并行处理可以增加程序完成的任务数量,从而减少整体处理时间。这些有助于处理大规模问题。
参考链接:Parallel Processing in Python - GeeksforGeeks
1 并行处理介绍
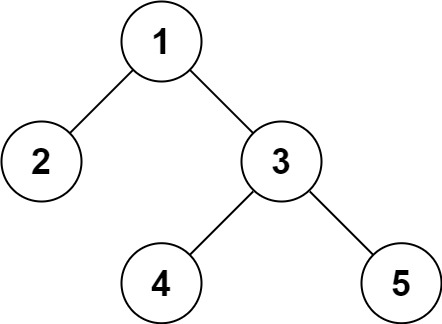
对于并行性,重要的是将问题划分为不依赖于其他子单元 (或较少依赖) 的子单元。子单元完全独立于其他子单元的问题称为embarrassingly parallel。
例如,数组上的元素操作。在这种情况下,操作需要了解其当前正在处理的特定元素。
在另一种情况下,被划分为子单元的问题必须共享一些数据以执行操作。由于通信成本的原因,这些导致了性能问题。
处理并行程序有两种主要方法:
共享内存
在共享存储器中,子单元可以通过相同的存储器空间相互通信。优点是不需要显式处理通信,因为这种方法足以从共享内存读取或写入。但是当多个进程访问并同时更改相同的内存位置时,问题就出现了。使用同步(synchronization)技术可以避免这种冲突。
分布式内存
在分布式内存中,每个进程是完全分开的,并具有自己的内存空间。在这种情况下,进程之间的通信是显式处理的。由于通信是通过网络接口进行的,因此与共享内存相比成本更高。
线程是实现与共享内存并行性的方法之一。线程是源自进程并共享内存的独立子任务。
由于全局解释器锁定 (GIL),线程不能用于提高Python中的性能。
GIL是一种机制,其中Python解释器设计一次只允许一条Python指令运行。、
GIL限制可以通过使用进程而不是线程来完全避免。使用进程几乎没有缺点,例如比共享内存效率更低的进程间通信,但是它更加灵活和明确。
2 并行处理的多处理
使用标准的多处理模块,我们可以通过创建子进程来有效地并行处理简单的任务。该模块提供了一个易于使用的界面,并包含一组实用程序来处理任务提交和同步。
通过子类化multiprocessing.Processing,您可以创建一个独立运行的进程。通过扩展 __init__ 方法,可以初始化资源,通过实现Process.ru n() 方法,可以为子进程编写代码。在下面的代码中,我们看到了如何创建一个打印分配的id的进程:
import multiprocessing
import time
class Process(multiprocessing.Process):
def __init__(self, id):
super(Process, self).__init__()
self.id = id
def run(self):
time.sleep(1)
print("I'm the process with id: {}".format(self.id))要生成进程,需要初始化我们的进程对象并调用process.start() 方法。这里Process.start() 将创建一个新的进程,并将调用Process.run() 方法。
if __name__ == '__main__':
p = Process(0)
p.start()p.start() 之后的代码将在process p的任务完成之前立即执行。要等待任务完成,可以使用Process.join()。
if __name__ == '__main__':
p = Process(0)
p.start()
p.join()
p = Process(1)
p.start()
p.join()OUTPUT: