GPU线程的理解 thread,block,grid
- 一、从 cpu 多线程角度理解 gpu 多线程
- 1、cpu 多线程并行加速
- 2、gpu多线程并行加速
- 2.1、cpu 线程与 gpu 线程的理解(核函数)
- 2.1.1 、第一步:编写核函数
- 2.1.2、第二步:调用核函数(使用内核函数)
- 2.1.3、第三步:编写 CMakeLists & 编译代码
- 二、重要概念 & 与线程索引的直观理解
- 2.1、重要概念
- 2.2、dim3与启动内核
- 2.3、如何找到线程块的索引
- 2.4、如何找到绝对线程索引
- 三、参考代码(打印索引)
- 3.1、打印一维索引
- 3.2、打印二维索引
- 3.2、扩展应用 (获取图片坐标)
一、从 cpu 多线程角度理解 gpu 多线程
1、cpu 多线程并行加速
在 cpu 中,用 openmp 并行计算,有限的线程数对 128 进行分组运算。
#pragma omp parallel for
for(int i =0;i<128;i++)
{
a[i]=b[i]*c[i];
}
2、gpu多线程并行加速
在 gpu 中,可以直接开启 128 个线程对其进行计算。下面步骤和代码是演示如何开启 128个线程并打印
2.1、cpu 线程与 gpu 线程的理解(核函数)
2.1.1 、第一步:编写核函数
__global__ void some_kernel_func(int *a, int *b, int *c)
{
// 初始化线程ID
int i = (blockIdx.x * blockDim.x) + threadIdx.x;
// 对数组元素进行乘法运算
a[i] = b[i] * c[i];
// 打印打前处理的进程ID
// 可以看到blockIdx并非是按照顺序启动的,这也说明线程块启动的随机性
printf("blockIdx.x = %d,blockDimx.x = %d,threadIdx.x = %d\n", blockIdx.x, blockDim.x, threadIdx.x);
}
2.1.2、第二步:调用核函数(使用内核函数)
#)调用语法
kernel_function<<<num_blocks,num_threads>>>(param1,param2,...)
- num_blocks 线程块,至少保证一个线程块
- num_threads 执行内核函数的线程数量
#)tips:
1、 some_kernel_func<<<1,128>>>(a,b,c); 调用 some_kernel_func 1*128 次
2、 some_kernel_func<<<2,128>>>(a,b,c); 调用 some_kernel_func 2*128 次
3、如果将 num_blocks 从 1 改成 2 ,则表示 gpu 将启动两倍于之前的线程数量的线程,
在 blockIdx.x = 0 中,i = threadIdx.x
在 blockIdx.x = 1 中, blockDim.x 表示所要求每个线程块启动的线程数量,在这 = 128
2.1.3、第三步:编写 CMakeLists & 编译代码
CMakeLists.txt
cmake_minimum_required(VERSION 2.8 FATAL_ERROR)
project(demo)
add_definitions(-std=c++14)
find_package(CUDA REQUIRED)
# add cuda
include_directories(${CUDA_INCLUDE_DIRS} )
message("CUDA_LIBRARIES:${CUDA_LIBRARIES}")
message("CUDA_INCLUDE_DIRS:${CUDA_INCLUDE_DIRS}")
cuda_add_executable(demo print_theardId.cu)
# link
target_link_libraries (demo ${CUDA_LIBRARIES})
print_theardId.cu
#include <stdio.h>
#include <stdlib.h>
#include <cuda.h>
#include <cuda_runtime.h>
/*gpu 中的矩阵乘法*/
__global__ void some_kernel_func(int *a, int *b, int *c)
{
// 初始化线程ID
int i = (blockIdx.x * blockDim.x) + threadIdx.x;
// 对数组元素进行乘法运算
a[i] = b[i] * c[i];
// 打印打前处理的进程ID
// 可以看到blockIdx并非是按照顺序启动的,这也说明线程块启动的随机性
printf("blockIdx.x = %d,blockDimx.x = %d,threadIdx.x = %d\n", blockIdx.x, blockDim.x, threadIdx.x);
}
int main(void)
{
// 初始化指针元素
int *a, *b, *c;
// 初始化GPU指针元素
int *gpu_a, *gpu_b, *gpu_c;
// 初始化数组大小
int size = 128 * sizeof(int);
// 为CPU指针元素分配内存
a = (int *)malloc(size);
b = (int *)malloc(size);
c = (int *)malloc(size);
// 为GPU指针元素分配内存
cudaMalloc((void **)&gpu_a, size);
cudaMalloc((void **)&gpu_b, size);
cudaMalloc((void **)&gpu_c, size);
// 初始化数组元素
for (int i = 0; i < 128; i++)
{
b[i] = i;
c[i] = i;
}
// 将数组元素复制到GPU中
cudaMemcpy(gpu_b, b, size, cudaMemcpyHostToDevice);
cudaMemcpy(gpu_c, c, size, cudaMemcpyHostToDevice);
// 执行GPU核函数
some_kernel_func<<<4, 32>>>(gpu_a, gpu_b, gpu_c);
// 将GPU中的结果复制到CPU中
cudaMemcpy(a, gpu_a, size, cudaMemcpyDeviceToHost);
// 释放GPU和CPU中的内存
cudaFree(gpu_a);
cudaFree(gpu_b);
cudaFree(gpu_c);
free(a);
free(b);
free(c);
return 0;
}
mkdir build
cd build
cmake ..
make
./demo
部分结果:
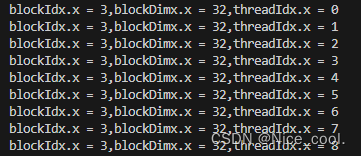
可以看到,
1、gpu 可以直接调用很多个线程,
2、线程数量的多少是由线程块,线程,线程网格等决定的,
3、在核函数中编写单个线程的使用代码,再调用核函数,便可简单的达到 cpu 中 openmp 的多线程方式
二、重要概念 & 与线程索引的直观理解
2.1、重要概念

gridDim.x – 线程网格X维度的线程块数目
gridDim.y – 线程网格Y维度的线程块数目
blockDim.x – 一个线程块X维度上的线程数量
blockDim.y – 一个线程块Y维度上的线程数量
theadIdx.x – 线程块X维度上的线程数量
theadIdx.y – 线程块Y维度上的线程数量
一般来说:
一个 kernel 对应一个 grid
一个 grid 可以有多个 block,一维~三维
一个 block 可以有多个 thread,一维~三维
2.2、dim3与启动内核
dim3 是CUDA中的特殊数据结构,可用来创建二维的线程块与线程网络
eg:4个线程块,128个线程
dim3 threads_rect(32,4) // 每个线程块在X方向开启32个线程,Y方向开启4个线程
dim3 blocks_rect(1,4) //在线程网格上,x方向1个线程块,Y方向4个线程
or
dim3 threads_square(16,8)
dim3 blocks_square(2,2)
以上两种方式线程数都是 324=128 , 168=128,只是线程块中线程的排布方式不一样
启动内核
1、 some_kernel_func<<<blocks_rect,threads_rect>>>(a,b,c);
2、 some_kernel_func<<<blocks_square,threads_square>>>(a,b,c);
2.3、如何找到线程块的索引
线程块的索引 x 线程块的大小 + 线程数量的起始点
参考核函数
// 定义ID查询函数
__global__ void what_is_my_id(
unsigned int *const block,
unsigned int *const thread,
unsigned int *const warp,
unsigned int *const calc_thread)
{
/*线程ID是线程块的索引 x 线程块的大小 + 线程数量的起始点*/
const unsigned int thread_idx = (blockIdx.x * blockDim.x) + threadIdx.x;
block[thread_idx] = blockIdx.x;
thread[thread_idx] = threadIdx.x;
/*线程束 = 线程ID / 内置变量warpSize*/
warp[thread_idx] = thread_idx / warpSize;
calc_thread[thread_idx] = thread_idx;
}
来个.cu文件,体验一下这个核函数,// 编译方法同上
#include <stdio.h>
#include <stdlib.h>
#include "cuda.h"
#include "cuda_runtime.h"
// 定义ID查询函数
__global__ void what_is_my_id(
unsigned int *const block,
unsigned int *const thread,
unsigned int *const warp,
unsigned int *const calc_thread)
{
/*线程ID是线程块的索引 x 线程块的大小 + 线程数量的起始点*/
const unsigned int thread_idx = (blockIdx.x * blockDim.x) + threadIdx.x;
block[thread_idx] = blockIdx.x;
thread[thread_idx] = threadIdx.x;
/*线程束 = 线程ID / 内置变量warpSize*/
warp[thread_idx] = thread_idx / warpSize;
calc_thread[thread_idx] = thread_idx;
}
// 定义数组大小
#define ARRAY_SIZE 1024
// 定义数组字节大小
#define ARRAY_BYTES ARRAY_SIZE * sizeof(unsigned int)
// 声明主机下参数
unsigned int cpu_block[ARRAY_SIZE];
unsigned int cpu_thread[ARRAY_SIZE];
unsigned int cpu_warp[ARRAY_SIZE];
unsigned int cpu_calc_thread[ARRAY_SIZE];
// 定义主函数
int main(void)
{
// 总线程数量为 2 x 64 = 128
// 初始化线程块和线程数量
const unsigned int num_blocks = 2;
const unsigned int num_threads = 64;
char ch;
// 声明设备下参数
unsigned int *gpu_block, *gpu_thread, *gpu_warp, *gpu_calc_thread;
// 声明循环数量
unsigned int i;
// 为设备下参数分配内存
cudaMalloc((void **)&gpu_block, ARRAY_BYTES);
cudaMalloc((void **)&gpu_thread, ARRAY_BYTES);
cudaMalloc((void **)&gpu_warp, ARRAY_BYTES);
cudaMalloc((void **)&gpu_calc_thread, ARRAY_BYTES);
// 调用核函数
what_is_my_id<<<num_blocks, num_threads>>>(gpu_block, gpu_thread, gpu_warp, gpu_calc_thread);
// 将设备下参数复制到主机下
cudaMemcpy(cpu_block, gpu_block, ARRAY_BYTES, cudaMemcpyDeviceToHost);
cudaMemcpy(cpu_thread, gpu_thread, ARRAY_BYTES, cudaMemcpyDeviceToHost);
cudaMemcpy(cpu_warp, gpu_warp, ARRAY_BYTES, cudaMemcpyDeviceToHost);
cudaMemcpy(cpu_calc_thread, gpu_calc_thread, ARRAY_BYTES, cudaMemcpyDeviceToHost);
// 释放GPU内存
cudaFree(gpu_block);
cudaFree(gpu_thread);
cudaFree(gpu_warp);
cudaFree(gpu_calc_thread);
// 循环打印结果
for (i = 0; i < ARRAY_SIZE; i++)
{
printf("Calculated Thread: %d - Block: %d - Warp: %d - Thread: %d\n", cpu_calc_thread[i], cpu_block[i], cpu_warp[i], cpu_thread[i]);
}
return 0;
}
2.4、如何找到绝对线程索引
thread_idx = ( (gridDim.x * blockDim.x ) * idy ) + idx;
绝对线程索引 = 当前行索引 * 每行线程总数 + x方向的偏移
参考核函数
/*定义线程id计算函数*/
__global__ void what_is_my_id_2d_A(
unsigned int *const block_x,
unsigned int *const block_y,
unsigned int *const thread,
unsigned int *const calc_thread,
unsigned int *const x_thread,
unsigned int *const y_thread,
unsigned int *const grid_dimx,
unsigned int *const block_dimx,
unsigned int *const grid_dimy,
unsigned int *const block_dimy)
{
/*获得线程索引*/
const unsigned int idx = (blockIdx.x * blockDim.x) + threadIdx.x;
const unsigned int idy = (blockIdx.y * blockDim.y) + threadIdx.y;
/*
计算线程id
计算公式:线程ID = ((网格维度x * 块维度x) * 线程idy) + 线程idx(作为x维度上的偏移)
*/
const unsigned int thread_idx = ((gridDim.x * blockDim.x) * idy) + idx;
/*获取线程块的索引*/
block_x[thread_idx] = blockIdx.x;
block_y[thread_idx] = blockIdx.y;
/*获取线程的索引*/
thread[thread_idx] = threadIdx.x;
/*计算线程id*/
calc_thread[thread_idx] = thread_idx;
/*获取线程的x维度索引*/
x_thread[thread_idx] = idx;
/*获取线程的y维度索引*/
y_thread[thread_idx] = idy;
/*获取网格维度的X,Y值*/
grid_dimx[thread_idx] = gridDim.x;
grid_dimy[thread_idx] = gridDim.y;
/*获取block_dimy*/
block_dimx[thread_idx] = blockDim.x;
}
来个.cu文件,体验一下这个核函数,// 编译方法同上
#include <stdio.h>
#include <stdlib.h>
#include <cuda.h>
#include <cuda_runtime.h>
/*定义线程id计算函数*/
__global__ void what_is_my_id_2d_A(
unsigned int *const block_x,
unsigned int *const block_y,
unsigned int *const thread,
unsigned int *const calc_thread,
unsigned int *const x_thread,
unsigned int *const y_thread,
unsigned int *const grid_dimx,
unsigned int *const block_dimx,
unsigned int *const grid_dimy,
unsigned int *const block_dimy)
{
/*获得线程索引*/
const unsigned int idx = (blockIdx.x * blockDim.x) + threadIdx.x;
const unsigned int idy = (blockIdx.y * blockDim.y) + threadIdx.y;
/*
计算线程id
计算公式:线程ID = ((网格维度x * 块维度x) * 线程idy) + 线程idx(作为x维度上的偏移)
*/
const unsigned int thread_idx = ((gridDim.x * blockDim.x) * idy) + idx;
/*获取线程块的索引*/
block_x[thread_idx] = blockIdx.x;
block_y[thread_idx] = blockIdx.y;
/*获取线程的索引*/
thread[thread_idx] = threadIdx.x;
/*计算线程id*/
calc_thread[thread_idx] = thread_idx;
/*获取线程的x维度索引*/
x_thread[thread_idx] = idx;
/*获取线程的y维度索引*/
y_thread[thread_idx] = idy;
/*获取网格维度的X,Y值*/
grid_dimx[thread_idx] = gridDim.x;
grid_dimy[thread_idx] = gridDim.y;
/*获取block_dimy*/
block_dimx[thread_idx] = blockDim.x;
}
/*定义矩阵宽度以及大小*/
#define ARRAY_SIZE_X 32
#define ARRAY_SIZE_Y 16
#define ARRAY_SIZE_IN_BYTES (ARRAY_SIZE_X * ARRAY_SIZE_Y * sizeof(unsigned int))
/*声明CPU端上的各项参数内存*/
unsigned int *cpu_block_x[ARRAY_SIZE_Y][ARRAY_SIZE_X];
unsigned int *cpu_block_y[ARRAY_SIZE_Y][ARRAY_SIZE_X];
unsigned int *cpu_thread[ARRAY_SIZE_Y][ARRAY_SIZE_X];
unsigned int *cpu_warp[ARRAY_SIZE_Y][ARRAY_SIZE_X];
unsigned int *cpu_calc_thread[ARRAY_SIZE_Y][ARRAY_SIZE_X];
unsigned int *cpu_x_thread[ARRAY_SIZE_Y][ARRAY_SIZE_X];
unsigned int *cpu_y_thread[ARRAY_SIZE_Y][ARRAY_SIZE_X];
unsigned int *cpu_grid_dimx[ARRAY_SIZE_Y][ARRAY_SIZE_X];
unsigned int *cpu_grid_dimy[ARRAY_SIZE_Y][ARRAY_SIZE_X];
unsigned int *cpu_block_dimx[ARRAY_SIZE_Y][ARRAY_SIZE_X];
unsigned int *cpu_block_dimy[ARRAY_SIZE_Y][ARRAY_SIZE_X];
int main(void)
{
const dim3 thread_rect = (32, 4);
/*注意这里的块的dim3值为1x4*/
const dim3 block_rect = (1, 4);
/*初始化矩形线程分布启动项*/
const dim3 thread_square = (16, 8);
/*注意这里的块的dim3值为2x2*/
const dim3 block_square = (2, 2);
/*定义一个临时指针用于打印信息*/
char ch;
/*定义GPU端上的各项参数内存*/
unsigned int *gpu_block_x;
unsigned int *gpu_block_y;
unsigned int *gpu_thread;
unsigned int *gpu_warp;
unsigned int *gpu_calc_thread;
unsigned int *gpu_x_thread;
unsigned int *gpu_y_thread;
unsigned int *gpu_grid_dimx;
unsigned int *gpu_grid_dimy;
unsigned int *gpu_block_dimx;
/*分配GPU端上的各项参数内存*/
cudaMalloc((void **)&gpu_block_x, ARRAY_SIZE_IN_BYTES);
cudaMalloc((void **)&gpu_block_y, ARRAY_SIZE_IN_BYTES);
cudaMalloc((void **)&gpu_thread, ARRAY_SIZE_IN_BYTES);
cudaMalloc((void **)&gpu_warp, ARRAY_SIZE_IN_BYTES);
cudaMalloc((void **)&gpu_calc_thread, ARRAY_SIZE_IN_BYTES);
cudaMalloc((void **)&gpu_x_thread, ARRAY_SIZE_IN_BYTES);
cudaMalloc((void **)&gpu_y_thread, ARRAY_SIZE_IN_BYTES);
cudaMalloc((void **)&gpu_grid_dimx, ARRAY_SIZE_IN_BYTES);
cudaMalloc((void **)&gpu_grid_dimy, ARRAY_SIZE_IN_BYTES);
cudaMalloc((void **)&gpu_block_dimx, ARRAY_SIZE_IN_BYTES);
/*调用核函数*/
for (int kernel = 0; kernel < 2; kernel++)
{
switch (kernel)
{
case 0:
/*执行矩形配置核函数*/
what_is_my_id_2d_A<<<block_rect, thread_rect>>>(gpu_block_x, gpu_block_y, gpu_thread, gpu_warp, gpu_calc_thread, gpu_x_thread, gpu_y_thread, gpu_grid_dimx, gpu_grid_dimy, gpu_block_dimx);
break;
case 1:
/*执行方形配置核函数*/
what_is_my_id_2d_A<<<block_square, thread_square>>>(gpu_block_x, gpu_block_y, gpu_thread, gpu_warp, gpu_calc_thread, gpu_x_thread, gpu_y_thread, gpu_grid_dimx, gpu_grid_dimy, gpu_block_dimx);
break;
default:
exit(1);
break;
}
/*将GPU端上的各项参数内存拷贝到CPU端上*/
cudaMemcpy(cpu_block_x, gpu_block_x, ARRAY_SIZE_IN_BYTES, cudaMemcpyDeviceToHost);
cudaMemcpy(cpu_block_y, gpu_block_y, ARRAY_SIZE_IN_BYTES, cudaMemcpyDeviceToHost);
cudaMemcpy(cpu_thread, gpu_thread, ARRAY_SIZE_IN_BYTES, cudaMemcpyDeviceToHost);
cudaMemcpy(cpu_warp, gpu_warp, ARRAY_SIZE_IN_BYTES, cudaMemcpyDeviceToHost);
cudaMemcpy(cpu_calc_thread, gpu_calc_thread, ARRAY_SIZE_IN_BYTES, cudaMemcpyDeviceToHost);
cudaMemcpy(cpu_x_thread, gpu_x_thread, ARRAY_SIZE_IN_BYTES, cudaMemcpyDeviceToHost);
cudaMemcpy(cpu_y_thread, gpu_y_thread, ARRAY_SIZE_IN_BYTES, cudaMemcpyDeviceToHost);
cudaMemcpy(cpu_grid_dimx, gpu_grid_dimx, ARRAY_SIZE_IN_BYTES, cudaMemcpyDeviceToHost);
cudaMemcpy(cpu_grid_dimy, gpu_grid_dimy, ARRAY_SIZE_IN_BYTES, cudaMemcpyDeviceToHost);
cudaMemcpy(cpu_block_dimx, gpu_block_dimx, ARRAY_SIZE_IN_BYTES, cudaMemcpyDeviceToHost);
printf("\n kernel %d\n", kernel);
/*打印结果*/
for (int y = 0; y < ARRAY_SIZE_Y; y++)
{
for (int x = 0; x < ARRAY_SIZE_X; x++)
{
printf("CT: %2u Bkx: %1u TID: %2u YTID: %2u XTID: %2u GDX: %1u BDX: %1u GDY: %1u BDY:%1U\n", cpu_calc_thread[y * ARRAY_SIZE_X + x], cpu_block_x[y * ARRAY_SIZE_X + x], cpu_thread[y * ARRAY_SIZE_X + x], cpu_y_thread[y * ARRAY_SIZE_X + x], cpu_x_thread[y * ARRAY_SIZE_X + x], cpu_grid_dimx[y * ARRAY_SIZE_X + x], cpu_block_dimx[y * ARRAY_SIZE_X + x], cpu_grid_dimy[y * ARRAY_SIZE_X + x], cpu_block_y[y * ARRAY_SIZE_X + x]);
}
/*每行打印完后按任意键继续*/
ch = getchar();
}
printf("Press any key to continue\n");
ch = getchar();
}
/*释放GPU端上的各项参数内存*/
cudaFree(gpu_block_x);
cudaFree(gpu_block_y);
cudaFree(gpu_thread);
cudaFree(gpu_warp);
cudaFree(gpu_calc_thread);
cudaFree(gpu_x_thread);
cudaFree(gpu_y_thread);
cudaFree(gpu_grid_dimx);
cudaFree(gpu_grid_dimy);
cudaFree(gpu_block_dimx);
}
其中有个代码片段
const dim3 thread_rect = (32, 4);
/*注意这里的块的dim3值为1x4*/
const dim3 block_rect = (1, 4);
const dim3 thread_square = (16, 8);
/*注意这里的块的dim3值为2x2*/
const dim3 block_square = (2, 2);
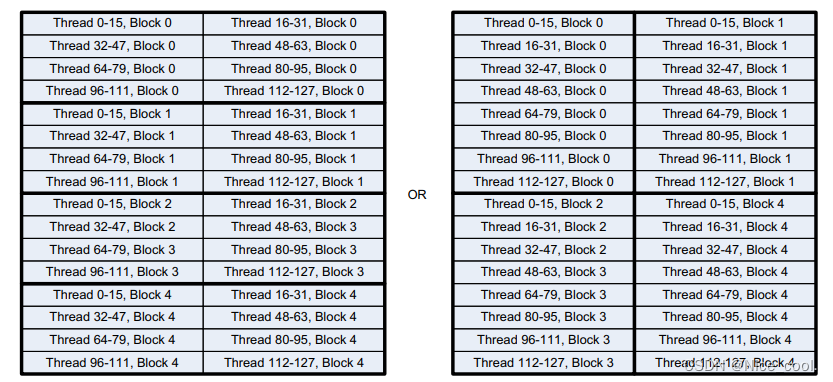
如图理解,都是 2x2 / 1x4 = 四个线程块;每一块 32x4 / 16x8 =128个线程。这是两种不同的线程块布局方式。
但是一般会选择长方形的布局方式。
1、要以行的方式进行连续访问内存,而不是列的方式
2、同一个线程块可以通过共享内存进行通信
3、同一个线程束中的线程存储访问合并在一起了,长方形布局只需要一次访问操作就可以获得连续的内存数据 // 正方形要两次访问
三、参考代码(打印索引)
3.1、打印一维索引
场景:
一个数组有 8 个数据,要开 8 个线程去访问。
我们想切成 2 个block 访问,所以一个 blcok 就有 4 个线程
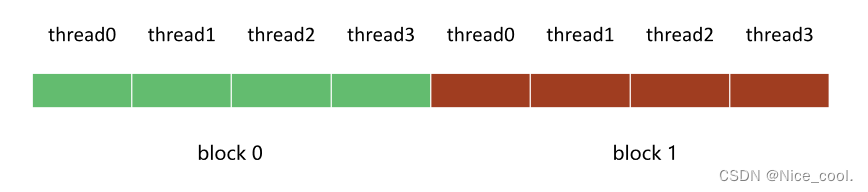
所以 线程设置如下:一个 block里面4个线程,一个grid里面2个block
一维索引的设置如下:
dim3 block(4);// 一个 block 里面 4 个线程
dim3 grid(2);// 一个 grid 里面 2 个 block
#include <cuda_runtime.h>
#include <stdio.h>
__global__ void print_idx_kernel(){
printf("block idx: (%3d, %3d, %3d), thread idx: (%3d, %3d, %3d)\n",
blockIdx.z, blockIdx.y, blockIdx.x,
threadIdx.z, threadIdx.y, threadIdx.x);
}
__global__ void print_dim_kernel(){
printf("grid dimension: (%3d, %3d, %3d), block dimension: (%3d, %3d, %3d)\n",
gridDim.z, gridDim.y, gridDim.x,
blockDim.z, blockDim.y, blockDim.x);
}
__global__ void print_thread_idx_per_block_kernel(){
int index = threadIdx.z * blockDim.x * blockDim.y + \
threadIdx.y * blockDim.x + \
threadIdx.x;
printf("block idx: (%3d, %3d, %3d), thread idx: %3d\n",
blockIdx.z, blockIdx.y, blockIdx.x,
index);
}
__global__ void print_thread_idx_per_grid_kernel(){
int bSize = blockDim.z * blockDim.y * blockDim.x;
int bIndex = blockIdx.z * gridDim.x * gridDim.y + \
blockIdx.y * gridDim.x + \
blockIdx.x;
int tIndex = threadIdx.z * blockDim.x * blockDim.y + \
threadIdx.y * blockDim.x + \
threadIdx.x;
int index = bIndex * bSize + tIndex;
printf("block idx: %3d, thread idx in block: %3d, thread idx: %3d\n",
bIndex, tIndex, index);
}
void print_one_dim(){
int inputSize = 8;
int blockDim = 4;
int gridDim = inputSize / blockDim;
dim3 block(blockDim);//4
dim3 grid(gridDim);//2
print_idx_kernel<<<grid, block>>>();
//print_dim_kernel<<<grid, block>>>();
//print_thread_idx_per_block_kernel<<<grid, block>>>();
//print_thread_idx_per_grid_kernel<<<grid, block>>>();
cudaDeviceSynchronize(); //用于同步
}
int main() {
print_one_dim();
return 0;
}
核函数及其结果:
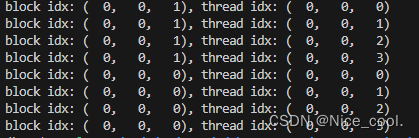
- 8个线程,8个输出;
- 索引都是从 z到y到x的;
1、线程块与线程
__global__ void print_idx_kernel(){
printf("block idx: (%3d, %3d, %3d), thread idx: (%3d, %3d, %3d)\n",
blockIdx.z, blockIdx.y, blockIdx.x,
threadIdx.z, threadIdx.y, threadIdx.x);
}
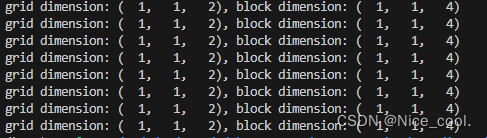
2、线程网格与线程块
__global__ void print_dim_kernel(){
printf("grid dimension: (%3d, %3d, %3d), block dimension: (%3d, %3d, %3d)\n",
gridDim.z, gridDim.y, gridDim.x,
blockDim.z, blockDim.y, blockDim.x);
}
1x1x2=2
1x1x4=4
3、在 block 里面寻找每个线程的索引
__global__ void print_thread_idx_per_block_kernel(){
int index = threadIdx.z * blockDim.x * blockDim.y + \
threadIdx.y * blockDim.x + \
threadIdx.x;
printf("block idx: (%3d, %3d, %3d), thread idx: %3d\n",
blockIdx.z, blockIdx.y, blockIdx.x,
index);
}
可以根据下面的图来理解访问顺序:
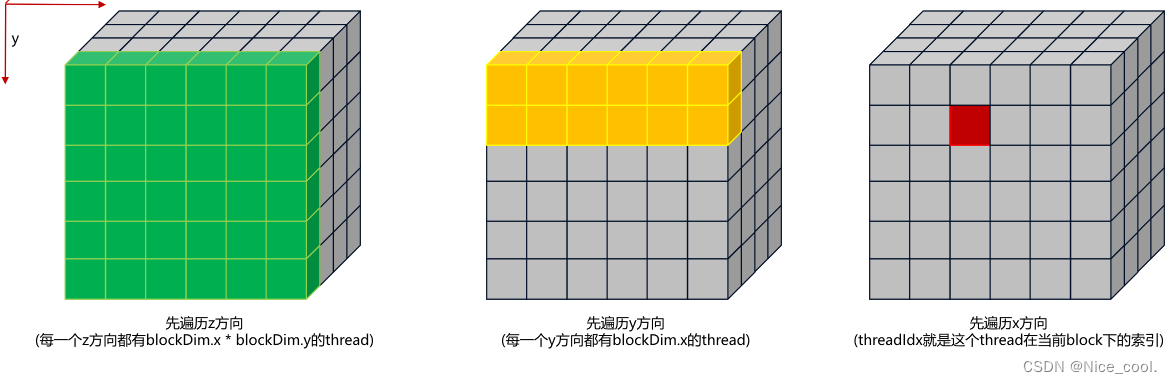
结果:
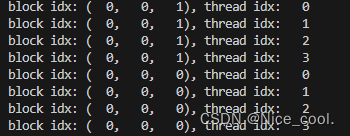
4、在 grid 里面寻找每个线程索引
__global__ void print_thread_idx_per_grid_kernel(){
int bSize = blockDim.z * blockDim.y * blockDim.x; // block 的线程大小
int bIndex = blockIdx.z * gridDim.x * gridDim.y + \
blockIdx.y * gridDim.x + \
blockIdx.x;
int tIndex = threadIdx.z * blockDim.x * blockDim.y + \
threadIdx.y * blockDim.x + \
threadIdx.x;
int index = bIndex * bSize + tIndex;
printf("block idx: %3d, thread idx in block: %3d, thread idx: %3d\n",
bIndex, tIndex, index);
}
可以根据下面的图来理解访问顺序:实际上就是从一堆方块里面找到那个红点
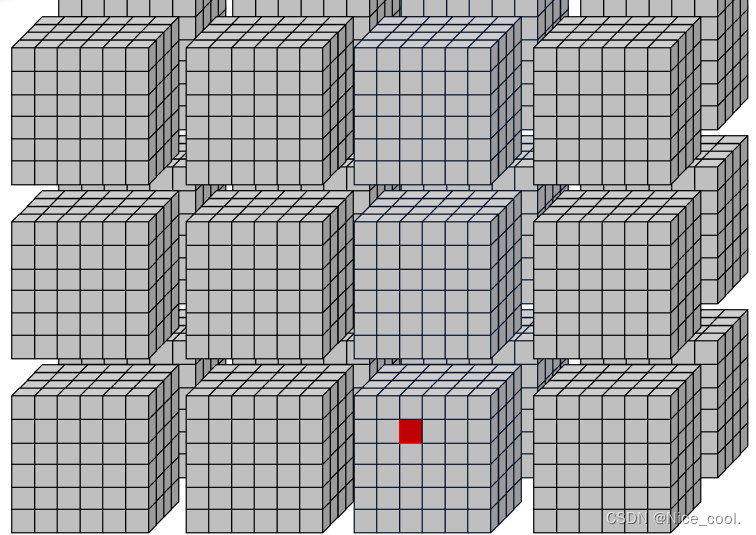
结果:(thread 从 0 ~ 7 )
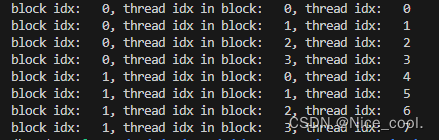
3.2、打印二维索引
#include <cuda_runtime.h>
#include <stdio.h>
__global__ void print_idx_kernel(){
printf("block idx: (%3d, %3d, %3d), thread idx: (%3d, %3d, %3d)\n",
blockIdx.z, blockIdx.y, blockIdx.x,
threadIdx.z, threadIdx.y, threadIdx.x);
}
__global__ void print_dim_kernel(){
printf("grid dimension: (%3d, %3d, %3d), block dimension: (%3d, %3d, %3d)\n",
gridDim.z, gridDim.y, gridDim.x,
blockDim.z, blockDim.y, blockDim.x);
}
__global__ void print_thread_idx_per_block_kernel(){
int index = threadIdx.z * blockDim.x * blockDim.y + \
threadIdx.y * blockDim.x + \
threadIdx.x;
printf("block idx: (%3d, %3d, %3d), thread idx: %3d\n",
blockIdx.z, blockIdx.y, blockIdx.x,
index);
}
__global__ void print_thread_idx_per_grid_kernel(){
int bSize = blockDim.z * blockDim.y * blockDim.x;
int bIndex = blockIdx.z * gridDim.x * gridDim.y + \
blockIdx.y * gridDim.x + \
blockIdx.x;
int tIndex = threadIdx.z * blockDim.x * blockDim.y + \
threadIdx.y * blockDim.x + \
threadIdx.x;
int index = bIndex * bSize + tIndex;
printf("block idx: %3d, thread idx in block: %3d, thread idx: %3d\n",
bIndex, tIndex, index);
}
void print_two_dim(){
int inputWidth = 4;
int blockDim = 2;
int gridDim = inputWidth / blockDim;
dim3 block(blockDim, blockDim);// 2 , 2
dim3 grid(gridDim, gridDim); //2,2
print_idx_kernel<<<grid, block>>>();
// print_dim_kernel<<<grid, block>>>();
// print_thread_idx_per_block_kernel<<<grid, block>>>();
//print_thread_idx_per_grid_kernel<<<grid, block>>>();
cudaDeviceSynchronize();
}
int main() {
print_two_dim();
return 0;
}
3.2、扩展应用 (获取图片坐标)
原理其实就是同上面(在 grid 里面寻找每个线程索引)一样,这里为了方便看,再次贴一次图。
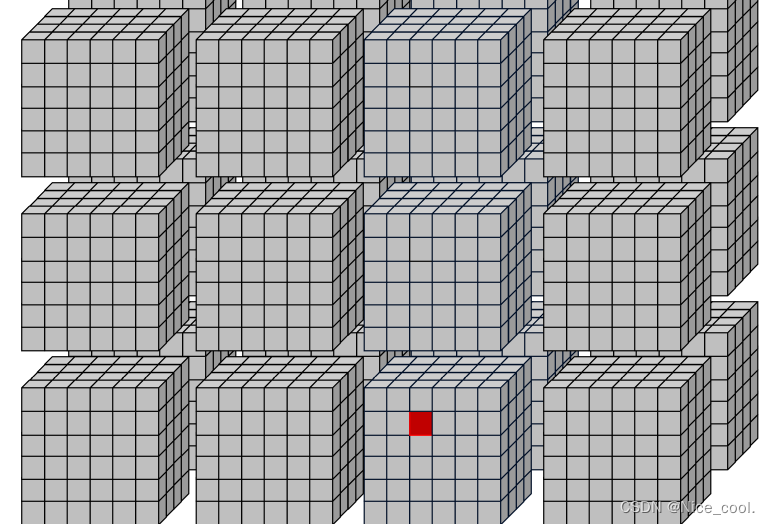
重写一个核函数,比之前的方便看
__global__ void print_cord_kernel(){
int index = threadIdx.z * blockDim.x * blockDim.y + \
threadIdx.y * blockDim.x + \
threadIdx.x;
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
printf("block idx: (%3d, %3d, %3d), thread idx: %3d, cord: (%3d, %3d)\n",
blockIdx.z, blockIdx.y, blockIdx.x,
index, x, y);
}
完整的 .cu 文件如下:
#include <cuda_runtime.h>
#include <stdio.h>
__global__ void print_cord_kernel(){
int index = threadIdx.z * blockDim.x * blockDim.y + \
threadIdx.y * blockDim.x + \
threadIdx.x;
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
printf("block idx: (%3d, %3d, %3d), thread idx: %3d, cord: (%3d, %3d)\n",
blockIdx.z, blockIdx.y, blockIdx.x,
index, x, y);
}
void print_cord(){
int inputWidth = 4;
int blockDim = 2;
int gridDim = inputWidth / blockDim;
dim3 block(blockDim, blockDim);
dim3 grid(gridDim, gridDim);
print_cord_kernel<<<grid, block>>>();
cudaDeviceSynchronize();
}
int main() {
print_cord();
return 0;
}