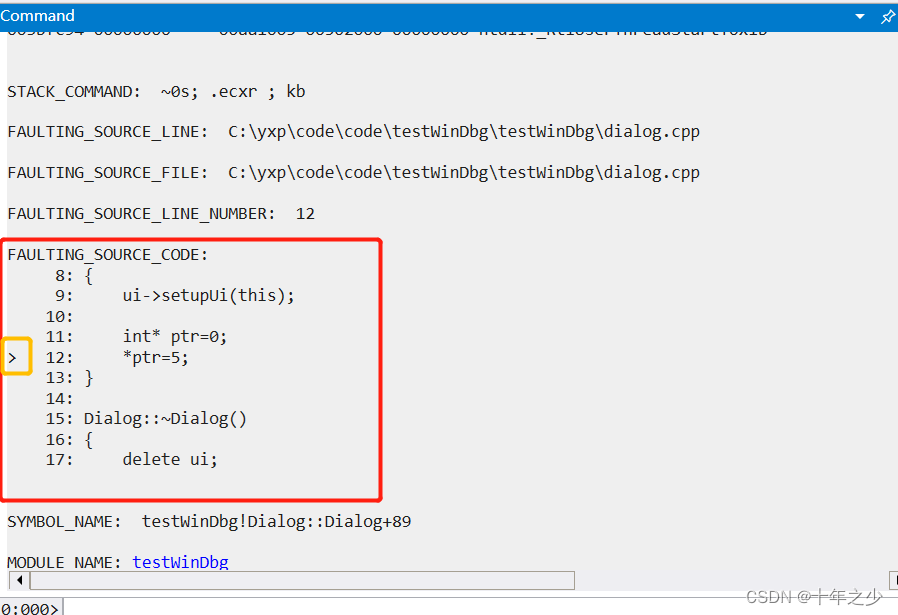
文章目录
- 一、快速开始
- 1.1 安装PaddleNLP并 加载数据集
- 1.2 数据预处理
- 1.3 加载预训练模型
- 1.4 设置评价指标和训练策略
- 1.5 模型训练与评估
- 1.6 模型预测
- 二、数据处理
- 2.1 整体介绍
- 2.2 加载内置数据集
- 2.3 自定义数据集
- 2.3.1 从本地文件创建数据集
- 2.3.2 paddle.io.Dataset/IterableDataset 创建数据集
- 2.3.3 从其他python对象创建数据集
- 2.4 数据处理
- 2.4.1 基于预训练模型的数据处理
- 2.4.1.1 Tokenizer
- 2.4.1.2 `map()`方法
- 2.4.1.3 Batchify
- 2.4.2 基于非预训练模型的数据处理
- 三、Transformer预训练模型
- 四、使用Trainer API进行训练
- 4.1 Trainer基本使用方法介绍
- 4.2 Trainer /TrainingArguments参数介绍
- 五、模型压缩
- 5.1 模型压缩简介
- 5.2 模型压缩快速启动示例
- 5.3 四步启动模型压缩
- 5.3.1获取模型压缩参数 compression_args
- 5.3.2 实例化 Trainer 并调用 compress
- 5.3.3实现自定义评估函数,以适配自定义压缩任务
- 5.3.4:传参并运行压缩脚本
- 5.3.5 CompressionArguments 参数介绍
- 5.4 模型评估与部署
- 5.5 模型压缩示例
- 5.5.1 Bi-LSTM知识蒸馏
- 5.5.2 BERT压缩
- 六、PaddleNLP Embedding API:预训练词向量
- 七、Taskflow API:PaddleNLP一键预测功能
- 八、Transformer高性能加速
- 九、实践案例
- 十、PaddleNLP常见问题汇总
- 10.1 NLP精选5问
- Q1.1 如何加载自己的本地数据集,以便使用PaddleNLP的功能?
- Q1.2 PaddleNLP会将内置的数据集、模型下载到默认路径,如何修改路径?
- Q1.3 PaddleNLP中如何保存、加载训练好的模型?
- Q1.4 当训练样本较少时,有什么推荐的方法能提升模型效果吗?
- Q1.5 如何提升模型的性能,提升QPS?
- 10.2 NLP通用问题
- Q2.1 数据类别分布不均衡, 有哪些应对方法?
- Q2.2 如果使用预训练模型,一般需要多少条样本?
- 10.3 PaddleNLP实战问题
- 10.3.1数据集和数据处理
- Q3.1 使用自己的数据集训练预训练模型时,如何引入额外的词表?
- 10.3.2模型训练调优
- Q3.2 如何加载自己的预训练模型,进而使用PaddleNLP的功能?
- Q3.3 如果训练中断,需要继续热启动训练,如何保证学习率和优化器能从中断地方继续迭代?
- Q3.4 如何冻结模型梯度?
- Q3.5 如何在eval阶段打印评价指标,在各epoch保存模型参数?
- Q3.6 训练过程中,训练程序意外退出或Hang住,应该如何排查?
- Q3.7 在模型验证和测试过程中,如何保证每一次的结果是相同的?
- Q3.8 ERNIE模型如何返回中间层的输出?
- 10.4 预测部署
- Q3.9 PaddleNLP训练好的模型如何部署到服务器 ?
- Q3.10 静态图模型如何转换成动态图模型?
- 10.5 特定模型和应用场景咨询
- Q4.1 【词法分析】LAC模型,如何自定义标签label,并继续训练?
- Q4.2 信息抽取任务中,是否推荐使用预训练模型+CRF,怎么实现呢?
- Q4.3.【阅读理解】`MapDatasets`的`map()`方法中对应的`batched=True`怎么理解,在阅读理解任务中为什么必须把参数`batched`设置为`True`?
- Q4.4 【语义匹配】语义索引和语义匹配有什么区别?
- Q4.5 【解语】wordtag模型如何自定义添加命名实体及对应词类?
- 10.6 其他使用咨询
- Q5.1 在CUDA11使用PaddlNLP报错?
- Q5.2 如何设置parameter?
- Q5.3 GPU版的Paddle虽然能在CPU上运行,但是必须要有GPU设备吗?
- Q5.4 如何指定用CPU还是GPU训练模型?
- Q5.5 动态图模型和静态图模型的预测结果一致吗?
- Q5.6 如何可视化acc、loss曲线图、模型网络结构图等?
全文参考 PaddleNLP官方文档
一、快速开始
参考:NLP文档《10分钟完成高精度中文情感分析》、NLP经典项目集02:使用预训练模型ERNIE优化情感分析
1.1 安装PaddleNLP并 加载数据集
安装相关过程和问题可以参考PaddleNLP的 安装文档
pip install --upgrade paddlenlp -i https://pypi.org/simple
PaddleNLP内置了适用于阅读理解、文本分类、序列标注、机器翻译等下游任务的多个数据集,这里我们使用公开中文情感分析数据集ChnSenticorp,包含7000多条正负向酒店评论数据,一键加载数据集,打印标签和前五条数据:
import paddlenlp as ppnlp
from paddlenlp.datasets import load_dataset
train_ds, dev_ds, test_ds = load_dataset(
"chnsenticorp", splits=["train", "dev", "test"])
print(train_ds.label_list)
for data in train_ds.data[:5]:
print(data)
['0', '1']
{'text': '选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。酒店装修一般,但还算整洁。 泳池在大堂的屋顶,因此很小,不过女儿倒是喜欢。 包的早餐是西式的,还算丰富。 服务吗,一般', 'label': 1, 'qid': ''}
{'text': '15.4寸笔记本的键盘确实爽,基本跟台式机差不多了,蛮喜欢数字小键盘,输数字特方便,样子也很美观,做工也相当不错', 'label': 1, 'qid': ''}
{'text': '房间太小。其他的都一般。。。。。。。。。', 'label': 0, 'qid': ''}
{'text': '1.接电源没有几分钟,电源适配器热的不行. 2.摄像头用不起来. 3.机盖的钢琴漆,手不能摸,一摸一个印. 4.硬盘分区不好办.', 'label': 0, 'qid': ''}
{'text': '今天才知道这书还有第6卷,真有点郁闷:为什么同一套书有两种版本呢?当当网是不是该跟出版社商量商量,单独出个第6卷,让我们的孩子不会有所遗憾。', 'label': 1, 'qid': ''}
可见每条数据包含一句评论和对应的标签,0代表负向评论,1代表正向评论。
1.2 数据预处理
- 加载tokenizer
PaddleNLP对于各种预训练模型已经内置了相应的tokenizer。指定想要使用的模型名字即可加载对应的tokenizer。这里我们使用预训练模型ERNIE:
# 设置想要使用模型的名称
MODEL_NAME = "ernie-1.0" # 也可使用'ernie-tiny'
tokenizer = ppnlp.transformers.ErnieTokenizer.from_pretrained(MODEL_NAME)
- 测试tokenizer效果
# 一行代码完成切分token,映射token ID以及拼接特殊token
encoded_text = tokenizer(text="请输入测试样例")
for key, value in encoded_text.items():
print("{}:\n\t{}".format(key, value))
# 使用paddle.to_tensor将input_ids 和token_type_ids转化成tensor格式
input_ids = paddle.to_tensor([encoded_text['input_ids']])
print("input_ids : {}".format(input_ids))
segment_ids = paddle.to_tensor([encoded_text['token_type_ids']])
print("token_type_ids : {}".format(segment_ids))
# 此时即可输入ERNIE模型中得到相应输出
sequence_output, pooled_output = ernie_model(input_ids, segment_ids)
print("Token wise output: {}, Pooled output: {}".format(sequence_output.shape, pooled_output.shape))
input_ids:
[1, 647, 789, 109, 558, 525, 314, 656, 2]
token_type_ids:
[0, 0, 0, 0, 0, 0, 0, 0, 0]
input_ids : Tensor(shape=[1, 9], dtype=int64, place=CUDAPlace(0), stop_gradient=True,
[[1 , 647, 789, 109, 558, 525, 314, 656, 2 ]])
token_type_ids : Tensor(shape=[1, 9], dtype=int64, place=CUDAPlace(0), stop_gradient=True,
[[0, 0, 0, 0, 0, 0, 0, 0, 0]])
Token wise output: [1, 9, 768], Pooled output: [1, 768]
sequence_output:对应每个输入token的语义特征表示,shape为(1, num_tokens, hidden_size)。其一般用于序列标注、问答等任务。pooled_output:对应整个句子的语义特征表示,shape为(1, hidden_size)。其一般用于文本分类、信息检索等任务。
- 数据处理
from functools import partial
from paddlenlp.data import Stack, Tuple, Pad
from utils import convert_example, create_dataloader
# 模型运行批处理大小
batch_size = 32
max_seq_length = 128
trans_func = partial(convert_example,tokenizer=tokenizer,max_seq_length=max_seq_length)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # segment
Stack(dtype="int64") # label
): [data for data in fn(samples)]
train_data_loader = create_dataloader(train_ds,batch_size=batch_size,
batchify_fn=batchify_fn,trans_fn=trans_func,mode='train')
dev_data_loader = create_dataloader(dev_ds,batch_size=batch_size,
batchify_fn=batchify_fn,trans_fn=trans_func,mode='dev')
1.3 加载预训练模型
PaddleNLP对于各种预训练模型已经内置了对于下游任务-文本分类的Fine-tune网络,情感分析本质是一个文本分类任务,在ERNIE模型后拼接上一个全连接网络(Full Connected)即可进行分类。
ernie_model = ppnlp.transformers.ErnieModel.from_pretrained(MODEL_NAME)
model = ppnlp.transformers.ErnieForSequenceClassification.from_pretrained(MODEL_NAME, num_classes=len(train_ds.label_list))
1.4 设置评价指标和训练策略
from paddlenlp.transformers import LinearDecayWithWarmup
learning_rate = 5e-5
epochs = 1 #3
warmup_proportion = 0.1 # 学习率预热比例
weight_decay = 0.01 # 权重衰减系数,类似模型正则项策略,避免模型过拟合
num_training_steps = len(train_data_loader) * epochs
lr_scheduler = LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
])
criterion = paddle.nn.loss.CrossEntropyLoss()
metric = paddle.metric.Accuracy()
1.5 模型训练与评估
模型训练的过程通常有以下步骤:
- 从dataloader中取出一个batch data
- 将batch data喂给model,做前向计算
- 将前向计算结果传给损失函数,计算loss。将前向计算结果传给评价方法,计算评价指标。
- loss反向回传,更新梯度。重复以上步骤。
每训练一个epoch时,程序将会评估一次,评估当前模型训练的效果。
!mkdir /home/aistudio/checkpoint # checkpoint文件夹用于保存训练模型
import paddle.nn.functional as F
from utils import evaluate
global_step = 0
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, segment_ids, labels = batch
logits = model(input_ids, segment_ids)
loss = criterion(logits, labels)
probs = F.softmax(logits, axis=1)
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
if global_step % 10 == 0 :
print("global step %d, epoch: %d, batch: %d, loss: %.5f, acc: %.5f" % (global_step, epoch, step, loss, acc))
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
evaluate(model, criterion, metric, dev_data_loader)
model.save_pretrained('/home/aistudio/checkpoint')
tokenizer.save_pretrained('/home/aistudio/checkpoint')
1.6 模型预测
调用predict()函数即可一键预测。
from utils import predict
data = [
{"text":'这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般'},
{"text":'怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片'},
{"text":'作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。'},
]
label_map = {0: 'negative', 1: 'positive'}
results = predict(
model, data, tokenizer, label_map, batch_size=batch_size)
for idx, text in enumerate(data):
print('Data: {} \t Lable: {}'.format(text, results[idx]))
更多预训练模型参考《Transformer预训练模型》,更多训练示例参考《PaddleNLP Examples》
二、数据处理
参考《数据处理》
2.1 整体介绍
- 核心API:
-
load_dataset():数据集快速加载接口,通过传入数据集读取脚本的名称和其他参数调用DatasetBuilder子类的相关方法加载数据集。 -
DatasetBuilder: DatasetBuilder 是一个基类,所有的内置数据集都继承自该类,该类的主要功能是下载和读取数据集文件并生成Dataset。贡献者可以通过重写_get_data()和_read()等方法向社区贡献数据集 -
MapDataset/IterDataset:PaddleNLP内置数据集类型,分别是对paddle.io.Dataset和paddle.io.IterableDataset的扩展。内置诸如map(),filter()等适用于NLP任务的数据处理功能。同时还能帮助用户简单创建自定义数据集。
- 数据处理流程设计
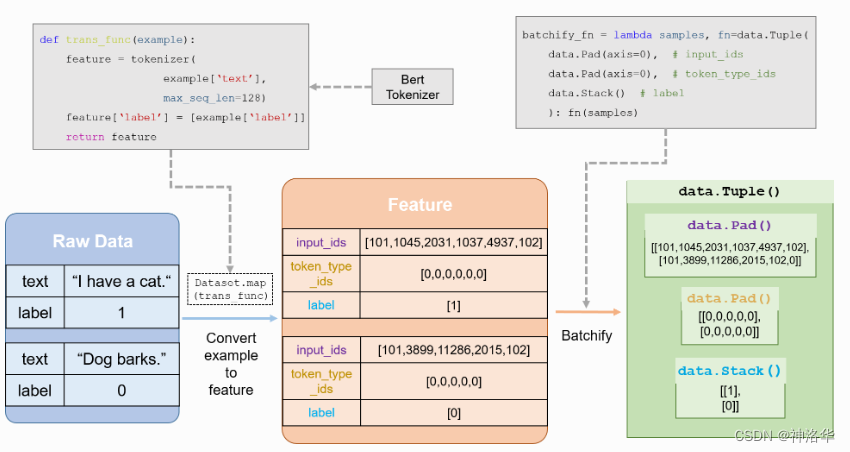
PaddleNLP的通用数据处理流程如下:
- 加载数据集(内置数据集或者自定义数据集,数据集返回 原始数据)。
- 定义
trans_func(),包括tokenize,token to id等操作,并传入数据集的map()方法,将原始数据转为 feature 。 - 根据上一步数据处理的结果定义
batchify方法和BatchSampler。 - 定义
DataLoader, 传入BatchSampler和batchify_fn()。
下面是基于Bert的文本分类任务的数据处理流程图:
2.2 加载内置数据集
- 快速加载内置数据集
目前PaddleNLP内置20余个NLP数据集,涵盖阅读理解,文本分类,序列标注,机器翻译等多项任务,可以通过PaddleNLP Datasets API来快速加载,实际使用时请根据需要添加splits信息。以 msra_ner 数据集为例:
from paddlenlp.datasets import load_dataset
train_ds, test_ds = load_dataset("msra_ner", splits=("train", "test"))
load_dataset() 方法会从 paddlenlp.datasets 下找到msra_ner数据集对应的数据读取脚本(默认路径:paddlenlp/datasets/msra_ner.py),并调用脚本中 DatasetBuilder 类的相关方法生成数据集。
生成数据集可以以 MapDataset 和 IterDataset 两种类型返回,分别是对 paddle.io.Dataset 和 paddle.io.IterableDataset 的扩展。返回类型通过 lazy 参数定义,Flase 对应返回 MapDataset (默认),True 对应返回 IterDataset。(关于 MapDataset 和 IterDataset 功能和异同可以参考API文档 datasets)
- 选择子数据集
有些数据集是很多子数据集的集合,每个子数据集都是一个独立的数据集。例如 GLUE 数据集就包含COLA, SST2, MRPC, QQP等10个子数据集。load_dataset() 方法提供了一个 name 参数用来指定想要获取的子数据集。使用方法如下:
from paddlenlp.datasets import load_dataset
train_ds, dev_ds = load_dataset("glue", name="cola", splits=("train", "dev"))
- 以内置数据集格式读取本地数据集
有的时候,我们希望使用数据格式与内置数据集相同的本地数据替换某些内置数据集的数据(例如参加SQuAD竞赛,对训练数据进行了数据增强)。 load_dataset() 方法提供的 data_files 参数可以实现这个功能。以 SQuAD 为例:
from paddlenlp.datasets import load_dataset
train_ds, dev_ds = load_dataset("squad", data_files=("my_train_file.json", "my_dev_file.json"))
test_ds = load_dataset("squad", data_files="my_test_file.json")
对于某些数据集,不同的split的读取方式不同。此时需要在 splits 参数中以传入与 data_files 一一对应 的split信息。此时 splits 不再代表选取的内置数据集,而代表以何种格式读取本地数据集。以 COLA 数据集为例:
from paddlenlp.datasets import load_dataset
train_ds, test_ds = load_dataset("glue", "cola", splits=["train", "test"], data_files=["my_train_file.csv", "my_test_file.csv"])
2.3 自定义数据集
2.3.1 从本地文件创建数据集
从本地文件创建数据集时,我们 推荐 根据本地数据集的格式给出读取function并传入 load_dataset() 中创建数据集。以 waybill_ie 快递单信息抽取任务中的数据为例:
from paddlenlp.datasets import load_dataset
def read(data_path):
with open(data_path, 'r', encoding='utf-8') as f:
# 跳过列名
next(f)
for line in f:
words, labels = line.strip('\n').split('\t')
words = words.split('\002')
labels = labels.split('\002')
yield {'tokens': words, 'labels': labels}
# data_path为read()方法的参数
map_ds = load_dataset(read, data_path='train.txt',lazy=False)
iter_ds = load_dataset(read, data_path='train.txt',lazy=True)
- 推荐将数据读取代码写成生成器(generator)的形式,这样可以更好的构建
MapDataset和IterDataset两种数据集,这两种数据集可以直接接入DataLoader用于模型训练。同时我们也推荐将单条数据写成字典的格式,这样可以更方便的监测数据流向。 MapDataset在绝大多数时候都可以满足要求。一般只有在数据集过于庞大无法一次性加载进内存的时候我们才考虑使用IterDataset。- 自定义数据读取
function中的参数可以直接以关键字参数的的方式传入load_dataset()中。而且对于自定义数据集,lazy参数是 必须 传入的。
2.3.2 paddle.io.Dataset/IterableDataset 创建数据集
有时我们希望更方便的使用一些数据处理(例如convert to feature, 数据清洗,数据增强等),此时可以使用 paddle.io.Dataset/IterableDataset 创建数据集,然后套上一层 MapDataset 或 IterDataset,就可以把原数据集转换成PaddleNLP的数据集。
from paddle.io import Dataset
from paddlenlp.datasets import MapDataset
class MyDataset(Dataset):
def __init__(self, path):
def load_data_from_source(path):
...
...
return data
self.data = load_data_from_source(path)
def __getitem__(self, idx):
return self.data[idx]
def __len__(self):
return len(self.data)
ds = MyDataset(data_path) # paddle.io.Dataset
new_ds = MapDataset(ds) # paddlenlp.datasets.MapDataset
2.3.3 从其他python对象创建数据集
理论上,我们可以使用任何包含 __getitem__() 方法和 __len__() 方法的python对象创建 MapDataset。包括 List ,Tuple ,DataFrame 等。只要将符合条件的python对象作为初始化参数传入 MapDataset 即可完成创建。
from paddlenlp.datasets import MapDataset
data_source_1 = [1,2,3,4,5]
data_source_2 = ('a', 'b', 'c', 'd')
list_ds = MapDataset(data_source_1)
tuple_ds = MapDataset(data_source_2)
print(list_ds[0]) # 1
print(tuple_ds[0]) # a
同样的,我们也可以使用包含 __iter__() 方法的python对象创建 IterDataset 。例如 List, Generator 等。创建方法与 MapDataset 相同。
list_ds = IterDataset(data_source_1)
gen_ds = IterDataset(data_source_2)
print([data for data in list_ds]) # ['a', 'b', 'c', 'd']
print([data for data in gen_ds]) # [0, 1, 2, 3, 4]
上例中直接将 生成器 对象传入
IterDataset所生成的数据集。其数据只能迭代 一次
我们也可以使用同样的方法从第三方数据集创建PaddleNLP数据集,例如HuggingFace Dataset:
from paddlenlp.datasets import MapDataset
from datasets import load_dataset
hf_train_ds = load_dataset('msra_ner', split='train')
print(type(train_ds)) # <class 'datasets.arrow_dataset.Dataset'>
train_ds = MapDataset(train_ds)
print(type(train_ds)) # <class 'paddlenlp.datasets.dataset.MapDataset'>
print(train_ds[2]) # {'id': '2',
# 'ner_tags': [0, 0, 0, 5, 0, 0, 5, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
# 0, 0, 0, 0, 0, 0, 5, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0],
# 'tokens': ['因', '有', '关', '日', '寇', '在', '京', '掠', '夺', '文', '物',
# '详', '情', ',', '藏', '界', '较', '为', '重', '视', ',', '也',
# '是', '我', '们', '收', '藏', '北', '京', '史', '料', '中', '的',
# '要', '件', '之', '一', '。']}
hf_train_ds = load_dataset('cmrc2018', split='train')
train_ds = MapDataset(hf_train_ds)
print(train_ds[1818]) # {'answers': {'answer_start': [9], 'text': ['字仲可']},
# 'context': '徐珂(),原名昌,字仲可,浙江杭县(今属杭州市)人。光绪举人。
# 后任商务印书馆编辑。参加南社。1901年在上海担任了《外交报》、
# 《东方杂志》的编辑,1911年,接管《东方杂志》的“杂纂部”。与潘仕成、
# 王晋卿、王辑塘、冒鹤亭等友好。编有《清稗类钞》、《历代白话诗选》、
# 《古今词选集评》等。光绪十五年(1889年)举人。后任商务印书馆编辑。
# 参加南社。曾担任袁世凯在天津小站练兵时的幕僚,不久离去。',
# 'id': 'TRAIN_113_QUERY_0',
# 'question': '徐珂字什么?'}
hf_train_ds = load_dataset('glue', 'sst2', split='train')
train_ds = MapDataset(hf_train_ds)
print(train_ds[0]) # {'idx': 0, 'label': 0, 'sentence': 'hide new secretions from the parental units '}
hf_train_ds = load_dataset('ptb_text_only', split='train')
train_ds = MapDataset(hf_train_ds)
print(train_ds[1]) # {'sentence': 'pierre <unk> N years old will join the board as a nonexecutive director nov. N'}
2.4 数据处理
Dataset中通常为原始数据,需要经过一定的数据处理并进行采样组batch,而后通过 paddle.io.DataLoader 加载,为训练或预测使用,PaddleNLP中为其中各环节提供了相应的功能支持。
2.4.1 基于预训练模型的数据处理
2.4.1.1 Tokenizer
在使用预训练模型做NLP任务时,需要加载对应的Tokenizer,PaddleNLP在 PreTrainedTokenizer 中内置的 __call__() 方法可以实现基础的数据处理功能。PaddleNLP内置的所有预训练模型的Tokenizer都继承自 PreTrainedTokenizer ,下面以BertTokenizer举例说明:
from paddlenlp.transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
# 单句转换(单条数据)
print(tokenizer(text='天气不错')) # {'input_ids': [101, 1921, 3698, 679, 7231, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0]}
# 句对转换(单条数据)
print(tokenizer(text='天气',text_pair='不错')) # {'input_ids': [101, 1921, 3698, 102, 679, 7231, 102], 'token_type_ids': [0, 0, 0, 0, 1, 1, 1]}
# 单句转换(多条数据)
print(tokenizer(text=['天气','不错'])) # [{'input_ids': [101, 1921, 3698, 102], 'token_type_ids': [0, 0, 0, 0]},
# {'input_ids': [101, 679, 7231, 102], 'token_type_ids': [0, 0, 0, 0]}]
关于
__call__()方法的其他参数和功能,请查阅PreTrainedTokenizer
2.4.1.2 map()方法
MapDataset 的 map() 方法支持传入一个函数,对数据集内的数据进行统一转换。下面我们以 LCQMC 的数据处理流程为例:
from paddlenlp.transformers import BertTokenizer
from paddlenlp.datasets import load_dataset
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
train_ds = load_dataset('lcqmc', splits='train')
print(train_ds[0]) # {'query': '喜欢打篮球的男生喜欢什么样的女生', 'title': '爱打篮球的男生喜欢什么样的女生', 'label': 1}
可以看到,LCQMC 是一个句对匹配任务,即判断两个句子的意思是否相似的2分类任务。下面编写基于 PreTrainedTokenizer 的数据处理函数并传入数据集的 map() 方法。
from functools import partial
def convert_example(example, tokenizer):
tokenized_example = tokenizer(text=example['query'],text_pair=example['title'])
tokenized_example['label'] = [example['label']] # 加上label用于训练
return tokenized_example
trans_func = partial(convert_example,tokenizer=tokenizer)
train_ds.map(trans_func)
print(train_ds[0]) # {'input_ids': [101, 1599, 3614, 2802, 5074, 4413, 4638, 4511, 4495,
# 1599, 3614, 784, 720, 3416, 4638, 1957, 4495, 102,
# 4263, 2802, 5074, 4413, 4638, 4511, 4495, 1599, 3614,
# 784, 720, 3416, 4638, 1957, 4495, 102],
# 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
# 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
# 'label': [1]}
可以看到,数据集中的文本数据已经被处理成了模型可以接受的 feature 。
- batched参数
map()方法有一个重要的参数batched,当设置为 True 时(默认为 False ),数据处理函数trans_func()的输入不再是单条数据,而是数据集的所有数据,这样数据处理就更快。
from functools import partial
def convert_examples(examples, tokenizer):
querys = [example['query'] for example in examples]
titles = [example['title'] for example in examples]
tokenized_examples = tokenizer(text=querys, text_pair=titles,return_dict=False)
# 加上label用于训练
for idx in range(len(tokenized_examples)):
tokenized_examples[idx]['label'] = [examples[idx]['label']]
return tokenized_examples
trans_func = partial(convert_examples, tokenizer=tokenizer)
train_ds.map(trans_func, batched=True)
print(train_ds[0]) # {'input_ids': [101, 1599, 3614, 2802, 5074, 4413, 4638, 4511, 4495,
# 1599, 3614, 784, 720, 3416, 4638, 1957, 4495, 102,
# 4263, 2802, 5074, 4413, 4638, 4511, 4495, 1599, 3614,
# 784, 720, 3416, 4638, 1957, 4495, 102],
# 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
# 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
# 'label': [1]}
在本例中两种实现的结果是相同的。但是在诸如阅读理解,对话等任务中,一条原始数据可能会产生多个 feature 的情况(参见 run_squad.py )通常需要将 batched 参数设置为 True 。
- num_workers 参数:用于多进程数据处理,可以提高处理速度。但如果在数据处理的函数中用到了 数据index 的相关信息,多进程处理可能会导致错误的结果
- 关于
map()方法的其他参数和paddlenlp.datasets.MapDataset的其他数据处理方法,请查阅 dataset 。
2.4.1.3 Batchify
PaddleNLP内置了多种collate function,配合 paddle.io.BatchSampler 可以协助用户简单的完成组batch的操作。
我们继续以 LCQMC 的数据处理流程为例。从上一节最后可以看到,处理后的单条数据是一个 字典 ,包含 input_ids , token_type_ids 和 label 三个key。其中 input_ids 和 token_type_ids 是需要进行 padding 操作后输入模型的,而 label 是需要 stack 之后传入loss function的。
因此,我们使用PaddleNLP内置的 Dict() ,Stack() 和 Pad() 函数整理batch中的数据。最终的 batchify_fn() 如下:
from paddlenlp.data import Dict, Stack, Pad
# 使用Dict函数将Pad,Stack等函数与数据中的键值相匹配
train_batchify_fn = lambda samples, fn=Dict({
'input_ids': Pad(axis=0, pad_val=tokenizer.pad_token_id),
'token_type_ids': Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
'label': Stack(dtype="int64")
}): fn(samples)
之后使用 paddle.io.BatchSampler 和 batchify_fn() 构建 paddle.io.DataLoader :
from paddle.io import DataLoader, BatchSampler
train_batch_sampler = BatchSampler(train_ds, batch_size=2, shuffle=True)
train_data_loader = DataLoader(dataset=train_ds, batch_sampler=train_batch_sampler, collate_fn=train_batchify_fn)
到此,一个完整的数据准备流程就完成了。关于更多batchify方法,请查阅 collate。
- 当需要进行 单机多卡 训练时,需要将
BatchSampler更换为DistributedBatchSampler。更多有关 paddle.io.BatchSampler 的信息,请查阅 BatchSampler。
- 当需要诸如batch内排序,按token组batch等更复杂的组batch功能时。可以使用PaddleNLP内置的
SamplerHelper。相关用例请参考 reader.py。
2.4.2 基于非预训练模型的数据处理
使用非预训练模型做NLP任务时,我们可以借助PaddleNLP内置的 JiebaTokenizer 和 Vocab 完成数据处理的相关功能,整体流程与使用预训练模型基本相似。我们以中文情感分析 ChnSentiCorp 数据集为例:
from paddlenlp.data import JiebaTokenizer, Vocab
from paddlenlp.datasets import load_dataset
train_ds = load_dataset('chnsenticorp', splits='train')
print(train_ds[0]) # {'text': '选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。
# 酒店装修一般,但还算整洁。 泳池在大堂的屋顶,因此很小,不过女儿倒是喜欢。 包的早餐是西式的,还算丰富。
# 服务吗,一般', 'label': 1}
# 从本地词典文件构建Vocab
vocab = Vocab.load_vocabulary('./senta_word_dict.txt', unk_token='[UNK]', pad_token='[PAD]')
# 使用Vocab初始化JiebaTokenizer
tokenizer = JiebaTokenizer(vocab)
- Vocab 除了可以从本地词典文件初始化之外,还提供多种初始化方法,包括从
dictionary创建、从数据集创建等。详情请查阅Vocab。- 除了使用内置的
JiebaTokenizer外,用户还可以使用任何自定义的方式或第三方库进行分词,之后使用Vocab.to_indices()方法将token转为id。
之后与基于预训练模型的数据处理流程相似,编写数据处理函数并传入 map() 方法:
def convert_example(example, tokenizer):
input_ids = tokenizer.encode(example["text"])
valid_length = [len(input_ids)]
label = [example["label"]]
return input_ids, valid_length, label
trans_fn = partial(convert_example, tokenizer=tokenizer)
train_ds.map(trans_fn)
print(train_ds[0]) # ([417329, 128448, 140437, 173188, 118001, 213058, 595790, 1106339, 940533, 947744, 169206,
# 421258, 908089, 982848, 1106339, 35413, 1055821, 4782, 377145, 4782, 238721, 4782, 642263,
# 4782, 891683, 767091, 4783, 672971, 774154, 1250380, 1106339, 340363, 146708, 1081122,
# 4783, 1, 943329, 1008467, 319839, 173188, 909097, 1106339, 1010656, 261577, 1110707,
# 1106339, 770761, 597037, 1068649, 850865, 4783, 1, 993848, 173188, 689611, 1057229, 1239193,
# 173188, 1106339, 146708, 427691, 4783, 1, 724601, 179582, 1106339, 1250380],
# [67],
# [1])
可以看到,原始数据已经被处理成了 feature 。但是这里我们发现单条数据并不是一个 字典 ,而是 元组 。所以我们的 batchify_fn() 也要相应的做一些调整:
from paddlenlp.data import Tuple, Stack, Pad
# 使用Tuple函数将Pad,Stack等函数与数据中的键值相匹配
train_batchify_fn = lambda samples, fn=Tuple((
Pad(axis=0, pad_val=vocab.token_to_idx.get('[PAD]', 0)), # input_ids
Stack(dtype="int64"), # seq len
Stack(dtype="int64") # label
)): fn(samples)
可以看到,Dict() 函数是将单条数据中的键值与 Pad() 等函数进行对应,适用于单条数据是字典的情况。而 Tuple() 是通过单条数据中不同部分的index进行对应的。所以需要 注意 的是 convert_example() 方法和 batchify_fn() 方法的匹配。之后的流程与基于预训练模型的数据处理相同。
三、Transformer预训练模型
参考文档《PaddleNLP Transformer预训练模型》
PaddleNLP Transformer API提供了丰富的预训练模型,使用Auto模块,就可以加载不同网络结构的预训练模型,以及下游任务Fine-tuning。
- 加载数据集
- 通过
from_pretrained()方法加载预训练模型: Auto模块(包括AutoModel, AutoTokenizer, 及各种下游任务类)提供了方便易用的接口, 无需指定类别,即可调用不同网络结构的预训练模型。 第一个参数是汇总表中对应的Pretrained Weight,可加载对应的预训练权重。 AutoModelForSequenceClassification 初始化__init__所需的其他参数,如 num_classes 等, 也是通过 from_pretrained() 传入。Tokenizer 使用同样的from_pretrained方法加载。 - 通过 Dataset 的
map函数,使用 tokenizer 将 dataset 从原始文本处理成模型的输入。 - 定义
BatchSampler和DataLoader,组合Batch。 - 定义训练所需的优化器,loss函数等,就可以开始进行模型fine-tune任务。
import paddle
from functools import partial
import numpy as np
from paddlenlp.datasets import load_dataset
from paddlenlp.transformers import AutoModelForSequenceClassification, AutoTokenizer
train_ds = load_dataset("chnsenticorp", splits=["train"])
model = AutoModelForSequenceClassification.from_pretrained("bert-wwm-chinese", num_classes=len(train_ds.label_list))
tokenizer = AutoTokenizer.from_pretrained("bert-wwm-chinese")
def convert_example(example, tokenizer):
encoded_inputs = tokenizer(text=example["text"], max_seq_len=512, pad_to_max_seq_len=True)
return tuple([np.array(x, dtype="int64") for x in [
encoded_inputs["input_ids"], encoded_inputs["token_type_ids"], [example["label"]]]])
train_ds = train_ds.map(partial(convert_example, tokenizer=tokenizer))
batch_sampler = paddle.io.BatchSampler(dataset=train_ds, batch_size=8, shuffle=True)
train_data_loader = paddle.io.DataLoader(dataset=train_ds, batch_sampler=batch_sampler, return_list=True)
optimizer = paddle.optimizer.AdamW(learning_rate=0.001, parameters=model.parameters())
criterion = paddle.nn.loss.CrossEntropyLoss()
for input_ids, token_type_ids, labels in train_data_loader():
logits = model(input_ids, token_type_ids)
loss = criterion(logits, labels)
loss.backward()
optimizer.step()
optimizer.clear_grad()
上面的代码给出使用预训练模型的简要示例,更完整详细的示例代码, 可以参考:使用预训练模型Fine-tune完成中文文本分类任务
PaddleNLP的Transformer预训练模型包含从 huggingface.co 直接转换的模型权重和百度自研模型权重,方便社区用户直接迁移使用。 目前共包含了40多个主流预训练模型,500多个模型权重,详见Transformer预训练模型汇总。
四、使用Trainer API进行训练
参考文档《PaddleNLP Trainer API》
PaddleNLP提供了Trainer训练API,针对训练过程的通用训练配置做了封装,比如:
- 优化器、学习率调度等训练配置
- 多卡,混合精度,梯度累积等功能
- checkpoint断点,断点重启(数据集,随机数恢复)
- 日志显示,loss可视化展示等
4.1 Trainer基本使用方法介绍
用户输入模型,数据集,就可以使用Trainer API高效快速的实现预训练、微调等任务。下面以中文情感分类数据集chnsenticorp为例。
- 导入需要用到的头文件:模型、Tokenizer、Trainer组件
- 其中
Trainer是训练主要入口,用户传入模型,数据集,即可进行训练 TrainingArguments包含了用户需要的大部分训练参数。PdArgumentParser是用户输出参数的工具
- 其中
from functools import partial
import paddle
from paddlenlp.datasets import load_dataset
from paddlenlp.transformers import AutoModelForSequenceClassification, AutoTokenizer
from paddlenlp.trainer import Trainer, TrainingArguments, PdArgumentParser
- 设置好用户参数
-
PdArgumentParser可以接受多个类似TrainingArguments的参数。用户可以自定义所需要的ModelArguments,DataArguments,然后以tuple传入PdArgumentParser即可。 -
这些参数都是通过python xxx.py --dataset xx --max_seq_length xx的方式传入。
TrainingArguments的所有可配置参数见后文。
from dataclasses import dataclass
@dataclass
class DataArguments:
dataset: str = field(
default=None,
metadata={"help": "The name of the dataset to use."})
max_seq_length: int = field(
default=128,
metadata={"help": "The maximum total input sequence length after tokenization."})
parser = PdArgumentParser(TrainingArguments, DataArguments)
(training_args, data_args) = parser.parse_args_into_dataclasses()
- 加载模型,tokenizer, 数据集
- 数据集需要输出的是一个dict。dict中的key,需要和模型的输入名称对应。
- labels如果模型没有使用到,我们还需要额外定义criterion,计算最后的loss损失。
train_dataset = load_dataset("chnsenticorp", splits=["train"])
model = AutoModelForSequenceClassification.from_pretrained("ernie-3.0-medium-zh", num_classes=len(train_dataset.label_list))
tokenizer = AutoTokenizer.from_pretrained("ernie-3.0-medium-zh")
def convert_example(example, tokenizer):
encoded_inputs = tokenizer(text=example["text"], max_seq_len=128, pad_to_max_seq_len=True)
encoded_inputs["labels"] = int(example["label"])
return encoded_inputs
train_dataset = train_dataset.map(partial(convert_example, tokenizer=tokenizer))
-
构造Trainer实例,进行模型训练。
- 这里传入model,criterion,args,train_dataset,tokenizer这些训练需要的组件,构建了实例化的trainer
- 使用
trainer.train()接口开始训练过程。训练完成后,可以保存模型,保存一些日志。
trainer = Trainer(
model=model,
criterion=paddle.nn.loss.CrossEntropyLoss(),
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
tokenizer=tokenizer)
if training_args.do_train:
train_result = trainer.train()
metrics = train_result.metrics
trainer.save_model()
trainer.log_metrics("train", metrics)
trainer.save_state()
预训练的使用方式可以参考ERNIE-1.0 Trainer版本
4.2 Trainer /TrainingArguments参数介绍
Trainer参数:
-
model([
PretrainedModel] 或paddle.nn.Layer,可选):用于训练、评估或预测的模型。
[Trainer] 对PaddleNLP的 [PretrainedModel] 一起使用进行了优化。你仍然可以使用您自己的模型定义为paddle.nn.Layer,只要它们的工作方式与 PaddleNLP 模型相同。 -
criterion (
paddle.nn.Layer,可选):
model可能只输出中间结果loggit,如果想对模型的输出做更多的计算,可以添加criterion层。 -
args([
TrainingArguments],可选):训练时需要用到的参数。将默认使用 [TrainingArguments] 初始化。output_dir设置为当前目录中名为tmp_trainer的目录(如果未提供)。 -
([
TrainingArguments], optional):训练参数,默认为[TrainingArgument]的基本实例。如果未提供,则将output_dir设置为当前目录中名为tmp_trainer的目录。 -
data_collator(
DataCollator,可选):用于将train_dataset或eval_dataset的数据,组合为batch的函数。如果没有提供tokenizer,则默认为 [default_data_collator], 否则为[DataCollatorWithPadding]。 -
train_dataset(
paddle.io.Dataset或paddle.io.IterableDataset,可选):用于训练的数据集。如果是datasets.Dataset,那么model.forward()不需要的输入字段会被自动删除。 -
eval_dataset(
paddle.io.Dataset,可选):用于评估的数据集。如果是datasets.Dataset,那么model.forward()不需要的输入字段会被自动删除。 -
tokenizer([
PretrainedTokenizer],可选):用于数据预处理的tokenizer。如果传入,将用于自动Pad输入batch输入的最大长度,它随模型保存,可以重新运行中断的训练过程。 -
compute_metrics (
Callable[[EvalPrediction], Dict], 可选):用于评估的计算指标的函数。必须采用 [EvalPrediction] 并返回dict形式的metrics结果。 -
callbacks (List of [
TrainerCallback],可选):用于自定义训练call列表函数。将这些函数会被添加到默认回调函数列表。如果要删除使用的回调函数,请使用 [Trainer.remove_callback] 方法。 -
optimizers (
Tuple[paddle.optimizer.Optimizer, paddle.optimizer.lr.LRScheduler], 可选):一个tuple, 包含要使用Optimizer和LRScheduler,默认为 [AdamW] 实例和LinearDecayWithWarmup。 -
preprocess_logits_for_metrics (
Callable[[paddle.Tensor, paddle.Tensor], paddle.Tensor], 可选)):
一个函数, 在每次评估之前对logits进行预处理。
TrainingArguments 参数
--output_dir
保存模型输出和和中间checkpoints的输出目录。(`str`, 必须, 默认为 `None`)
The output directory where the model predictions and
checkpoints will be written. (default: None)
--overwrite_output_dir
如果 `True`,覆盖输出目录的内容。如果 `output_dir` 指向检查点
目录,则使用它继续训练。(`bool`, 可选, 默认为 `False`)
Overwrite the content of the output directory. Use
this to continue training if output_dir points to a
checkpoint directory. (default: False)
--do_train
是否进行训练任务。 注:`Trainer`不直接使用此参数,而是提供给用户
的训练/评估脚本使用。(`bool`, 可选, 默认为 `False`)
Whether to run training. (default: False)
--do_eval
是否进行评估任务。同上。(`bool`, 可选, 默认为 `False`)
Whether to run eval on the dev set. (default: False)
--do_predict
是否进行预测任务。同上。(`bool`, 可选, 默认为 `False`)
Whether to run predictions on the test set. (default:False)
--do_export
是否进行模型导出任务。同上。(`bool`, 可选, 默认为 `False`)
Whether to export infernece model. (default: False)
--evaluation_strategy {no,steps,epoch}
评估策略,(`str`, 可选,默认为 `"no"`):
训练期间采用的评估策略。可能的值为:
- `"no"`:训练期间不进行评估。
- `"steps"`:评估在每个`eval_steps`完成(并记录)。
- `"epoch"`:在每个 epoch 结束时进行评估。
The evaluation strategy to use. (default: no)
--prediction_loss_only
在执行评估和预测任务时,只返回loss的值。(`bool`, 可选, 默认为 `False`)
When performing evaluation and predictions, only
returns the loss. (default: False)
--per_device_train_batch_size
用于训练的每个 GPU 核心/CPU 的batch大小.(`int`,可选,默认为 8)
Batch size per GPU core/CPU for training. (default: 8)
--per_device_eval_batch_size
用于评估的每个 GPU 核心/CPU 的batch大小.(`int`,可选,默认为 8)
Batch size per GPU core/CPU for evaluation. (default:8)
--gradient_accumulation_steps
在执行反向,更新回传梯度之前,累积梯度的更新步骤数(`int`,可选,默认为 1)
Number of updates steps to accumulate before
performing a backward/update pass. (default: 1)
--learning_rate
优化器的初始学习率, (`float`,可选,默认为 5e-05)
The initial learning rate for optimizer. (default: 5e-05)
--weight_decay
除了所有bias和 LayerNorm 权重之外,应用于所有层的权重衰减数值。(`float`,可选,默认为 0.0)
Weight decay for AdamW if we apply some. (default:
0.0)
--adam_beta1
AdamW的优化器的 beta1 超参数。(`float`,可选,默认为 0.9)
Beta1 for AdamW optimizer (default: 0.9)
--adam_beta2
AdamW的优化器的 beta2 超参数。(`float`,可选,默认为 0.999)
Beta2 for AdamW optimizer (default: 0.999)
--adam_epsilon
AdamW的优化器的 epsilon 超参数。(`float`,可选,默认为 1e-8)
Epsilon for AdamW optimizer. (default: 1e-08)
--max_grad_norm
最大梯度范数(用于梯度裁剪)。(`float`,可选,默认为 1.0)
Max gradient norm. (default: 1.0)
--num_train_epochs
要执行的训练 epoch 总数(如果不是整数,将在停止训练
之前执行最后一个 epoch 的小数部分百分比)。
(`float`, 可选, 默认为 3.0):
Total number of training epochs to perform. (default:3.0)
--max_steps
如果设置为正数,则表示要执行的训练步骤总数。
覆盖`num_train_epochs`。(`int`,可选,默认为 -1)
If > 0: set total number of training steps to
perform.Override num_train_epochs. (default: -1
--lr_scheduler_type
要使用的学习率调度策略。 (`str`, 可选, 默认为 `"linear"`)
The scheduler type to use. (default: linear) 支持,linear, cosine, constant, constant_with_warmup.
--warmup_ratio
用于从 0 到 `learning_rate` 的线性warmup的总训练步骤的比例。(`float`,可选,默认为 0.0)
Linear warmup over warmup_ratio fraction of total
steps. (default: 0.0)
--warmup_steps
用于从 0 到 `learning_rate` 的线性warmup的步数。覆盖warmup_ratio参数。
(`int`,可选,默认为 0)
Linear warmup over warmup_steps. (default: 0)
--log_on_each_node
在多节点分布式训练中,是在每个节点上记录一次,还是仅在主节点上记录节点。(`bool`,可选,默认为`True`)
When doing a multinode distributed training, whether
to log once per node or just once on the main node.
(default: True)
--logging_dir
VisualDL日志目录。(`str`,可选,默认为None)
None情况下会修改为 *output_dir/runs/**CURRENT_DATETIME_HOSTNAME**
VisualDL log dir. (default: None)
--logging_strategy {no,steps,epoch}
(`str`, 可选,默认为 `"steps"`)
训练期间采用的日志记录策略。可能的值为:
- `"no"`:训练期间不进行记录。
- `"epoch"`:记录在每个 epoch 结束时完成。
- `"steps"`:记录是每 `logging_steps` 完成的。
The logging strategy to use. (default: steps)
--logging_first_step
是否记录和评估第一个 `global_step`。(`bool`,可选,默认为`False`)
Log the first global_step (default: False)
--logging_steps
如果 `logging_strategy="steps"`,则两个日志之间的更新步骤数。
(`int`,可选,默认为 500)
Log every X updates steps. (default: 500)
--save_strategy {no,steps,epoch}
(`str`, 可选,默认为 `"steps"`)
训练期间采用的checkpoint保存策略。可能的值为:
- `"no"`:训练期间不保存。
- `"epoch"`:保存在每个 epoch 结束时完成。
- `"steps"`:保存是每`save_steps`完成。
The checkpoint save strategy to use. (default: steps)
--save_steps
如果 `save_strategy="steps"`,则在两个checkpoint保存之间的更新步骤数。
(`int`,可选,默认为 500)
Save checkpoint every X updates steps. (default: 500)
--save_total_limit
如果设置次参数,将限制checkpoint的总数。删除旧的checkpoints
`输出目录`。(`int`,可选)
Limit the total amount of checkpoints. Deletes the
older checkpoints in the output_dir. Default is
unlimited checkpoints (default: None)
--save_on_each_node
在做多节点分布式训练时,是在每个节点上保存模型和checkpoints,
还是只在主节点上。当不同的节点使用相同的存储时,不应激活此功能,
因为每个节点的文件将以相同的名称保存。(`bool`, 可选, 默认为 `False`)
When doing multi-node distributed training, whether to
save models and checkpoints on each node, or only on
the main one (default: False)
--no_cuda
是否不使用 CUDA,即使CUDA环境可用。(`bool`, 可选, 默认为 `False`)
Do not use CUDA even when it is available (default:
False)
--seed
设置的随机种子。为确保多次运行的可复现性。(`int`,可选,默认为 42)
Random seed that will be set at the beginning of
training. (default: 42)
--bf16
是否使用 bf16 混合精度训练而不是 fp32 训练。需要 Ampere 或更高的 NVIDIA
显卡架构支持。这是实验性质的API,以后可能会修改。
(`bool`, 可选, 默认为 `False`)
Whether to use bf16 (mixed) precision instead of
32-bit. Requires Ampere or higher NVIDIA architecture.
This is an experimental API and it may change.
(default: False)
--fp16
是否使用 fp16 混合精度训练而不是 fp32 训练。
(`bool`, 可选, 默认为 `False`)
Whether to use fp16 (mixed) precision instead of
32-bit (default: False)
--fp16_opt_level
混合精度训练模式,可为``O1``或``O2``模式,默认``O1``模式,默认O1.
O1表示混合精度训练,O2表示纯fp16/bf16训练。
只在fp16或bf16选项开启时候生效.
(`str`, 可选, 默认为 `O1`)
For fp16: AMP optimization level selected in
['O0', 'O1', and 'O2']. See details at https://www.pad
dlepaddle.org.cn/documentation/docs/zh/develop/api/pad
dle/amp/auto_cast_cn.html (default: O1)
--scale_loss
fp16/bf16训练时,scale_loss的初始值。
(`float`,可选,默认为 32768)
The value of initial scale_loss for fp16. (default: 32768)
--sharding
是否使用Paddle的Sharding数据并行功能,用户的参数。支持sharding `stage1`, `stage2` or `stage3`。
其中`stage2``stage3`可以和`offload`组合使用。
每个种策略分别为:
stage1 : optimizer 中的参数切分到不同卡
stage2 : optimizer + gradient 中的参数切分到不同卡
stage3 : parameter + gradient + optimizer 中的参数都切分到不同卡
offload : offload parameters to cpu 部分参数存放到cpu中
(`str`, 可选, 默认为 `` 不使用sharding)
注意:当前stage3暂时不可用
Whether or not to use Paddle Sharding Data Parallel training (in distributed training
only). The base option should be `stage1`, `stage2` or `stage3` and you can add
CPU-offload to `stage2` or `stage3` like this: `stage2 offload` or `stage3 offload`.
Each stage means:
stage1 : optimizer state segmentation
stage2 : optimizer state + gradient segmentation
stage3 : parameter + gradient + optimizer state segmentation
offload : offload parameters to cpu
NOTICE: stage3 is temporarily unavaliable.
--sharding_degree
设置sharding的通信组参数,表示通信组的大小。同一个sharding通信组内的参数,进行sharding,分布到不同卡上。
不同sharding通信组之间,相当于单纯的数据并行。此选项只在sharding选项开启时候生效。
默认值为-1,表示所有训练的卡在同一个通信组内。
(`int`, 可选, 默认为 `-1`)
Sharding parameter in certain cards group. For example, aussume we use 2 machines each
with 8 cards, then set sharding_degree=8, sharding will only communication inside machine.
default -1 means sharding parameters between all workers. (`int`, *optional*, defaults to `-1`)
--recompute
是否使用重计算训练。可以节省显存。
重新计算前向过程以获取梯度,减少中间变量显存.
注:需要组网支持 recompute,默认使用 enable_recompute 关键字作为recompute功能开关。
(`bool`, 可选, 默认为 `False`)
Recompute the forward pass to calculate gradients. Used for saving memory (default: False)
--minimum_eval_times
最少评估次数,如果当前设置的eval_steps,评估次数少于minimum_eval_times,
此选项会覆盖eval_steps参数。
(`int`,可选,默认为 None)
If under eval_steps, the valid time is less then
minimum_eval_times, the config of override eval_steps.
(default: None)
--local_rank
分布式训练时,设备的本地rank值。
For distributed training: local_rank (default: -1)
--dataloader_drop_last
是否丢弃最后一个不完整的批次(如果数据集的长度不能被批次大小整除)
(`bool`,可选,默认为 False)
Drop the last incomplete batch if it is not divisible
by the batch size. (default: False)
--eval_steps
如果 `evaluation_strategy="steps"`,则两次评估之间的更新步骤数。将默认为相同如果未设置,则值为 `logging_steps`。
(`int`,可选,默认为 None)
Run an evaluation every X steps. (default: None)
--dataloader_num_workers
用于数据加载的子进程数。 0 表示数据将在主进程制造。
(`int`,可选,默认为 0)
Number of subprocesses to use for data loading. 0 means
that the data will be loaded in the main process. (default: 0)
--past_index
If >=0, uses the corresponding part of the output as
the past state for next step. (default: -1)
--run_name
An optional descriptor for the run. (default: None)
--device
运行的设备名称。支持cpu/gpu, 默认gpu
(`str`,可选,默认为 'gpu')
select cpu, gpu, xpu devices. (default: gpu)
--disable_tqdm
是否使用tqdm进度条
Whether or not to disable the tqdm progress bars.
(default: None)
--remove_unused_columns
去除Dataset中不用的字段数据
Remove columns not required by the model when using an
nlp.Dataset. (default: True)
--label_names
训练数据标签label的名称
The list of keys in your dictionary of inputs that
correspond to the labels. (default: None)
--load_best_model_at_end
训练结束后是否加载最优模型,通常与`metric_for_best_model`配合使用
Whether or not to load the best model found during
training at the end of training. (default: False)
--metric_for_best_model
最优模型指标,如`eval_accuarcy`等,用于比较模型好坏。
The metric to use to compare two different models.
(default: None)
--greater_is_better
与`metric_for_best_model`配合使用。
Whether the `metric_for_best_model` should be
maximized or not. (default: None)
--ignore_data_skip
重启训练时候,不略过已经训练的数据。
When resuming training, whether or not to skip the
first epochs and batches to get to the same training
data. (default: False)
--optim
优化器名称,默认为adamw,,(`str`, 可选,默认为 `adamw`)
The optimizer to use. (default: adamw)
--report_to
日志可视化显示,默认使用visualdl可视化展示。(可选,默认为 None,展示所有)
The list of integrations to report the results and
logs to. (default: None)
--resume_from_checkpoint
是否从断点重启恢复训练,(可选,默认为 None)
The path to a folder with a valid checkpoint for your
model. (default: None)
--skip_memory_metrics
是否跳过内存profiler检测。(可选,默认为True,跳过)
Whether or not to skip adding of memory profiler reports
to metrics.(default:True)
五、模型压缩
参考《PaddleNLP 模型压缩 API》、《进阶指南——模型压缩》、《ERNIE 3.0 轻量级模型》
5.1 模型压缩简介
模型压缩在保证一定精度的情况下,能够降低模型的存储,加速模型的推理时间。常见的模型压缩方法主要包括模型裁剪、量化和蒸馏。下面分别对这几种方法进行简要的介绍。
-
模型裁剪:通过对已经训练好的模型中不重要的网络连接进行裁剪,减少模型的冗余和计算量,从而减少网络存储、大幅度进行加速的模型压缩方法。
-
量化:用INT8代替Float32来存储神经网络模型参数,减少模型的存储空间,并且能够大幅度加速,使得神经网络在CPU上的运行成为可能。
- 量化包含多种方法,例如:二值神经网络、三元权重网络以及XNOR网络。
- 量化现在支持静态离线量化方法(PTQ)和量化训练(QAT)。PTQ 无需训练,只需少量校准数据,即可导出量化模型。QAT 类似 FP32 模型的训练过程,也基本能够做到精度无损。
-
蒸馏:将teacher模型(参数量较多)蒸馏为student模型(参数量较少的模型),student模型通过拟合teacher模型而从中学到知识。比较常见的方法通常是由Bert base蒸馏到Bi-LSTM或者是Transformer层数更少的BERT小模型。例如DistilBERT,它保留了BERT-base 97%的精度,减少了40%的参数,推理速度快了60%。
PaddleNLP 模型压缩 API ,支持对 ERNIE 类模型在下游任务微调后,进行裁剪、量化,以缩小模型体积减少内存占用,减少计算量提升推理速度,最终减少部署难度。
ERNIE 3.0 压缩效果
如下表所示,ERNIE 3.0-Medium (6-layer, 384-hidden, 12-heads) 模型在三类任务(文本分类、序列标注、抽取式阅读理解)经过裁剪 + 量化后加速比均达到 3 倍左右,所有任务上平均精度损失可控制在 0.5 以内(0.46)。
TNEWS 性能 TNEWS 精度 MSRA_NER 性能 MSRA_NER 精度 CMRC2018 性能 CMRC2018 精度
ERNIE 3.0-Medium+FP32 1123.85(1.0x) 57.45 366.75(1.0x) 93.04 146.84(1.0x) 66.95
ERNIE 3.0-Medium+INT8 3226.26(2.9x) 56.99(-0.46) 889.33(2.4x) 92.70(-0.34) 348.84(2.4x) 66.32(-0.63
ERNIE 3.0-Medium+裁剪+FP32 1424.01(1.3x) 57.31(-0.14) 454.27(1.2x) 93.27(+0.23) 183.77(1.3x) 65.92(-1.03)
ERNIE 3.0-Medium+裁剪+INT8 3635.48(3.2x) 57.26(-0.19) 1105.26(3.0x) 93.20(+0.16) 444.27(3.0x) 66.17(-0.78)
5.2 模型压缩快速启动示例
本项目提供了压缩 API 在分类(包含文本分类、文本匹配、自然语言推理、代词消歧等任务)、序列标注、抽取式阅读理解三大场景下的使用样例,可以分别参考 ERNIE 3.0 目录下的 compress_seq_cls.py 、compress_token_cls.py、compress_qa.py 脚本,启动方式如下:
# 分类任务
# 该脚本共支持 CLUE 中 7 个分类任务,超参不全相同,因此分类任务中的超参配置利用 config.yml 配置
python compress_seq_cls.py \
--dataset "clue tnews" \
--model_name_or_path best_models/TNEWS \
--output_dir ./
# 序列标注任务
python compress_token_cls.py \
--dataset "msra_ner" \
--model_name_or_path best_models/MSRA_NER \
--output_dir ./ \
--max_seq_length 128 \
--per_device_train_batch_size 32 \
--per_device_eval_batch_size 32 \
--learning_rate 0.00005 \
--remove_unused_columns False \
--num_train_epochs 3
# 阅读理解任务
python compress_qa.py \
--dataset "clue cmrc2018" \
--model_name_or_path best_models/CMRC2018 \
--output_dir ./ \
--max_seq_length 512 \
--learning_rate 0.00003 \
--num_train_epochs 8 \
--per_device_train_batch_size 24 \
--per_device_eval_batch_size 24 \
--max_answer_length 50 \
5.3 四步启动模型压缩
环境依赖
- paddlepaddle-gpu >=2.3
- paddlenlp >= 2.4.0
- paddleslim >= 2.3.0
模型压缩 API 中的压缩功能依赖最新的 paddleslim 包。可运行以下命令安装:
pip install paddleslim -i https://pypi.tuna.tsinghua.edu.cn/simple
模型压缩 API 的使用大致分为四步:
- Step 1: 使用
PdArgumentParser解析从命令行传入的超参数,以获取压缩参数compression_args; - Step 2: 实例化 Trainer 并调用
compress()压缩 API - Step 3: 实现自定义评估函数和 loss 计算函数(按需可选),以适配自定义压缩任务
- Step 4:传参并运行压缩脚本
示例代码
from paddlenlp.trainer import PdArgumentParser, CompressionArguments
# Step1: 使用 `PdArgumentParser` 解析从命令行传入的超参数,以获取压缩参数 `compression_args`;
parser = PdArgumentParser(CompressionArguments)
compression_args = parser.parse_args_into_dataclasses()
# Step2: 实例化 Trainer 并调用 compress()
trainer = Trainer(
model=model,
args=compression_args,
data_collator=data_collator,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
criterion=criterion)
# Step 3: 使用内置模型和评估方法,则不需要实现自定义评估函数和 loss 计算函数
trainer.compress()
# Step4: 传参并运行压缩脚本
python compress.py \
--output_dir ./compress_models \
--per_device_train_batch_size 32 \
--per_device_eval_batch_size 32 \
--num_train_epochs 4 \
--width_mult_list 0.75 \
--batch_size_list 4 8 16 \
--batch_num_list 1 \
5.3.1获取模型压缩参数 compression_args
使用 PdArgumentParser 对象解析从命令行得到的超参数,从而得到 compression_args,并将 compression_args 传给 Trainer 对象。获取 compression_args 的方法通常如下:
from paddlenlp.trainer import PdArgumentParser, CompressionArguments
# Step1: 使用 `PdArgumentParser` 解析从命令行传入的超参数,以获取压缩参数 `compression_args`;
parser = PdArgumentParser(CompressionArguments)
compression_args = parser.parse_args_into_dataclasses()
5.3.2 实例化 Trainer 并调用 compress
Trainer 实例化参数介绍
- –model 待压缩的模型,目前支持 ERNIE、BERT、RoBERTa、ERNIE-M、ELECTRA、ERNIE-Gram、PP-MiniLM、TinyBERT 等结构相似的模型,是在下游任务中微调后的模型,当预训练模型选择 ERNIE 时,需要继承
ErniePretrainedModel。以分类任务为例,可通过AutoModelForSequenceClassification.from_pretrained(model_name_or_path)等方式来获取,这种情况下,model_name_or_path目录下需要有 model_config.json, model_state.pdparams 文件; - –data_collator 三类任务均可使用 PaddleNLP 预定义好的 DataCollator 类,
data_collator可对数据进行Pad等操作。使用方法参考 示例代码 即可; - –train_dataset 裁剪训练需要使用的训练集,是任务相关的数据。自定义数据集的加载可参考 文档。不启动裁剪时,可以为 None;
- –eval_dataset 裁剪训练使用的评估集,也是量化使用的校准数据,是任务相关的数据。自定义数据集的加载可参考 文档。是 Trainer 的必选参数;
- –tokenizer 模型
model对应的tokenizer,可使用AutoTokenizer.from_pretrained(model_name_or_path)来获取。 - –criterion 模型的 loss 计算方法,可以是一个 nn.Layer 对象,也可以是一个函数,用于在 ofa_utils.py 计算模型的 loss 用于计算梯度从而确定神经元重要程度。
其中,criterion 函数定义示例:
# 支持的形式一:
def criterion(logits, labels):
loss_fct = paddle.nn.BCELoss()
start_ids, end_ids = labels
start_prob, end_prob = outputs
start_ids = paddle.cast(start_ids, 'float32')
end_ids = paddle.cast(end_ids, 'float32')
loss_start = loss_fct(start_prob, start_ids)
loss_end = loss_fct(end_prob, end_ids)
loss = (loss_start + loss_end) / 2.0
return loss
# 支持的形式二:
class CrossEntropyLossForSQuAD(paddle.nn.Layer):
def __init__(self):
super(CrossEntropyLossForSQuAD, self).__init__()
def forward(self, y, label):
start_logits, end_logits = y
start_position, end_position = label
start_position = paddle.unsqueeze(start_position, axis=-1)
end_position = paddle.unsqueeze(end_position, axis=-1)
start_loss = paddle.nn.functional.cross_entropy(input=start_logits,
label=start_position)
end_loss = paddle.nn.functional.cross_entropy(input=end_logits,
label=end_position)
loss = (start_loss + end_loss) / 2
return loss
用以上参数实例化 Trainer 对象,之后直接调用 compress() 。compress() 会根据选择的策略进入不同的分支,以进行裁剪或者量化的过程。
示例代码
from paddlenlp.trainer import PdArgumentParser, CompressionArguments
# Step1: 使用 `PdArgumentParser` 解析从命令行传入的超参数,以获取压缩参数 `compression_args`;
parser = PdArgumentParser(CompressionArguments)
compression_args = parser.parse_args_into_dataclasses()
# Step2: 实例化 Trainer 并调用 compress()
trainer = Trainer(
model=model,
args=compression_args,
data_collator=data_collator,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
criterion=criterion)
trainer.compress()
5.3.3实现自定义评估函数,以适配自定义压缩任务
当使用 DynaBERT 裁剪功能时,如果模型、Metrics 不符合下表的情况,那么模型压缩 API 中评估函数需要自定义。
目前 DynaBERT 裁剪功能只支持 SequenceClassification 等三类 PaddleNLP 内置 class,并且内置评估器对应为 Accuracy、F1、Squad。
| Model class name | SequenceClassification | TokenClassification | QuestionAnswering |
|---|---|---|---|
| Metrics | Accuracy | F1 | Squad |
需要注意以下三个条件:
-
如果模型是自定义模型,需要继承
XXXPretrainedModel,例如当预训练模型选择 ERNIE 时,继承ErniePretrainedModel,模型需要支持调用from_pretrained()导入模型,且只含pretrained_model_name_or_path一个必选参数,forward函数返回logits或者tuple of logits; -
如果模型是自定义模型,或者数据集比较特殊,压缩 API 中 loss 的计算不符合使用要求,需要自定义
custom_evaluate评估函数,需要同时支持paddleslim.nas.ofa.OFA模型和paddle.nn.layer模型。可参考下方示例代码。- 输入
model和dataloader,返回模型的评价指标(单个 float 值)。 - 将该函数传入
compress()中的custom_evaluate参数;
- 输入
custom_evaluate() 函数定义示例:
import paddle
from paddle.metric import Accuracy
@paddle.no_grad()
def evaluate_seq_cls(self, model, data_loader):
metric = Accuracy()
model.eval()
metric.reset()
for batch in data_loader:
logits = model(input_ids=batch['input_ids'],
token_type_ids=batch['token_type_ids'])
# Supports paddleslim.nas.ofa.OFA model and nn.layer model.
if isinstance(model, paddleslim.nas.ofa.OFA):
logits = logits[0]
correct = metric.compute(logits, batch['labels'])
metric.update(correct)
res = metric.accumulate()
logger.info("acc: %s, " % res)
model.train()
return res
在调用 compress() 时传入这个自定义函数:
trainer.compress(custom_evaluate=evaluate_seq_cls)
5.3.4:传参并运行压缩脚本
这一步主要是将压缩需要用到的参数通过命令行传入,并启动压缩脚本。压缩启动命令:
示例代码
# Step4: 运行压缩脚本
python compress.py \
--output_dir ./compress_models \
--per_device_train_batch_size 32 \
--per_device_eval_batch_size 32 \
--num_train_epochs 4 \
--width_mult_list 0.75 \
--batch_size_list 4 8 16 \
--batch_num_list 1 \
下面会介绍模型压缩启动命令可以传递的超参数。
5.3.5 CompressionArguments 参数介绍
CompressionArguments 中的参数一部分是模型压缩功能特定参数,另一部分继承自 TrainingArguments,是压缩训练时需要设置的超参数。下面会进行具体介绍,
1. 公共参数
公共参数中的参数和具体的压缩策略无关。
-
–strategy 模型压缩策略,目前支持
'dynabert+ptq'、'dynabert'、'ptq'和'qat'。
其中'dynabert'代表基于 DynaBERT 的宽度裁剪策略,'ptq'表示静态离线量化,'dynabert+ptq'代表先裁剪后量化。qat表示量化训练。默认是'dynabert+ptq'; -
–output_dir 模型压缩后模型保存目录;
-
–input_infer_model_path 待压缩的静态图模型,该参数是为了支持对静态图模型的压缩。不需使用时可忽略。默认为
None;
2. DynaBERT 裁剪参数
当用户使用了 DynaBERT 裁剪、PTQ 量化策略(即策略中包含 ‘dynabert’、‘qat’ 时需要传入以下可选参数:
-
–width_mult_list 裁剪宽度保留的搜索列表,对 6 层模型推荐
3/4,对 12 层模型推荐2/3,表示对q、k、v以及ffn权重宽度的保留比例,假设 12 层模型原先有 12 个 attention heads,裁剪后只剩 9 个 attention heads。默认是[3/4]; -
–per_device_train_batch_size 用于裁剪训练的每个 GPU/CPU 核心 的 batch 大小。默认是 8;
-
–per_device_eval_batch_size 用于裁剪评估的每个 GPU/CPU 核心 的 batch 大小。默认是 8;
-
–num_train_epochs 裁剪训练所需要的 epochs 数。默认是 3.0;
-
–max_steps 如果设置为正数,则表示要执行的训练步骤总数。覆盖
num_train_epochs。默认为 -1; -
–logging_steps 两个日志之间的更新步骤数。默认为 500;
-
–save_steps 评估模型的步数。默认为 100;
-
–optim 裁剪训练使用的优化器名称,默认为adamw,默认为 ‘adamw’;
-
–learning_rate 裁剪训练使用优化器的初始学习率,默认为 5e-05;
-
–weight_decay 除了所有 bias 和 LayerNorm 权重之外,应用于所有层裁剪训练时的权重衰减数值。 默认为 0.0;
-
–adam_beta1 裁剪训练使用 AdamW 的优化器时的 beta1 超参数。默认为 0.9;
-
–adam_beta2 裁剪训练使用 AdamW 优化器时的 beta2 超参数。默认为 0.999;
-
–adam_epsilon 裁剪训练使用 AdamW 优化器时的 epsilon 超参数。默认为 1e-8;
-
–max_grad_norm 最大梯度范数(用于梯度裁剪)。默认为 1.0;
-
–lr_scheduler_type 要使用的学习率调度策略。默认为 ‘linear’;
-
–warmup_ratio 用于从 0 到
learning_rate的线性 warmup 的总训练步骤的比例。 默认为 0.0; -
–warmup_steps 用于从 0 到
learning_rate的线性 warmup 的步数。覆盖 warmup_ratio 参数。默认是 0; -
–seed 设置的随机种子。为确保多次运行的可复现性。默认为 42;
-
–device 运行的设备名称。支持 cpu/gpu。默认为 ‘gpu’;
-
–remove_unused_columns 是否去除 Dataset 中不用的字段数据。默认是 True;
3. PTQ 量化参数
当用户使用了 PTQ 量化策略时需要传入以下可选参数:
-
–algo_list 量化策略搜索列表,目前支持
'KL'、'abs_max'、'min_max'、'avg'、'hist'、'mse'和'emd',不同的策略计算量化比例因子的方法不同。建议传入多种策略,可批量得到由多种策略产出的多个量化模型,可从中选择效果最优模型。ERNIE 类模型较推荐'hist','mse','KL','emd'等策略。默认是 [‘mse’, ‘KL’]; -
–batch_num_list batch_nums 的超参搜索列表,batch_nums 表示采样需要的 batch 数。校准数据的总量是 batch_size * batch_nums。如 batch_num 为 None,则 data loader 提供的所有数据均会被作为校准数据。默认是 [1];
-
–batch_size_list 校准样本的 batch_size 搜索列表。并非越大越好,也是一个超参数,建议传入多种校准样本数,最后可从多个量化模型中选择最优模型。默认是
[4]; -
–weight_quantize_type 权重的量化类型,支持
'abs_max'和'channel_wise_abs_max'两种方式。通常使用 ‘channel_wise_abs_max’, 这种方法得到的模型通常精度更高; -
activation_quantize_type 激活 tensor 的量化类型。支持 ‘abs_max’, ‘range_abs_max’ 和 ‘moving_average_abs_max’。在 ‘ptq’ 策略中,默认是 ‘range_abs_max’;
-
–round_type 权重值从 FP32 到 INT8 的转化方法,目前支持
'round'和 ‘adaround’,默认是'round'; -
–bias_correction 如果是 True,表示使用 bias correction 功能,默认为 False。
4. QAT 量化参数
当用户使用了 QAT 量化策略时,除了可以设置上面训练相关的参数,还可以传入以下可选参数:
-
–weight_quantize_type 权重的量化类型,支持
'abs_max'和'channel_wise_abs_max'两种方式。通常使用 ‘channel_wise_abs_max’, 这种方法得到的模型通常精度更高; -
activation_quantize_type 激活 tensor 的量化类型。支持 ‘abs_max’, ‘range_abs_max’ 和 ‘moving_average_abs_max’。在’qat’策略中,它默认是 ‘moving_average_abs_max’;
-
use_pact 是否使用 PACT 量化策略,是对普通方法的改进,参考论文PACT: Parameterized Clipping Activation for Quantized Neural Networks,打开后精度更高,默认是 True。
-
moving_rate ‘moving_average_abs_max’ 量化方法中的衰减系数,默认为 0.9;
5.4 模型评估与部署
裁剪、量化后的模型不能再通过 from_pretrained 导入进行预测,而是需要使用 Paddle 部署工具才能完成预测。压缩后的模型部署可以参考 部署文档 完成。
-
Python 部署
服务端部署可以从这里开始。可以利用 预测 backend 脚本,并参考 infer_cpu.py 或者 infer_gpu.py 来编写自己的预测脚本。并根据 Python 部署指南 的介绍安装预测环境,对压缩后的模型进行精度评估、性能测试以及部署。 -
服务化部署
- Triton Inference Server 服务化部署指南
- Paddle Serving 服务化部署指南
-
Paddle2ONNX 部署:ONNX 导出及 ONNXRuntime 部署请参考:ONNX 导出及 ONNXRuntime 部署指南
-
Paddle Lite 移动端部署:即将支持,敬请期待
5.5 模型压缩示例
参考《模型压缩简介》
下面对基于飞桨实现的常见的模型压缩示例进行介绍。
- 《由BERT到Bi-LSTM的知识蒸馏》:可以作为蒸馏实验的"Hello World"示例。
- 《使用DynaBERT中的策略对BERT进行压缩》:DynaBERT则是同时对不同尺寸的子网络进行训练,通过该方法训练后可以在推理阶段直接对模型裁剪
5.5.1 Bi-LSTM知识蒸馏
详见《由BERT到Bi-LSTM的知识蒸馏》
5.5.2 BERT压缩
详见《使用DynaBERT中的策略对BERT进行压缩》
六、PaddleNLP Embedding API:预训练词向量
参考《PaddleNLP Embedding API》、
七、Taskflow API:PaddleNLP一键预测功能
参考《PaddleNLP一键预测功能:Taskflow API》、《PaddleNLP系列课程一:Taskflow、小样本学习、FasterTransformer》第一章
八、Transformer高性能加速
参考《Transformer高性能加速》、《PaddleNLP系列课程一:Taskflow、小样本学习、FasterTransformer》第三章
九、实践案例
参考《案例集》
十、PaddleNLP常见问题汇总
-
【精选】NLP精选5问
- Q1.1 如何加载自己的本地数据集,以便使用PaddleNLP的功能?
- Q1.2 PaddleNLP会将内置的数据集、模型下载到默认路径,如何修改路径?
- Q1.3 PaddleNLP中如何保存、加载训练好的模型?
- Q1.4 当训练样本较少时,有什么推荐的方法能提升模型效果吗?
- Q1.5 如何提升模型的性能,提升QPS?
-
【理论篇】NLP通用问题
- Q2.1 数据类别分布不均衡, 有哪些应对方法?
- Q2.2 如果使用预训练模型,一般需要多少条样本?
-
【实战篇】PaddleNLP实战问题
数据集和数据处理
- Q3.1 使用自己的数据集训练预训练模型时,如何引入额外的词表?
模型训练调优
-
Q3.2 如何加载自己的预训练模型,进而使用PaddleNLP的功能?
-
Q3.3 如果训练中断,需要继续热启动训练,如何保证学习率和优化器能从中断地方继续迭代?
-
Q3.4 如何冻结模型梯度?
-
Q3.5 如何在eval阶段打印评价指标,在各epoch保存模型参数?
-
Q3.6 训练过程中,训练程序意外退出或Hang住,应该如何排查?
-
Q3.7 在模型验证和测试过程中,如何保证每一次的结果是相同的?
-
Q3.8 ERNIE模型如何返回中间层的输出?
预测部署
- Q3.9 PaddleNLP训练好的模型如何部署到服务器 ?
- Q3.10 静态图模型如何转换成动态图模型?
-
特定模型和应用场景咨询
- Q4.1 【词法分析】LAC模型,如何自定义标签label,并继续训练?
- Q4.2 信息抽取任务中,是否推荐使用预训练模型+CRF,怎么实现呢?
- Q4.3 【阅读理解】
MapDatasets的map()方法中对应的batched=True怎么理解,在阅读理解任务中为什么必须把参数batched设置为True? - Q4.4 【语义匹配】语义索引和语义匹配有什么区别?
- Q4.5 【解语】wordtag模型如何自定义添加命名实体及对应词类?
-
其他使用咨询
- Q5.1 在CUDA11使用PaddlNLP报错?
- Q5.2 如何设置parameter?
- Q5.3 GPU版的Paddle虽然能在CPU上运行,但是必须要有GPU设备吗?
- Q5.4 如何指定用CPU还是GPU训练模型?
- Q5.5 动态图模型和静态图模型的预测结果一致吗?
- Q5.6 如何可视化acc、loss曲线图、模型网络结构图等?
10.1 NLP精选5问
Q1.1 如何加载自己的本地数据集,以便使用PaddleNLP的功能?
A: 通过使用PaddleNLP提供的 load_dataset, MapDataset 和 IterDataset ,可以方便的自定义属于自己的数据集哦,也欢迎您贡献数据集到PaddleNLP repo。
从本地文件创建数据集时,我们 推荐 根据本地数据集的格式给出读取function并传入 load_dataset() 中创建数据集。
以waybill_ie快递单信息抽取任务中的数据为例:
from paddlenlp.datasets import load_dataset
def read(data_path):
with open(data_path, 'r', encoding='utf-8') as f:
# 跳过列名
next(f)
for line in f:
words, labels = line.strip('\n').split('\t')
words = words.split('\002')
labels = labels.split('\002')
yield {'tokens': words, 'labels': labels}
# data_path为read()方法的参数
map_ds = load_dataset(read, data_path='train.txt', lazy=False)
iter_ds = load_dataset(read, data_path='train.txt', lazy=True)
如果您习惯使用paddle.io.Dataset/IterableDataset来创建数据集也是支持的,您也可以从其他python对象如List对象创建数据集,详细内容可参照官方文档-自定义数据集。
Q1.2 PaddleNLP会将内置的数据集、模型下载到默认路径,如何修改路径?
A: 内置的数据集、模型默认会下载到$HOME/.paddlenlp/下,通过配置环境变量可下载到指定路径:
(1)Linux下,设置 export PPNLP_HOME="xxxx",注意不要设置带有中文字符的路径。
(2)Windows下,同样配置环境变量 PPNLP_HOME 到其他非中文字符路径,重启即可。
Q1.3 PaddleNLP中如何保存、加载训练好的模型?
A:(1)PaddleNLP预训练模型
保存:
model.save_pretrained("./checkpoint')
tokenizer.save_pretrained("./checkpoint')
加载:
model.from_pretrained("./checkpoint')
tokenizer.from_pretrained("./checkpoint')
(2)常规模型
保存:
emb = paddle.nn.Embedding(10, 10)
layer_state_dict = emb.state_dict()
paddle.save(layer_state_dict, "emb.pdparams") #保存模型参数
加载:
emb = paddle.nn.Embedding(10, 10)
load_layer_state_dict = paddle.load("emb.pdparams") # 读取模型参数
emb.set_state_dict(load_layer_state_dict) # 加载模型参数
Q1.4 当训练样本较少时,有什么推荐的方法能提升模型效果吗?
A: 增加训练样本带来的效果是最直接的。此外,可以基于我们开源的预训练模型进行热启,再用少量数据集fine-tune模型。此外,针对分类、匹配等场景,小样本学习也能够带来不错的效果。
Q1.5 如何提升模型的性能,提升QPS?
A: 从工程角度,对于服务器端部署可以使用Paddle Inference高性能预测引擎进行预测部署。对于Transformer类模型的GPU预测还可以使用PaddleNLP中提供的FasterTransformer功能来进行快速预测,其集成了NV FasterTransformer并进行了功能增强。
从模型策略角度,可以使用一些模型小型化技术来进行模型压缩,如模型蒸馏和裁剪,通过小模型来实现加速。PaddleNLP中集成了ERNIE-Tiny这样一些通用小模型供下游任务微调使用。另外PaddleNLP提供了模型压缩示例,实现了DynaBERT、TinyBERT、MiniLM等方法策略,可以参考对自己的模型进行蒸馏压缩。
10.2 NLP通用问题
Q2.1 数据类别分布不均衡, 有哪些应对方法?
A: 可以采用以下几种方法优化类别分布不均衡问题:
(1)欠采样:对样本量较多的类别进行欠采样,去除一些样本,使得各类别数目接近。
(2)过采样:对样本量较少的类别进行过采样,选择样本进行复制,使得各类别数目接近。
(3)修改分类阈值:直接使用类别分布不均衡的数据训练分类器,会使得模型在预测时更偏向于多数类,所以不再以0.5为分类阈值,而是针对少数类在模型仅有较小把握时就将样本归为少数类。
(4)代价敏感学习:比如LR算法中设置class_weight参数。
Q2.2 如果使用预训练模型,一般需要多少条样本?
A: 很难定义具体需要多少条样本,取决于具体的任务以及数据的质量。如果数据质量没问题的话,分类、文本匹配任务所需数据量级在百级别,翻译则需要百万级能够训练出一个比较鲁棒的模型。如果样本量较少,可以考虑数据增强,或小样本学习。
10.3 PaddleNLP实战问题
10.3.1数据集和数据处理
Q3.1 使用自己的数据集训练预训练模型时,如何引入额外的词表?
A: 预训练模型通常会有配套的tokenzier和词典,对于大多数中文预训练模型,如ERNIE-3.0,使用的都是字粒度的输入,tokenzier会将句子转换为字粒度的形式,模型无法收到词粒度的输入。如果希望引入额外的词典,需要修改预训练模型的tokenizer和词典,可以参考这里blog,另外注意embedding矩阵也要加上这些新增词的embedding表示。
另外还有一种方式可以使用这些字典信息,可以将数据中在词典信息中的词进行整体mask进行一个mask language model的二次预训练,这样经过二次训练的模型就包含了对额外字典的表征。可参考 PaddleNLP 预训练数据流程。
此外还有些词粒度及字词混合粒度的预训练模型,在这些词粒度的模型下引入额外的词表也会容易些,我们也将持续丰富PaddleNLP中的预训练模型。
10.3.2模型训练调优
Q3.2 如何加载自己的预训练模型,进而使用PaddleNLP的功能?
A: 以bert为例,如果是使用PaddleNLP训练,通过save_pretrained()接口保存的模型,可通过from_pretrained()来加载:
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertModel.from_pretrained("bert-base-uncased")
如果不是上述情况,可以使用如下方式加载模型,也欢迎您贡献模型到PaddleNLP repo中。
(1)加载BertTokenizer和BertModel
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertModel.from_pretrained("bert-base-uncased")
(2)调用save_pretrained()生成 model_config.json、 tokenizer_config.json、model_state.pdparams、 vocab.txt 文件,保存到./checkpoint:
tokenizer.save_pretrained("./checkpoint")
model.save_pretrained("./checkpoint")
(3)修改model_config.json、 tokenizer_config.json这两个配置文件,指定为自己的模型,之后通过from_pretrained()加载模型。
tokenizer = BertTokenizer.from_pretrained("./checkpoint")
model = BertModel.from_pretrained("./checkpoint")
Q3.3 如果训练中断,需要继续热启动训练,如何保证学习率和优化器能从中断地方继续迭代?
A:
(1)完全恢复训练状态,可以先将lr、 optimizer、model的参数保存下来:
paddle.save(lr_scheduler.state_dict(), "xxx_lr")
paddle.save(optimizer.state_dict(), "xxx_opt")
paddle.save(model.state_dict(), "xxx_para")
(2)加载lr、 optimizer、model参数即可恢复训练:
lr_scheduler.set_state_dict(paddle.load("xxxx_lr"))
optimizer.set_state_dict(paddle.load("xxx_opt"))
model.set_state_dict(paddle.load("xxx_para"))
Q3.4 如何冻结模型梯度?
A:
有多种方法可以尝试:
(1)可以直接修改 PaddleNLP 内部代码实现,在需要冻结梯度的地方用 paddle.no_grad() 包裹一下
paddle.no_grad() 的使用方式,以对 forward() 进行冻结为例:
# Method 1
class Model(nn.Layer):
def __init__(self, ...):
...
def forward(self, ...):
with paddle.no_grad():
...
# Method 2
class Model(nn.Layer):
def __init__(self, ...):
...
@paddle.no_grad()
def forward(self, ...):
...
paddle.no_grad() 的使用也不局限于模型内部实现里面,也可以包裹外部的方法,比如:
@paddle.no_grad()
def evaluation(...):
...
model = Model(...)
model.eval()
...
(2)第二种方法:以ERNIE为例,将模型输出的 tensor 设置 stop_gradient 为 True。可以使用 register_forward_post_hook 按照如下的方式尝试:
def forward_post_hook(layer, input, output):
output.stop_gradient=True
self.ernie.register_forward_post_hook(forward_post_hook)
(3)第三种方法:在 optimizer 上进行处理,model.parameters 是一个 List,可以通过 name 进行相应的过滤,更新/不更新某些参数,这种方法需要对网络结构的名字有整体了解,因为网络结构的实体名字决定了参数的名字,这个使用方法有一定的门槛:
[ p for p in model.parameters() if 'linear' not in p.name] # 这里就可以过滤一下linear层,具体过滤策略可以根据需要来设定
Q3.5 如何在eval阶段打印评价指标,在各epoch保存模型参数?
A: 飞桨主框架提供了两种训练与预测的方法,一种是用 paddle.Model()对模型进行封装,通过高层API如Model.fit()、Model.evaluate()、Model.predict()等完成模型的训练与预测;另一种就是基于基础API常规的训练方式。
(1)对于第一种方法:
-
我们可以设置
paddle.Model.fit()API中的 eval_data 和 eval_freq 参数在训练过程中打印模型评价指标:eval_data 参数是一个可迭代的验证集数据源,eval_freq 参数是评估的频率;当eval_data 给定后,eval_freq 的默认值为1,即每一个epoch进行一次评估。注意:在训练前,我们需要在Model.prepare()接口传入metrics参数才能在eval时打印模型评价指标。 -
关于模型保存,我们可以设置
paddle.Model.fit()中的 save_freq 参数控制模型保存的频率:save_freq 的默认值为1,即每一个epoch保存一次模型。
(2)对于第二种方法:
-
我们在PaddleNLP的examples目录下提供了常见任务的训练与预测脚本:如GLUE 和 SQuAD等
-
开发者可以参考上述脚本进行自定义训练与预测脚本的开发。
Q3.6 训练过程中,训练程序意外退出或Hang住,应该如何排查?
A: 一般先考虑内存、显存(使用GPU训练的话)是否不足,可将训练和评估的batch size调小一些。
需要注意,batch size调小时,学习率learning rate也要调小,一般可按等比例调整。
Q3.7 在模型验证和测试过程中,如何保证每一次的结果是相同的?
A: 在验证和测试过程中常常出现的结果不一致情况一般有以下几种解决方法:
(1)确保设置了eval模式,并保证数据相关的seed设置保证数据一致性。
(2)如果是下游任务模型,查看是否所有模型参数都被导入了,直接使用bert-base这种预训练模型是不包含任务相关参数的,要确认导入的是微调后的模型,否则任务相关参数会随机初始化导致出现随机性。
(3)部分算子使用CUDNN后端产生的不一致性可以通过环境变量的设置来避免。如果模型中使用了CNN相关算子,可以设置FLAGS_cudnn_deterministic=True。如果模型中使用了RNN相关算子,可以设置CUBLAS_WORKSPACE_CONFIG=:16:8或CUBLAS_WORKSPACE_CONFIG=:4096:2(CUDNN 10.2以上版本可用,参考CUDNN 8 release note)。
Q3.8 ERNIE模型如何返回中间层的输出?
A: 目前的API设计不保留中间层输出,当然在PaddleNLP里可以很方便地修改源码。
此外,还可以在ErnieModel的__init__函数中通过register_forward_post_hook()为想要保留输出的Layer注册一个forward_post_hook函数,在forward_post_hook函数中把Layer的输出保存到一个全局的List里面。forward_post_hook函数将会在forward函数调用之后被调用,并保存Layer输出到全局的List。详情参考register_forward_post_hook()。
10.4 预测部署
Q3.9 PaddleNLP训练好的模型如何部署到服务器 ?
A: 我们推荐在动态图模式下开发,静态图模式部署。
(1)动转静
动转静,即将动态图的模型转为可用于部署的静态图模型。
动态图接口更加易用,python 风格的交互式编程体验,对于模型开发更为友好,而静态图相比于动态图在性能方面有更绝对的优势。因此动转静提供了这样的桥梁,同时兼顾开发成本和性能。
可以参考官方文档 动态图转静态图文档,使用 paddle.jit.to_static 完成动转静。
另外,在 PaddleNLP 我们也提供了导出静态图模型的例子,可以参考 waybill_ie 模型导出。
(2)借助Paddle Inference部署
动转静之后保存下来的模型可以借助Paddle Inference完成高性能推理部署。Paddle Inference内置高性能的CPU/GPU Kernel,结合细粒度OP横向纵向融合等策略,并集成 TensorRT 实现模型推理的性能提升。具体可以参考文档 Paddle Inference 简介。
为便于初次上手的用户更易理解 NLP 模型如何使用Paddle Inference,PaddleNLP 也提供了对应的例子以供参考,可以参考 /PaddleNLP/examples 下的deploy目录,如基于ERNIE的命名实体识别模型部署。
Q3.10 静态图模型如何转换成动态图模型?
A: 首先,需要将静态图参数保存成ndarray数据,然后将静态图参数名和对应动态图参数名对应,最后保存成动态图参数即可。详情可参考参数转换脚本。
10.5 特定模型和应用场景咨询
Q4.1 【词法分析】LAC模型,如何自定义标签label,并继续训练?
A: 更新label文件tag.dict,添加 修改下CRF的标签数即可。
可参考自定义标签示例,增量训练自定义LABLE示例。
Q4.2 信息抽取任务中,是否推荐使用预训练模型+CRF,怎么实现呢?
A: 预训练模型+CRF是一个通用的序列标注的方法,目前预训练模型对序列信息的表达也是非常强的,也可以尝试直接使用预训练模型对序列标注任务建模。
Q4.3.【阅读理解】MapDatasets的map()方法中对应的batched=True怎么理解,在阅读理解任务中为什么必须把参数batched设置为True?
A: batched=True就是对整个batch(这里不一定是训练中的batch,理解为一组数据就可以)的数据进行map,即map中的trans_func接受一组数据为输入,而非逐条进行map。在阅读理解任务中,根据使用的doc_stride不同,一条样本可能被转换成多条feature,对数据逐条map是行不通的,所以需要设置batched=True。
Q4.4 【语义匹配】语义索引和语义匹配有什么区别?
A: 语义索引要解决的核心问题是如何从海量 Doc 中通过 ANN 索引的方式快速、准确地找出与 query 相关的文档,语义匹配要解决的核心问题是对 query和文档更精细的语义匹配信息建模。换个角度理解, 语义索引是要解决搜索、推荐场景下的召回问题,而语义匹配是要解决排序问题,两者要解决的问题不同,所采用的方案也会有很大不同,但两者间存在一些共通的技术点,可以互相借鉴。
Q4.5 【解语】wordtag模型如何自定义添加命名实体及对应词类?
A: 其主要依赖于二次构造数据来进行finetune,同时要更新termtree信息。wordtag分为两个步骤:
(1)通过BIOES体系进行分词;
(2)将分词后的信息和TermTree进行匹配。
因此我们需要:
(1)分词正确,这里可能依赖于wordtag的finetune数据,来让分词正确;
(2)wordtag里面也需要把分词正确后term打上相应的知识信息。wordtag自定义TermTree的方式将在后续版本提供出来。
可参考issue。
10.6 其他使用咨询
Q5.1 在CUDA11使用PaddlNLP报错?
A: 在CUDA11安装,可参考issue,其他CUDA版本安装可参考 官方文档
Q5.2 如何设置parameter?
A: 有多种方法:
(1)可以通过set_value()来设置parameter,set_value()的参数可以是numpy或者tensor。
layer.weight.set_value(
paddle.tensor.normal(
mean=0.0,
std=self.initializer_range
if hasattr(self, "initializer_range") else
self.ernie.config["initializer_range"],
shape=layer.weight.shape))
(2)通过create_parameter()设置参数。
class MyLayer(paddle.nn.Layer):
def __init__(self):
super(MyLayer, self).__init__()
self._linear = paddle.nn.Linear(1, 1)
w_tmp = self.create_parameter([1,1])
self.add_parameter("w_tmp", w_tmp)
def forward(self, input):
return self._linear(input)
mylayer = MyLayer()
for name, param in mylayer.named_parameters():
print(name, param)
Q5.3 GPU版的Paddle虽然能在CPU上运行,但是必须要有GPU设备吗?
A: 不支持 GPU 的设备只能安装 CPU 版本的 PaddlePaddle。 GPU 版本的 PaddlePaddle 如果想只在 CPU 上运行,可以通过 export CUDA_VISIBLE_DEVICES=-1 来设置。
Q5.4 如何指定用CPU还是GPU训练模型?
A: 一般我们的训练脚本提供了 --device 选项,用户可以通过 --device 选择需要使用的设备。
具体而言,在Python文件中,我们可以通过·paddle.device.set_device()·,设置为gpu或者cpu,可参考 set_device文档。
Q5.5 动态图模型和静态图模型的预测结果一致吗?
A: 正常情况下,预测结果应当是一致的。如果遇到不一致的情况,可以及时反馈给 PaddleNLP 的开发人员,我们进行处理。
Q5.6 如何可视化acc、loss曲线图、模型网络结构图等?
A: 可使用VisualDL进行可视化。其中acc、loss曲线图的可视化可参考Scalar——折线图组件使用指南,模型网络结构的可视化可参考Graph——网络结构组件使用指南。

![[Linux_]make/Makefile](https://img-blog.csdnimg.cn/26782a673c9946289f713d4861191e26.png)