作为迁移学习中的常用技术,Fine-tuning(微调)已经成为了深度学习革命的重要部分。微调不需要针对新任务从头开始学习,只需要加载预训练模型的参数,然后利用新任务的数据进行一步训练模型即可。也可以说微调是对开放域任务的预训练模型进行训练,从而适应特定域任务。
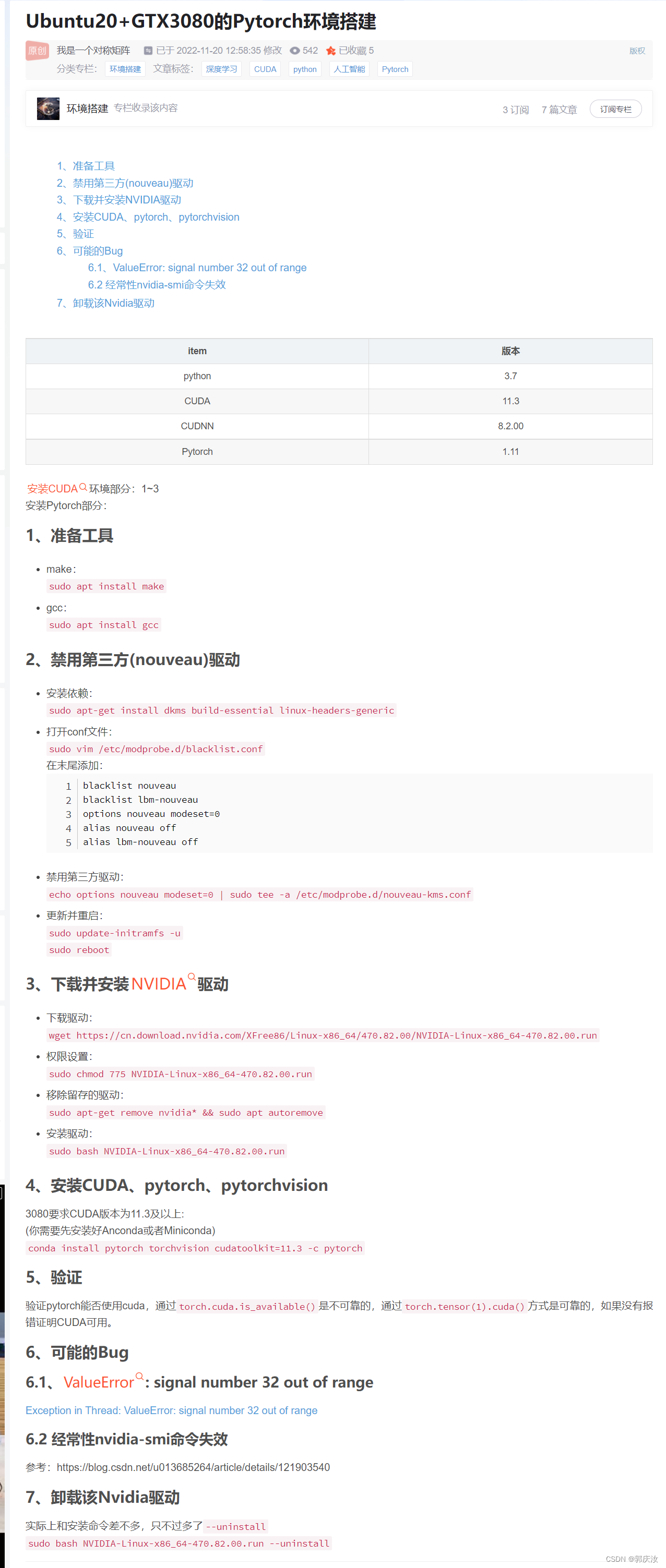
与从零开始训练网络相比,微调是一种低成本,高收益的解决方案。它可以做到:
更少的数据标注,微调不需要从头学习所有内容,所有的训练都是为了获取特定域知识。
更短的训练时间,因为微调的过程中,深度神经网络的大多数层都会冻结,所以需要训练的参数很少。
充分利用现有的训练,并将其迁移到新任务上是深度学习革命的重要实践。微调不仅经济高效,而且不需要高额的算力。这对于希望利用 AI 技术的微小企业和个人开发者来说非常友好。(至少,几乎所有深度学习的博文都会这样告诉你。)
但是如果你仔细想想,或者尝试在真实世界的用例中使用微调技术,很快你就会发现这个承诺伴随着很多不确定因素:
微调究竟需要多少数据,才能得到好的结果?一条标记数据?十条还是一千条?
究竟需要多长时间的训练,才能获得好的结果?一分钟,一小时,一天或者一周?
即使对于大型企业来说,这些问题也很难解答。对于投入 AI 的资源有限的中小型企业和个人来说,这些问题显得尤为关键。特定域数据既不免费,也有错误,所以需要昂贵的人力来标记数据。而且顶级 GPU 算力的购买和维护成本高得惊人,大多数企业都在云服务上租用 GPU 资源。最好的情况下,租借云服务器每月也需要数千元到数万元。这笔费用对于企业来说不容小觑。
针对以上问题,本文将使用 Jina AI Finetuner 给出 定量 答案。Finetuner 旨在提升预训练模型的性能,并且无需昂贵的硬件设施就能将预训练模型投入生产。
https://github.com/jina-ai/finetuner
Finetuner 是一款能够简化神经网络微调流程,加快微调速度的工具。它基于云端整合工作流,并处理所有复杂性和基础架构要求,使得微调神经网络变得更容易、更快速、更高效。
实验设计
我们设计了两个实验来定量研究 标记数据 和 训练时间 对微调性能的影响。在每个实验中,我们通过微调 3 个深度神经网络来构建 3 个多模态搜索任务。我们一共使用了 7 个数据集,为了保证实验的泛化性,其中两个数据集是非特定域的公开据集。
我们通过评估微调模型执行搜索任务的能力来衡量微调模型的性能,评估指标分别为 mRR(Mean Reciprocal Rank[1] )、Recall、mAP(Mean Average Precision[2])。这些指标都是基于验证集中每次搜索的前 20 个结果计算得到的。
下表总结了我们的实验任务、模型和数据集,以及它们在没有微调的情况下的性能指标。
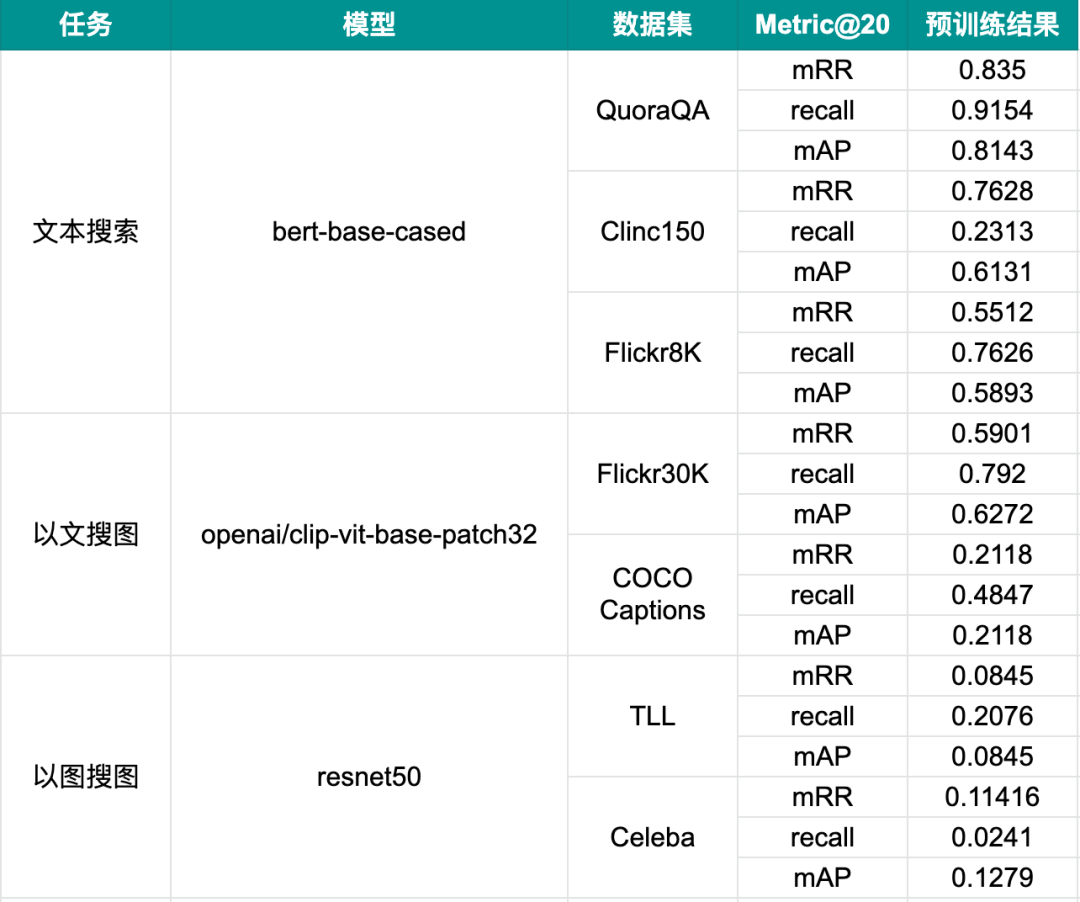
我们已经知道,对于训练任务来说,同等的实验条件下,更多的标注数据、更长的训练时间会对模型的性能产生积极影响。但这远远不够,我们要知道具体需要多少标注数据和多长的训练时间?
实验的首要问题是:
我们能否估计出,为了达到足够好的性能所需的最少的标签数据和训练时间?
1. 为了达到良好的微调性能,需要多少标注数据?
我们将 Finetuner 的标注数据逐渐从 100 条增加到 100,000 条,然后观察这对实验指标产生的影响。为了进一步计算投资收益率(ROI),我们将相对改进(代表净利润)除以标注数据量(代表投资成本)。这对于我们观察实验结果很有帮助,因为它指出了添加标注数据所产生收益递减的点。
下图中,X 轴表示标注数据的数量,Y 轴表示预训练模型的相对改进, Y 值越高越好。
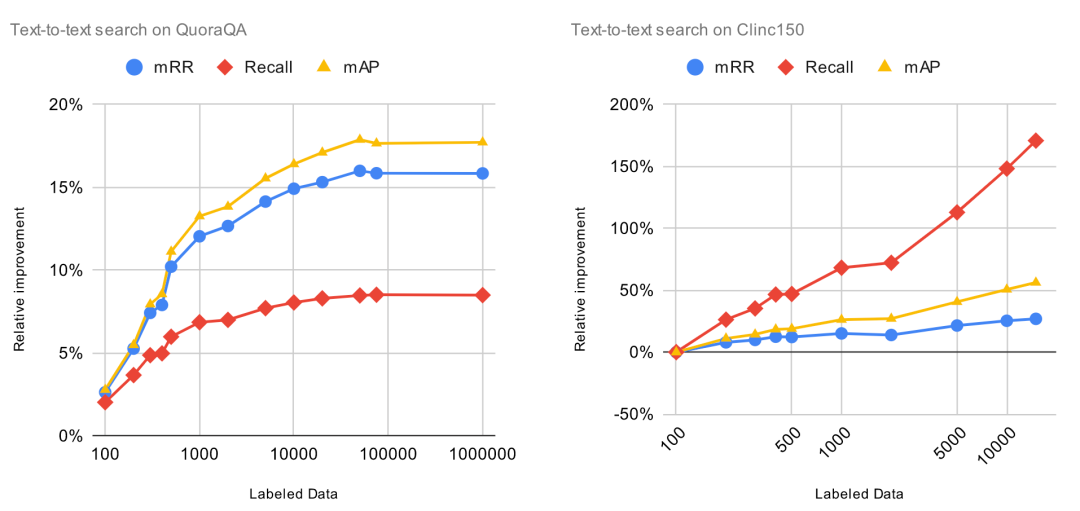
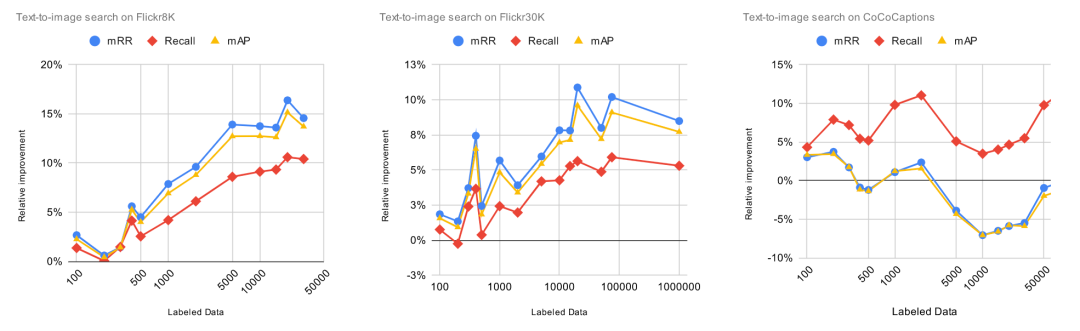
图中显示的结果并不令人惊讶,在所有任务上,模型的性能随着数据集中标记数据的增加而提高,某些任务和数据集比其它任务和数据提升更大。然而,我们可以从这些数字中得出的唯一结论是 Finetuner 的效果和宣传的一样。到目前为止,一切都很好。
更有趣的是 ROI 曲线。在下图中,X 轴表示标记数据的数量,Y 轴表示每个标记数据项的 ROI,当然 Y 值越高越好。特别说明的是,ROI=0 意味着在该点添加新的标记数据,模型的性能将不再提升。
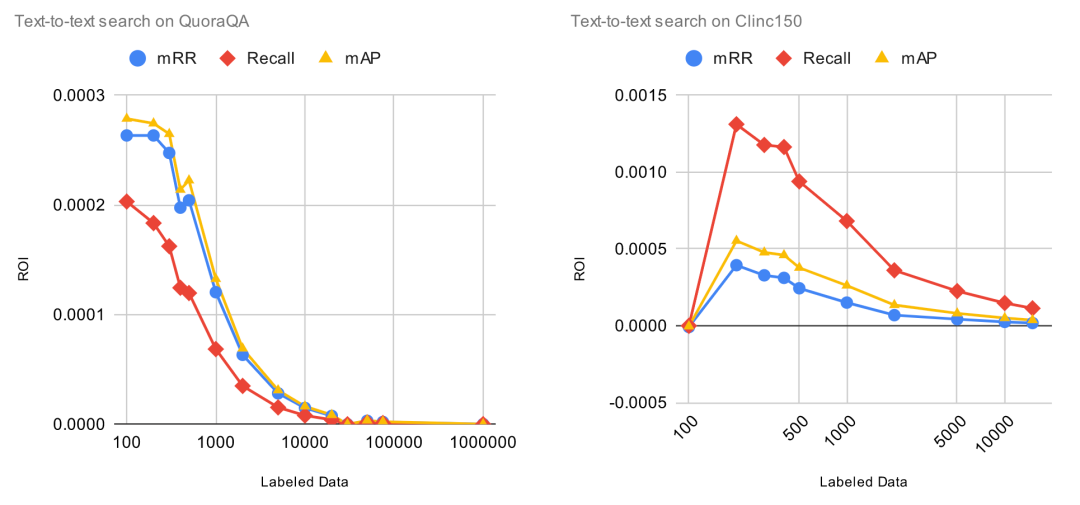
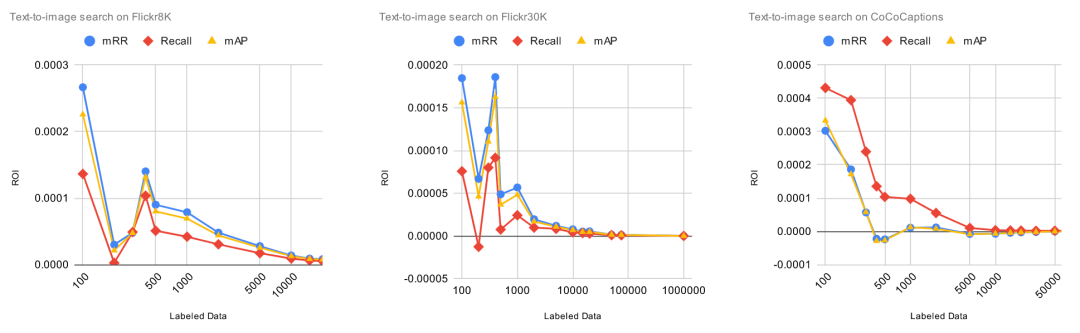
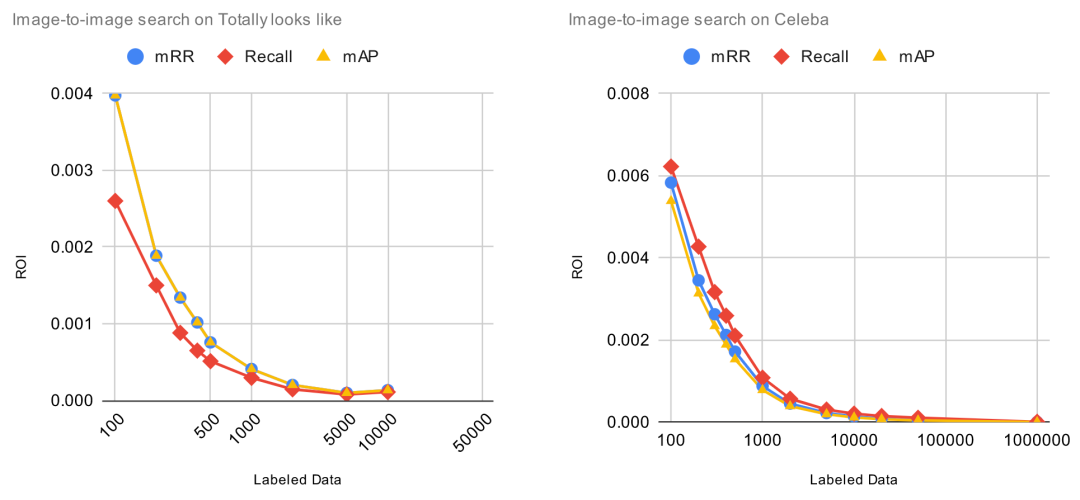
令人惊讶的是,我们可以看到,每单位标签数据的 ROI 从一开始就立即下降。虽然我们预计到它最终会下降,但没想到它从一开始就一直下降,这是一个意外的结果。
2. 为了达到良好的微调性能,微调需要多长时间?
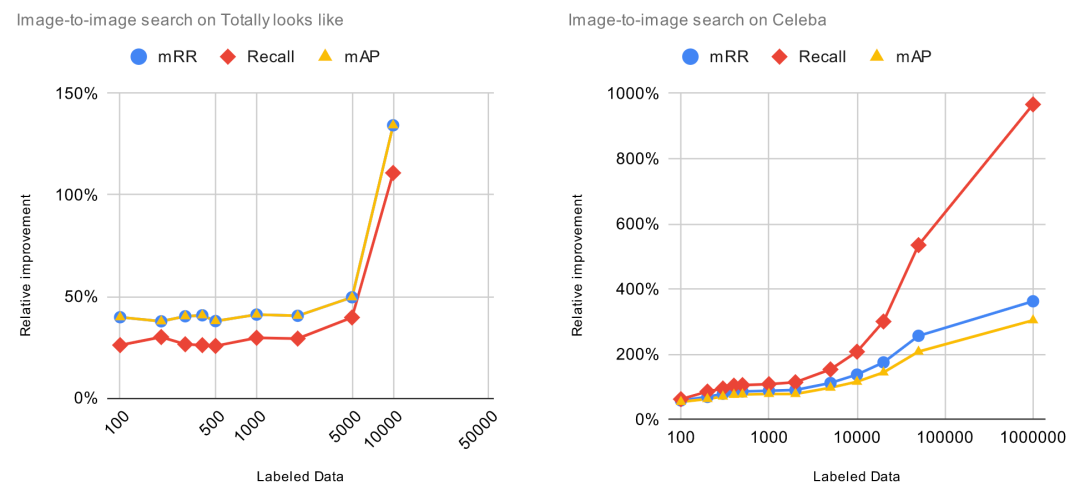
为了评估增加训练时长带来的影响,我们将增加的标注数据固定为 1000 项,然后将训练 epoch 从 1 逐渐增加到 10。每次增加训练 epoch,我们都评估预训练模型的改进并且计算 ROI。对于这些实验,ROI 的计算方法是用相对改进除以训练时长(以秒为单位)。这意味着,当 ROI=0时,增加训练时间将不会提高预训练模型的性能。
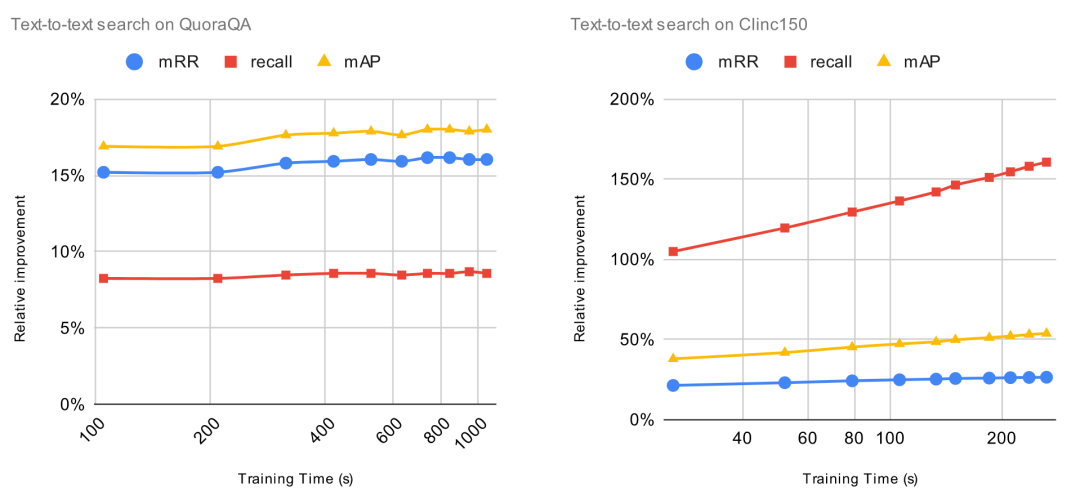
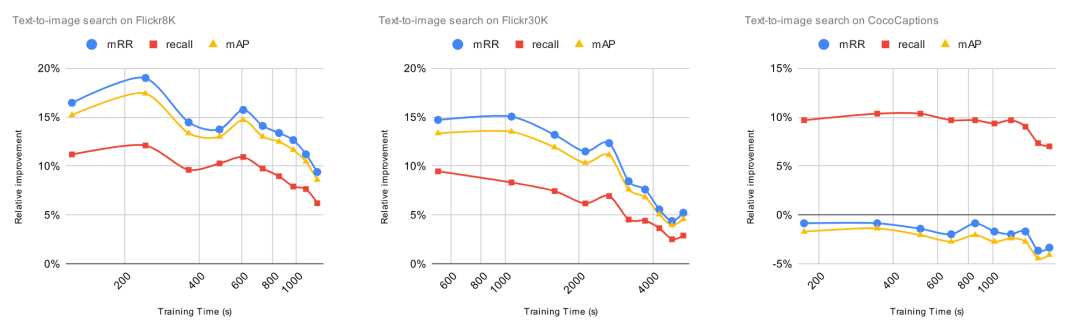
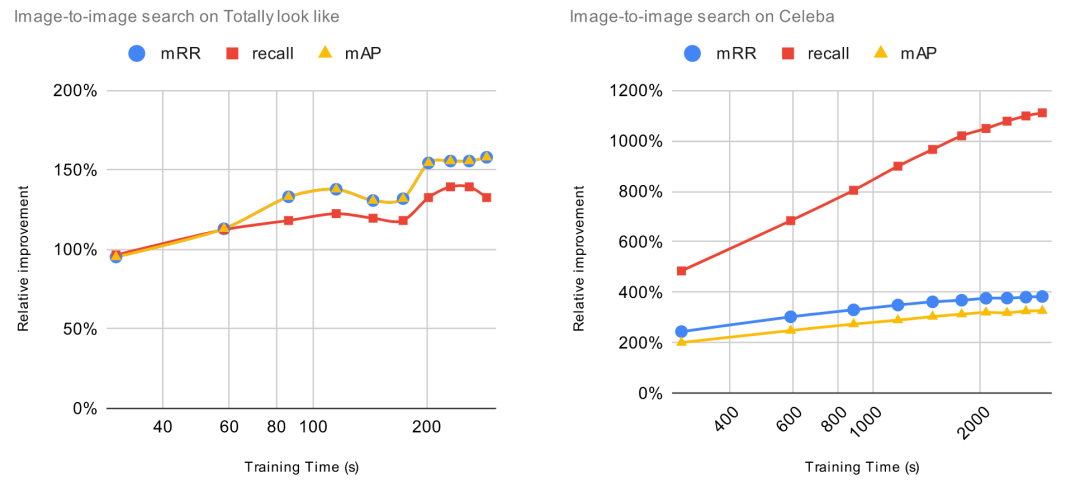
我们事先知道,一直增加更多时间并不能保证模型有任何改善。事实上,这可能会带来过拟合问题,导致预训练模型性能下降。某些模型(例如 CLIP)比其他模型更容易过度拟合。原则上,如果我们不断地用相同的 1000 个数据点进行训练,肯定会造成过度拟合,导致模型的整体性能下降。
让我们一起看看 ROI 曲线。
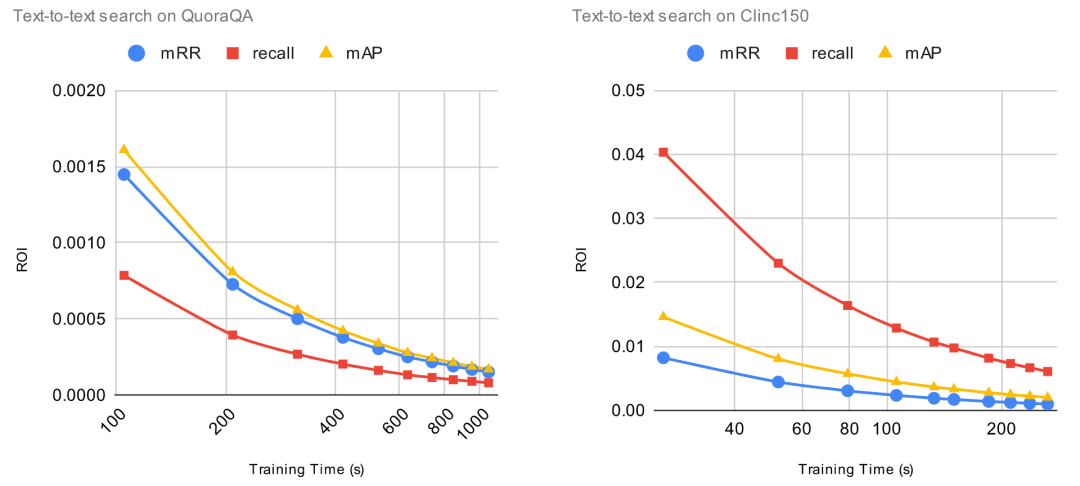
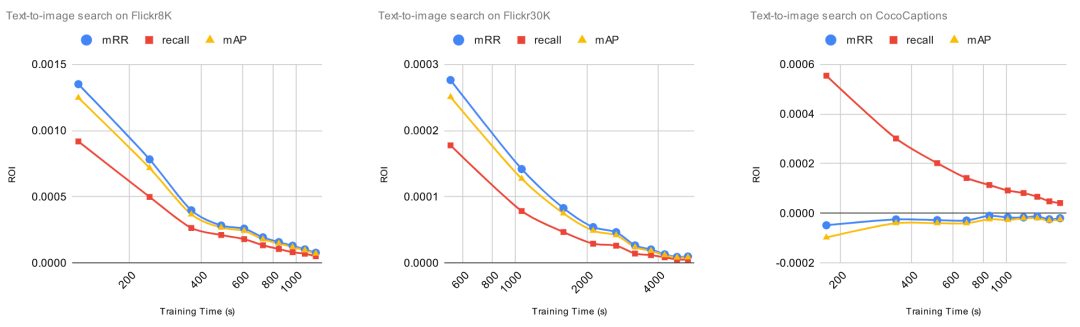
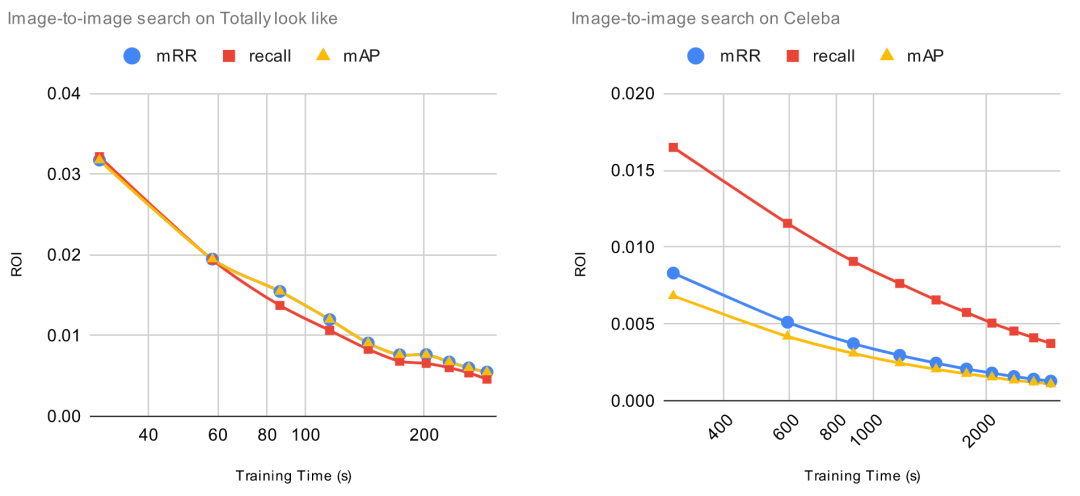
ROI 在微调的第一个 epoch 后立即下降。在上一个实验中, 当 ROI 接近零时,增加标注数据,ROI 依然保持正值。与上一个实验不同,由于过拟合问题,继续增加训练时间,ROI 可能会变成负数。
总结
这对追求最大化收益和最小化成本的用户意味着什么?
许多最先进的深度神经网络都能进行小样本学习,它们只需要几百条标注数据和几分钟训练,就能得到很大的性能提升。你可能会认为训练深度神经网络需要数百万的数据和一周的运行时间,本文打破了这种刻板印象。
它们能以最快的速度,从最少的数据中学习到最多的知识,所以随着投入更多时间和数据进行微调,ROI 会迅速下降。上面的实验中,在 500 个标记数据上训练,或者将 GPU 训练时长增加 600 秒后,ROI 从最高值缩小了 70%。这说明使用超过数百项的训练数据,超过几分钟的训练时长,并不会带来预期的收益。
总的来说,对于开发者来说,使用 Jina AI Finetuner[3] 绝对是明智之举。它能以最快的速度,从最少的数据中学习到最多的知识,而且能在保持最小化成本的同时,实现最大化收益。赶快来试试吧!
参考资料
[1]
Mean Reciprocal Rank: https://en.wikipedia.org/wiki/Mean_reciprocal_rank
[2]Mean Average Precision: https://stats.stackexchange.com/questions/127041/mean-average-precision-vs-mean-reciprocal-rank
[3]Finetuner: https://github.com/jina-ai/finetuner
原文链接
https://jina.ai/news/fine-tuning-with-low-budget-and-high-expectations/
本文作者
肖涵,Jina AI 创始人兼 CEO
王博,Jina AI 高级算法工程师
Scott,Jina AI 高级布道师
本文译者
吴书凝,Jina AI 社区贡献者
🐰 新年活动预约
春节即将到来,1 月 16 日,Jina AI “中文社区面对面·兔年迎新活动”将会在线上举行,欢迎大家点击下方卡片预约直播,定制新年礼盒、多轮互动抽奖、定制红包封面等你来拿!Jina AI 将与社区用户一起,回顾过去一年的高光时刻,展望新一年的美好愿景!
最后,祝大家新年快乐、万事顺遂!1 月 16 日,晚 8 点,我们线上不见不散哦!
更多技术文章
📖 Jina AI创始人肖涵博士解读多模态AI的范式变革
🎨 语音生成图像任务|🚀 模型微调神器Finetuner
💨 DocArray + Redis:快到飞起来的推荐系统
😎 Jina AI正式将DocArray捐赠给Linux基金会
🧬 搜索是过拟合的生成;生成是欠拟合的搜索
👬 在Jina AI社区连接、分享、共创

点击“阅读原文”,即刻了解 Jina

![[cpp进阶]C++智能指针](https://img-blog.csdnimg.cn/3f718a199e3d4f178a6a265266731a67.png)