一、上周工作
了解注意力机制,开始论文的初步阅读
二、本周计划
简单了解transform架构,继续研读论文U-MixFormer: UNet-like Transformer with Mix-Attention for Efficient Semantic Segmentation。
三、完成情况——论文研读
标题:U-MixFormer: UNet-like Transformer with Mix-Attention for Efficient Semantic Segmentation——U-MixFormer:具有混合注意力的类UNet Transformer用于有效的语义分割
作者:Seul-Ki Yeom, Julian von Klitzing
代码:https://github.com/julian-klitzing/u-mixformer
3.1 简介
| UNet | Transformer | |
|---|---|---|
| 优点 | 融合深层语义信息和高精度特征所含信息 | 提取全局信息 |
| 缺点 | 无法对距离较远的特征的上下文关系进行建模 | 缺少局部细节处的信息 |
- 论文背景:语义分割在Transformer架构的适应下取得了显著的进步。同时基于CNN的U-Net在高质量医学影像和遥感领域的重大进展。这两种双赢激发了作者将它们的优势结合起来,从而诞生了一种基于U-Net的视觉Transformer解码器,专为高效语义编码而设计。
- 论文方法:提出了一种新的Transformer解码器U-MixFormer,它建立在UNet结构的基础上,用于高效的语义分割。
- 将横向连接解释为查询特征而不是作为跳跃连接:作者提出的方法与以前的Transformer方法不同,它利用编码器和解码器阶段之间的横向连接作为注意力模块的特征查询,而不是传统的跳跃连接。
- 融入了一种独特的注意力机制:创新性地混合了来自不同编码器和解码器阶段的分层特征图,以形成Key和Value的统一表示,从而产生了独特的混合注意力模块。
- 方法的创新点:该模块确保了特征的逐渐传播,并在解码器阶段依次混合它们,有效地管理这些阶段之间的依赖关系,以捕获上下文并细化边界。他不仅能像传统的CNN一样强调层次特征表示,还能增强Transformers的全局上下文理解能力。据作者所知,这是首次将U-Net的固有优势与视觉Transformer的转换能力相结合,特别是通过一个新颖的注意力模块,有效地协调查询、键和值用于语义分割。
3.2 Transformer架构与U-Net
语义分割是计算机视觉的一个基本下游任务,其重要性在于他在实际场景中的广泛应用,例如自动驾驶和医学诊断。 全卷积网络(FCN)可以对图像进行像素级的分类,从而解决了语义级别的图像分割问题。尽管取得了这些进展,实现精确的像素级预测仍然是一个挑战,因为需要平衡全局和局部上下文。这一限制激发了人们对基于视觉Transformer的分割方法的兴趣。
Transformer模型是2017年Google公司在论文《Attention is All You Need》中提出的。自提出起该模型便在NLP和CV界大杀四方,多次达到SOTA效果。Trasnformer可以说是完全基于自注意力机制的一个深度学习模型,因为它适用于并行化计算。
那什么是Transformer呢?
可以简单理解为它是一个黑盒子,当在做文本翻译任务时,输入一个中文,经过这个黑盒子之后,输出来翻译过后的英文。
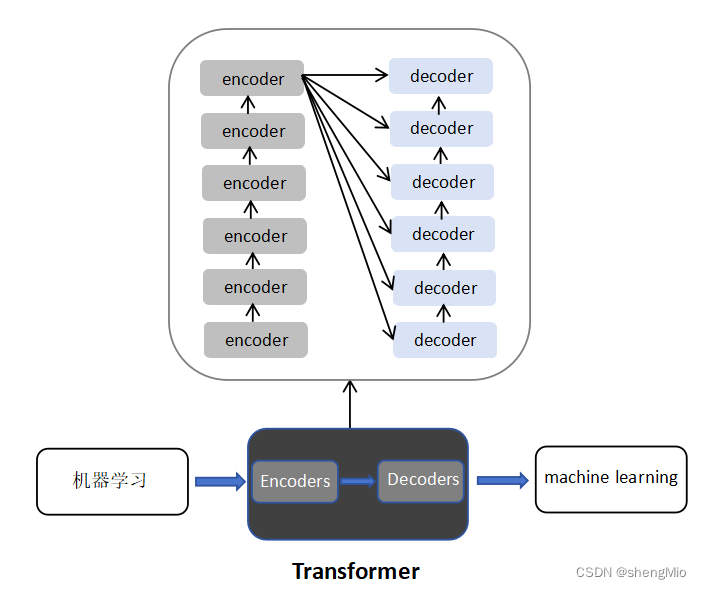

每一个小的编码器的输入是前一个小编码器的输出,一个encoder包含一个自注意力机制加上一个前馈神经网络。
而每一个小解码器的输入不光是它的前一个解码器的输出,还包括了整个编码部分的输出。
Transformer 的工作流程大体如下:
- 第一步:获取输入句子的每一个单词的表示向量x,x由单词的Embedding(Embedding就是从原始数据提取出来的Feature)和单词位置的Embedding相加得到。最终得到单词表示向量矩阵(每一行是一个单词的表示 x),用
表示,n是句子中单词个数,d是表示向量的维度

- 第二步:将得到的向量矩阵传入Encoder中,经过6个Encoder block后可以得到句子所有单词的编码信息矩阵 C,如下图。

- 第三步:将编码信息矩阵C传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1~ i 翻译下一个单词 i+1,如下图所示。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。即下图中 Decoder 接收了 Encoder 的编码矩阵 C,然后首先输入一个翻译开始符 "<Begin>",预测第一个单词 "I";然后输入翻译开始符 "<Begin>" 和单词 "I",预测单词 "have",以此类推。

Transformer最初是为了自然语言处理而设计的,但由于自注意力机制可以捕获输入序列中的全局关系,因此已经被应用于视觉任务并取得了显著的成功。受其成功的启发,Dosovitskiy等人也将其应用于视觉任务,从而产生了视觉Transformer(ViT),该方法将图像解释为嵌入式补丁的序列,并使用Transformer编码器来处理它们。这种方法在ImageNet上取得了显著的结果。他的主要目标是两个方面:优化编码器并创建能够有效地利用编码器阶段特征的解码器。
Transformer面临的问题:尽管基于Transformer的解码器在图像分割已经取得了进展,但这些方法通常依赖于在其注意力机制内的计算密集型的特征配置。此外,这些方法在解码器阶段之间,传播特征图方面存在效率问题。
传统上,U-Net架构以其对称的基于CNN的编码器-解码器结构为特征,一直是语义分割的首选,尤其是在医学领域。这种青睐源于U-Net有效捕捉和传播层次特征的特性。此外,它的横向连接促进了编码器和解码器之间多级特征的流动。作者假设,利用U-Net架构这些固有优势可以有效地细化特征,然后可以将其分层集成到Transformer解码器阶段。
3.3 主要贡献:
1. 基于U-Net的新型解码器结构
作者提出了一种新的强大的Transformer解码器架构,旨在实现高效的语义分割。利用U-Net在捕获和传播分层特征方面的优势,作者使用Transformer编码器的横向连接作为查询特征。这种方法确保了高级语义和低级结构的和谐融合。
2. 优化特征合成,增强上下文理解
为了提高效率,作者将多个编码器和解码器输出作为Key和Value的集成特征进行混合和更新,从而产生了我们提出的混合注意力机制。这种方法不仅为每个解码器阶段提供了丰富的特征表示,而且还增强了上下文理解。
3. 兼容不同的编码器
作者展示了将U-MixFormer与现有的流行的基于Transformer的编码器(如MiT和LVT)和基于CNN的编码器(如MSCAN)相结合的兼容性。
4. 基准测试经验
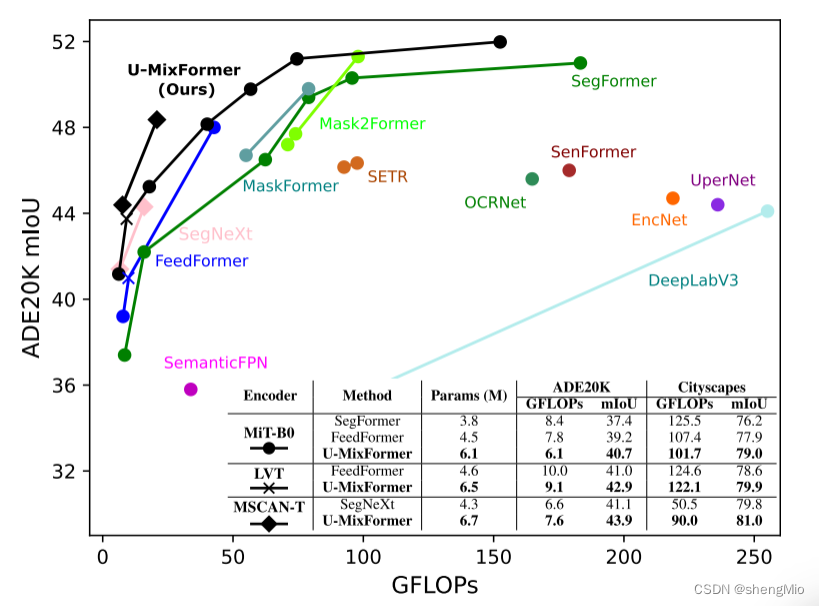
图1:ADE20K(单尺度推理)数据集的性能与计算效率。U-MixFormer在所有配置中都优于以前的方法。
如图1所示,U-MixFormer在语义分割方法方面,无论是计算成本还是准确性,都实现了新的最先进水平。它始终优于轻量级、中量级和甚至重量级编码器。这种优越性在ADE20K和Cityscapes数据集上得到了证明,特别是在具有挑战性的Cityscape-C数据集上的显著表现。
3.4 相关工作
Encoder Architectures编码器架构
- SETR是第一个将ViT作为语义分割的编码器架构。因为ViT只将输入图像划分为块,所以SETR生成单一尺度的编码器特征。
- PVT和Swin-Transformer在编码器阶段之间重复将特征映射分组成新的、不重叠的块,从而分层生成多尺度编码器特征。这两种方法还通过减少键和值的空间维度(PVT)或将具有移位窗口的补丁分组(Swin-Transformer)来提高自注意模块的效率。
- SegFormer重新使用了PVT的效率策略,同时去除位置编码并将特征图嵌入到重叠块中。
- 与前面提到的方法相反,SegNeXt和LVT的编码器采用了卷积注意力机制。
Decoder Architectures解码器架构
- DETR是第一种使用Transformer解码器进行语义分割的方法。随后的研究改编了DETR,但也依赖于对象可学习的查询,这在与多尺度编码器特征相结合时计算上是昂贵的。0
- 相比之下,FeedFormer直接利用编码器阶段的特征作为特征查询,从而提高了效率。FeedFormer解码了高级编码器特征(用作查询特征)和最低级编码器特征(用作键和值的特征),然而,这种设置单独处理了特征图,而没有在解码器阶段之间进行特征映射的递增传播,从而错过了进行更多增量细化以改进对象边界检测的机会。
- 此外,其他最近的基于MLP或CNN的解码器也缺乏解码器特征的增量传播。
UNet-like Transformer
在医学和遥感领域,人们已经尝试将UNet架构从基于CNN的框架转变为基于transformer的框架。
- TransUNet标志着首次成功将Transformer引入医学图像分割中,它使用ViT与他们的CNN编码器相结合。
- Cao等人(2023)介绍了Swin-UNet,这是第一个完全基于Transformer的UNet-like架构。该设计具有用于编码器和解码器的重型Swin Transformer阶段,保留了它们之间的横向连接作为跳跃连接。
- 与Swin-UNet相比,作者的方法采用了更轻量级的解码器阶段,使其适用于更广泛的下游任务。此外,我们将横向连接解释为查询特征而不是作为跳跃连接,并融入了一种独特的注意力机制。
3.5 方法 U-MixFormer
3.5.1 U-MixFormer架构概述
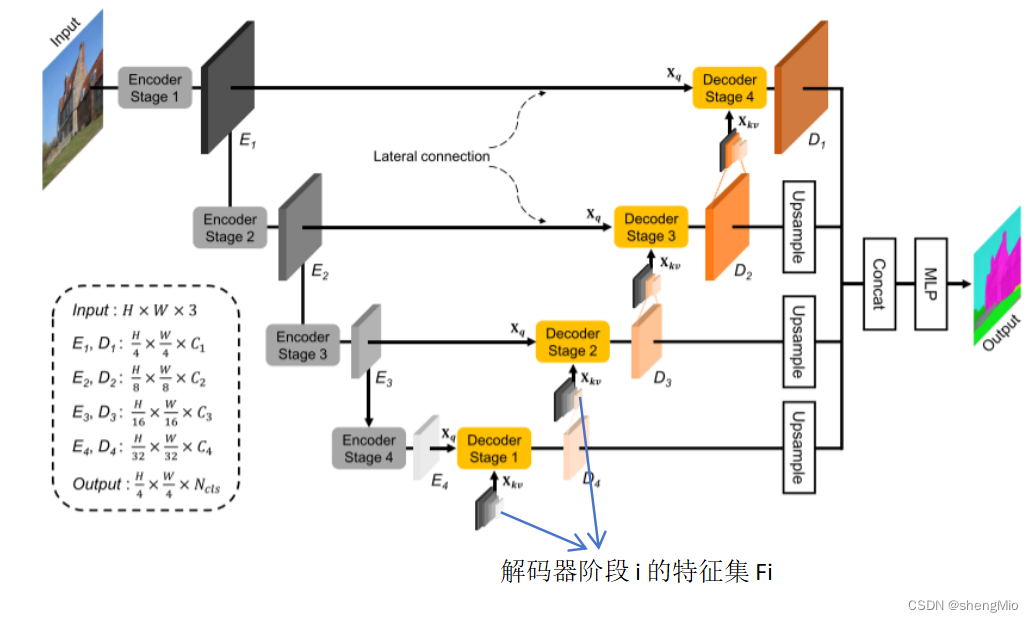
图2:U-MixFormer架构:编码器(左)从输入图像中提取多分辨率特征图,解码器(右)通过使用混合注意力机制将横向编码器输出作为,与上一解码器阶段的输出融合到
中。最后,来自所有解码器阶段的特征图被串联,并且MLP预测输出。
是类别的数量。
通常,我们的解码器由与编码器阶段一样多的阶段i ∈ {1, ...,N}组成。为了清晰起见,图2提供了架构的可视化概述,以四级(N=4)分层编码器为例,如MiT、LVT或MSCAN。
- 首先,编码器处理输入一个H×W×3(channel)的图像,我们首先将其分割成大小为 4×4 的小块,使用较小的patch有利于密集的预测任务。 然后将这些patch作为输入到分层的Transformer编码器中,四个阶段i∈{1,…, 4}产生分层的、多分辨率的特征Ei,其尺寸为
,即获得原始图像分辨率为{1/4,1/8,1/16,1/32} 的多级特征。。
- 第二,我们的解码器阶段 i 依次通过执行混合注意力,来顺序地生成细化特征
,其中查询特征
等于相应的横向编码器特征图。Key和Value特征
由编码器和解码器阶段的混合给出。值得注意的是,作者的解码器与编码器阶段输出的维度相同。
- 第三,使用双线性插值对解码器特征进行上采样,以匹配
的高度和宽度。
- 最后,通过MLP对连接的特征进行处理,以预测H/4×W/4×3的分割图。
3.5.2 Mix-Attention混合注意力
在Transformer模块中使用的是缩放点积注意力(Scaled Dot-Product Attention),计算查询Q、键K和值V。例如基于n个查询和m个键一值对计算注意力,其中查询和键的长度为d,值的长度为v,查询、键
和值
的缩放点积注意力是:
(1)
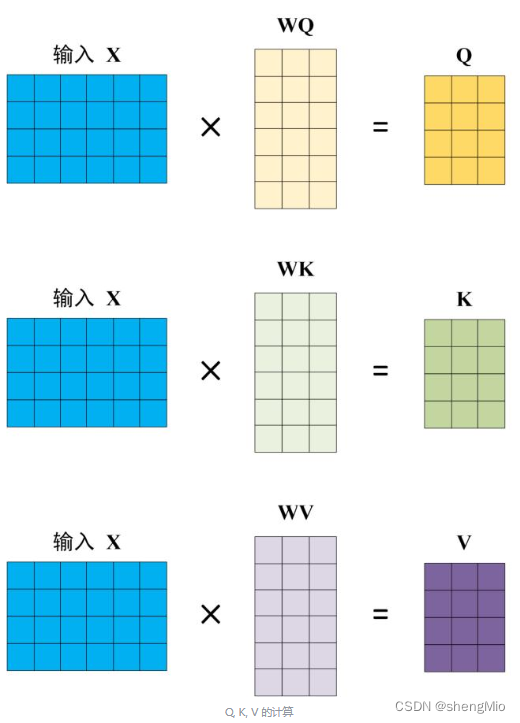
其中表示Q,K矩阵的列数,即向量维度。Q、K、V 是由选择的特征进行线性投影得到的,即 若输入用矩阵X进行表示,则可以使用线性变阵矩阵WQ,WK,WV计算得到Q,K,V。
Scaled Dot-Product Attention的计算方式如下:
- 计算矩阵Q和
每一行向量的内积,得到得分矩阵scores。
- 对得分矩阵scores进行缩放,即将其除以向量维度的平方根(np.sqrt(d_k)),这是为了防止内积过大。
- 对得分矩阵scores进行softmax计算,使用 Softmax 计算每一个单词对于其他单词的注意系数,公式中的 Softmax 是对矩阵的每一行进行Softmax。得到Attention权重矩阵attn。
- 计算Value矩阵V和Attention权重矩阵attn的乘积,得到加权后的Context矩阵。
核心代码:
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)通过这种方式,Scaled Dot-Product Attention可以计算出Query和Key之间的相似度,同时考虑了Value矩阵对最终结果的影响,进而实现了注意力机制的作用。
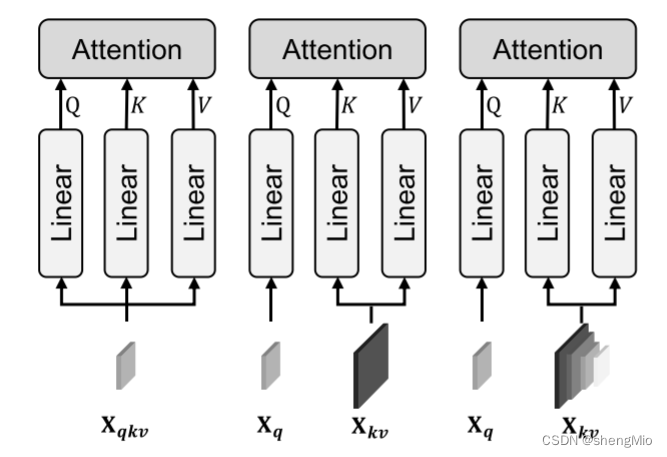
图3:三种不同注意力模块的比较:自注意力(左)、交叉注意力(中)和混合注意力(右)。
作者提出的方法其核心是选择要投影到Key和Value的特征,这就产生了作者提出的混合注意力机制。传统的自注意、交叉注意和作者所提出的混合注意力之间的比较 如图3所示。
- 在自注意中,用于生成查询、键和值的特征是相同的(
),它们都源自同一个来源,即相同的编码器/解码器阶段。
- 交叉注意力采用了两个不同的特征,
和
,每个特征都源自一个唯一的来源。
- 相比之下,作者的混合注意力机制利用了来自多个多尺度阶段的混合特征
对于解码器阶段i的特征集选择,作者采用分段形式进行如下形式化表示:
(2)
其中对于第一个解码器阶段(i=1),所有编码器特征都被选择。对于后续阶段,通过替换
中的横向编码器对应项来传播先前计算的解码器阶段输出。
为了对齐中特征的空间维度,作者采用了Wang等人(2021年)引入的空间降维过程:
(3)
其中表示特征集
的第j个元素,
是池化比率,它使特征图的大小与最小的特征图
对齐。操作AvgPool和Linear分别配置为AvgPool(kernelSize,步幅)(·)和Linear(
,
)(·),
其中 AvgPool强调对整体特征信息进行一层下采样,为分别以
和
为输入向量维数和输出向量维数的线性层。
将空间对齐的特征沿通道维度拼接在一起,形成键和值的混合特征:
(4)
3.5.2 Decoder Stage解码器阶段

图4:解码器阶段的结构,采用混合注意力机制,并将查询特征以及混合特征键值
作为输入。
作者通过舍弃自注意力模块(Shim et al. (2023)的建议)来改进传统的Transformer解码器模块。此外,作者用提出的混合注意力模块替换了交叉注意力模块。结果的结构如图4所示。
使用层归一化(LN)和前馈网络(FFN),的输出计算如下:
(5)
其中MixAtt表示作者提出的混合注意力。
3.5.3 Relationship to UNet Architectures 与UNet架构的关系
作者提出了U-MixFormer作为UNet类似架构。然而,作者想要强调他的方法与其他类似UNet的变种之间的主要区别。
- 因为作者将横向连接视为查询的特征,所以解码器特征图隐含地提高了空间分辨率,而无需在解码器阶段之间进行显式上采样。
- 作者的方法使用所有解码器阶段来预测分割图,而不仅仅是最后的阶段。
- 最后一个解码器阶段的特征图产生了一个分辨率为H/4,W/4的图像,而其他解码器阶段的特征图恢复了原始空间分辨率H,W。
3.6 Experiments实验
3.6.1 数据集
实验在两个流行的基准数据集上进行:ADE20K和Cityscapes。
- ADE20K是一个严格的场景解析基准测试,突出了150个复杂的语义概念,分为20210张用于训练的图像,2000张用于验证的图像。
- Cityscapes包含了来自城市图像的19个密集注释的对象类别,聚合了5,000张分辨率为2048×1024的高分辨率图像。它还引入了19,998张粗略注释的图像,用于增强模型训练。
3.6.2 Implementation Details实施细节
为了评估U-MixFormer在不同编码器复杂性下的适应性,作者采用了三种不同的编码器主干:Mix Transformer (MiT)、Light Vision Transformer (LVT)和多尺度卷积注意力编码器(MSCAN)。具体来说,作者使用了MiT-B0、LVT和MSCAN-T作为轻量级模型,使用MiT-B1/2和MSCAN-S作为中量级架构,而更重的变体包括MiT-B3/4/5。对于轻量级模型,最后阶段(MLP)的嵌入维度为128,其他模型的维度为768。补充材料中的A.1部分提供了关于训练和评估设置的额外信息。
3.6.3 Experimental Results实验结果
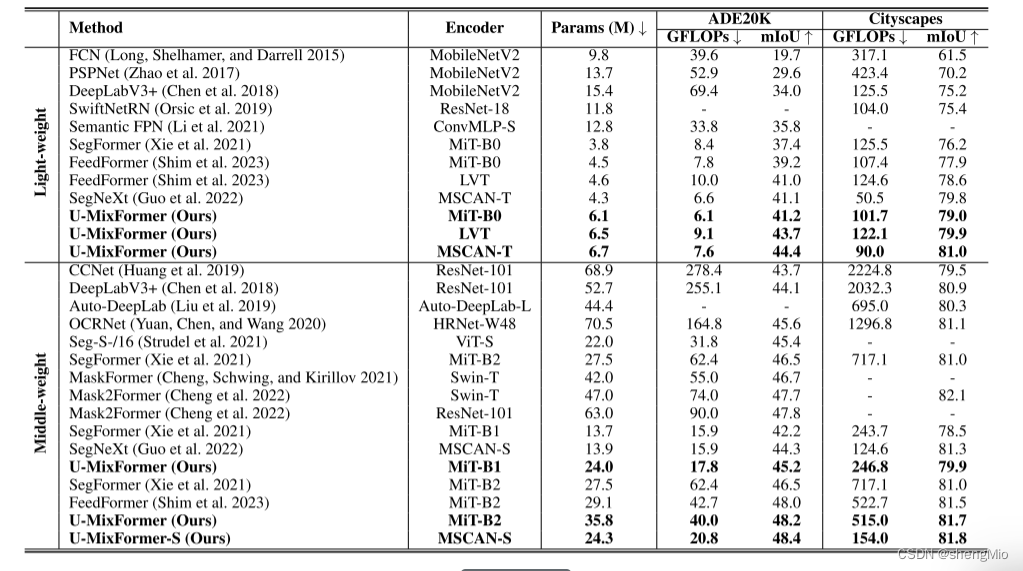
表1:在ADE20K和Cityscapes数据集上与现有语义分割方法的性能进行比较。
作者将其实验结果与现有的语义分割方法在ADE20K和Cityscapes数据集上进行了比较。表1展示了作者的结果,包括两个数据集的参数数量、浮点运算(FLOPs)和mIoU。如图1所示,作者在Cityscapes和ADE20K验证集上绘制了不同方法的性能计算曲线。
补充:
- 在语义分割的问题中,交并比就是该类的真实标签和预测值的交和并的比值。
- mIoU就是该数据集中的每一个类的交并比的平均。
- FLOPs 是floating point of operations的缩写,是浮点运算数,理解为计算量。可以用来衡量算法/模型复杂度。有相关计算FLOPs的三方库,一个是torchstat,一个是thop。
- GFLOPs:这其实是一个单位,1GLOPs=10亿次浮点运算。
轻型和中型模型
在表1的上面部分展示了轻量级模型的性能。如表所示,作者的轻量级U-MixFormer-B0在ADE20K上具有41.2%的mIoU,6.1M的参数和6.1 GFLOPs,在FLOPs和mIoU方面都优于其他所有轻量级对比模型,展示了性能-计算的更好权衡。
值得注意的是,与使用相同编码器(MiT-B0)的SegFormer和Feedformer相比,U-MixFormer在mIoU方面提高了3.8%和2.0%,同时将计算减少了27.3%和21.8%。
在Cityscapes上的性能差异更加明显,作者的模型仅使用101.7GFLOPs就实现了79.0%的mIoU,与SegFormer-B0和FeedFormer-B0相比,分别提高了2.8%和1.1%,并将计算减少了18.9%和5.3%。
当使用LVT时,作者的模型在数据集上的性能进一步得到提升,mIoU提高了2.7%和1.3%。
此外,作者的U-MixFormer与MSCAN-T(来自SegNeXt的最新编码器)也提供了出色的结果:使用6.7M参数,ADE20K和Cityscapes上的mIoU分别为44.4%和81.0%。
表1的后一部分将重点放在了中量级模型上,作者的方法在中量级模型上继续展示了优越的结果,保持了相对于竞争对手的优势。
重型模型
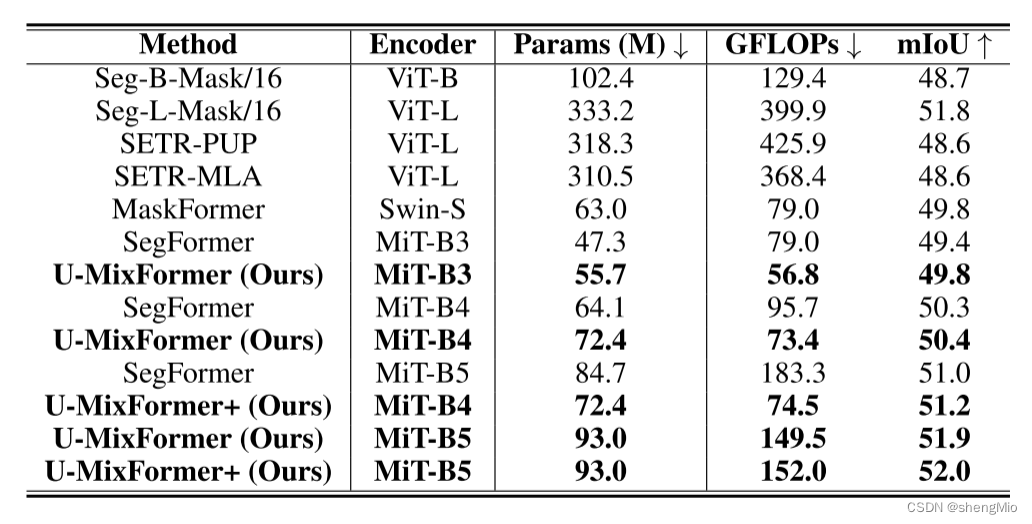
表2:ADE20K上重量级编码器的性能比较。
表2详细介绍了U-MixFormer在搭配相同的重量级编码器(特别是MiT-B3/4/5)时优于SegFormer的情况。
例如,在ADE20K上,U-MixFormer-B3获得了49.8%的mIoU,仅需56.8GFLOPs。这表明与SegFormer-B3相比,mIoU提高了0.4%,并将计算减少了28.1%。
此外,作者还推测,通过扩大模型大小(从MiT-B0更改为MiT-B5)可以允许从编码器阶段提取更丰富的上下文信息,可能有助于提高性能。
因此,作者训练并评估了重量级模型变体,包括MiT-B4和MiT-B5,并引入了一种从编码器的第三阶段中提取额外的键和值的方法,其中堆叠了大量注意力块。作者称这种增强的变体为U-MixFormer+。对于MiT-B4和MiT-B5配置,作者分别提取了5和6个Key和Value,以便于混合注意力。结果,当整合更多来自编码器的上下文数据时,作者观察到MiT-B4的性能提高了0.8%,而MiT-B5的性能提高了0.1%,且仅在计算需求上略有增加。
3.6.4 Qualitative Results定性结果

图5:ADE20K和Cityscapes数据集的定性分析:我们选择SegFormer和FeedFormer作为基准,因为它们共享相同的编码器。我们的观察结果表明,U-MixFormer优于这些方法,特别是在分割复杂物体细节方面,如湖泊和地面之间的边界以及人体对象之间的边界。
如图5所示,U-MixFormer,FeedFormer和SegFormer在ADE20K和Cityscapes数据集上使用相同的编码器,并呈现了各自的定性结果。与其它方法相比,U-MixFormer在更清楚地分割复杂的物体细节和具有挑战性的区域方面表现出色。它可以显著识别出语义相关的区域和物体细节,这正是它从多阶段编码器中学习上下文特征表示以实现高效分割的能力。
3.6.5 Ablation Studies消融研究
消融实验(ablation study)是一种机器学习实验方法,用于分析模型中各个组成部分(如网络层、正则化项、数据处理方法等)对模型性能的影响程度。 在消融实验中,可以将模型中的某些组成部分去掉或者改变,然后重新训练模型并比较其性能指标,以确定这些组成部分对模型性能的贡献。
混合注意力和类U-Net架构的有效性
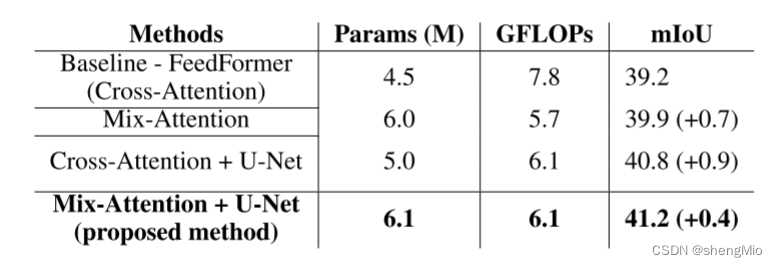
表3:显示混合注意力和类U-Net架构有效性的消融研究。
在表3中,作者对不同的设计选择进行了系统性的评估。为了保证比较的公平性,所有模型都在一个统一的随机种子下进行训练和评估。我们将基于传统交叉注意力的FeedFormer作为我们的基线。通过混合注意力模块将来自多个编码器阶段的上下文信息集成,可以在mIoU方面提高0.7%,同时降低计算成本。在没有混合注意力的情况下适配U-Net Transformer解码器可将mIoU提高0.9%,FLOPs略有增加(+0.4)。值得注意的是,通过将混合注意力模块应用于U-Net架构,模型的性能增加到41.2%,这意味着在U-Net类似配置中,与传统交叉注意力相比,性能有了显著的提高。
Robustness in Image Corruption图像损坏中的鲁棒性
在自动驾驶和智能交通系统这样的关键领域中,图像分割的鲁棒性至关重要。在这方面,作者对U-MixFormer的鲁棒性进行了评估,以应对腐蚀和干扰。作者遵循 (Kamann and Rother 2020)中的方法,引入了Cityscapes-C,这是Cityscapes验证的增强版本,它涵盖了16种算法损坏,包括噪声、模糊、天气和数字类别。作者将U-MixFormer与共享相同编码器的SegFormer和FeedFormer进行比较。

表4:针对三种语义分割方法计算了Cityscapes验证集的干净变体和损坏变体的平均mIoU值,所有这些方法都使用相同的编码器(MiT)。mIoU在所有适用的严重程度级别上取平均值,除了噪声损坏类别,该类别考虑了五个严重程度级别中的前三个级别。
表4中的结果突显了U-MixFormer的优越鲁棒性。值得注意的是,它在与所有损坏类别显著改进,在消除散粒噪声方面分别达到20.0%和33.3%,在雪地条件下分别达到21.8%和19.2%。这些结果表明了U-MixFormer的鲁棒性,使其成为在安全性和可靠性至关重要的应用的理想选择。
Effectiveness of Mix-Attention混合注意力的有效性

图6:MLP、交叉注意力和ADE20K上提出的混合注意力方法之间的定性比较。我们可以清楚地看到对象的边界片段(上排:墙/床(蓝色)和斜坡/箱子/床(红色),下排:建筑/背景(蓝色),湖/地板(红色)),这可以提高语义分割性能。
为了验证基于U-Net的混合注意力模块的有效性,作者进行了一个微观上的消融实验,通过与常见研究(MLP和交叉注意力)相比,我们通过从相同位置提取特征图进行了一个微观上的消融研究。如图6所示。作者观察到其方法有了明显的改进。具体来说,作者的特征图更加精确地描绘了物体细节,并清晰地划定了物体之间的边界。这一观察表明,所提出的方法可以在局部和全局上显著分割和捕捉可区分的视觉细节。
Effectiveness of Decoding head with the same encoder同一编码器的解码头的有效性
为了将作者的方法与现有技术进行比较,作者的目标是使用一致的编码器,特别是采用MiT和MSCAN。这些多阶段设计的编码器因其效率和创新设计而受到广泛关注。正如SegNeXt中的结果所示,MiT和MSCAN都实现了更高的平均交并集(mIoU)分数和减少了计算开销,其更少的FLOPs表明了这一点。这一分析对于突出作者方法相对于这些已建立的编码器相比的优势至关重要。
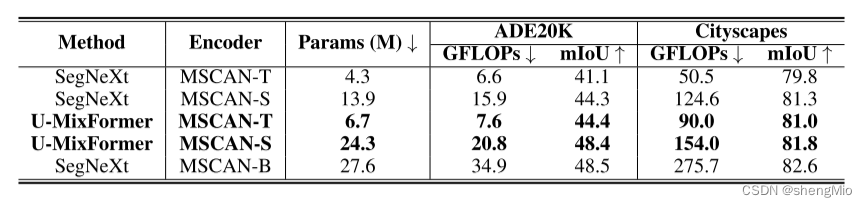
表5:ADE20K和Cityscapes上MSCAN编码器的性能比较。
如表1和2所示,作者的U-MixFormer在从B0到B5的各种模型复杂性中,在mIoU和FLOP中始终表现出色。表5进一步突显了U-MixFormer的优势,与较重的SegNeXt-s相比,ADE20K的mIoU增加了3.3%。此外,MSCAN-S与更密集的MSCAN编码器(SegNeXt-B)的性能非常接近。这些发现表明U-MixFormer是语义分割中一个有前途的解码器架构。
Limitation and Future Works限制和未来工作
尽管在计算成本和mIoU方面,作者的U-MixFormer具有竞争力的结果,但需要解决一些局限性。作者在mmsegmentation基准设置下,使用单个A100 GPU测试了单个2048×1024图像的推理时间。
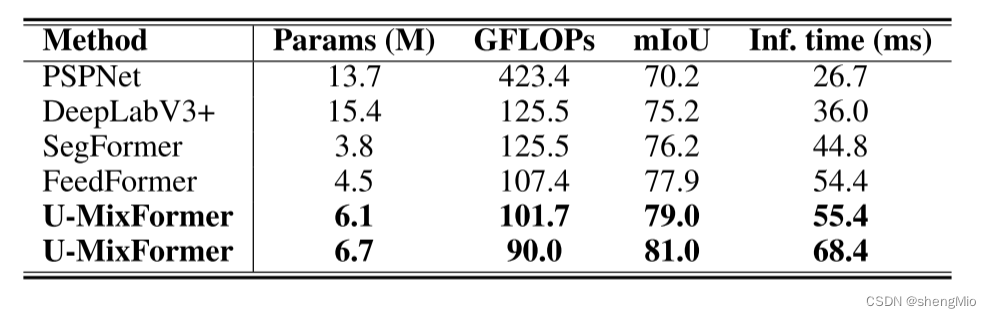
表6:推理时间与轻量级模型的比较
如表6所示,与其他轻量级模型相比,U-MixFormer的推理时间较慢。延迟可以归因于U-Net固有的结构,需要通过横向(或残差)连接来保存信息。虽然这些连接对于捕获分层特征至关重要,但在推理阶段会引入开销。
为了解决这一限制,作者计划在未来的工作中探索模型压缩技术,如剪枝和知识提取。预计这些方法可能会提高推理速度,同时保留UMixFormer的准确性优势。
3.7 Conclusion结论
在本文中,作者提出了U-MixFormer,它基于U-Net结构设计用于语义分割。U-MixFormer从最具上下文的编码器特征图开始,逐步纳入更细微的细节,这依赖于U-Net捕获和传播层次特征的能力。作者的混合注意力设计强调了合并特征图的组成部分,并将它们与越来越细粒度的横向编码器特征对齐。这确保了高层次上下文信息与复杂的低级细节的和谐融合,这对于精确分割至关重要。作者在流行的基准数据集上展示了U-MixFormer在不同编码器上的优越性。
四、总结
本周效率不算高,只完成了论文的研读。这篇论文的代码复杂且设计到其他框架,网络架构并未找到。理论知识学习了,但是没有找到相关合适的代码去进行复现与学习。
五、下一周计划
继续Transfomer,跑Transfomer代码并进行调试