目录
一、什么是索引
二、索引的有哪些种类?
三、InnoDB的不同的索引组织结构是怎样的呢?
四、什么是覆盖索引
五、如何使用是覆盖索引?
六、如何确定数据库成功使用了覆盖索引呢
总结:
一、什么是索引
索引(在 MySQL 中也叫“键key”)是存储引擎快速找到记录的一种数据结构,通俗来说类似书本的目录,这个比方虽然被用的最多但是也是最恰如其当的,在查询书本中的某个知识点不借助目录的情况下,往往都找的够呛,那么索引相较于数据库的重要性也可见一斑。
二、索引的有哪些种类?
索引的种类这里只罗列出InnoDB支持的索引:主键索引(PRIMARY),普通索引(INDEX),唯一索引(UNIQUE),组合索引,总体划分为两类,主键索引也被称为聚簇索引(clustered index),其余都称呼为非主键索引也被称为二级索引(secondary index)。
三、InnoDB的不同的索引组织结构是怎样的呢?
众所周知在InnoDB引用的是B+树索引模型,这里对B+树结构暂时不做过多阐述,很多文章都有描述,在第二问中我们对索引的种类划分为两大类主键索引和非主键索引,那么问题就在于比较两种索引的区别了,我们这里建立一张学生表,其中包含字段id设置主键索引、name设置普通索引、age(无处理),并向数据库中插入4条数据:("小赵", 10)("小王", 11)("小李", 12)("小陈", 13)
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`name` varchar(32) COLLATE utf8_bin NOT NULL COMMENT '名称',
`age` int(3) unsigned NOT NULL DEFAULT '1' COMMENT '年龄',
PRIMARY KEY (`id`),
KEY `I_name` (`name`)
) ENGINE=InnoDB;
INSERT INTO student (name, age) VALUES("小赵", 10),("小王", 11),("小李", 12),("小陈", 13);
这里我们设置了主键为自增,那么此时数据库里数据为
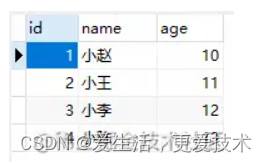
每一个索引在 InnoDB 里面对应一棵B+树,那么此时就存着两棵B+树。
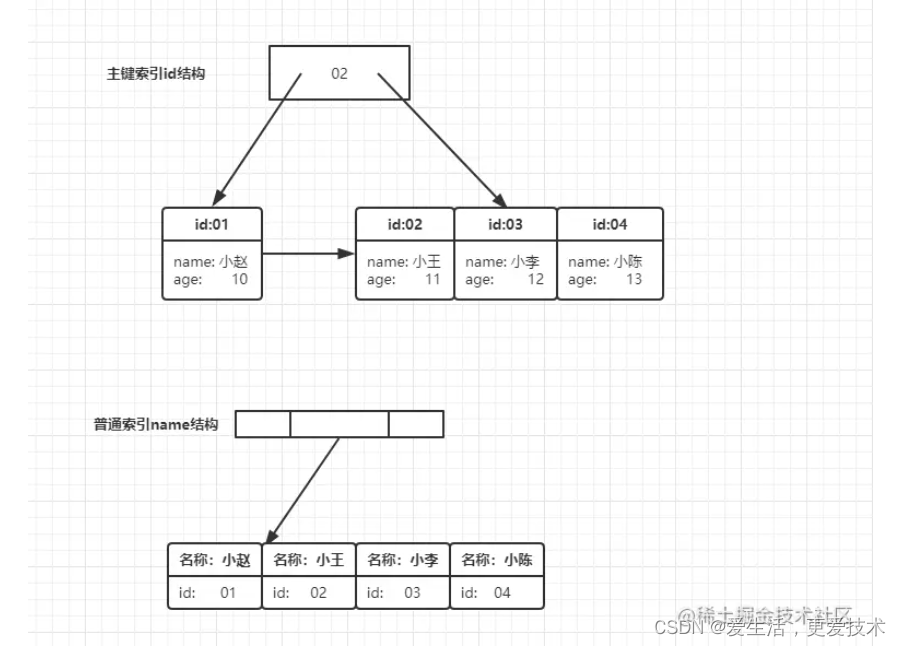
可以发现区别在与叶子节点中,主键索引存储了整行数据,而非主键索引中存储的值为主键id, 在我们执行如下sql后
SELECT age FROM student WHERE name = '小李';流程为:
- 在name索引树上找到名称为小李的节点 id为03
- 从id索引树上找到id为03的节点 获取所有数据
- 从数据中获取字段命为age的值返回 12 在流程中从非主键索引树搜索回到主键索引树搜索的过程称为:回表,在本次查询中因为查询结果只存在主键索引树中,我们必须回表才能查询到结果,那么如何优化这个过程呢?引入正文覆盖索引
四、什么是覆盖索引
覆盖索引(covering index ,或称为索引覆盖)即从非主键索引中就能查到的记录,而不需要查询主键索引中的记录,避免了回表的产生减少了树的搜索次数,显著提升性能。
五、如何使用是覆盖索引?
之前我们已经建立了表student,那么现在出现的业务需求中要求根据名称获取学生的年龄,并且该搜索场景非常频繁,那么先在我们删除掉之前以字段name建立的普通索引,以name和age两个字段建立联合索引,sql命令与建立后的索引树结构如下
ALTER TABLE student DROP INDEX I_name;
ALTER TABLE student ADD INDEX I_name_age(name, age);
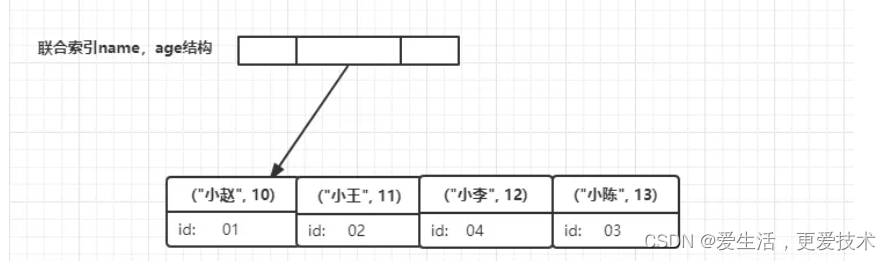
那在我们再次执行如下sql后
SELECT age FROM student WHERE name = '小李';
流程为:
- 在name,age联合索引树上找到名称为小李的节点
- 此时节点索引里包含信息age 直接返回 12
六、如何确定数据库成功使用了覆盖索引呢
当发起一个索引覆盖查询时,在explain的extra列可以看到using index的信息
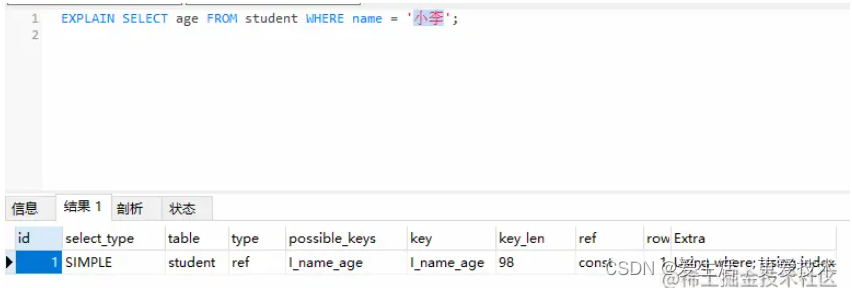
这里我们很清楚的看到Extra中Using index表明我们成功使用了覆盖索引
总结:
覆盖索引避免了回表现象的产生,从而减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是性能优化的一种手段,文章有不当之处,欢迎指正~