目录
1. 多表查询
1.1.1 介绍
1.1.2 分类
1.2 内连接
1.3 外连接
1.4 子查询
1.4.1 介绍
1.4.2 标量子查询
1.4.3 列子查询
1.4.4 行子查询
1.4.5 表子查询
2. 事务
2.1 操作
2.2 四大特性
数据库总结2
数据库总结1
1. 多表查询
1.1.1 介绍
多表查询:查询时从多张表中获取所需数据
单表查询的SQL语句:select 字段列表 from 表名;
那么要执行多表查询,只需要使用逗号分隔多张表即可,如: select 字段列表 from 表1, 表2
查询用户表和部门表中的数据:
select * from tb_emp , tb_dept;
会存在多卡尔集
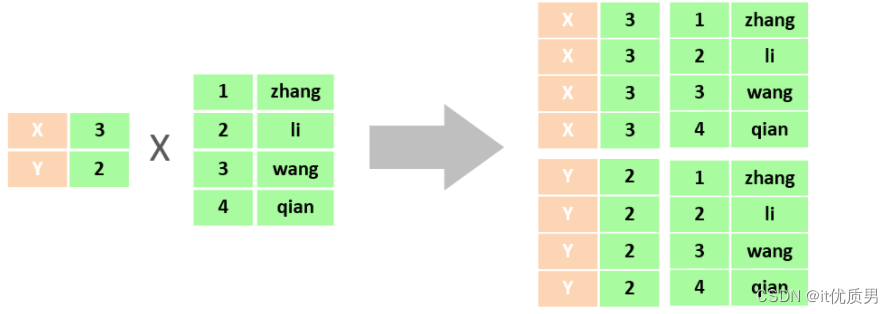
在多表查询时,需要消除无效的笛卡尔积,只保留表关联部分的数据
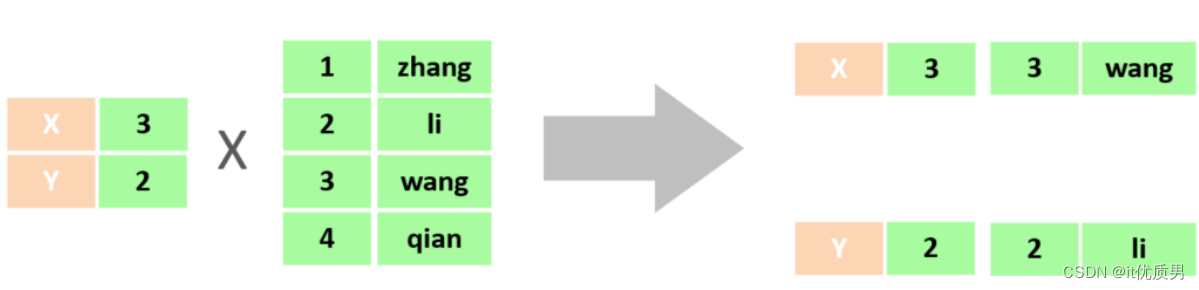
去除无效的笛卡尔积 只需要给多表查询加上连接查询的条件即可。
select * from tb_emp , tb_dept where tb_emp.dept_id = tb_dept.id ;
1.1.2 分类
多表查询可以分为:
1连接查询
内连接:相当于查询A、B交集部分数据

2外连接
左外连接:查询左表所有数据(包括两张表交集部分数据)
右外连接:查询右表所有数据(包括两张表交集部分数据)
3 子查询
1.2 内连接
select 字段列表 from 表1 [ inner ] join 表2 on 连接条件 ... ;
select tb_emp.name , tb_dept.name from tb_emp inner join tb_dept on tb_emp.dept_id = tb_dept.id;
多表查询时给表起别名:
-
tableA as 别名1 , tableB as 别名2 ;
-
tableA 别名1 , tableB 别名2 ;
注意事项:
一旦为表起了别名,就不能再使用表名来指定对应的字段了,此时只能够使用别名来指定字段。
1.3 外连接
外连接分为两种:左外连接 和 右外连接。
左外连接语法结构:
select 字段列表 from 表1 left [ outer ] join 表2 on 连接条件 ... ;
右外连接语法结构:
select 字段列表 from 表1 right [ outer ] join 表2 on 连接条件 ... ;
右外连接相当于查询表2(右表)的所有数据,当然也包含表1和表2交集部分的数据。
注意事项:
左外连接和右外连接是可以相互替换的,只需要调整连接查询时SQL语句中表的先后顺序就可以了。而我们在日常开发使用时,更偏向于左外连接。
1.4 子查询
1.4.1 介绍
SQL语句中嵌套select语句,称为嵌套查询,又称子查询。
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 ... );
子查询外部的语句可以是insert / update / delete / select 的任何一个,最常见的是 select。
子查询可以书写的位置:
-
where之后
-
from之后
-
select之后
1.4.2 标量子查询
查询在 "方东白" 入职之后的员工信息
可以将需求分解为两步:
查询 方东白 的入职日期
查询 指定入职日期之后入职的员工信息
-- 1.查询"方东白"的入职日期
select entrydate from tb_emp where name = '方东白'; #查询结果:2012-11-01
-- 2.查询指定入职日期之后入职的员工信息
select * from tb_emp where entrydate > '2012-11-01';
-- 合并以上两条SQL语句
select * from tb_emp where entrydate > (select entrydate from tb_emp where name = '方东白');
1.4.3 列子查询
查询"教研部"和"咨询部"的所有员工信息
分解为以下两步:
查询 "销售部" 和 "市场部" 的部门ID
根据部门ID, 查询员工信息
-- 1.查询"销售部"和"市场部"的部门ID
select id from tb_dept where name = '教研部' or name = '咨询部'; #查询结果:3,2
-- 2.根据部门ID, 查询员工信息
select * from tb_emp where dept_id in (3,2);
-- 合并以上两条SQL语句
select * from tb_emp where dept_id in (select id from tb_dept where name = '教研部' or name = '咨询部');
1.4.4 行子查询
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
常用的操作符:= 、<> 、IN 、NOT IN
查询与"韦一笑"的入职日期及职位都相同的员工信息
可以拆解为两步进行:
查询 "韦一笑" 的入职日期 及 职位
查询与"韦一笑"的入职日期及职位相同的员工信息
-- 查询"韦一笑"的入职日期 及 职位
select entrydate , job from tb_emp where name = '韦一笑'; #查询结果: 2007-01-01 , 2
-- 查询与"韦一笑"的入职日期及职位相同的员工信息
select * from tb_emp where (entrydate,job) = ('2007-01-01',2);
-- 合并以上两条SQL语句
select * from tb_emp where (entrydate,job) = (select entrydate , job from tb_emp where name = '韦一笑');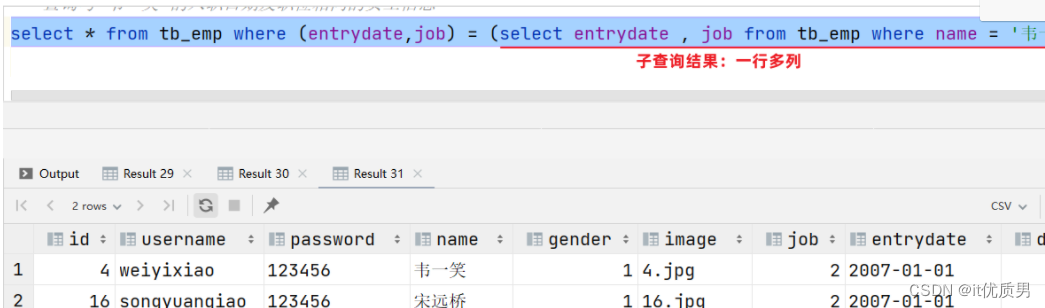
1.4.5 表子查询
子查询返回的结果是多行多列,常作为临时表,这种子查询称为表子查询。
查询入职日期是 "2006-01-01" 之后的员工信息 , 及其部门信息
分解为两步执行:
查询入职日期是 "2006-01-01" 之后的员工信息
基于查询到的员工信息,在查询对应的部门信息
select * from emp where entrydate > '2006-01-01';
select e.*, d.* from (select * from emp where entrydate > '2006-01-01') e left join dept d on e.dept_id = d.id ;
2. 事务
挺有用的 工作中经常用到
-- 删除学工部
delete from dept where id = 1; -- 删除成功-- 删除学工部的员工
delete from emp where dept_id = 1; -- 删除失败(操作过程中出现错误:造成删除没有成功)
-
如果删除部门成功了,而删除该部门的员工时失败了,此时就造成了数据的不一致。
要解决上述的问题,就需要通过数据库中的事务来解决。
2.1 操作
MYSQL中有两种方式进行事务的操作:
-
自动提交事务:即执行一条sql语句提交一次事务。(默认MySQL的事务是自动提交)
-
手动提交事务:先开启,再提交
事务操作有关的SQL语句:
| SQL语句 | 描述 |
|---|---|
| start transaction; / begin ; | 开启手动控制事务 |
| commit; | 提交事务 |
| rollback; | 回滚事务 |
手动提交事务使用步骤:
第1种情况:开启事务 => 执行SQL语句 => 成功 => 提交事务
第2种情况:开启事务 => 执行SQL语句 => 失败 => 回滚事务
2.2 四大特性
-
原子性(Atomicity):事务是不可分割的最小单元,要么全部成功,要么全部失败。
-
一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
-
隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
-
持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
事务的四大特性简称为:ACID
3. 索引
3.1 介绍
索引(index):是帮助数据库高效获取数据的数据结构 。
-
简单来讲,就是使用索引可以提高查询的效率。

-
添加索引后查询
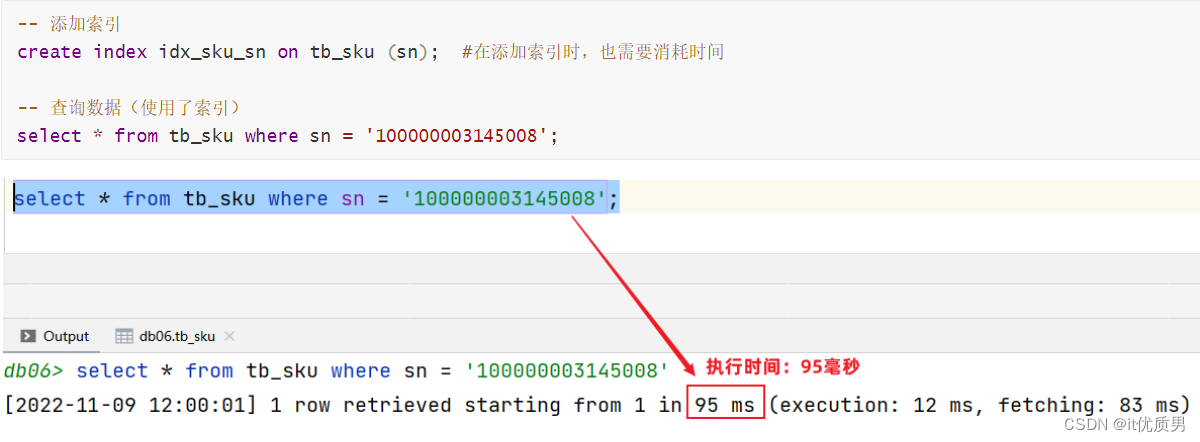
优点:
1. 提高数据查询的效率,降低数据库的IO成本。
2. 通过索引列对数据进行排序,降低数据排序的成本,降低CPU消耗。
缺点:
1. 索引会占用存储空间。
2. 索引大大提高了查询效率,同时却也降低了insert、update、delete的效率。
3.2 结构
二叉查找树:左边的子节点比父节点小,右边的子节点比父节点大

当我们向二叉查找树保存数据时,是按照从大到小(或从小到大)的顺序保存的,此时就会形成一个单向链表,搜索性能会打折扣

可以选择平衡二叉树或者是红黑树来解决上述问题。(红黑树也是一棵平衡的二叉树)
看看B+Tree(多路平衡搜索树)结构中如何避免这个问题 数据结构书上涉及到问题
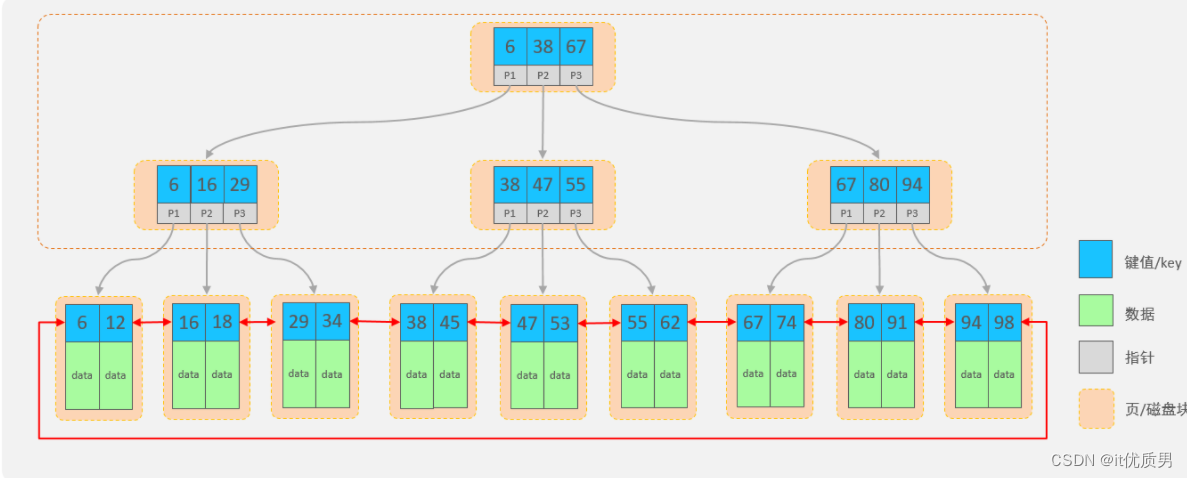
B+Tree结构:
- 每一个节点,可以存储多个key(有n个key,就有n个指针)
- 节点分为:叶子节点、非叶子节点
- 叶子节点,就是最后一层子节点,所有的数据都存储在叶子节点上
- 非叶子节点,不是树结构最下面的节点,用于索引数据,存储的的是:key+指针
- 为了提高范围查询效率,叶子节点形成了一个双向链表,便于数据的排序及区间范围查询