMap().get("user_id");
//拿到user_id的查询范围
Long lowerEndpoint = userIdRange.lowerEndpoint();
Long upperEndpoint = userIdRange.upperEndpoint();
//如果下限 》= 上限
if(lowerEndpoint >= upperEndpoint){
//抛出异常,终止去数据库查询的操作
throw new UnsupportedShardingOperationException("empty record query","course");
//如果查询范围明显不包含1001
}else if(upperEndpoint<1001L || lowerEndpoint>1001L){
//抛出异常,终止去数据库查询的操作
throw new UnsupportedShardingOperationException("error range query param","course");
// return result;
}else{
List<String> result = new ArrayList<>();
//user_id范围包含了1001后,就按照cid的奇偶分片
String logicTableName = shardingValue.getLogicTableName();//操作的逻辑表 course
for (Long cidVal : cidCol) {
String targetTable = logicTableName+"_"+(cidVal%2+1);
if(availableTargetNames.contains(targetTable)){
result.add(targetTable);
}
}
return result;
}
}
private Collection<String> getShardingColumns(final Properties props) {
String shardingColumns = props.getProperty(SHARING_COLUMNS_KEY, "");
return shardingColumns.isEmpty() ? Collections.emptyList() : Arrays.asList(shardingColumns.split(","));
}
public void setProps(Properties props) {
this.props = props;
}
@Override
public Properties getProps() {
return this.props;
}
@Override
public String getType(){
return "MYCOMPLEX";
}
}执行上述案例结果如下

HINT_INLINE强制分片策略
强制指定查询的表
配置文件如下:
# 之前配置都一样,只更改分表策略
#给course表指定分表策略 hint-与SQL无关的方式进行分片
spring.shardingsphere.rules.sharding.tables.course.table-strategy.hint.sharding-algorithm-name=course_tbl_alg
# 分表策略-HINT:用于SQL无关的方式分表,使用value关键字。
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.type=HINT_INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.props.algorithm-expression=course_$->{value}
@Test
public void queryCourseByHint(){
//强制只查course_1表
HintManager hintManager = HintManager.getInstance();
// 强制查course_1表
// hintManager.setDatabaseShardingValue(1L);
hintManager.addTableShardingValue("course","1");
//select * from course;
List<Course> courses = courseMapper.selectList(null);
courses.forEach(course -> System.out.println(course));
//线程安全,所有用完要注意关闭。
hintManager.close();
//hintManager关闭的主要作用是清除ThreadLocal,释放内存。HintManager实现了AutoCloseable接口,所以建议使用try-resource的方式,用完自动关闭。
//try(HintManager hintManager = HintManager.getInstance()){ xxxx }
}执行结果如下

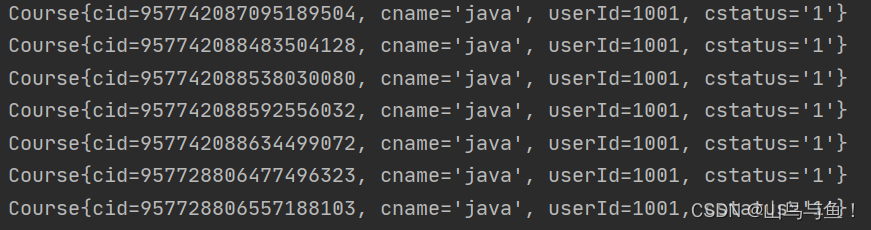
可以看到数据查询的两个数据库中course1表。