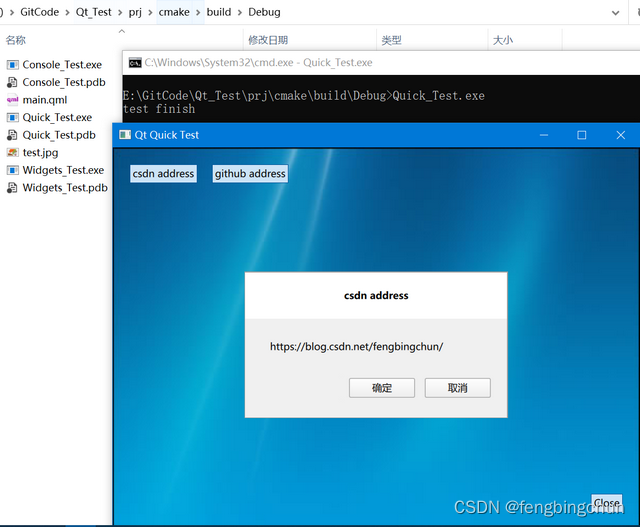
RANSAC算法解析
RANSAC是一种在具有噪声的模型中去估计最优的一个算法,其核心思想是采用不断迭代的方法去选择一组全是内点的集合,并采用该集合进行模型估计的一种方法,可以提高模型估计的鲁棒性。

假设目前有 K K K组采集到的数据,但是数据中的一些点是噪声点,如何使用RANSAC去根据这些有噪声的数据去估计一个比较好的模型呢?
- 选择任意一种能够根据当前采集的数据进行模型评估的方法。
- 使用有放回抽样的方式抽取 S i S_i Si个数据,使用上述方法进行模型评估。
- 根据当前模型,进行数据点的回代。
- 根据计算误差的自由度和置信区间查卡方检验表== χ 2 \chi^2 χ2和指定的方差的乘积==作为阈值 t t t。
- 使用阈值 t t t设置内点标识,统计内点数目 K i n K_{in} Kin。
- 根据给定的内点百分比 ω \omega ω和数据总数 K K K的乘积为阈值 T T T,判断这次RANSAC迭代的模型是否有效。
- 根据计算得出的迭代次数 N N N。
1 外点阈值 t t t
- RANSAC算法的模型估计后,进行数据回代判断内点时,所使用到的参数。
- 这个参数的选择是根据模型误差计算的自由度和置信区间查卡方检验表确定的。
- 在卡方检验中,假设误差符合高斯分布, e 2 < k 2 e^2<k^2 e2<k2的概率为 P ( k 2 ) = ∫ 0 k 2 χ m 2 ( ξ ) d ξ P(k^2)=\int_{0}^{k^2}{\chi^2_m(\xi) d\xi} P(k2)=∫0k2χm2(ξ)dξ,其中 e e e为误差, χ 2 \chi^2 χ2为高斯分布的平方表示, ξ \xi ξ为置信区间, m m m为高斯分布的自由度, t = k 2 = P − 1 ( ξ ) σ 2 t=k^2=P^{-1}(\xi)\sigma^2 t=k2=P−1(ξ)σ2,其中 σ \sigma σ为高斯分布标准差。
- 在这一部分,一般是需要95%的置信区间,也就是说如果满足假设的高斯分布的话,我需要去掉5%的离群点,但是往往并不是这样,这是因为误差往往都是不满足高斯分布的。
- 这里计算阈值 t t t时,也需要确定方差的 σ 2 \sigma^2 σ2的大小,这就需要一定的先验内容了,在ORB-SLAM中,以金字塔层级的缩放因子的平方作为误差分布的先验方差,金字塔层级越高,认定的方差越大,所对应的误差阈值越大。
2 模型合格阈值 T T T
- 在判断这次RANSAC算法是否合格时,需要的阈值 T T T
- 这个 T T T是能接受数据中最少内点的内点个数,是人为定义的一个数值,但是这个数值一般不少于采集数据总数的50%。
3 迭代次数 N N N
当RANSAC进行N次抽样时,至少有一次全为内点。或者说至少有一次全为内点的概率是 P P P。确定迭代次数的方式主要有两种:
- 假设采集到的数据中,内点的比例为
ω
\omega
ω,则进行
N
N
N次抽样时,至少有一次全为内点的概率计算公式为
P
=
1
−
(
1
−
ω
s
i
)
N
P=1-(1-\omega^{s_i})^N
P=1−(1−ωsi)N
- 进行 s i s_i si次有放回抽样,抽到全是内点的概率为 ω s i \omega^{s_i} ωsi,则抽不到全是内点的概率为 1 − ω s i 1-\omega^{s_i} 1−ωsi
- 进行N次上述抽样,抽不到全是内点的概率为 ( 1 − ω s i ) N (1-\omega^{s_i})^N (1−ωsi)N,则至少有一次全是内点的概率为 P = 1 − ( 1 − ω s i ) N P=1-(1-\omega^{s_i})^N P=1−(1−ωsi)N
- 这种计算方式计算的迭代次数比较粗糙,在很大程度上依赖于内点占比的假设,在ORB-SLAM中也是用的这种方法。
- 使用迭代的方式进行迭代次数N的确定
- 迭代次数N是用于设置迭代终止条件的,因此重要的并不是求迭代次数N是多少,而是需要一个RANSAC迭代停止的条件
- 在RANSAC进行数据回代时,会统计一个内点的占比 ω i \omega_i ωi,可以根据 ω i \omega_i ωi来动态的计算和更新迭代次数 N N N
- 若当前更新的迭代次数 N N N小于目前真实的迭代次数,那么退出迭代即可。