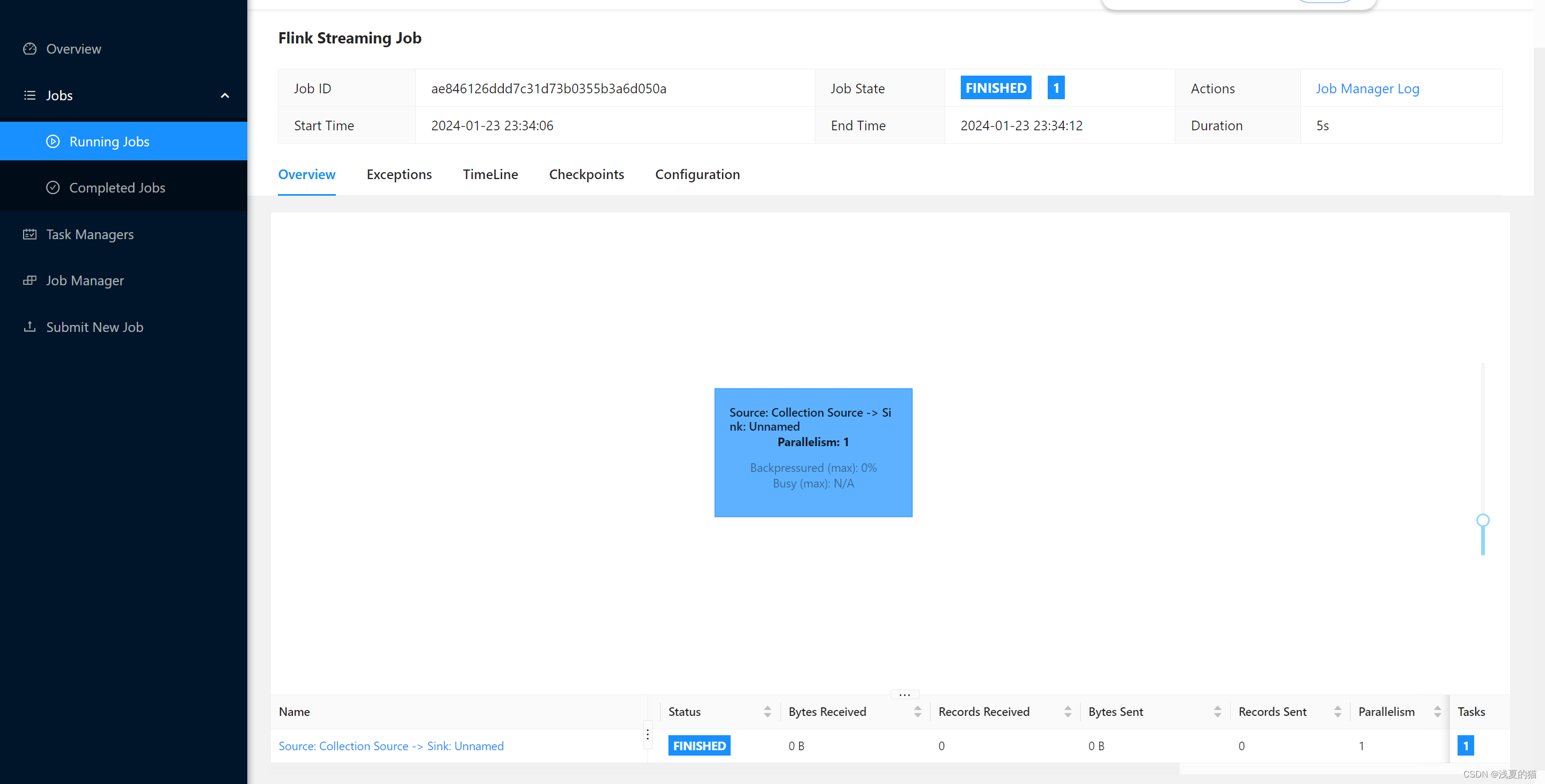
文章目录
- 1.3.1 5种基本数据类型
- 1.3.1.1 总结篇
- 1.3.1.2 底层源码引入篇
- 1.3.1.2.1 redis是字典数据库KV键值对到底是什么
- 1.3.1.2.2 数据类型视角
- 1.3.1.2.3 数据模型解析(重点)
- 1.3.1.2.4 redisObjec
- 1.3.1.2.5 SDS
- 1.3.1.3 String
- 1.3.1.3.1 底层分析
- 1.3.1.3.1.1 数据结构
- 1.3.1.3.1.2 源码分析
- 1.3.1.3.1.3 INT 编码格式(set k1 123)
- 1.3.1.3.1.4 EMBSTR编码格式(set k1 abc)
- 1.3.1.3.1.5 raw 编码格式(set k1 大于44长度的一个字符串)
- 1.3.1.4 Hash
- 1.3.1.4.1 底层分析
- 1.3.1.4.1.1 验证编码
- 1.3.1.4.1.2 源码分析
- 1.3.1.4.1.3 Ziplist
- 1.3.1.4.1.4 hashtable
- 1.3.1.5 List
- 1.3.1.5.1 底层分析
- 1.3.1.5.1.1 验证编码
- 1.3.1.5.1.2 数据结构
- 1.3.1.5.1.3 源码分析
- 1.3.1.6 Set
- 1.3.1.6.1 底层分析
- 1.3.1.6.1.1 编码验证
- 1.3.1.6.1.2 数据结构
- 1.3.1.7 Zset
- 1.3.1.7.1 底层分析
- 1.3.1.7.1.1 编码验证
- 1.3.1.7.1.2 数据结构(skiplist)
- 1.3.1.7.1.3 源码分析
- 1.3.2 3种新类型bitmap/hyperloglgo/GEO
- 1.3.2.1 出现背景分析及统计类型
- 1.3.2.2 Bitmap
- 1.3.2.2.1 数据结构
- 1.3.2.2.2 编码验证
- 1.3.2.3 Hyperloglog
- 1.3.2.3.1 计数算法
- 1.3.2.3.2 HyPerLogLog如何做的?如何演化出来的?
- 1.3.2.3.3 为什么redis集群的最大槽数是16384个?
- 1.3.2.3.4 天猫网站首页亿级UV的Redis统计方案
- 1.3.2.4 GEO
- 1.3.2.4.1 案例:美团地图位置附近的酒店推送
官网命令大全: http://doc.redisfans.com/,命令不区分大小写,而key是区分大小写的,help @类型名词

1.3.1 5种基本数据类型
程序员写代码时脑子底层思维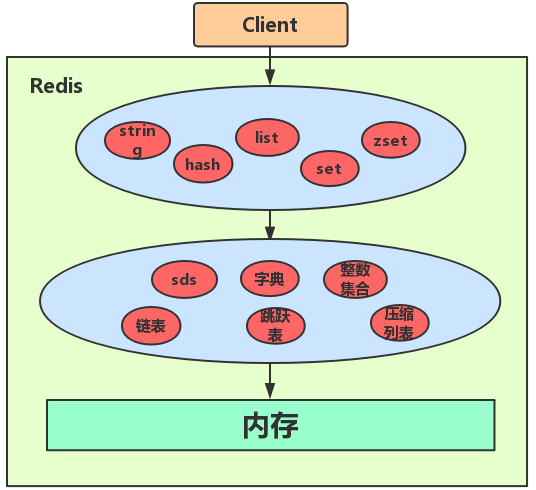
总结:
1.3.1.1 总结篇
不同数据类型对应的底层数据结构:
1. 字符串
int:8个字节的长整型。
embstr:小于等于44个字节的字符串。
raw:大于44个字节的字符串。
Redis会根据当前值的类型和长度决定使用哪种内部编码实现。
2. 哈希(ziplist(压缩列表)+hashtable(哈希表))
ziplist(压缩列表):元素个数<512,值长度<64字节,否则,hashtable(哈希表)
ziplist内存连续紧凑,时间换空间,适合内存中数据少的情况
hashtable:读写时间复杂度为O(1)
3.列表(ziplist(压缩列表)+linkedlist(链表))
Ziplist:元素个数<512,值长度<64字节,否则,inkedlist(链表)
4. 集合(intset(整数集合)+hashtable(哈希表))
Intset:元素个数小于512,否则,hashtable
Redis会选用intset来作为集合的内部实现,从而减少内存的使用。
5. 有序集合(ziplist(压缩列表)+skiplist(跳跃表))
ziplist:元素个数<128,元素值长度<64字节,否则,skiplist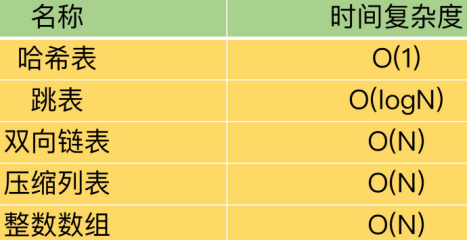
1.3.1.2 底层源码引入篇
redis源码在哪里:redis-6.0.8\redis-6.0.8\src
1.3.1.2.1 redis是字典数据库KV键值对到底是什么
redis是key-value存储系统,其中key类型一般为字符串(SDS),value类型则为redis对象(redisObject)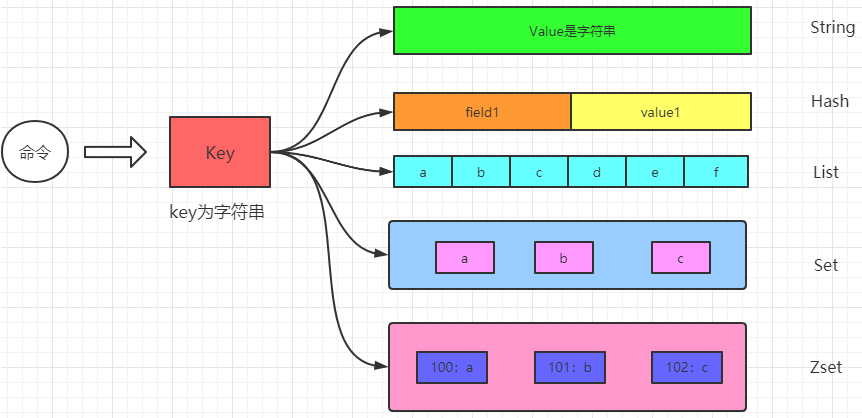
字典、KV是什么:每个键值对都会有一个dictEntry。类比java Map中的Entry
1.3.1.2.2 数据类型视角

上帝视角:
https://redissrc.readthedocs.io/en/latest/datastruct/dict.html
https://redissrc.readthedocs.io/en/latest/index.html
1.3.1.2.3 数据模型解析(重点)
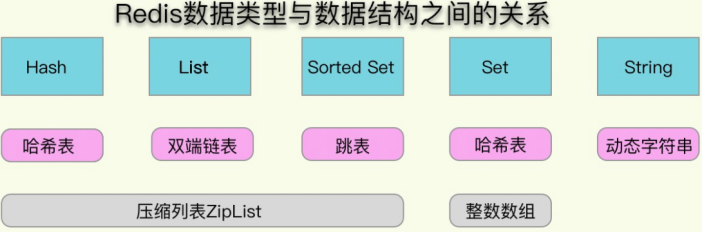
redisObject +Redis数据类型+Redis 所有编码方式(底层实现)三者之间的关系
简单地说,redisObjec就是string、hash、list、set、zset的父类,可以在函数间传递时隐藏具体的类型信息,所以作者抽象了redisObjec结构来到达同样的目的。
1.3.1.2.4 redisObjec
Redis定义了redisObjec结构体来表示string、hash、list、set、zset等数据类型。
Redis 中每个对象都是一个redisObject结构
redisObject结构作用?
其实无论是设计redisObject,还是对存储字符设计这么多的SDS,都是为了根据存储的不同内容(type和encoding字段)选择不同的存储方式,这样可以实现尽量地节省内存空间和提升查询速度的目的。
- 4位的type表示具体的数据类型
- 4位的encoding表示该类型的物理编码方式见下表,同一种数据类型可能有不同的编码方式。(比如String就提供了3种:int embstr raw)
- lru字段表示当内存超限时采用LRU算法清除内存中的对象。
- refcount表示对象的引用计数。
- ptr指针指向真正的底层数据结构的指针。
编码类型:
Set age 17后redisObjec:

1.3.1.2.5 SDS
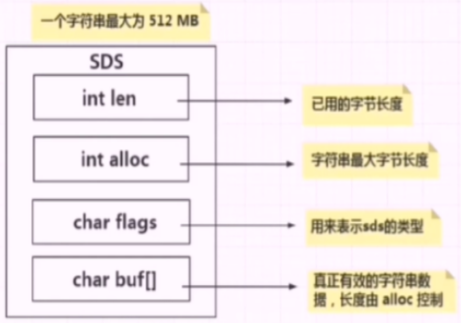

Redis中字符串的实现,SDS有多种结构(sds.h)用于存储不同的长度的字符串:
sdshdr5(2^5=32byte)、sdshdr8(2 ^ 8=256byte)、sdshdr16(2 ^ 16=65536byte=64KB)
sdshdr32(2 ^ 32byte=4GB)、sdshdr64(2的64次方byte=17179869184G)。
**len **表示SDS的长度,获取字符串长度O(1),不像C那样需要遍历一遍字符串。
**alloc **用于计算字符串已经分配的未使用的空间,作用:预分配空间的算法,而不用去考虑内存分配的问题。
buf 表示字符串数组,真存数据的。
Redis为什么重新设计一个 SDS 数据结构?
C语言没有Java里面的String类型,redis自己构建了一种名为简单动态字符串 SDS(simple dynamic string)的抽象类型,并将 SDS 作为 Redis 的默认字符串
1.3.1.3 String
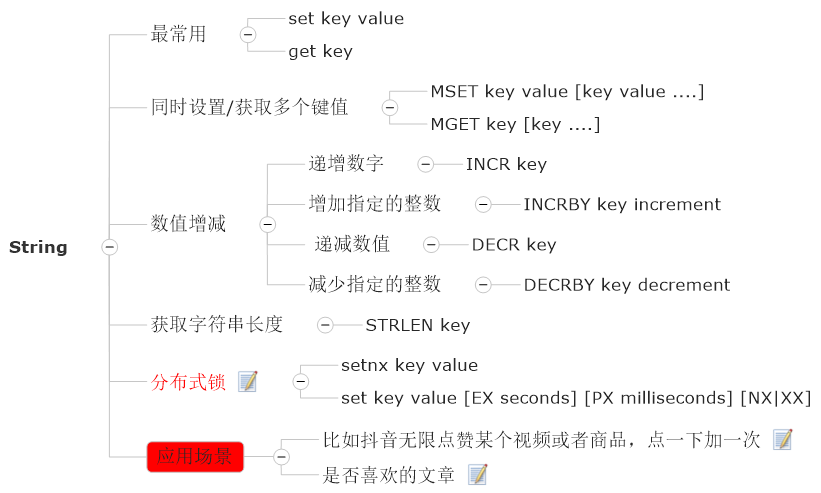
1.3.1.3.1 底层分析
1.3.1.3.1.1 数据结构
详见SDS,总结如下:
1.3.1.3.1.2 源码分析
1.3.1.3.1.3 INT 编码格式(set k1 123)
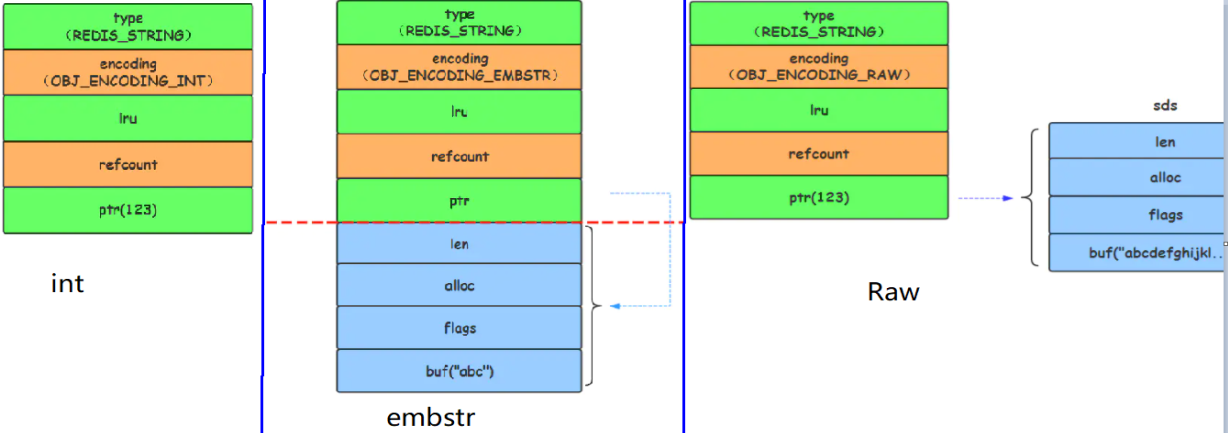
当字符串键值的内容可以用一个64位有符号整形来表示时,Redis会将键值转化为long型来进行存储,此时即对应 OBJ_ENCODING_INT 编码类型。内部的内存结构表示如下: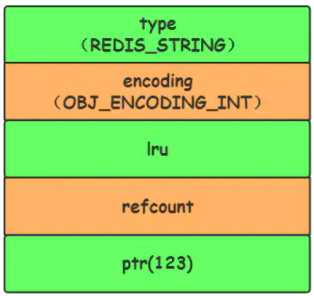
Redis启动时会预先建立10000个分别存储09999的redisObject变量作为共享对象,这就意味着如果set字符串的键值在010000之间的话,则可以直接指向共享对象而不需要再建立新对象,此时键值不占空间!
set k1 123、set k2 123使用同一块空间
redis源代码:object.c,通过源码说明确实有10000的预分配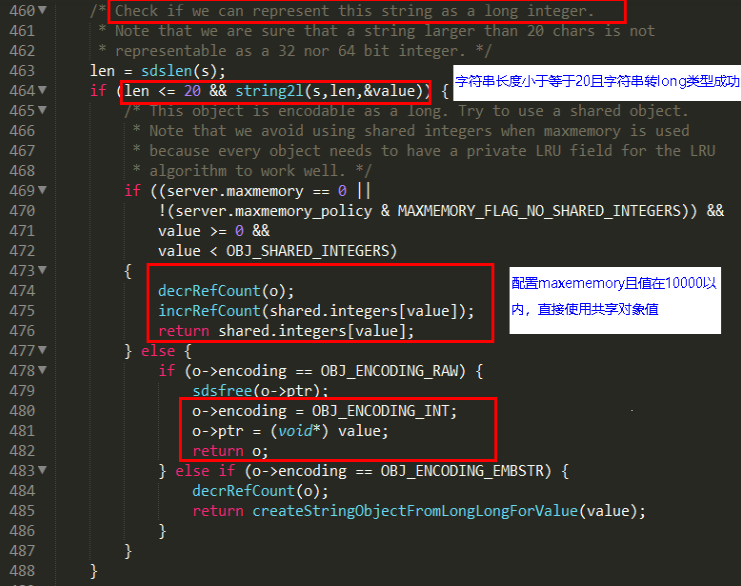

1.3.1.3.1.4 EMBSTR编码格式(set k1 abc)
redis源代码:object.c
对于长度小于 44的字符串,Redis 对键值采用OBJ_ENCODING_EMBSTR 方式,EMBSTR 顾名思义即:embedded string,表示嵌入式的String。从内存结构上来讲 即字符串 sds结构体与其对应的 redisObject 对象分配在同一块连续的内存空间,字符串sds嵌入在redisObject对象之中一样。
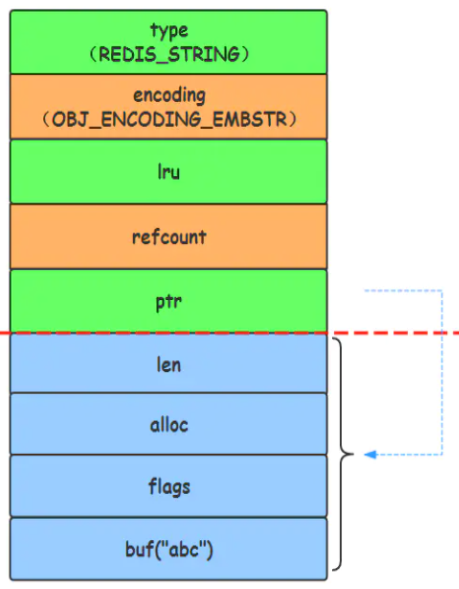
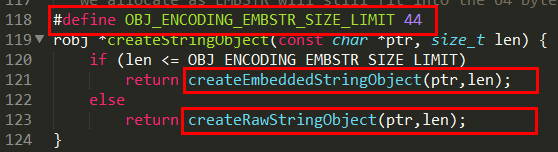
1.3.1.3.1.5 raw 编码格式(set k1 大于44长度的一个字符串)

当字符串的键值为长度大于44的超长字符串时,Redis 则会将键值的内部编码方式改为OBJ_ENCODING_RAW格式,这与OBJ_ENCODING_EMBSTR编码方式的不同之处在于,此时动态字符串sds的内存与其依赖的redisObject的内存不再连续了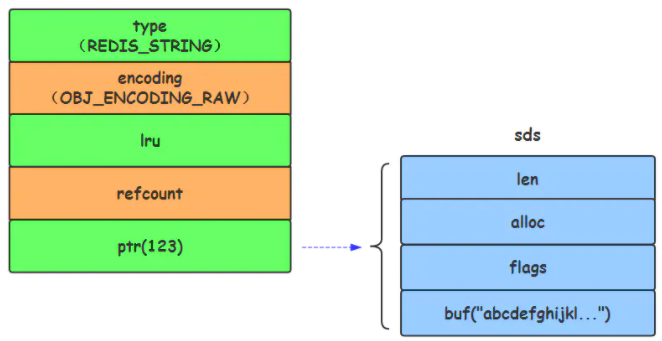
1.3.1.4 Hash

1.3.1.4.1 底层分析
1.3.1.4.1.1 验证编码
hash的两种编码格式:ziplist、hashtable
hash-max-ziplist-entries:使用压缩列表保存时哈希集合中的最大元素个数。
hash-max-ziplist-value:使用压缩列表保存时哈希集合中单个元素的最大长度。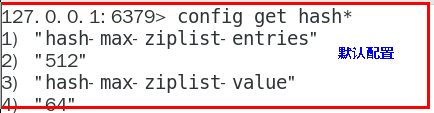
采用哪种编码?
Hash类型键的字段个数小于hash-max-ziplist-entries,并且每个字段名和字段值的长度小于hash-max-ziplist-value时,Redis才会使用OBJ_ENCODING_ZIPLIST来存储该键,前述条件任意一个不满足则会转换为OBJ_ENCODING_HT的编码方式
验证:分别先将这两个值设置为3和8
验证上述选择哪种编码的几种情况: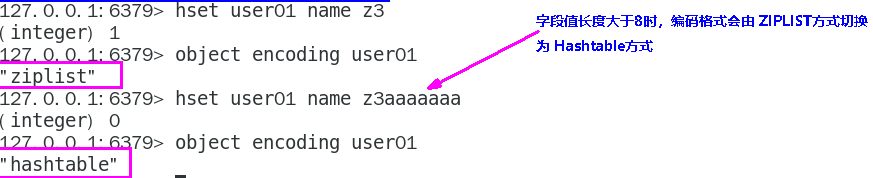
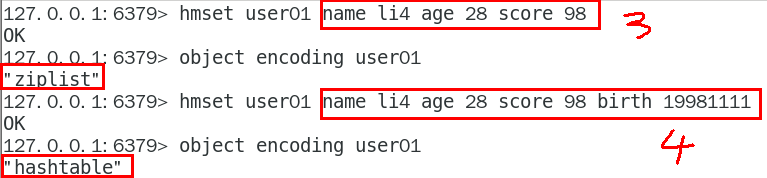
1.3.1.4.1.2 源码分析
编码变化流程:
1.3.1.4.1.3 Ziplist
ziplist.c权威注释: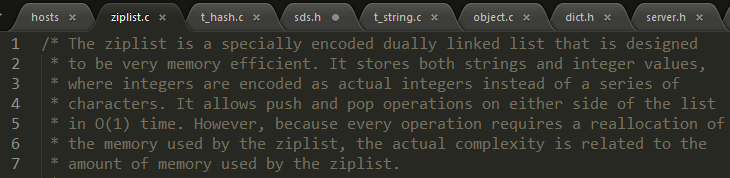
Ziplist 压缩列表是一种紧凑编码格式,时间换空间的思想,用于字段个数少,且字段值也较小的场景。压缩列表内存利用率极高的原因与其连续内存的特性是分不开的。
想想我们的学过的一种GC垃圾回收机制:标记–压缩算法,当一个hash对象只包含少量键值对且每个键值对的键和值要么就是小整数要么就是长度比较短的字符串,那么它用ziplist作为底层实现
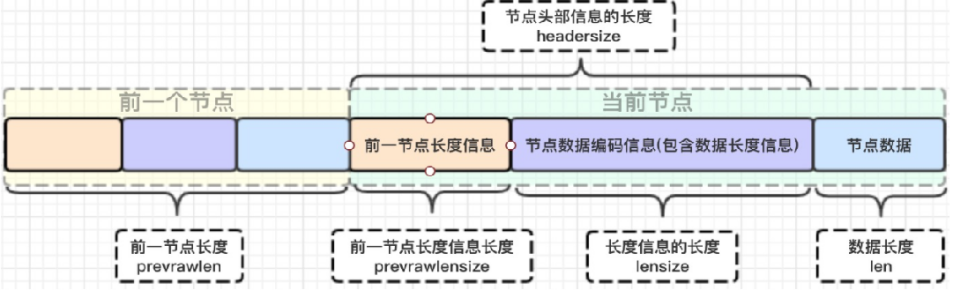
1.3.1.4.1.3.1 压缩列表节点的构成
组成分为三部分:header+entry集合+end,其中header由zlbytes+zltail+zllen组成
zlbytes 4字节,记录整个压缩列表占用的内存字节数。
zltail 4字节,记录压缩列表表尾节点的位置。
zllen 2字节,记录压缩列表节点个数。
zlentry 列表节点,长度不定,由内容决定。
zlend 1字节,0xFF 标记压缩的结束。该字节为255(1111 1111)
压缩列表是 Redis 为节约空间而实现的一系列特殊编码的连续内存块组成的顺序型数据结构,本质上是字节数组
源代码:ziplist.c
ziplist是一个经过特殊编码的双向链表,它不存储指向上一个链表节点和指向下一个链表节点的指针,而是存储上一个节点长度和当前节点长度,通过牺牲部分读写性能,来换取高效的内存空间利用率,节约内存,是一种时间换空间的思想。只用在字段个数少,字段值小的场景里面
zlentry实体结构解析(链表中元素结构)

压缩列表的遍历:(偏移)
通过指向表尾节点的位置指针p1, 减去节点的previous_entry_length,得到前一个节点起始地址的指针。如此循环,从表尾遍历到表头节点。
ziplist存取情况: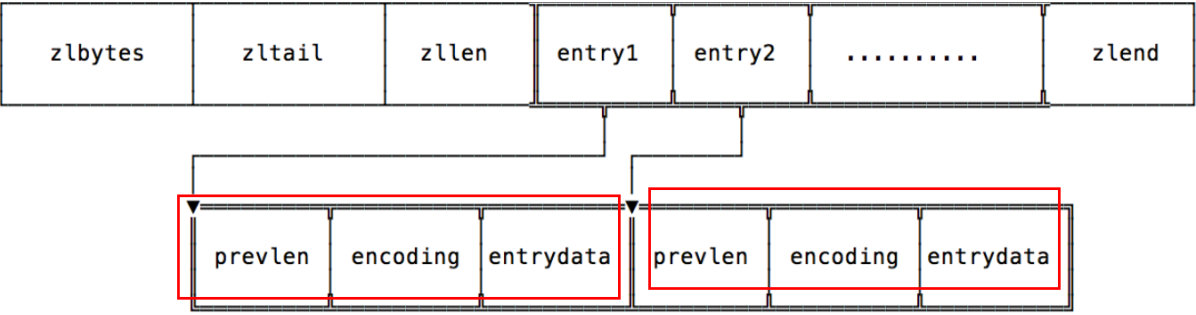

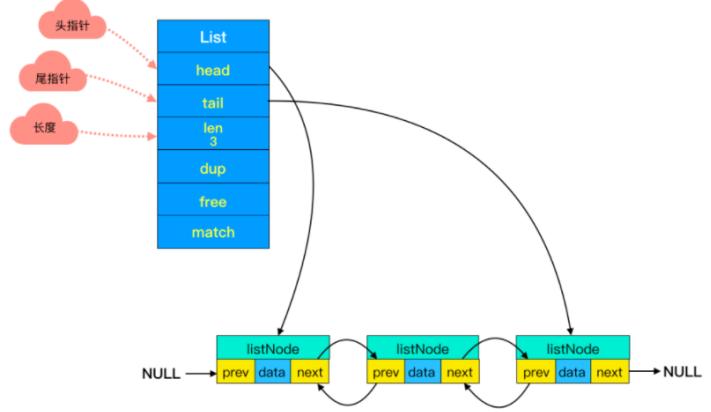
1.3.1.4.1.3.2 明明有链表了,为什么出来一个压缩链表?
1.3.1.4.1.4 hashtable
在 Redis 中,hashtable 被称为字典(dictionary),它是一个数组+链表的结构
t_hash.c: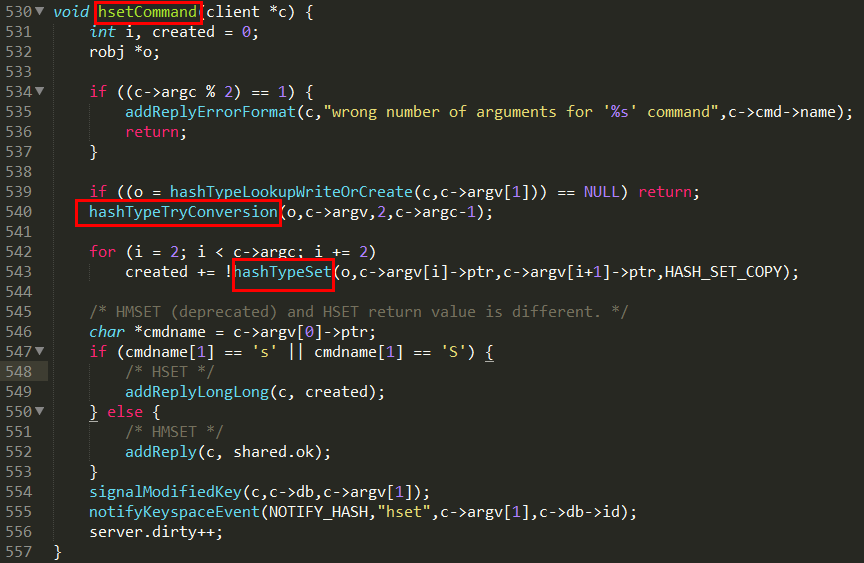
OBJ_ENCODING_HT 编码分析:(每个键值对都会有一个dictEntry)
OBJ_ENCODING_HT 这种编码方式内部才是真正的哈希表结构,或称为字典结构,其可以实现O(1)复杂度的读写操作,因此效率很高。在 Redis内部,从 OBJ_ENCODING_HT类型到底层真正的散列表数据结构是一层层嵌套下去的,组织关系见面图:

源代码:dict.h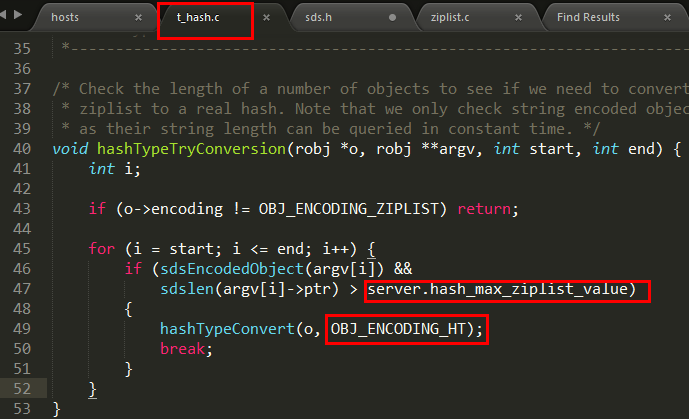

1.3.1.5 List

1.3.1.5.1 底层分析
1.3.1.5.1.1 验证编码

1.3.1.5.1.2 数据结构
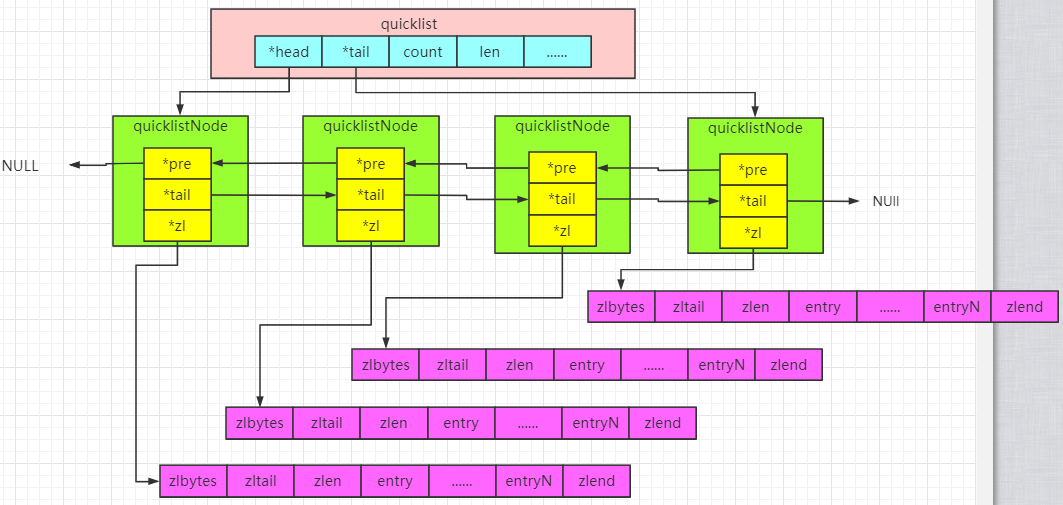
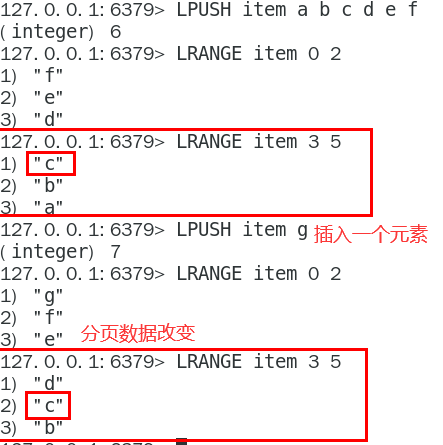
List的一种编码格式:list用quicklist来存储,quicklist存储了一个双向链表,每个节点都是一个ziplist
(低版本redis:ziplist+linkedList;高版本redis:quicklist+ziplist)
1.3.1.5.1.3 源码分析
quicklist.h
head和tail指向双向列表的表头和表尾
quicklistNode中的*zl指向一个ziplist,一个ziplist可以存放多个元素
1.3.1.6 Set

1.3.1.6.1 底层分析
1.3.1.6.1.1 编码验证

如果元素都是整数类型,就用intset存储,否则用hashtable(数组+链表的存来储结构)。key就是元素的值,value为null。
将配置设置为3,存储元素超过3个编码改变
验证是否改变
1.3.1.6.1.2 数据结构
t_set.c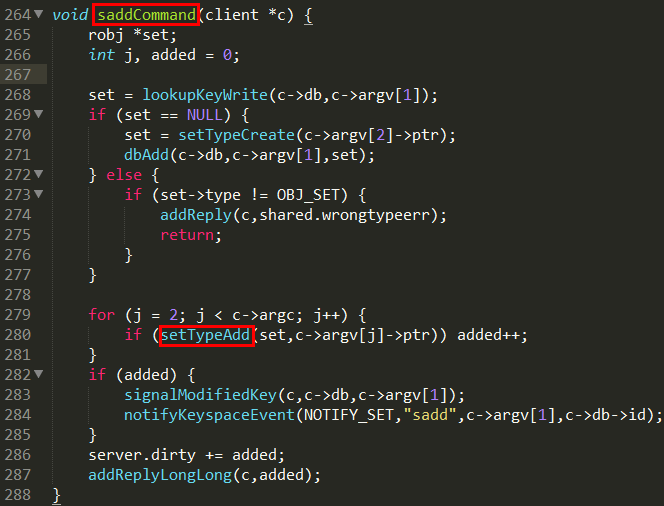

1.3.1.7 Zset

1.3.1.7.1 底层分析
1.3.1.7.1.1 编码验证
 ,超过配置阈值,ziplist转化为skiplist
,超过配置阈值,ziplist转化为skiplist
server.zset_max_ziplist_entries:元素个数
server.zset_max_ziplist_value:元素长度
将阈值调小: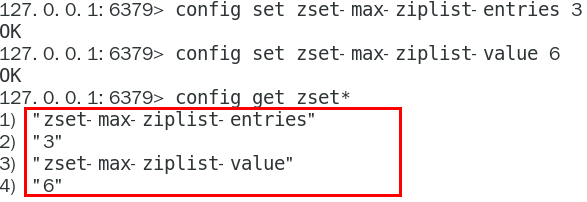

1.3.1.7.1.2 数据结构(skiplist)
跳跃表=链表+多级索引,可以实现二分查找的有序链表,空间换时间的结构
说说链表和数组的优缺点?为什么引出跳表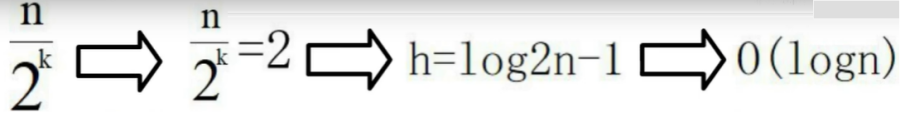

(解决方法:升维,也叫空间换时间)
跳表的时间复杂度:O(logN)
二分查找,时间复杂度是O(logN)
跳表的空间复杂度:O(N)
首先原始链表长度为n
若索引是每2个结点有一个索引结点,每层索引的结点数:n/2, n/4, n/8 … , 8, 4, 2 以此类推;
若每3个结点有一个索引结点,每层索引的结点数:n/3, n/9, n/27 … , 9, 3, 1 以此类推;
所以空间复杂度是O(n);
优缺点
只有在数据量较大的情况下才能体现出来优势。而且应该是读多写少的情况下才能使用,所以它的适用范围应该还是比较有限的
维护成本相对要高 - 新增或者删除时需要把所有索引都更新一遍;
最后在新增和删除的过程中的更新,时间复杂度也是O(log n)
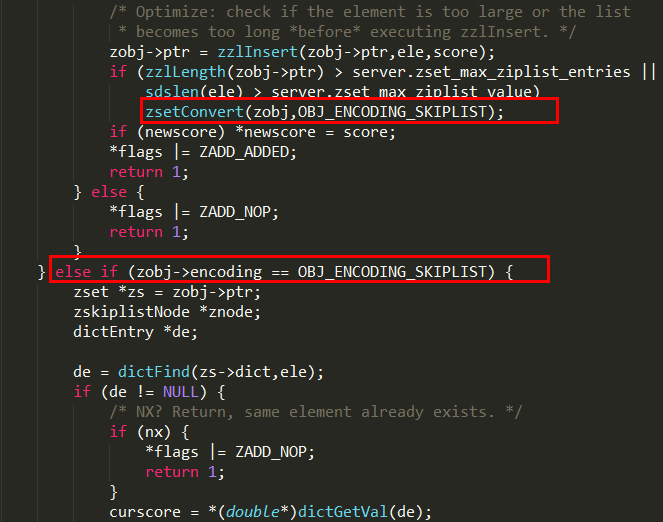
1.3.1.7.1.3 源码分析
t_zset.c:
1.3.2 3种新类型bitmap/hyperloglgo/GEO
1.3.2.1 出现背景分析及统计类型
出现背景:
实现问题:
- 手机App中的每天的⽤⼾登录信息:1天对应1系列⽤⼾ID或移动设备ID;
- 电商⽹站上商品的⽤⼾评论列表:1个商品对应了1系列的评论;
- ⽤⼾在⼿机App上的签到打卡信息:1天对应1系列⽤⼾的签到记录;
- 应⽤⽹站上的⽹⻚访问信息:1个⽹⻚对应1系列的访问点击。
- 在移动应用中,需要统计每天的新增用户数和第2天的留存用户数;
- 在电商网站的商品评论中,需要统计评论列表中的最新评论;
- 在签到打卡中,需要统计一个月内连续打卡的用户数;
- 在网页访问记录中,需要统计独立访客(UniqueVisitor,UV)量。
痛点:类似今日头条、抖音、淘宝这样的额用户访问级别都是亿级的,请问如何处理?
统计类型:
排序统计案例:
以抖音vcr最新的留言评价为案例,所有评论需要两个功能,按照时间排序+分页显示
能够排序+分页显示的redis数据结构是什么合适?
分析:在⾯对需要展示最新列表、排行榜等场景时,如果数据更新频繁或者需要分页显示,建议使⽤ZSet(使用Zset分析此处用户对应的评论条数不会太大)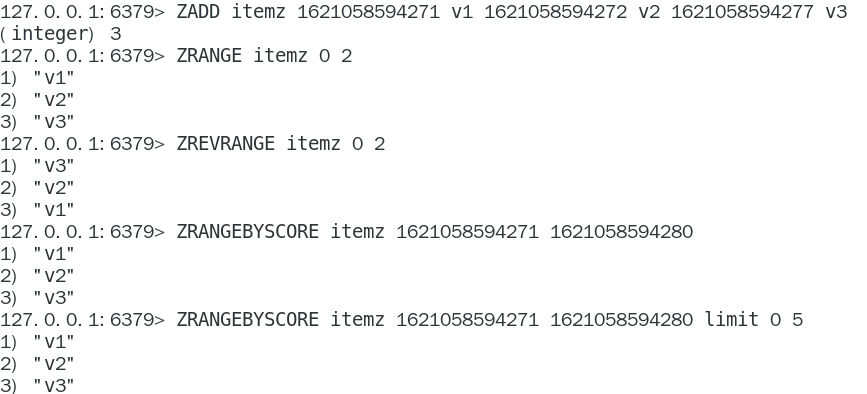
若是使用list,存在分页数据改变问题(个人感觉能接受,不是什么么问题)
1.3.2.2 Bitmap
1.3.2.2.1 数据结构
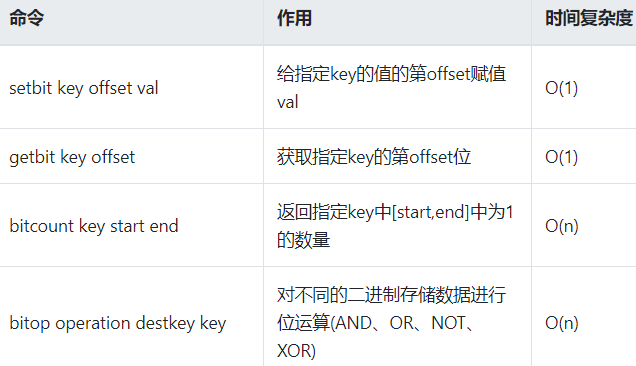
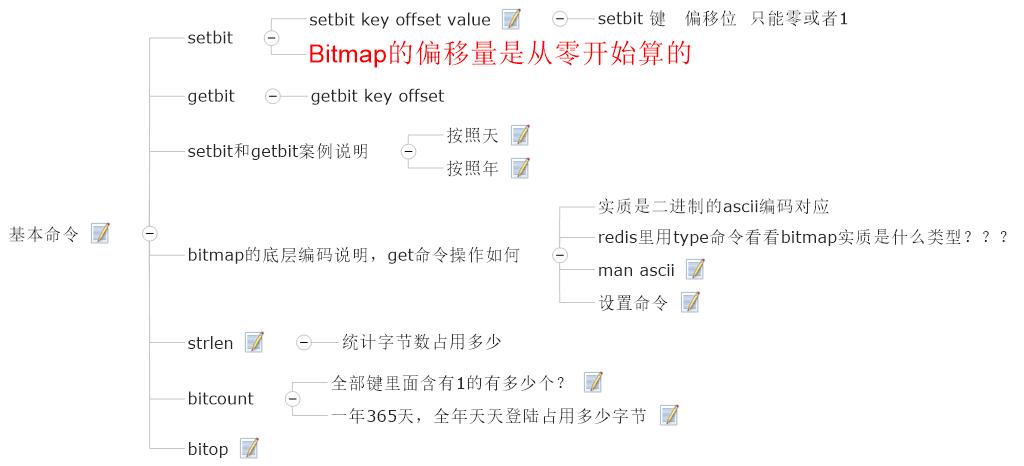
由0和1状态表现的二进制位的bit数组,底层String实现
位图本质是数组,它是基于String数据类型的按位的操作。该数组由多个二进制位组成,每个二进制位都对应一个偏移量(我们可以称之为一个索引或者位格)。Bitmap支持的最大位数是232位,它可以极大的节约存储空间,使用512M内存就可以存储多大42.9亿的字节信息(232 = 4294967296)
案例:京东签到领取京豆(连续签到问题)
在签到统计时,每个用户一天的签到用1个bit位就能表示,
一个月(假设是31天)的签到情况用31个bit位就可以,一年的签到也只需要用365个bit位,根本不用太复杂的集合类型
1.3.2.2.2 编码验证
实质是二进制的ascii编码对应,redis里用type命令看看bitmap实质是什么类型???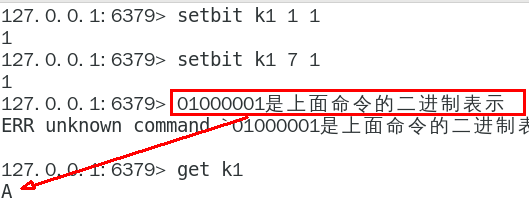
两个setbit命令对k1进行设置后,对应的二进制串就是0100 0001
二进制串就是0100 0001对应的10进制就是65,所以见下图: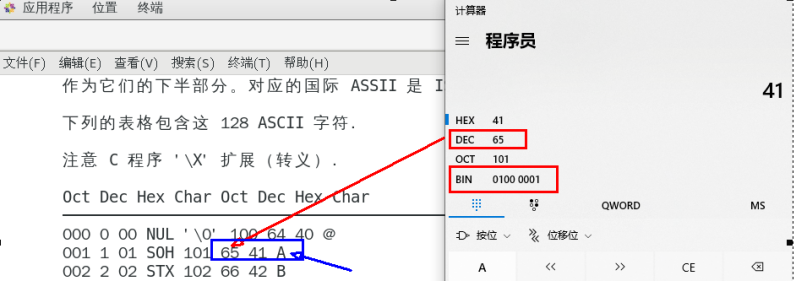
1.3.2.3 Hyperloglog
用途:
1.3.2.3.1 计数算法
去重复统计功能的基数估计算法-就是HyperLogLog
案例:
1.3.2.3.2 HyPerLogLog如何做的?如何演化出来的?
去重复统计你先会想到哪些方式?HashSet、bitmap,优势在于精确。
HashSet存储原始数据,内存消耗大
Bitmap不存储原始数据,消耗比HashSet,随着数据集越大内存消耗也就越大
为解决内存消耗问题,采用概率算法

1.3.2.3.3 为什么redis集群的最大槽数是16384个?
https://github.com/redis/redis/issues/2576
分析:

1.3.2.3.4 天猫网站首页亿级UV的Redis统计方案

分析:
用redis的hash结构存储,按照ipv4的结构来说明,每个ipv4的地址最多是15个字节,某一天的1.5亿15个字节=2G,一个月60G,redis死定了
Hyperloglog:
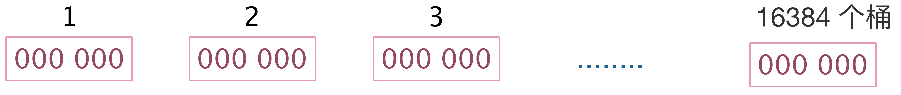
为什么是12Kb?
每个桶取6位,163846÷8 = 12kb,每个桶有6位,最大全部都是1,值就是63
1.3.2.4 GEO

原理:
地理位置信息,地球上的地理位置是使用二维的经纬度表示,核心思想就是将球体转换为平面,区块转换为一点

难点:GeoHash核心原理解析
1.3.2.4.1 案例:美团地图位置附近的酒店推送

选型:es中地理位置信息 或 redis中geo。此处讲述geo
Redis中应该有一份静态数据(如xxx酒店位置),当我们查找会将我们实时位置上传,将附件满足的位置返回给我们(如:xxx酒店)